对视频进行解码的设备的制作方法
技术领域
本发明的一个或更多个实施例涉及视频编码和解码,更具体地讲,涉及一种用于对与变换单元相关的信息进行熵编码和熵解码的方法和设备。
背景技术:
根据图像压缩方法(诸如MPEG-1、MPEG-2或MPEG-4H.264/MPEG-4先进视频编码(AVC)),图像被划分为具有预定尺寸的块,然后,通过帧间预测或帧内预测获得块的残差数据。通过变换、量化、扫描、游程编码和熵编码对残差数据进行压缩。在熵编码中,对句法元素(诸如变换系数或预测模式)进行熵编码以输出比特流。解码器从比特流解析并提取句法元素,并基于提取的句法元素重建图像。
技术实现要素:
技术问题
本发明的一个或更多个实施例包括这样的熵编码方法和设备以及熵解码方法和设备,所述方法和设备用于基于指示编码单元和变换单元之间的分层划分关系的变换深度,来选择上下文模型,该上下文模型用于对与作为用于对编码单元进行变换的数据单元的变换单元有关的句法元素进行熵编码和熵解码。
解决方案
基于变换深度来确定用于对变换单元有效系数标记进行算术解码的上下文模型,并且基于确定的上下文模型对变换单元有效系数标记进行算术解码,其中,变换深度指示为了确定包括在编码单元中的变换单元而对编码单元进行划分的次数。
有益效果
根据本发明的实施例,通过基于变换深度来选择上下文模型,用于选择上下文模型的条件可被简化并且用于熵编码和熵解码的操作也可被简化。
附图说明
图1是根据本发明的实施例的视频编码设备的框图。
图2是根据本发明的实施例的视频解码设备的框图。
图3是用于描述根据本发明的实施例的编码单元的概念的示图。
图4是根据本发明的实施例的基于具有分层结构的编码单元的视频编码器的框图。
图5是根据本发明的实施例的基于具有分层结构的编码单元的视频解码器的框图。
图6是示出根据本发明的实施例的根据深度的较深层编码单元和分区的示图。
图7是用于描述根据本发明的实施例的编码单元与变换单元之间的关系的示图。
图8是用于描述根据本发明的实施例的与编码深度相应的编码单元的编码信息的示图。
图9是根据本发明的实施例的根据深度的较深层编码单元的示图。
图10至图12是用于描述根据本发明的实施例的编码单元、预测单元和频率变换单元之间的关系的示图。
图13是用于描述根据表1的编码模式信息的编码单元、预测单元和变换单元之间的关系的示图。
图14是根据本发明的实施例的熵编码设备的框图。
图15是示出根据本发明的实施例的对与变换单元相关的句法元素进行熵编码和熵解码的操作的流程图。
图16是示出根据本发明的实施例的编码单元和包括在编码单元中的变换单元的示图。
图17是示出用于基于变换深度确定图16的每个变换单元的变换单元有效系数标记的上下文模型的上下文增加参数的示图。
图18是示出根据本发明的另一实施例的编码单元和包括在编码单元中的变换单元的示图。
图19是示出根据本发明的实施例的用于确定包括在图16的编码单元中的变换单元的结构的划分信息标记的示图。
图20示出根据本发明的实施例被熵编码的变换单元。
图21示出与图20的变换单元相应的有效图。
图22示出与图20的4×4变换单元相应的coeff_abs_level_greater1_flag。
图23示出与图20的4×4变换单元相应的coeff_abs_level_greater2_flag。
图24示出与图20的4×4变换单元相应的coeff_abs_level_remaining。
图25是根据本发明的实施例的视频的熵编码方法的流程图。
图26是根据本发明的实施例的熵解码设备的框图。
图27是根据本发明的实施例的视频的熵解码方法的流程图。
最佳实施方式
根据本发明的一个或更多个实施例,一种视频的熵解码方法,所述方法包括:确定包括在编码单元中并用于对编码单元进行逆变换的变换单元;从比特流获得变换单元有效系数标记,其中,变换单元有效系数标记指示非零变换系数是否存在于变换单元中;在为了确定变换单元而对编码单元进行划分的次数被称为变换单元的变换深度的情况下,基于变换单元的变换深度来确定用于对变换单元有效系数标记进行算术解码的上下文模型;基于确定的上下文模型来对变换单元有效系数标记进行算术解码。
根据本发明的一个或更多个实施例,一种视频的熵解码设备,所述设备包括:解析器,用于从比特流获得变换单元有效系数标记,其中,变换单元有效系数标记指示非零变换系数是否存在于变换单元中,变换单元包括在编码单元中并用于对编码单元进行逆变换;上下文建模器,用于在为了确定变换单元而对编码单元进行划分的次数被称为变换单元的变换深度的情况下,基于变换单元的变换深度来确定用于对变换单元有效系数标记进行算术解码的上下文模型;算术解码器,用于基于确定的上下文模型来对变换单元有效系数标记进行算术解码。
根据本发明的一个或更多个实施例,一种视频的熵编码方法,所述方法包括:获得基于变换单元而变换的编码单元的数据;在为了确定变换单元而对编码单元进行划分的次数被称为变换单元的变换深度的情况下,基于变换单元的变换深度来确定用于对变换单元有效系数标记进行算术编码的上下文模型,其中,变换单元有效系数标记指示非零变换系数是否存在于变换单元中;基于确定的上下文模型来对变换单元有效系数标记进行算术编码。
根据本发明的一个或更多个实施例,一种视频的熵编码设备,所述设备包括:上下文建模器,用于获得基于变换单元而变换的编码单元的数据,并且在为了确定变换单元而对编码单元进行划分的次数被称为变换单元的变换深度的情况下,基于变换单元的变换深度来确定用于对变换单元有效系数标记进行算术编码的上下文模型,其中,变换单元有效系数标记指示非零变换系数是否存在于变换单元中;算术编码器,用于基于确定的上下文模型来对变换单元有效系数标记进行算术编码。
具体实施方式
以下,将参照图1至图13描述根据本发明的实施例的用于更新在对变换单元的尺寸信息进行熵编码和熵解码中使用的参数的方法和设备。此外,将参照图14至图27详细地描述通过使用参照图1至图13描述的对视频进行熵编码和熵解码的方法获得的句法元素进行熵编码和熵解码的方法。当诸如“…中的至少一个”的表述在一列元素之后时,该表述修饰整列元素而不是修饰该列中的个别元素。
图1是根据本发明的实施例的视频编码设备100的框图。
视频编码设备100包括分层编码器110和熵编码器120。
分层编码器110可以以预定数据单元为单位划分将编码的当前画面,以对每个数据单元执行编码。详细地讲,分层编码器110可基于最大编码单元划分当前画面,其中,最大编码单元是最大尺寸的编码单元。根据本发明的实施例的最大编码单元可以是尺寸为32×32、64×64、128×128、256×256等的数据单元,其中,数据单元的形状是具有2的若干次方且大于8的宽度和长度的方形。
根据本发明的实施例的编码单元可由最大尺寸和深度表征。深度表示编码单元从最大编码单元被空间划分的次数,并且随着深度加深,根据深度的较深层编码单元可从最大编码单元被划分到最小编码单元。最大编码单元的深度为最高深度,最小编码单元的深度为最低深度。由于随着最大编码单元的深度加深,与每个深度相应的编码单元的尺寸减小,因此与更高深度相应的编码单元可包括多个与更低深度相应的编码单元。
如上所述,当前画面的图像数据根据编码单元的最大尺寸被划分为最大编码单元,并且每个最大编码单元可包括根据深度被划分的较深层编码单元。由于根据深度对根据本发明的实施例的最大编码单元进行划分,因此可根据深度对在最大编码单元中包括的空间域的图像数据进行分层地分类。
可预先确定编码单元的最大深度和最大尺寸,所述最大深度和最大尺寸限制对最大编码单元的高度和宽度进行分层划分的总次数。
分层编码器110对通过根据深度对最大编码单元的区域进行划分而获得的至少一个划分区域进行编码,并且根据所述至少一个划分区域来确定用于输出最终编码的图像数据的深度。换句话说,分层编码器110通过根据当前画面的最大编码单元以根据深度的较深层编码单元对图像数据进行编码,并选择具有最小编码误差的深度,来确定编码深度。确定的编码深度和根据最大编码单元的被编码的图像数据被输出到熵编码器120。
基于与等于或小于最大深度的至少一个深度相应的较深层编码单元,对最大编码单元中的图像数据进行编码,并且基于每个较深层编码单元来比较对图像数据进行编码的结果。在对较深层编码单元的编码误差进行比较之后,可选择具有最小编码误差的深度。可针对每个最大编码单元选择至少一个编码深度。
随着编码单元根据深度被分层地划分并随着编码单元的数量增加,最大编码单元的尺寸被划分。另外,即使在一个最大编码单元中编码单元与同一深度相应,也通过分别测量每个编码单元的图像数据的编码误差来确定是否将与同一深度相应的每个编码单元划分为更低深度。因此,即使图像数据被包括在一个最大编码单元中,图像数据仍被划分为根据深度的区域,并且在一个最大编码单元中编码误差根据区域而不同,因此在图像数据中编码深度可根据区域而不同。因此,可在一个最大编码单元中确定一个或更多个编码深度,并且可根据至少一个编码深度的编码单元来对最大编码单元的图像数据进行划分。
因此,分层编码器110可确定在最大编码单元中包括的具有树结构的编码单元。根据本发明的实施例的“具有树结构的编码单元”包括在最大编码单元中包括的所有较深层编码单元中的与确定为编码深度的深度相应的编码单元。可在最大编码单元的同一区域中根据深度来分层地确定具有编码深度的编码单元,并可在不同区域中独立地确定具有编码深度的编码单元。类似地,当前区域中的编码深度可独立于另一区域中的编码深度而被确定。
根据本发明的实施例的最大深度是与最大编码单元被划分为最小编码单元的次数有关的索引。根据本发明的实施例的第一最大深度可表示最大编码单元被划分为最小编码单元的总次数。根据本发明的实施例的第二最大深度可表示从最大编码单元到最小编码单元的深度等级的总数。例如,当最大编码单元的深度为0时,对最大编码单元划分一次的编码单元的深度可被设置为1,对最大编码单元划分两次的编码单元的深度可被设置为2。这里,如果最小编码单元是对最大编码单元划分四次的编码单元,则存在深度0、1、2、3和4的5个深度等级,并因此第一最大深度可被设置为4,第二最大深度可被设置为5。
可根据最大编码单元执行预测编码和变换。还根据最大编码单元,基于根据等于或小于最大深度的深度的较深层编码单元来执行预测编码和变换。
由于每当根据深度对最大编码单元进行划分时,较深层编码单元的数量增加,因此对随着深度加深而产生的所有较深层编码单元执行包括预测编码和变换的编码。为了便于描述,在最大编码单元中,现在将基于当前深度的编码单元来描述预测编码和变换。
视频编码设备100可不同地选择用于对图像数据进行编码的数据单元的尺寸或形状。为了对图像数据进行编码,执行诸如预测编码、变换和熵编码的操作,此时,可针对所有操作使用相同的数据单元,或者可针对每个操作使用不同的数据单元。
例如,视频编码设备100不仅可选择用于对图像数据进行编码的编码单元,还可选择不同于编码单元的数据单元,以便对编码单元中的图像数据执行预测编码。
为了对最大编码单元执行预测编码,可基于与编码深度相应的编码单元(即,基于不再被划分成与更低深度相应的编码单元的编码单元)来执行预测编码。以下,不再被划分且成为用于预测编码的基本单元的编码单元将被称为“预测单元”。通过划分预测单元而获得的分区可包括预测单元或通过对预测单元的高度和宽度中的至少一个进行划分而获得的数据单元。
例如,当2N×2N(其中,N是正整数)的编码单元不再被划分,并且成为2N×2N的预测单元时,分区的尺寸可以是2N×2N、2N×N、N×2N或N×N。分区类型的示例包括通过对预测单元的高度或宽度进行对称地划分而获得的对称分区、通过对预测单元的高度或宽度进行非对称地划分(诸如,1:n或n:1)而获得的分区、通过对预测单元进行几何地划分而获得的分区、以及具有任意形状的分区。
预测单元的预测模式可以是帧内模式、帧间模式和跳过模式中的至少一个。例如,可对2N×2N、2N×N、N×2N或N×N的分区执行帧内模式或帧间模式。另外,可仅对2N×2N的分区执行跳过模式。可对编码单元中的一个预测单元独立地执行编码,从而选择具有最小编码误差的预测模式。
视频编码设备100不仅可基于用于对图像数据进行编码的编码单元还可基于与编码单元不同的数据单元,来对编码单元中的图像数据执行变换。
为了在编码单元中执行变换,可基于具有尺寸等于或小于编码单元的尺寸的数据单元,来执行变换。例如,用于变换的数据单元可包括用于帧内模式的数据单元和用于帧间模式的数据单元。
用作变换的基础的数据单元被称为“变换单元”。与编码单元类似,编码单元中的变换单元可被递归地划分为更小尺寸的区域,使得变换单元可以以区域为单位被独立地确定。因此,可基于根据变换深度的具有树结构的变换单元,对编码单元中的残差数据进行划分。
还可在变换单元中设置变换深度,其中,变换深度表示对编码单元的高度和宽度进行划分以达到变换单元的次数。例如,在2N×2N的当前编码单元中,当变换单元的尺寸是2N×2N时,变换深度可以为0,当变换单元的尺寸是N×N时,变换深度可以是1,当变换单元的尺寸是N/2×N/2时,变换深度可以是2。也就是说,还可根据变换深度设置具有树结构的变换单元。
根据与编码深度相应的编码单元的编码信息不仅需要关于编码深度的信息,还需要关于与预测编码和变换相关的信息的信息。因此,分层编码器110不仅确定具有最小编码误差的编码深度,还确定预测单元中的分区类型、根据预测单元的预测模式和用于变换的变换单元的尺寸。
以下将参照图3至图12详细描述根据本发明的实施例的最大编码单元中的根据树结构的编码单元,以及确定分区的方法。
分层编码器110可通过使用基于拉格朗日乘数的率失真优化,来测量根据深度的较深层编码单元的编码误差。
熵编码器120在比特流中输出最大编码单元的图像数据和关于根据编码深度的编码模式的信息,其中,所述最大编码单元的图像数据基于由分层编码器110确定的至少一个编码深度被编码。编码图像数据可以是图像的残差数据的编码结果。关于根据编码深度的编码模式的信息可包括关于编码深度的信息、关于在预测单元中的分区类型的信息、预测模式信息和变换单元的尺寸信息。具体地讲,如以下将描述的,熵编码器120可通过使用基于变换单元的变换深度确定的上下文模型来对变换单元有效系数标记(coded_block_flag)cbf进行熵编码,其中,cbf指示非0变换系数是否被包括在变换单元中。以下将描述熵编码器120中的对与变换单元相关的句法元素进行熵编码的操作。
可通过使用根据深度的划分信息来定义关于编码深度的信息,其中,根据深度的划分信息指示是否对更低深度而不是当前深度的编码单元执行编码。如果当前编码单元的当前深度是编码深度,则对当前编码单元中的图像数据进行编码并输出,因此可定义划分信息以不将当前编码单元划分到更低深度。可选地,如果当前编码单元的当前深度不是编码深度,则对更低深度的编码单元执行编码,并因此可定义划分信息以对当前编码单元进行划分来获得更低深度的编码单元。
如果当前深度不是编码深度,则对被划分到更低深度的编码单元的编码单元执行编码。由于更低深度的至少一个编码单元存在于当前深度的一个编码单元中,因此对更低深度的每个编码单元重复执行编码,并因此可对具有相同深度的编码单元递归地执行编码。
由于针对一个最大编码单元确定具有树结构的编码单元,并且针对编码深度的编码单元确定关于至少一个编码模式的信息,所以可针对一个最大编码单元确定关于至少一个编码模式的信息。另外,由于根据深度对图像数据进行分层划分,因此最大编码单元的图像数据的编码深度可根据位置而不同,因此可针对图像数据设置关于编码深度和编码模式的信息。
因此,熵编码器120可将关于相应的编码深度和编码模式的编码信息分配给包括在最大编码单元中的编码单元、预测单元和最小单元中的至少一个。
根据本发明的实施例的最小单元是通过将构成最低深度的最小编码单元划分为4份而获得的方形数据单元。可选择地,最小单元可以是包括在最大编码单元中所包括的所有编码单元、预测单元、分区单元和变换单元中的最大方形数据单元。
例如,通过熵编码器120输出的编码信息可被分类为根据编码单元的编码信息和根据预测单元的编码信息。根据编码单元的编码信息可包括关于预测模式的信息和关于分区尺寸的信息。根据预测单元的编码信息可包括关于帧间模式的估计方向的信息、关于帧间模式的参考图像索引的信息、关于运动矢量的信息、关于帧内模式的色度分量的信息、以及关于帧内模式的插值方法的信息。此外,根据画面、条带或GOP定义的关于编码单元的最大尺寸的信息和关于最大深度的信息可被插入到比特流的头。
在视频编码设备100中,较深层编码单元可以是通过将更高深度的编码单元(更高一层)的高度或宽度划分成两份而获得的编码单元。换言之,当当前深度的编码单元的尺寸是2N×2N时,更低深度的编码单元的尺寸是N×N。另外,尺寸为2N×2N的当前深度的编码单元可包括最多4个更低深度的编码单元。
因此,视频编码设备100可基于考虑当前画面的特征而确定的最大编码单元的尺寸和最大深度,通过针对每个最大编码单元确定具有最优形状和最优尺寸的编码单元来形成具有树结构的编码单元。另外,由于可通过使用各种预测模式和变换中的任意一个对每个最大编码单元执行编码,因此可考虑各种图像尺寸的编码单元的特征来确定最优编码模式。
因此,如果以传统宏块对具有高分辨率或大数据量的图像进行编码,则每个画面的宏块的数量极度增加。因此,针对每个宏块产生的压缩信息的条数增加,因此难以发送压缩的信息,并且数据压缩效率降低。然而,通过使用视频编码设备100,由于在考虑图像的特征的同时调整编码单元,同时,在考虑图像的尺寸的同时增加编码单元的最大尺寸,因此可提高图像压缩效率。
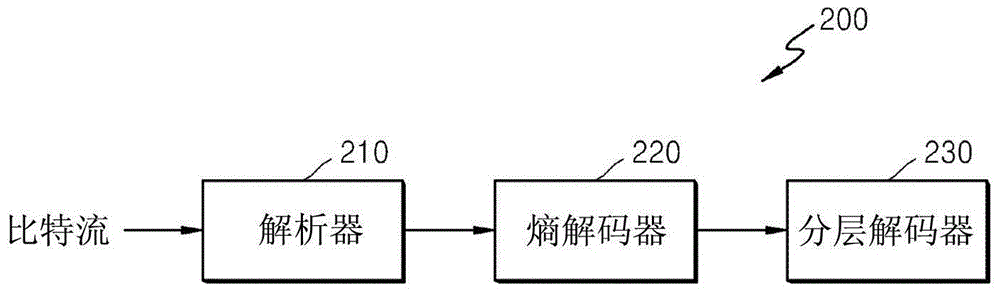
图2是根据本发明的实施例的视频解码设备200的框图。
视频解码设备200包括解析器、熵解码器220和分层解码器230。用于视频解码设备200的各种操作的各种术语(诸如编码单元、深度、预测单元、变换单元和关于各种编码模式的信息)的定义与参照图1和视频编码设备100描述的各种术语的定义相同。
解析器210接收编码视频的比特流以解析句法元素。熵解码器220通过对解析的句法元素执行熵解码来对指示基于具有结构的编码单元编码的图像数据的句法元素进行算术解码,并将算术解码后的句法元素输出到分层解码器230。也就是,熵解码器220对接收的字符串0和1的形式的句法元素执行熵解码,从而重建句法元素。
另外,熵解码器220从解析的比特流,根据每个最大编码单元,提取关于具有树结构的编码单元的编码深度、编码模式、颜色分量信息、预测模式信息等的信息。提取的关于编码深度和编码模式的信息被输出到分层解码器230。比特流中的图像数据被划分为最大编码单元,使得分层解码器230可针对每个最大编码单元对图像数据进行解码。
可针对关于与编码深度相应的至少一个编码单元的信息设置关于根据最大编码单元的编码深度和编码模式的信息,关于编码模式的信息可包括关于与编码深度相应的相应编码单元的分区类型的信息、关于预测模式的信息和关于变换单元的尺寸的信息。另外,根据深度的划分信息可被提取为关于编码深度的信息。
由熵解码器220提取的关于根据每个最大编码单元的编码深度和编码模式的信息是这样的关于编码深度和编码模式的信息:该信息被确定为在编码器(诸如,视频编码设备100)根据最大编码单元对根据深度的每个较深层编码单元重复地执行编码时产生最小编码误差。因此,视频解码设备200可通过根据产生最小编码误差的编码深度和编码模式对图像数据进行解码来重建图像。
由于关于编码深度和编码模式的编码信息可被分配给相应的编码单元、预测单元和最小单元中的预定数据单元,因此熵解码器220可根据预定数据单元,提取关于编码深度和编码模式的信息。当关于相应最大编码单元的编码深度和编码模式的信息被分配每个预定数据单元时,可将被分配了相同的关于编码深度和编码模式的信息的预定数据单元推断为是包括在同一最大编码单元中的数据单元。
此外,如以下将描述的,熵解码器220可通过使用基于变换单元的变换深度确定的上下文模型来对变换单元有效系数标记cbf进行熵解码。以下将描述在熵解码器220中对与变换单元相关的句法元素进行熵解码的操作。
分层解码器230基于关于根据最大编码单元的编码深度和编码模式的信息,通过对每个最大编码单元中的图像数据进行解码,来重建当前画面。换言之,分层解码器230可基于提取出的关于包括在每个最大编码单元中的具有树结构的编码单元之中的每个编码单元的分区类型、预测模式和变换单元的信息,对编码的图像数据进行解码。解码操作可包括预测(包含帧内预测和运动补偿)和逆变换。
分层解码器230可基于关于根据编码深度的编码单元的预测单元的分区和预测模式的信息,根据每个编码单元的分区和预测模式,执行帧内预测或运动补偿。
此外,分层解码器230可基于关于根据编码深度的编码单元的变换单元的尺寸的信息,根据编码单元中的每个变换单元执行逆变换,以便根据最大编码单元执行逆变换。
分层解码器230可通过使用根据深度的划分信息来确定当前最大编码单元的至少一个编码深度。如果划分信息指示图像数据在当前深度中不再被划分,则当前深度是编码深度。因此,分层解码器230可通过使用关于预测单元的分区类型的信息、关于预测模式的信息和关于变换单元的尺寸的信息,针对当前最大编码单元的图像数据,对当前深度的编码单元进行解码。
换言之,可通过观察分配给编码单元、预测单元和最小单元中的预定数据单元的编码信息集来收集包含包括相同划分信息的编码信息的数据单元,并且收集的数据单元可被认为是将由分层解码器230以相同编码模式进行解码的一个数据单元。
视频解码设备200可获得关于当针对每个最大编码单元递归地执行编码时产生最小编码误差的至少一个编码单元的信息,并且可使用所述信息来对当前画面进行解码。换言之,被确定为每个最大编码单元中的最优编码单元的具有树结构的编码单元的编码的图像数据可被解码。
因此,即使图像数据具有高分辨率和大数据量,也可通过使用编码单元的尺寸和编码模式,对图像数据进行有效地解码和重建,其中,通过使用从编码器接收到的关于最优编码模式的信息,根据图像数据的特征自适应地确定所述编码单元的尺寸和编码模式。
现在将参照图3至图13描述根据本发明的实施例的确定具有树结构的编码单元、预测单元和变换单元的方法。
图3是用于描述根据本发明的实施例的编码单元的概念的示图。
编码单元的尺寸可被表示为宽度×高度,并可以是64×64、32×32、16×16和8×8。64×64的编码单元可被划分为64×64、64×32、32×64或32×32的分区,32×32的编码单元可被划分为32×32、32×16、16×32或16×16的分区,16×16的编码单元可被划分为16×16、16×8、8×16或8×8的分区,8×8的编码单元可被划分为8×8、8×4、4×8或4×4的分区。
关于视频数据310,分辨率1920×1080、编码单元的最大尺寸64、最大深度2被设置。关于视频数据320,分辨率1920×1080、编码单元的最大尺寸64、最大深度3被设置。关于视频数据330,分辨率352×288、编码单元的最大尺寸16、最大深度1被设置。图3中示出的最大深度表示从最大编码单元到最小编码单元的划分总次数。
如果分辨率高或数据量大,则编码单元的最大尺寸可能较大,从而不仅提高编码效率,而且准确地反映图像的特征。因此,具有比视频数据330更高分辨率的视频数据310和320的编码单元的最大尺寸可以是64。
由于视频数据310的最大深度是2,因此由于通过对最大编码单元划分两次,深度加深至两层,因此视频数据310的编码单元315可包括长轴尺寸为64的最大编码单元和长轴尺寸为32和16的编码单元。同时,由于视频数据330的最大深度是1,因此由于通过对最大编码单元划分一次,深度加深至一层,因此视频数据330的编码单元335可包括长轴尺寸为16的最大编码单元和长轴尺寸为8的编码单元。
由于视频数据320的最大深度是3,因此由于通过对最大编码单元划分三次,深度加深至3层,因此视频数据320的编码单元325可包括长轴尺寸为64的最大编码单元和长轴尺寸为32、16和8的编码单元。随着深度加深,详细信息可被精确地表示。
图4是根据本发明的实施例的基于具有分层结构的编码单元的视频编码器400的框图。
帧内预测器410针对当前帧405对帧内模式下的编码单元执行帧内预测,运动估计器420和运动补偿器425通过使用当前帧405和参考帧495分别对帧间模式下的编码单元执行帧间估计和运动补偿。
从帧内预测器410、运动估计器420和运动补偿器425输出的数据通过变换器430和量化器440被输出为量化后的变换系数。量化后的变换系数通过反量化器460和逆变换器470被重建为空间域中的数据,重建的空间域中的数据在通过去块滤波器480和环路滤波器490后处理之后被输出为参考帧495。量化后的变换系数可通过熵编码器450被输出为比特流455。
熵编码单元450对与变换单元相关的句法元素,诸如变换单元有效系数标记(cbf)、有效图、第一临界值标记(coeff_abs_level_greater1_flag)、第二临界值标记(coeff_abs_level_greather2_flag)、变换系数的大小信息(coeff_abs_level_remaining)进行算术编码,其中,cbf指示非0变换系数是否包括在变换单元中,有效图指示非0变换系数的位置,第一临界值标记指示变换系数是否具有大于1的值,第二临界值标记指示变换系数是否具有大于2的值,coeff_abs_level_remaining与基于第一临界值标记和第二临界值标记确定的基本级别(baseLevel)和实际变换系数(abscoeff)之间的差相应。
为了将视频编码器400应用到视频编码设备100中,视频编码器400的所有元件(即,帧内预测器410、运动估计器420、运动补偿器425、变换器430、量化器440、熵编码器450、反量化器460、逆变换器470、去块滤波器480和环路滤波器490)在考虑每个最大编码单元的最大深度的同时,必须基于具有树结构的编码单元中的每个编码单元执行操作。
具体地,帧内预测器410、运动估计器420和运动补偿器425在考虑当前最大编码单元的最大尺寸和最大深度的同时,确定具有树结构的编码单元中的每个编码单元的分区和预测模式,变换器430确定具有树结构的编码单元中的每个编码单元中的变换单元的尺寸。
图5是根据本发明的实施例的基于编码单元的视频解码器500的框图。
解析器510从比特流505解析将被解码的编码图像数据和解码所需的信息。编码图像数据通过解码器520和反量化器530被输出为反量化的数据。熵解码器520从比特流获得与变换单元相关的元素,即,变换单元有效系数标记(cbf)、有效图、第一临界值标记(coeff_abs_level_greater1_flag)、第二临界值标记(coeff_abs_level_greather2_flag)、变换系数的大小信息(coeff_abs_level_remaining),并对获得的句法元素进行算术编码以便重建句法元素,其中,cbf指示非0变换系数是否包括在变换单元中,有效图指示非0变换系数的位置,第一临界值标记指示变换系数是否具有大于1的值,第二临界值标记指示变换系数是否具有大于2的值,coeff_abs_level_remaining与基于第一临界值标记和第二临界值标记确定的基本级别(baseLevel)和实际变换系数(abscoeff)之间的差相应。
逆变换器540将反量化的数据重建为空间域中的图像数据。针对空间域中的图像数据,帧内预测器550对帧内模式下的编码单元执行帧内预测,运动补偿器560通过使用参考帧585对帧间模式下的编码单元执行运动补偿。
已经通过帧内预测器550和运动补偿器560的空间域中的图像数据可在通过去块滤波器570和环路滤波器580后处理之后被输出为重建帧595。另外,通过去块滤波器570和环路滤波器580后处理的图像数据可被输出为参考帧585。
为了将视频解码器500应用到视频解码设备200中,视频解码器500的所有元件(即,解析器510、熵解码器520、反量化器530、逆变换器540、帧内预测器550、运动补偿器560、去块滤波器570和环路滤波器580)针对每个最大编码单元,基于具有树结构的编码单元执行操作。
帧内预测器550和运动补偿器560确定具有树结构的每个编码单元的分区和预测模式,逆变换器540必须确定每个编码单元的变换单元的尺寸。
图6是示出根据本发明的实施例的根据深度的较深层编码单元以及分区的示图。
视频编码设备100和视频解码设备200使用分层编码单元以考虑图像的特征。可根据图像的特征自适应地确定编码单元的最大高度、最大宽度和最大深度,或可由用户不同地设置编码单元的最大高度、最大宽度和最大深度。可根据编码单元的预定最大尺寸来确定根据深度的较深层编码单元的尺寸。
在根据本发明的实施例的编码单元的分层结构600中,编码单元的最大高度和最大宽度均是64,最大深度是4。由于沿着分层结构600的垂直轴深度加深,因此较深层编码单元的高度和宽度均被划分。另外,预测单元和分区沿着分层结构600的水平轴被示出,其中,所述预测单元和分区是对每个较深层编码单元进行预测编码的基础。
换言之,在分层结构600中,编码单元610是最大编码单元,其中,深度为0,尺寸(即,高度乘宽度)为64×64。深度沿着垂直轴加深,存在尺寸为32×32和深度为1的编码单元620、尺寸为16×16和深度为2的编码单元630、尺寸为8×8和深度为3的编码单元640、尺寸为4×4和深度为4的编码单元650。尺寸为4×4和深度为4的编码单元650是最小编码单元。
编码单元的预测单元和分区根据每个深度沿着水平轴被排列。换言之,如果尺寸为64×64和深度为0的编码单元610是预测单元,则可将预测单元划分成包括在编码单元610中的分区,即,尺寸为64×64的分区610、尺寸为64×32的分区612、尺寸为32×64的分区614或尺寸为32×32的分区616。
类似地,可将尺寸为32×32和深度为1的编码单元620的预测单元划分成包括在编码单元620中的分区,即,尺寸为32×32的分区620、尺寸为32×16的分区622、尺寸为16×32的分区624和尺寸为16×16的分区626。
类似地,可将尺寸为16×16和深度为2的编码单元630的预测单元划分成包括在编码单元630中的分区,即,包括在编码度单元630中的尺寸为16×16的分区630、尺寸为16×8的分区632、尺寸为8×16的分区634和尺寸为8×8的分区636。
类似地,可将尺寸为8×8和深度为3的编码单元640的预测单元划分成包括在编码单元640中的分区,即,包括在编码单元640中的尺寸为8×8的分区、尺寸为8×4的分区642、尺寸为4×8的分区644和尺寸为4×4的分区646。
尺寸为4×4和深度为4的编码单元650是最小编码单元以及最低深度的编码单元。编码单元650的预测单元仅被分配给尺寸为4×4的分区。
为了确定构成最大编码单元610的编码单元的至少一个编码深度,视频编码设备100的分层编码器120对包括在最大编码单元610中的与每个深度相应的编码单元执行编码。
随着深度加深,包括具有相同范围和相同尺寸的数据的根据深度的较深层编码单元的数量增加。例如,需要四个与深度2相应的编码单元来覆盖包括在与深度1相应的一个编码单元中的数据。因此,为了根据深度比较对相同数据进行编码的结果,与深度1相应的编码单元和四个与深度2相应的编码单元均被编码。
为了针对深度之中的当前深度执行编码,可沿着分层结构600的水平轴,通过对与当前深度相应的编码单元中的每个预测单元执行编码,来针对当前深度选择最小编码误差。可选地,随着深度沿着分层结构600的垂直轴加深,可通过针对每个深度执行编码,并比较根据深度的最小编码误差,来搜索最小编码误差。在最大编码单元610中的具有最小编码误差的深度和分区可被选为最大编码单元610的编码深度和分区类型。
图7是用于描述根据本发明的实施例的在编码单元710和变换单元720之间的关系的示图。
视频编码设备100或视频解码设备200根据具有等于或小于最大编码单元的尺寸的编码单元,对每个最大编码单元的图像进行编码或解码。可基于不大于相应的编码单元的数据单元,来选择用于在编码期间进行变换的变换单元的尺寸。
例如,在视频编码设备100或视频解码设备200中,如果编码单元710的尺寸是64×64,则可通过使用尺寸为32×32的变换单元720来执行变换。
此外,可通过对小于64×64的尺寸为32×32、16×16、8×8和4×4的每个变换单元执行变换,来对尺寸为64×64的编码单元710的数据进行编码,然后可选择具有最小编码误差的变换单元。
图8是用于描述根据本发明的实施例的与编码深度相应的编码单元的编码信息的示图。
视频编码设备100的输出单元130可对与编码深度相应的每个编码单元的关于分区类型的信息800、关于预测模式的信息810以及关于变换单元尺寸的信息820进行编码,并将信息800、信息810和信息820作为关于编码模式的信息来发送。
信息800指示关于通过划分当前编码单元的预测单元而获得的分区的形状的信息,其中,所述分区是用于对当前编码单元进行预测编码的数据单元。例如,可将尺寸为2N×2N的当前编码单元CU_0划分成以下分区中的任意一个:尺寸为2N×2N的分区802、尺寸为2N×N的分区804、尺寸为N×2N的分区806以及尺寸为N×N的分区808。这里,关于分区类型的信息800被设置来指示以下分区中的一个:尺寸为2N×2N的分区802、尺寸为2N×N的分区804、尺寸为N×2N的分区806以及尺寸为N×N的分区808。
信息810指示每个分区的预测模式。例如,信息810可指示对由信息800指示的分区执行的预测编码的模式,即,帧内模式812、帧间模式814或跳过模式816。
信息820指示当对当前编码单元执行变换时所基于的变换单元。例如,变换单元可以是第一帧内变换单元822、第二帧内变换单元824、第一帧间变换单元826或第二帧间变换单元828。
视频解码设备200的图像数据和编码数据提取单元210可根据每个较深层编码单元,提取并使用关于编码单元的信息、关于预测模式的信息810和关于变换单元的尺寸的信息820,以进行编码。
图9是根据本发明的实施例的根据深度的较深层编码单元的示图。
划分信息可用来指示深度的改变。划分信息指示当前深度的编码单元是否被划分成更低深度的编码单元。
用于对深度为0和尺寸为2N_0×2N_0的编码单元900进行预测编码的预测单元910可包括以下分区类型的分区:尺寸为2N_0×2N_0的分区类型912、尺寸为2N_0×N_0的分区类型914、尺寸为N_0×2N_0的分区类型916和尺寸为N_0×N_0的分区类型918。图9仅示出了通过对称地划分预测单元910而获得的分区类型912至918,但是分区类型不限于此,并且预测单元910的分区可包括非对称分区、具有预定形状的分区和具有几何形状的分区。
根据每种分区类型,对尺寸为2N_0×2N_0的一个分区、尺寸为2N_0×N_0的两个分区、尺寸为N_0×2N_0的两个分区和尺寸为N_0×N_0的四个分区重复地执行预测编码。可对尺寸为2N_0×2N_0、N_0×2N_0、2N_0×N_0和N_0×N_0的分区执行帧内模式和帧间模式下的预测编码。可仅对尺寸为2N_0×2N_0的分区执行跳过模式下的预测编码。
如果在尺寸为2N_0×2N_0、2N_0×N_0和N_0×2N_0的分区类型912至916中的一个分区类型中编码误差最小,则可不将预测单元910划分到更低深度。
如果在尺寸为N_0×N_0的分区类型918中编码误差最小,则深度从0改变到1以在操作920中划分分区类型918,并对深度为2和尺寸为N_0×N_0的分区类型编码单元重复地执行编码来搜索最小编码误差。
用于对深度为1和尺寸为2N_1×2N_1(=N_0×N_0)的(分区类型)编码单元930进行预测编码的预测单元940可包括以下分区类型的分区:尺寸为2N_1×2N_1的分区类型942、尺寸为2N_1×N_1的分区类型944、尺寸为N_1×2N_1的分区类型946以及尺寸为N_1×N_1的分区类型948。
如果在尺寸为N_1×N_1的分区类型948中编码误差最小,则深度从1改变到2以在操作950中划分分区类型948,并对深度为2和尺寸为N_2×N_2的编码单元960重复地执行编码来搜索最小编码误差。
当最大深度是d时,根据每个深度的划分操作可被执行直到深度变成d-1,并且划分信息可被编码直到深度为0到d-2中的一个。换句话说,当编码被执行直到在与d-2的深度相应的编码单元在操作970中被划分之后深度是d-1时,用于对深度为d-1和尺寸为2N_(d-1)×2N_(d-1)的编码单元980进行预测编码的预测单元990可包括以下分区类型的分区:尺寸为2N_(d-1)×2N_(d-1)的分区类型992、尺寸为2N_(d-1)×N_(d-1)的分区类型994、尺寸为N_(d-1)×2N_(d-1)的分区类型996和尺寸为N_(d-1)×N_(d-1)的分区类型998。
可对分区类型992至998中的尺寸为2N_(d-1)×2N_(d-1)的一个分区、尺寸为2N_(d-1)×N_(d-1)的两个分区、尺寸为N_(d-1)×2N_(d-1)的两个分区、尺寸为N_(d-1)×N_(d-1)的四个分区重复地执行预测编码,以搜索具有最小编码误差的分区类型。
即使当尺寸为N_(d-1)×N_(d-1)的分区类型998具有最小编码误差时,由于最大深度是d,因此深度为d-1的编码单元CU_(d-1)也不再被划分到更低深度,构成当前最大编码单元900的编码单元的编码深度被确定为d-1,并且当前最大编码单元900的分区类型可被确定为N_(d-1)×N_(d-1)。此外,由于最大深度是d,因此不设置最小编码单元952的划分信息。
数据单元999可以是用于当前最大编码单元的“最小单元”。根据本发明的实施例的最小单元可以是通过将最小编码单元980划分成4份而获得的矩形数据单元。通过重复地执行编码,视频编码设备100可通过比较根据编码单元900的深度的编码误差来选择具有最小编码误差的深度以确定编码深度,并将相应分区类型和预测模式设置为编码深度的编码模式。
这样,在所有深度1至d中对根据深度的最小编码误差进行比较,并且具有最小编码误差的深度可被确定为编码深度。编码深度、预测单元的分区类型和预测模式可作为关于编码模式的信息被编码并发送。另外,由于编码单元从0的深度被划分到编码深度,因此仅编码深度的划分信息被设置为0,并且除了编码深度以外的深度的划分信息被设置为1。
视频解码设备200的熵解码器220可提取并使用关于编码单元900的编码深度和预测单元的信息,来对编码单元912进行解码。视频解码设备200可通过使用根据深度的划分信息,将划分信息为0的深度确定为编码深度,并且使用关于相应深度的编码模式的信息来进行解码。
图10至图12是用于描述根据本发明的实施例的编码单元1010、预测单元1060和变换单元1070之间的关系的示图。
编码单元1010是最大编码单元中的与由视频编码设备100确定的编码深度相应的具有树结构的编码单元。预测单元1060是每个编码单元1010中的预测单元的分区,变换单元1070是每个编码单元1010的变换单元。
当在编码单元1010中最大编码单元的深度为0时,编码单元1012和1054的深度是1,编码单元1014、1016、1018、1028、1050和1052的深度是2,编码单元1020、1022、1024、1026、1030、1032和1048的深度是3,编码单元1040、1042、1044和1046的深度是4。
在预测单元1060中,通过划分编码单元来获得一些编码单元1014、1016、1022、1032、1048、1050、1052和1054。换句话说,编码单元1014、1022、1050和1054中的分区类型的尺寸是2N×N,编码单元1016、1048和1052中的分区类型的尺寸是N×2N,编码单元1032的分区类型的尺寸就N×N。编码单元1010的预测单元和分区等于或小于每个编码单元。
在小于编码单元1052的数据单元中的变换单元1070中,对编码单元1052的图像数据执行变换或逆变换。另外,在尺寸和形状方面,变换单元1070中的编码单元1014、1016、1022、1032、1048、1050、1052和1054不同于预测单元1060中的编码单元1014、1016、1022、1032、1048、1050、1052和1054。换句话说,视频编码设备100和视频解码设备200可对同一编码单元中的数据单元独立地执行帧内预测、运动估计、运动补偿、变换和逆变换。
因此,对最大编码单元的每个区域中的具有分层结构的每个编码单元递归地执行编码来确定最优编码单元,从而可获得具有递归树结构的编码单元。编码信息可包括关于编码单元的划分信息、关于分区类型的信息、关于预测模式的信息和关于变换单元的尺寸的信息。
表1示出可由视频编码设备100和视频解码设备200设置的编码信息。
[表1]
视频编码设备100的熵编码器120可输出关于具有树结构的编码单元的编码信息,视频解码设备200的熵解码器220可从接收到的比特流提取关于具有树结构的编码单元的编码信息。
划分信息指示是否将当前编码单元划分成更低深度的编码单元。如果当前深度d的划分信息为0,则当前编码单元不再被划分成更低深度的深度是编码深度,从而可针对所述编码深度来定义关于分区类型、预测模式和变换单元的尺寸的信息。如果当前编码单元根据划分信息被进一步划分,则对更低深度的四个划分编码单元独立地执行编码。
预测模式可以是帧内模式、帧间模式和跳过模式中的一种。可针对所有分区类型定义帧内模式和帧间模式,仅针对尺寸为2N×2N的分区类型定义跳过模式。
关于分区类型的信息可指示通过对称地划分预测单元的高度或宽度而获得的尺寸为2N×2N、2N×N、N×2N和N×N的对称分区类型,以及通过非对称地划分预测单元的高度或宽度而获得的尺寸为2N×nU、2N×nD、nL×2N和nR×2N的非对称分区类型。可通过按1:n和n:1(其中,n是大于1的整数)来划分预测单元的高度来分别获得尺寸为2N×nU和2N×nD的非对称分区类型,可通过按1:n和n:1来划分预测单元的宽度来分别获得尺寸为nL×2N和nR×2N的非对称分区类型。
可将变换单元的尺寸设置成帧内模式下的两种类型和帧间模式下的两种类型。换句话说,如果变换单元的划分信息为0,则变换单元的尺寸可以是2N×2N,即当前编码单元的尺寸。如果变换单元的划分信息是1,则可通过对当前编码单元进行划分来获得变换单元。另外,如果尺寸为2N×2N的当前编码单元的分区类型是对称分区类型时,则变换单元的尺寸可以是N×N,如果当前编码单元的分区类型是非对称分区类型,则变换单元的尺寸可以是N/2×N/2。
关于具有树结构的编码单元的编码信息可包括与编码深度相应的编码单元、预测单元和最小单元中的至少一个。与编码深度相应的编码单元可包括包含相同编码信息的预测单元和最小单元中的至少一个。
因此,通过比较邻近数据单元的编码信息来确定邻近数据单元是否被包括在与编码深度相应的同一编码单元中。另外,通过使用数据单元的编码信息来确定与编码深度相应的相应编码单元,并因此可确定最大编码单元中的编码深度的分布。
因此,如果基于邻近数据单元的编码信息来对当前编码单元进行预测,则可直接参考并使用与当前编码单元邻近的较深层编码单元中的数据单元的编码信息。
可选地,如果基于邻近数据单元的编码信息来对当前编码单元进行预测,则使用数据单元的编码信息来搜索与当前编码单元邻近的数据单元,并可参考搜索到的邻近编码单元以对当前编码单元进行预测。
图13是用于描述根据表1的编码模式信息的编码单元、预测单元和变换单元之间的关系的示图。
最大编码单元1300包括编码深度的编码单元1302、1304、1306、1312、1314、1316和1318。这里,由于编码单元1318是编码深度的编码单元,因此划分信息可以被设置成0。可将关于尺寸为2N×2N的编码单元1318的分区类型的信息设置成以下分区类型中的一种:尺寸为2N×2N的分区类型1322、尺寸为2N×N的分区类型1324、尺寸为N×2N的分区类型1326、尺寸为N×N的分区类型1328、尺寸为2N×nU的分区类型1332、尺寸为2N×nD的分区类型1334、尺寸为nL×2N的分区类型1336以及尺寸为nR×2N的分区类型1338。
当分区类型被设置成对称(即,分区类型1322、1324、1326或1328)时,如果变换单元的划分信息(TU尺寸标记)为0,则设置尺寸为2N×2N的变换单元1342,如果TU尺寸标记是1,则设置尺寸为N×N的变换单元1344。
当分区类型被设置成非对称(例如,分区类型1332、1334、1336或1338)时,如果TU尺寸标记为0,则设置尺寸为2N×2N的变换单元1352,如果TU尺寸标记是1,则设置尺寸为N/2×N/2的变换单元1354。
TU尺寸标记是变换索引的类型;可根据编码单元的预测单元类型或分区类型来修改与变换索引相应的变换单元的尺寸。
当分区类型被设置成对称(即,分区类型1322、1324、1326或1328)时,如果变换单元的TU尺寸标记为0,则设置尺寸为2N×2N的变换单元1342,如果TU尺寸标记是1,则设置尺寸为N×N的变换单元1344。
当分区类型被设置成非对称(例如,分区类型1332(2N×nU)、1334(2N×nD)、1336(nL×2N)或1338(nR×2N))时,如果TU尺寸标记为0,则设置尺寸为2N×2N的变换单元1352,如果TU尺寸标记是1,则设置尺寸为N/2×N/2的变换单元1354。
参照图9,以上描述的TU尺寸标记是具有值0或1的标记,但是TU尺寸标记不限于1比特,在TU尺寸标记从0增加的同时,变换单元可被分层划分。变换单元划分信息(TU尺寸标记)可用作变换索引的示例。
在此情况下,当使用根据实施例的TU尺寸标记以及变换单元的最大尺寸和最小尺寸时,可表示实际上使用的变换单元的尺寸。视频编码设备100可对最大变换单元尺寸信息、最小变换单元尺寸信息、和最大变换单元划分信息进行编码。可将编码的最大变换单元尺寸信息、最小变换单元尺寸信息、和最大变换单元划分信息插入到序列参数集(SPS)中。视频解码设备200可使用最大变换单元尺寸信息、最小变换单元尺寸信息、和最大变换单元划分信息来进行视频解码。
例如,(a)如果当前编码单元的尺寸是64×64并且最大变换单元的尺寸是32×32,则(a-1)如果TU尺寸标记为0,则变换单元的尺寸是32×32,(a-2)如果TU尺寸标记为1,则变换单元的尺寸是16×16,(a-3)如果TU尺寸标记为2,则变换单元的尺寸是8×8。
可选地,(b)如果当前编码单元的尺寸是32×32并且最小变换单元的尺寸是32×32,则(b-1)如果TU尺寸标记为0,则变换单元的尺寸是32×32,并且由于变换单元的尺寸不能够小于32×32,因此不可设置更多的TU尺寸标记。
可选地,(c)如果当前编码单元的尺寸是64×64并且最大TU尺寸标记为1,则TU尺寸标记可以为0或1,并且不可以设置其他的TU尺寸标记。
因此,当定义最大TU尺寸标记为“MaxTransformSizeIndex”,最小TU尺寸标记为“MinTransformSize”,并且在TU尺寸标记为0的情况下的变换单元(即,根变换单元RootTu)为“RootTuSize”时,可通过以下的等式(1)来定义在当前编码单元中可用的最小变换单元的尺寸“CurrMinTuSize”。
CurrMinTuSize=max(MinTransformSize,RootTuSize/(2^MaxTransformSizeIndex))…(1)
与在当前编码单元中可用的最小变换单元的尺寸“CurrMinTuSize”相比,作为当TU尺寸标记为0时的变换单元的尺寸的根变换单元尺寸“RootTuSize”可指示对于系统可选择的最大变换单元。也就是说,根据等式(1),“RootTuSize/(2^MaxTransformSizeIndex)”是通过将作为当变换单元划分信息为0时的变换单元的尺寸的“RootTuSize”划分与最大变换单元划分信息相应的划分次数而获得的变换单元的尺寸,“MinTransformSize”是最小变换单元的尺寸,因此,“RootTuSize/(2^MaxTransformSizeIndex)”和“MinTransformSize”中较小的值可以是在当前编码单元中可用的最小变换单元的尺寸“CurrMinTuSize”。
根据本发明的实施例的根变换单元“RootTuSize”的尺寸可根据预测模式而不同。
例如,如果当前预测模式是帧间模式,则可根据以下的等式(2)来确定“RootTuSize”。在等式(2)中,“MaxTransformSize”是指最大变换单元尺寸,“PUSize”是指当前预测单元尺寸。
RootTuSize=min(MaxTransformSize,PUSize)……(2)
换句话说,如果当前预测模式是帧间模式,则作为当TU尺寸标记为0时的变换单元的根变换单元尺寸“RootTuSize”的大小可被设置为最大变换单元尺寸和当前预测单元尺寸中较小的值。
如果当前分区单元的预测模式是帧内模式,则可根据以下的等式(3)来确定“RootTuSize”。“PartitionSize”是指当前分区单元的尺寸。
RootTuSize=min(MaxTransformSize,PartitionSize)……(3)
换句话说,如果当前预测模式是帧内模式,则根变换单元尺寸“RootTuSize”可被设置为最大变换单元尺寸和当前分区单元尺寸之中较小的值。
然而,应注意,根变换单元尺寸“RootTuSize”的大小是示例,用于确定当前最大变换单元尺寸的因素不限于此,其中,根变换单元尺寸“RootTuSize”的大小是根据本发明的实施例的当前最大变换单元尺寸,并根据分区单元的预测模式而不同。
现在将详细描述由图1的视频编码设备100的熵编码器120执行的句法元素的熵编码操作,以及由图2的视频解码设备200的熵解码器220执行的句法元素的熵解码操作。
如以上所描述的,视频编码设备100和视频解码设备200通过将最大编码单元划分为等于或小于最大编码单元的编码单元来执行编码和解码。可独立于其他数据单元基于代价来确定在预测和变换中使用的预测单元和变换单元。由于可通过对包括在最大编码单元中的具有分层结构的每个编码单元进行迭代地编码来确定最佳编码单元,因此可构造具有树结构的数据单元。换句话说,对于每个最大编码单元,可构造具有树结构的编码单元、以及均具有树结构的预测单元和变换单元。对于解码,分层信息和除了分层信息之外的用于解码的非分层信息需要被发送,其中,分层信息是指示具有分层结构的数据单元的结构信息。
如以上参照图10至图12所描述的,与分层结构有关的信息是确定具有树结构的编码单元、具有树结构的预测单元和具有树结构的变换单元所需的信息,并且包括最大编码单元的尺寸信息、编码深度、预测单元的分区信息、指示编码单元是否被划分的划分标记、变换单元的尺寸信息、以及指示变换单元是否被划分为用于变换操作的更小变换单元的划分信息标记(split_transform_flag)。除了分层结构信息之外的编码信息的示例包括被应用于每个预测单元的帧内/帧间预测的预测模式信息、运动矢量信息、预测方向信息、在使用多个颜色分量的情况下被应用于每个数据单元的颜色分量信息、以及变换系数级别信息。以下,分层信息和额外的分层信息可被称为将被熵编码或熵解码的句法元素。
具体地,根据本发明的实施例,提供了一种当对多个句法元素之中的与变换单元相关的句法元素进行熵编码和熵解码时选择上下文模型的方法。现在将详细描述对与变换单元相关的句法元素进行熵编码和熵解码的操作。
图14是根据本发明的实施例的熵编码设备1400的框图。熵编码设备1400对应于图1的视频编码设备100的熵编码器120。
参照图14,熵编码设备1400包括二值化器1410、上下文建模器1420和二进制算术编码器1430。此外,二进制算术编码器1430包括常规编码引擎1432和旁路编码引擎1434。
当输入到熵编码设备1400的句法元素不是二进制值时,二值化器1410对句法元素进行二值化以输出由二进制值0和1构成的二进制位(bin)串。二进制位表示由0和1构成的流的每个比特,并通过上下文自适应二进制算术编码(CABAC)来编码。如果句法元素是具有0和1之间的相同概率的值,则句法元素被输出到不使用概率值的旁路编码引擎1434以被编码。
二值化器1410可根据句法元素的类型使用各种二值化方法。二值化方法的示例可包括一元方法、截断一元方法、截断莱斯码(truncated rice code)方法、哥伦布码(Golomb code)方法和固定长度码方法。
指示非零变换系数(以下也被称为“有效系数”)是否存在于变换单元中的变换单元有效系数标记cbf通过使用固定长度码方法被二值化。也就是说,如果非零变换系数存在于变换单元中,则变换单元有效系数标记cbf被设置为具有值1。相反,如果非零变换系数不存在于变换单元中,则变换单元有效系数标记cbf被设置为具有值0。如果图像包括多个颜色分量,则可针对每个颜色分量的变换单元来设置变换单元有效系数标记cbf。例如,如果图像包括亮度(Y)分量和色度(Cb,Cr)分量,则亮度分量的变换单元的变换单元有效系数标记cbf_luma和色度分量的变换单元的变换单元有效系数标记cbf_cb或cbf_cr可被设置。
上下文建模器1420将用于对与句法元素相应的比特串进行编码的上下文模型提供给常规编码引擎1432。更详细地讲,上下文建模器1420将用于对当前句法元素的比特串的每个二进制值进行编码的二进制值的概率输出到二进制算术编码器1430。
上下文模型是二进制位的概率模型,可包括关于0和1中的哪个与最大概率符号(MPS)和最小概率符号(LPS)相应的信息、以及MPS和LPS中的至少一个的概率信息。
上下文建模器1420可基于变换单元的变换深度来选择用于对变换单元有效系数标记cbf进行熵编码的上下文模型。如果变换单元的尺寸等于编码单元的尺寸,也就是,如果变换单元的变换深度为0,则上下文建模器1420可将预设第一上下文模型确定为用于对变换单元有效系数标记cbf进行熵编码的上下文模型。相反,如果变换单元的尺寸小于编码单元的尺寸,也就是,如果变换单元的变换深度不为0,则上下文建模器1420可将预设第二上下文模型确定为用于对变换单元有效系数标记cbf进行熵编码的上下文模型。这里,第一上下文模型和第二上下文模型基于不同的概率分布模型。也就是说,第一上下文模型和第二上下文模型是不同的上下文模型。
如上所述,当变换单元有效系数标记cbf被熵编码时,上下文建模器1420在变换单元的尺寸等于编码单元的尺寸的情况以及在变换单元的尺寸不等于编码单元的尺寸的情况下使用不同的上下文模型。如果指示用于对变换单元有效系数标记cbf进行熵编码的多个预设上下文模型中的一个的索引被称为上下文索引ctxIdx,则上下文索引ctxldx可具有通过将用于确定上下文模型的上下文增加参数ctxlnc与预设上下文索引偏移ctxIdxOffset求和而获得的值。也就是,ctxIdx=ctxInc+ctxIdxOffset。上下文建模器1420可将变换单元的变换深度为0的情况与变换单元的变换深度不为0的情况区分开,可基于变换单元的变换深度来改变用于确定上下文模型的上下文增加参数ctxlnc,并且因此可改变用于确定用于对变换单元有效系数标记cbf进行熵编码的上下文模型的上下文索引ctxldx。
更详细地,如果变换深度被称为trafodepth,则上下文建模器1420可基于以下运算来确定上下文增加参数ctxInc:
ctxInc=(trafodepth==0)?1:0
该运算可由以下伪代码来实现。
可根据亮度分量和色度分量来单独地设置变换单元有效系数标记cbf。如上所述,可通过使用根据变换单元的变换深度是否为0而改变的上下文增加参数ctxlnc来确定用于对亮度分量的变换单元的变换单元有效系数标记cbf_luma进行熵编码的上下文模型。可通过将变换深度trafodepth的值用作上下文增加参数ctxInc来确定用于对色度分量的变换单元的变换单元有效系数标记cbf_cb或cbf_cr进行熵编码的上下文模型。
常规编码引擎1432基于包括在从上下文建模器1420提供的上下文模型中的关于MPS和LPS的信息以及MPS和LPS中的至少一个的概率信息,对与句法元素相应的比特流执行二进制算术编码。
图15是示出根据本发明的实施例的对与变换单元相关的句法元素进行熵编码和熵解码的操作的流程图。
参照图15,在操作1510,对变换单元有效系数标记cbf进行初始熵编码和熵解码,其中,变换单元有效系数标记cbf指示非零变换系数是否存在于包括在当前变换单元中的多个变换系数中。如上所述,可基于变换单元的变换深度来确定用于对变换单元有效系数标记cbf进行熵编码的上下文模型,并且可基于确定的上下文模型来执行对变换单元有效系数标记cbf进行二值化算术编码。
如果变换单元有效系数标记cbf为0,则由于仅变换系数0存在于当前变换单元中,因此仅值0被熵编码或熵解码为变换单元有效系数标记cbf,并且变换系数级别信息不被熵编码或熵解码。
在操作1520,如果在当前变换单元中存在有效系数,则对指示有效系数的位置的有效图SigMap进行熵编码或熵解码。
有效图SigMap可由有效位和指示最后一个有效系数的位置的预定信息构成。有效位指示根据每个扫描索引的变换系数是有效系数还为0,并可由significant_coeff_flag[i]来表示。如稍后将描述的,以通过划分变换单元而获得的具有预定尺寸的子集为单位来设置有效图。因此,significant_coeff_flag[i]指示在子集中包括的多个变换系数之中的第i个扫描索引的变换系数是否为0,其中,所述子集包括在变换单元中。
根据传统的H.264,指示每个有效系数是否为最后一个有效系数的标记(End-of-Block(块的结束))被单独地熵编码或熵解码。然而,根据本发明的实施例,对最后一个有效系数自身的位置信息进行熵编码或熵解码。例如,如果最后一个有效系数的位置是(x,y),则可对作为指示坐标值(x,y)的句法元素的last_significant_coeff_x和last_significant_coeff_y进行熵编码或熵解码,其中,x和y是整数。
在操作1530,指示变换系数的大小的变换系数级别信息被熵编码或熵解码。根据传统H.264/AVC,由作为句法元素的coeff_abs_level_minus1来表示变换系数级别信息。根据本发明的实施例,对作为变换系数级别信息的coeff_abs_level_greater1_flag、coeff_abs_level_greater2_flag和coeff_abs_level_remaining进行编码,其中,coeff_abs_level_greater1_flag是关于变换系数的绝对值是否大于1的句法元素,coeff_abs_level_greater2_flag是关于变换系数的绝对值是否大于2的句法元素,coeff_abs_level_remaining指示剩余变换系数的大小信息。
指示剩余变换系数的大小信息的句法元素coeff_abs_level_remaining是变换系数(absCoeff)的大小和基本级别值baseLevel之间的差,其中,通过使用coeff_abs_level_greater1_flag和coeff_abs_level_greater2_flag来确定基本级别值baseLevel。根据等式baseLevel=1+coeff_abs_level_greather1_flag+coeff_abs_level_greather2_flag来确定基本级别值baseLevel,并且根据等式coeff_abs_level_remaining=absCoeff-baseLevel来确定coeff_abs_level_remaining。在coeff_abs_level_greater1_flag和coeff_abs_level_greater2_flag具有值0或1的同时,基本级别值baseLevel可具有从1到3的值。因此,coeff_abs_level_remaining可从(absCoeff-1)到(absCoeff-3)改变。如上所述,作为原始变换系数absCoeff的大小和基本级别值baseLevel之间的差的(absCoeff-baseLevel)作为变换系数的大小信息被发送,以减小发送数据的大小。
现在将描述根据本发明的实施例的确定用于对变换单元有效系数标记进行熵编码的上下文模型的操作。
图16是示出根据本发明的实施例的编码单元和包括在编码单元中的变换单元1611至1617的示图。在图16中,由虚线指示的数据单元表示编码单元,由实线指示的数据单元表示变换单元1611至1617。
如上所述,视频编码设备100和视频解码设备200通过将最大编码单元划分为具有等于或小于最大编码单元的尺寸的尺寸的编码单元来执行编码和解码。独立于其他数据单元,可基于代价来确定在预测操作中使用的预测单元和在变换操作中使用的变换单元。如果编码单元的尺寸大于视频编码设备100和视频解码设备200可使用的最大变换单元的尺寸,则编码单元可被划分为具有等于或小于最大变换单元的尺寸的尺寸的变换单元,并且可基于划分的变换单元来执行变换操作。例如,如果编码单元的尺寸是64×64并且可用的最大变换单元的尺寸是32×32,为了对编码单元进行变换(或逆变换),则编码单元被划分为具有等于或小于32×32的尺寸的变换单元。
可确定指示编码单元在水平方向和竖直方向上被划分为变换单元的次数的变换深度(trafodepth)。例如,如果当前编码单元的尺寸是2N×2N并且变换单元的尺寸是2N×2N,则可确定变换深度为0。如果变换单元的尺寸是N×N,则可确定变换深度为1。不同地,如果变换单元的尺寸为N/2×N/2,则可确定变换深度为2。
参照图16,变换单元1611、1616和1617是通过将根编码单元划分一次而获得的级别1变换单元,并且具有变换深度1。变换单元1612、1614、1614和1615是通过通过将级别1变换单元划分为4片而获得的级别2变换单元,并且具有变换深度2。
图17是示出用于基于变换深度确定图16的变换单元1611至1617中的每个的变换单元有效系数标记cbf的上下文模型的上下文增加参数ctxInc的示图。在图17的树结构中,叶节点1711至1717分别对应于图16的变换单元1611至1617,标记在叶节点1711至1717上的值0和1指示变换单元1611至1617的变换单元有效系数标记cbf。另外,在图17中,具有相同变换深度的叶节点以位于左上方、右上方、左下方和右下方的变换单元的顺序被示出。例如,图17的叶节点1712、1713、1714和1715分别对应于图16的变换单元1612、1613、1614和1615。另外,参照图16和图17,假设仅变换单元1612和1614的变换单元有效系数标记cbf是1,而其他变换单元的变换单元有效系数标记cbf为0。
参照图17,由于图16的所有的变换单元1611至1617通过划分根编码单元而获得并且因此具有非零变换深度,因此用于确定变换单元1611至1617中的每个的变换单元有效系数标记cbf的上下文模型的上下文增加参数ctxlnc被设置为具有值0。
图18是示出根据本发明的另一实施例的编码单元1811和包括在编码单元1811中的变换单元1812的示图。在图18中,由虚线指示的数据单元表示编码单元1811,由实线指示的数据单元表示变换单元1812。
参照图18,如果编码单元1811的尺寸等于用于对编码单元1811进行变换的变换单元1812的尺寸,则变换单元1812的变换深度(trafodepth)具有值0。如果变换单元1812具有变换深度0,则用于确定变换单元1812的变换单元有效系数标记cbf的上下文模型的上下文增加参数ctxlnc被设置为具有值1。
图14的上下文建模器1420基于变换单元的变换深度来将编码单元的尺寸与变换单元的尺寸进行比较,并且可将变换单元的变换深度为0的情况与变换单元的变换深度不为0的情况区分开,因此可改变用于确定用于对变换单元有效系数标记cbf进行熵编码的上下文模型的上下文增加参数ctxlnc。在变换单元的变换深度为0的情况和变换单元的变换深度不为0的情况下,通过改变用于确定上下文模型的上下文增加参数ctxlnc,可改变用于对变换单元有效系数标记cbf进行熵编码的上下文模型。
图19是示出根据本发明的实施例的用于确定包括在图16的编码单元中的变换单元的结构的划分信息标记split_transform_flag的示图。
视频编码设备100可将关于用于对每个编码单元进行变换的变换单元的结构的信息用信号传输到视频解码设备200。可通过使用指示每个编码单元是否在水平方向和竖直方向上被划分为四个变换单元的划分信息标记split_transform_flag,来用信号传输关于变换单元的结构的信息。
参照图16和图19,由于根变换单元被划分为四片,因此根变换单元的划分变换标记split_transform_flag 1910被设置为1。如果根变换单元的尺寸大于可用的最大变换单元的尺寸,则根编码单元的划分变换标记split_transform_flag 1910可总被设置为1并且可不被信号传输。这是因为,如果编码单元的尺寸大于可用的最大变换单元的尺寸,则编码单元不需要被划分为具有等于或小于至少最大变换单元的尺寸的尺寸的较深层编码单元。
针对从根编码单元划分的四个变换单元中的每个变换单元已经具有变换深度1,指示是否将四个变换单元中的每个变换单元划分为具有变换深度2的四个变换单元的划分变换标记被设置。在图19中,具有相同变换深度的变换单元的划分变换标记以位于左上方、右上方、左下方和右下方的变换单元的顺序被示出。标号1911表示图16的变换单元1611的划分变换标记。由于变换单元1611没有被划分为具有较低深度的变换单元,因此变换单元1611的划分变换标记1911具有值0。同样,由于图16的变换单元1616和1617没有被划分为具有更低深度的变换单元,因此变换单元1616的划分变换标记1913和变换单元1617的划分变换标记1914具有值0。由于图16中的具有变换深度1的右上方变换单元被划分为具有变换深度2的变换单元1612、1613、1614和1615,因此,右上方变换单元的划分变换标记1912具有变换深度1。由于具有变换深度2的变换单元1612、1613、1614和1615没有被划分为具有更低深度的变换单元,则具有变换深度2的变换单元1612、1613、1614和1615的划分变换标记1915、1916、1917和1918具有值0。
如上所述,可基于变换单元的变换深度来确定用于对变换单元有效系数标记cbf进行熵编码的上下文模型,并且可基于选择的上下文模型来对变换单元有效系数标记cbf执行二值化算术编码。如果变换单元有效系数标记cbf为0,则由于仅变换系数0存在于当前变换单元中,因此仅值0被熵编码或熵解码为变换单元有效系数标记cbf,并且变换系数级别信息不被熵编码或解码。
现在将描述对与包括在其变换单元有效系数标记cbf具有值1的变换单元(也就是,具有非零变换系数的变换单元)中的变换系数相关的句法元素进行熵编码的操作。
图20示出根据本发明的实施例被熵编码的变换单元2000。尽管图20中示出具有16×16尺寸的变换单元2000,但是变换单元2000的尺寸不限于所示出的16×16尺寸,而是还可以具有从4×4到32×32多种尺寸。
参照图20,为了对包括在变换单元2000中的变换系数进行熵编码和熵解码,变换单元2000可被划分为更小的变换单元。现在将描述对与包括在变换单元2000中的4×4变换单元2010相关的句法元素进行熵编码的操作。此熵编码操作也可被应用于不同尺寸的变换单元。
包括在4×4变换单元2010中的变换系数均具有如图20所述的变换系数(absCoeff)。包括在4×4变换单元2010中的变换系数可根据如图20所示的预定扫描顺序被串行化(serialize)并被连续处理。然而,扫描顺序不限于所示出的扫描顺序,而是也可被修改。
与包括在4×4变换单元2010中的变换系数相关的句法元素的示例是significant_coeff_flag、coeff_abs_level_greater1_flag、coeff_abs_level_greater2_flag和coeff_abs_level_remaining,其中,significant_coeff_flag是指示包括在变换单元中的每个变换系数是否是具有不为0的值的有效系数的句法元素,coeff_abs_level_greater1_flag是指示变换系数的绝对值是否大于1的句法元素,coeff_abs_level_greater2_flag是指示变换系数的绝对值是否大于2的句法元素,coeff_abs_level_remaining是指示剩余变换系数的大小信息的句法元素。
图21示出与图20的变换单元2010相应的有效图SigMap 2100。
参照图20和图21,设置针对在图20的4×4变换单元2010中包括的变换系数之中具有值不为0的有效系数之中的每个有效系数具有值1的有效图SigMap 2100。通过使用先前设置的上下文模型对有效图SigMap 2100进行熵编码或熵解码。
图22示出与图20的4×4变换单元2010相应的coeff_abs_level_greater1_flag 2200。
参照图20至图22,设置coeff_abs_level_greater1_flag 2200,其中,coeff_abs_level_greater1_flag 2200是针对有效图SigMap 2100具有值1的有效系数指示相应有效变换系数是否具有大于1的值的标记。当coeff_abs_level_greater1_flag 2200是1时,这指示相应变换系数是具有大于1的值的变换系数,而当coeff_abs_level_greater1_flag 2200为0时,这指示相应变换系数是具有值1的变换系数。在图22中,当coeff_abs_level_greater1_flag 2210位于具有值1的变换系数的位置时,coeff_abs_level_greater1_flag 2210具有值0。
图23示出与图20的4×4变换单元2010相应的coeff_abs_level_greater2_flag 2300。
参照图20至图23,设置coeff_abs_level_greater2_flag 2300,其中,coeff_abs_level_greater2_flag 2300针对其coeff_abs_level_greater1_flag 2200被设值为1的变换系数指示相应变换系数是否具有大于2的值。当coeff_abs_level_greater2_flag 2300为1时,这指示相应变换系数是具有大于2的值的变换系数,而当coeff_abs_level_greater2_flag 2300为0时,这指示相应变换系数是具有值2的变换系数。在图23中,当coeff_abs_level_greater2_flag 2310位于具有值2的变换系数的位置时,coeff_abs_level_greater2_flag 2310具有值0。
图24示出与图20的4×4变换单元2010相应的coeff_abs_level_remaining2400。
参照图20至图24,可通过计算每个变换系数的(absCoeff-baseLevel)来获得作为指示剩余变换系数的大小信息的句法元素的coeff_abs_level_remaining2400。
作为指示剩余变换系数的大小信息的句法元素coeff_abs_level_remaining2400是变换系数(absCoeff)的大小和基本级别值baseLevel之间的差,其中,通过使用coeff_abs_level_greater1_flag和coeff_abs_level_greater2_flag来确定基本级别值baseLevel。根据等式baseLevel=1+coeff_abs_level_greather1_flag+coeff_abs_level_greather2_flag来确定基本级别值baseLevel,并且根据等式coeff_abs_level_remaining=absCoeff-baseLevel来确定coeff_abs_level_remaining。
可根据示出的扫描顺序来读取coeff_abs_level_remaining 2400并对其进行熵编码。
图25是根据本发明的实施例的视频的熵编码方法的流程图。
参照图14和图25,在操作2510,上下文建模器1420获得基于变换单元而变换的编码单元的数据。在操作2520,上下文建模器1420基于变换单元的变换深度来确定用于对变换单元有效系数标记进行算术编码的上下文模型,其中,变换单元有效系数标记指示非零变换系数是否存在于变换单元中。
上下文建模器1420可在变换单元的尺寸等于编码单元的尺寸(也就是,当变换单元的变换深度为0时)的情况和在变换单元的尺寸小于编码单元的尺寸(也就是,当变换单元的变换深度不为0时)的情况下确定不同的上下文模型。更详细地,上下文建模器1420可基于变换单元的变换深度来改变用于确定上下文模型的上下文增加参数ctxlnc,可将变换单元的变换深度为0的情况与变换单元的变换深度不为0的情况区分开,并且因此可改变用于确定用于对变换单元有效系数标记进行熵编码的上下文模型的上下文索引ctxldx。
可根据亮度分量和色度分量来单独地设置变换单元有效系数标记。可通过使用根据变换单元的变换深度是否为0而改变的上下文增加参数ctxlnc来确定用于对亮度分量的变换单元的变换单元有效系数标记cbf_luma进行熵编码的上下文模型。可通过将变换深度(trafodepth)的值用作上下文增加参数ctxInc来确定用于对色度分量的变换单元的变换单元有效系数标记cbf_cb或cbf_cr进行熵编码的上下文模型。
在操作2530,常规编码引擎1432基于确定的上下文模型来对变换单元有效系数标记进行算术编码。
图26是根据本发明的实施例的熵解码设备2600的框图。熵解码设备2600对应于图2的视频解码设备200的熵解码器220。熵解码设备2600执行由以上描述的熵编码设备1400执行的熵编码操作的逆操作。
参照图26,熵解码设备2600包括上下文建模器2610、常规解码引擎2620、旁路解码引擎2630和去二值化器2640。
通过使用旁路编码而被编码的句法元素被输出到旁路解码器2630以进行算术解码,通过使用常规编码而被编码的句法元素由常规解码器2620进行算术解码。常规解码器2620基于由上下文建模器2610提供的上下文模型对当前句法元素的二进制值进行算术解码,从而输出比特串。
与如上所述的图14的上下文建模器1420类似,上下文建模器2610可基于变换单元的变换深度来选择用于对变换单元有效系数标记cbf进行熵解码的上下文模型。也就是,上下文建模器2610可在变换单元的尺寸等于编码单元的尺寸(也就是,当变换单元的变换深度为0时)的情况以及在变换单元的尺寸小于编码单元的尺寸(也就是,当变换单元的变换深度不为0时)的情况下确定不同的上下文模型。更详细地,上下文建模器2610可基于变换单元的变换深度来改变用于确定上下文模型的上下文增加参数ctxlnc,可将变换单元的变换深度为0的情况与变换单元的变换深度不为0的情况区分开,并且因此可改变用于确定用于对变换单元有效系数标记cbf进行熵解码的上下文模型的上下文索引ctxldx。
如果基于指示从比特流获得的编码单元是否被划分为变换单元的划分变换标记split_transform_flag来确定包括在编码单元中的变换单元的结构,则可基于编码单元被划分以达到变换单元的次数来确定变换单元的变换深度。
可根据亮度分量和色度分量来单独地设置变换单元有效系数标记cbf。可通过使用根据变换单元的变换深度是否为0而改变的上下文增加参数ctxlnc来确定用于对亮度分量的变换单元的变换单元有效系数标记cbf_luma进行熵解码的上下文模型。可通过将变换深度(trafodepth)的值用作上下文增加参数ctxInc来确定用于对色度分量的变换单元的变换单元有效系数标记cbf_cb或cbf_cr进行熵解码的上下文模型。
去二值化器2640再次将由常规解码引擎2620或旁路解码引擎2630算术解码的比特串重建为句法元素。
熵解码设备2600对除了变换单元有效系数标记cbf之外的与变换单元相关的句法元素(诸如coeff_abs_level_remaing、SigMap、coeff_abs_level_greater1_flag和coeff_abs_level_greater2_flag)进行算术解码,并输出解码的句法元素。当与变换单元相关的句法元素被重建时,可通过基于重建的句法元素使用反量化、逆变换和预测解码来对包括在变换单元中的数据进行解码。
图27是根据本发明的实施例的视频的熵解码方法的流程图。
参照图27,在操作2710,确定包括在编码单元中并且用于对编码单元进行逆变换的变换单元。如上所述,可基于指示从比特流获得的编码单元是否被划分为变换单元的划分变换标记split_transform_flag来确定包括在编码单元中的变换单元的结构。另外,可基于编码单元被划分以达到变换单元的次数来确定变换单元的变换深度。
在操作2720,上下文建模器2610从比特流获得指示非零变换系数是否存在于变换单元中的变换单元有效系数标记。
在操作2730,上下文建模器2610基于变换单元的变换深度来确定用于对变换单元有效系数标记进行熵解码的上下文模型。如上所述,上下文建模器2610可在变换单元的尺寸等于编码单元的尺寸(也就是,当变换单元的变换深度为0时)的情况以及在变换单元的尺寸小于编码单元的尺寸(也就是,当变换单元的变换深度不为0时)的情况下确定不同的上下文模型。更详细地,上下文建模器2610可基于变换单元的变换深度来改变用于确定上下文模型的上下文增加参数ctxlnc,可将变换单元的变换深度为0的情况与变换单元的变换深度不为0的情况区分开,并且因此可改变用于确定用于对变换单元有效系数标记进行熵解码的上下文模型的上下文索引ctxldx。
在操作2740,常规解码引擎2620基于从上下文建模器2610提供的上下文模型来对变换单元有效系数标记进行算术解码。
本发明的以上实施例可被实现为计算机可读记录介质上的计算机可读代码。计算机可读记录介质是能够存储其后可由计算机系统读取的数据的任何数据存储装置。计算机可读记录介质的示例包括只读存储器(ROM)、随机存取存储器(RAM)、CD-ROM、磁带、软盘和光数据存储装置。计算机可读记录介质还可分布在联网的计算机系统上,从而计算机可读代码以分布式方式被存储和执行。
虽然已经参照本发明的示例性实施例具体示出并描述了本发明,但是本领域普通技术人员将理解,在不脱离由权利要求限定的本发明的精神和范围的情况下,可做出形式和细节上的各种改变。
- 还没有人留言评论。精彩留言会获得点赞!