一种视频编码方法和设备与流程
本发明涉及视频领域,特别涉及一种视频编码方法和设备。
背景技术:
通常,在视频编码过程中,包括MPEG系列和H.26X系列在内的现有的技术都是以像素为处理单位,实现对视频进行编码。
由于像素是视频帧的基本组成单位,视频帧中包含了大量的像素,从而使得在采用现有技术的方法进行视频的编码时,需要对视频帧中包含的大量的像素数据进行处理,数据处理量较大,从而降低了视频编码效率,另外,由于数据处理量较大,使得在传输编码后的视频时,码流数据较大,从而占用的大量的带宽资源。
技术实现要素:
为了减少视频传输时所占用的带宽,节省带宽资源,本发明实施例提供了一种视频编码方法和设备。所述技术方案如下:
第一方面,提供了一种视频编码方法,所述方法包括:
获取当前视频帧内的对象;
根据先前视频帧和所述先前视频帧之前的场景进行场景重建,生成重建后的场景;
对所述当前视频帧内的对象以及所述重建后的场景进行匹配,生成匹配视频帧;以及
根据所述当前视频帧与所述匹配视频帧之间的残差数据,对所述当前视频 帧进行编码,生成编码数据。
结合第一方面,在第一种可能的实现方式中,所述获取当前视频帧内的对象包括:
利用显著性,对所述当前视频帧内的对象进行检测;以及
在检测到所述对象后,对所述对象进行分割,从所述当前视频帧中获取所述对象。
结合第一方面或第一方面的第一种可能的实现方式,在第二种可能的实现方式中,所述根据先前视频帧和所述先前视频帧之前的场景进行场景重建,生成重建后的场景包括:
根据所述先前视频帧和所述先前视频帧之前的场景,对摄像头姿态进行估计,生成用于描述摄像头姿态的第一参数,以及对景深进行估计,生成用于描述景深的第二参数;
根据所述第一参数,对所述先前视频帧和所述先前视频帧之前的场景进行图像拼接,生成拼接后的图像;以及
根据所述拼接后的图像和所述第二参数进行场景重建,生成所述重建后的场景。
结合第一方面至第一方面的第二种任意一种可能的实现方式,在第三种可能的实现方式中,所述对所述当前视频帧内的对象以及所述重建后的场景进行匹配,生成匹配视频帧之前,所述方法还包括:
根据所述先前视频帧之前的场景的姿态参数,调整所述重建后的场景的姿态参数。
结合第一方面至第一方面的第三种任意一种可能的实现方式,在第四种可能的实现方式中,所述对所述当前视频帧内的对象以及所述重建后的场景进行匹配,生成匹配视频帧包括:
利用最邻近搜索,对所述当前视频帧内的对象以及所述重建后的场景进行匹配,生成匹配视频帧。
结合第一方面至第一方面的第四种任意一种可能的实现方式,在第五种可能的实现方式中,所述对所述当前视频帧内的对象以及所述重建后的场景进行匹配,生成匹配视频帧之后,所述方法还包括:
根据所述先前视频帧,对所述匹配视频帧进行运动补偿。
结合第一方面至第一方面的第五种任意一种可能的实现方式,在第六种可能的实现方式中,所述对所述当前视频帧内的对象以及所述重建后的场景进行匹配,生成匹配视频帧之后,所述方法还包括:
根据所述先前视频帧,对所述匹配视频帧进行光照估计。
结合第一方面至第一方面的第六种任意一种可能的实现方式,在第七种可能的实现方式中,所述根据所述当前视频帧与所述匹配视频帧之间的残差数据,对所述当前视频帧进行编码之前,所述方法包括:
对所述残差数据进行变换和量化。
结合第一方面的第七种可能的实现方式,在第八种可能的实现方式中,在所述变换和量化步骤之后,所述方法还包括:
对所述残差数据进行反量化和逆变换;以及
根据所述残差数据与所述匹配视频帧,生成当前视频帧的重建帧,用作下一次场景重建时的初始数据。
结合第一方面至第一方面的第八种任意一种可能的实现方式,在第九种可能的实现方式中,所述根据所述当前视频帧与所述匹配视频帧之间的残差数据,对所述当前视频帧进行编码之后,所述方法还包括:
向视频解码方发送所述重建后的场景和所述编码数据。
第二方面,提供了一种视频编码设备,所述视频编码设备包括:
获取模块,用于获取当前视频帧内的对象;
场景重建模块,用于根据先前视频帧和所述先前视频帧之前的场景进行场景重建,生成重建后的场景;
匹配模块,用于对所述当前视频帧内的对象以及所述重建后的场景进行匹 配,生成匹配视频帧;以及
编码模块,用于根据所述当前视频帧与所述匹配视频帧之间的残差数据,对所述当前视频帧进行编码,生成编码数据。
结合第二方面,在第一种可能的实现方式中,所述获取模块用于:
利用显著性,对所述当前视频帧内的对象进行检测;以及
在检测到所述对象后,对所述对象进行分割,从所述当前视频帧中获取所述对象。
结合第二方面或第二方面的第一种可能的实现方式,在第二种可能的实现方式中,所述场景重建模块用于:
根据所述先前视频帧和所述先前视频帧之前的场景,对摄像头姿态进行估计,生成用于描述摄像头姿态的第一参数,以及对景深进行估计,生成用于描述景深的第二参数;
根据所述第一参数,对所述先前视频帧和所述先前视频帧之前的场景进行图像拼接,生成拼接后的图像;以及
根据所述拼接后的图像和所述第二参数进行场景重建,生成重建后的场景。
结合第二方面至第二方面的第二种任意一种可能的实现方式,在第三种可能的实现方式中,所述设备还包括处理模块,用于:
根据所述先前视频帧之前的场景的姿态参数,调整所述重建后的场景的姿态参数。
结合第二方面至第二方面的第三种任意一种可能的实现方式,在第四种可能的实现方式中,所述匹配模块用于:
利用最邻近搜索,对所述当前视频帧内的对象以及所述重建后的场景进行匹配,生成匹配视频帧。
结合第二方面至第二方面的第四种任意一种可能的实现方式,在第五种可能的实现方式中,所述处理模块还用于:
根据所述先前视频帧,对所述匹配视频帧进行运动补偿。
结合第二方面至第二方面的第五种任意一种可能的实现方式,在第六种可能的实现方式中,所述处理模块还用于:
根据所述先前视频帧,对所述匹配视频帧进行光照估计。
结合第二方面至第二方面的六种任意一种可能的实现方式,在第七种可能的实现方式中,所述处理模块还用于:
对所述残差数据进行变换和量化。
结合第二方面的第七种可能的实现方式,在第八种可能的实现方式中,所述处理模块还用于:
对所述残差数据进行反量化和逆变换;以及
根据所述残差数据与所述匹配视频帧,生成当前视频帧的重建帧,用作下一次场景重建时的初始数据。
结合第二方面至第二方面的第八种任意一种可能的实现方式,在第九种可能的实现方式中,所述视频编码设备还包括发送模块,用于:
向视频解码方发送所述重建后的场景和所述编码数据。
第三方面,提供了一种视频编码设备,所述视频编码设备包括存储器以及与所述存储器连接的处理器,其中,所述存储器用于存储一组程序代码,所述处理器调用所述存储器所存储的程序代码用于执行以下操作:
获取当前视频帧内的对象;
根据先前视频帧和所述先前视频帧之前的场景进行场景重建,生成重建后的场景;
对所述当前视频帧内的对象以及所述重建后的场景进行匹配,生成匹配视频帧;以及
根据所述当前视频帧与所述匹配视频帧之间的残差数据,对所述当前视频帧进行编码,生成编码数据。
结合第三方面,在第一种可能的实现方式中,所述处理器调用所述存储器所存储的程序代码用于执行以下操作:
利用显著性,对所述当前视频帧内的对象进行检测;以及
在检测到所述对象后,对所述对象进行分割,从所述当前视频帧中获取所述对象。
结合第三方面或第三方面的第一种可能的实现方式,在第二种可能的实现方式中,所述处理器调用所述存储器所存储的程序代码用于执行以下操作:
根据所述先前视频帧和所述先前视频帧之前的场景,对摄像头姿态进行估计,生成用于描述摄像头姿态的第一参数,以及对景深进行估计,生成用于描述景深的第二参数;
根据所述第一参数,对所述先前视频帧和所述先前视频帧之前的场景进行图像拼接,生成拼接后的图像;以及
根据所述拼接后的图像和所述第二参数进行场景重建,生成所述重建后的场景。
结合第三方面至第三方面的第二种任意一种可能的实现方式,在第三种可能的实现方式中,所述处理器调用所述存储器所存储的程序代码用于执行以下操作:
根据所述先前视频帧之前的场景的姿态参数,调整所述重建后的场景的姿态参数。
结合第三方面至第三方面的第三种任意一种可能的实现方式,在第四种可能的实现方式中,所述处理器调用所述存储器所存储的程序代码用于执行以下操作:
利用最邻近搜索,对所述当前视频帧内的对象以及所述重建后的场景进行匹配,生成匹配视频帧。
结合第三方面至第三方面的第四种任意一种可能的实现方式,在第五种可能的实现方式中,所述处理器调用所述存储器所存储的程序代码用于执行以下操作:
根据所述先前视频帧,对所述匹配视频帧进行运动补偿。
结合第三方面至第三方面的第五种任意一种可能的实现方式,在第六种可能的实现方式中,所述处理器调用所述存储器所存储的程序代码用于执行以下操作:
根据所述先前视频帧,对所述匹配视频帧进行光照估计。
结合第三方面至第三方面的第六种任意一种可能的实现方式,在第七种可能的实现方式中,所述处理器调用所述存储器所存储的程序代码用于执行以下操作:
对所述残差数据进行变换和量化。
结合第三方面的第七种可能的实现方式,在第八种可能的实现方式中,所述处理器调用所述存储器所存储的程序代码用于执行以下操作:
对所述残差数据进行反量化和逆变换;以及
根据所述残差数据与所述匹配视频帧,生成当前视频帧的重建帧,用作下一次场景重建时的初始数据。
结合第三方面至第三方面的第八种任意一种可能的实现方式,在第九种可能的实现方式中,所述处理器调用所述存储器所存储的程序代码用于执行以下操作:
向视频解码方发送所述重建后的场景和所述编码数据。
本发明实施例提供了一种视频编码方法和设备,包括:获取当前视频帧内的对象;根据先前视频帧和先前视频帧之前的场景进行重建,生成重建后的场景;对当前视频帧内的对象以及重建后的场景进行匹配,生成匹配视频帧;根据当前视频帧与匹配视频帧之间的残差数据,对当前视频帧进行编码,生成编码数据。通过将对当前视频帧内的对象以及重建后的场景进行匹配,生成匹配视频帧,实现了基于对象的视频编码,减少了视频传输时所占用的带宽,节省了带宽资源,同时使得可以在带宽资源较低的情况下实现视频的传输,以便在网络环境较差的情况下仍然可以实现即时视频,提高了用户体验。另外,由于减少了视频传输时所占用的带宽,节省了带宽资源,从而保证了在视频传输过 程中通过较小的带宽即可保证视频的流畅性和视频的清晰度,提高了用户体验。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明实施例提供的一种视频编码方法流程图;
图2是本发明实施例提供的一种视频编码方法流程图;
图3是本发明实施例提供的一种视频编码设备结构示意图;
图4是本发明实施例提供的一种视频编码设备结构示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明实施例提供了一种视频编码方法,该方法应用于视频文件和/或流媒体视频传输过程中的编码,该流媒体包括即时视频交互过程中的即时视频和其他流媒体,除了视频文件和/或流媒体之外,本发明实施例所述的方法还可以应用其他视频的编码,本发明实施例对具体的视频不加以限定。
其中,本发明所述的对象可以为视频帧画面内系统指定或者用户自定义的人或物,该对象可以用多个特征点进行描述,本发明所述的场景为视频帧画面内除对象之外的其余部分,在即时视频过程中,由于视频双方对视频中的人体部分,尤其是人脸的关注度高于其他区域,所以通常该对象可以为即时视频中 的人脸,除此之外,该对象还可以为即时视频过程中视频双方所定义的其他物体或者双方身体的其他部位,本发明实施例对具体的对象不加以限定。
需要说明的是,在执行本发明实施例所述的方法之前,视频数据已经传输一帧完整的视频帧,该完整的视频帧包括对象数据以及场景数据,该完整的视频帧可以为视频的初始帧,也可以为视频的初始帧之后的视频帧,本发明实施例对具体的视频帧不加以限定。
实施例一为本发明实施例提供的一种视频编码方法,参照图1所示,该方法包括:
101、获取当前视频帧内的对象。
具体的,利用显著性,对当前视频帧内的对象进行检测;
在检测到对象后,对对象进行分割,从当前视频帧中获取对象。
102、根据先前视频帧和先前视频帧之前的场景进行场景重建,生成重建后的场景。
具体的,根据先前视频帧和先前视频帧之前的场景,对摄像头姿态进行估计,生成用于描述摄像头姿态的第一参数,以及对景深进行估计,生成用于描述景深的第二参数;
其中,假设当前视频帧为第n帧视频帧,根据先前视频帧和先前视频帧之前的场景对摄像头姿态进行估计,生成用于描述摄像头姿态的第一参数的过程可以是根据n-2帧对应的场景和n-1帧对摄像头姿态进行估计,生成用于描述摄像头姿态的第一参数;同理,对景深进行估计,生成用于描述景深的第二参数的过程可以是根据n-2帧对应的场景和n-1帧对景深进行估计,生成用于描述景深的第二参数;
根据第一参数,对先前视频帧和先前视频帧之前的场景进行图像拼接,生成拼接后的图像;以及
根据拼接后的图像和第二参数进行场景重建,生成重建后的场景。
其中,假设当前视频帧为第n帧视频帧,对先前视频帧和先前视频帧之前 的场景进行图像拼接,生成拼接后的图像的过程可以是对n-2帧对应的场景和n-1帧进行图像拼接,生成拼接后的图像。
值得注意的是,步骤101至步骤102除了所述过程所述的执行步骤之外,还可以同时执行,还可以先执行步骤102,再执行步骤101,本发明实施例对步骤101与步骤102的执行顺序不加以限定。
可选的,在步骤102之后,还可以包括以下步骤:
根据先前视频帧之前的场景的姿态参数,调整重建后的场景的姿态参数。
103、对当前视频帧内的对象以及重建后的场景进行匹配,生成匹配视频帧。
具体的,利用最邻近搜索,对当前视频帧内的对象以及重建后的场景进行匹配,生成匹配视频帧。
可选的,在步骤103之后,还可以包括以下步骤:
根据先前视频帧,对匹配视频帧进行运动补偿。
可选的,在步骤103之后,还可以包括以下步骤:
根据先前视频帧,对匹配视频帧进行光照估计。
104、根据当前视频帧与匹配视频帧之间的残差数据,对当前视频帧进行编码,生成编码数据。
可选的,在步骤104之前,步骤103之后,还可以包括以下步骤:
对残差数据进行变换和量化。
可选的,在变换和量化之后,还可以包括以下步骤:
对残差数据进行反量化和逆变换;以及
根据残差数据与匹配视频帧,生成当前视频帧的重建帧,用作下一次场景重建时的初始数据。
可选的,在步骤104之后,还可以包括以下步骤:
向视频解码方发送重建后的场景和编码数据。
本发明实施例提供了一种视频编码方法,通过将对当前视频帧内的对象以及重建后的场景进行匹配,生成匹配视频帧,实现了基于对象的视频编码,相 比于直接传输当前视频帧,减少了视频传输时所占用的带宽,节省了带宽资源,同时使得可以在带宽资源较低的情况下实现视频的传输,以便在网络环境较差的情况下仍然可以实现即时视频,提高了用户体验。另外,由于减少了视频传输时所占用的带宽,节省了带宽资源,从而保证了在视频传输过程中通过较小的带宽即可保证视频的流畅性和视频的清晰度,提高了用户体验。
实施例二为本发明实施例提供的一种视频编码方法,参照图2所示,该方法包括:
201、获取当前视频帧内的对象。
具体的,根据显著性,对当前频帧内的对象进行检测,该过程可以为:
对当前视频帧进行边界检测;
在对当前视频帧进行边界检测之后,提取对象的特征数据;
对对象的特征数据进行分类,该过程可以是通过支持向量机(SVM,Support Vector Machine)实现的;
按照分类后的特征数据,对当前视频帧进行分割,获取至少一个分割结果;
对至少一个分割结果进行排序,并根据排序结果确定检测结果;
根据该检测结果,获取当前视频帧内的对象;
在获取当前视频帧的对象之后,还可以对对象进行跟踪和姿态估计,本发明实施例对具体的跟踪方法和姿态估计方法不加以限定。
由于在即时视频过程中,用于对人脸所在的区域的兴趣度大于其他区域,所以对应的,该其他区域的兴趣度较小,通过以人脸作为对象,以不包括人脸的区域作为场景进行编码,使得在视频传输过程中,无需传输全部的场景数据,相比于直接传输当前视频帧,减少了视频传输时所占用的带宽,节省了带宽资源。另外,通过用户自定义对象,实现了视频过程中,尤其是在即时视频过程中,可以基于对方或者视频的双方都感兴趣的对象进行编码,满足了用户的个性化需求,提高了用户体验。
202、根据先前视频帧和先前视频帧之前的场景,对摄像头姿态进行估计, 生成用于描述摄像头姿态的第一参数,以及对景深进行估计,生成用于描述景深的第二参数。
具体的,该过程可以为:
根据先前视频帧和先前视频帧之前的场景,对摄像头姿态进行估计,生成用于描述当前视频帧的摄像头姿态的第一参数;
根据先前视频帧和先前视频帧之前的场景,对景深进行估计,生成用于描述当前视频帧的景深的第二参数。
其中,假设当前视频帧为第n帧视频帧,根据先前视频帧和先前视频帧之前的场景对摄像头姿态进行估计,生成用于描述摄像头姿态的第一参数的过程可以是根据n-2帧对应的场景和n-1帧对摄像头姿态进行估计,生成用于描述摄像头姿态的第一参数;根据先前视频帧和先前视频帧之前的场景对景深进行估计,生成用于描述景深的第二参数的过程可以是根据n-2帧对应的场景和n-1帧对景深进行估计,生成用于描述景深的第二参数;
对摄像头姿态进行估计和对景深进行估计的过程可以是利用预设算法实现的,示例性的,该算法可以为:Large-Scale Direct Monocular SLAM大规模直接单目视觉SLAM算法,其中SLAM为:simultaneous localization and mapping即时定位与地图构建。
所述实现过程仅仅是示例性的,还可以通过其他方式实现该过程,本发明实施例对具体的实现方式不加以限定。
由于摄像头姿态和景深能够真实地描述视频帧的场景,所以通过对摄像头姿态和景深进行估计,使得重建后的场景与视频帧的真实场景相近或者相同,从而增加了场景的真实感,更进一步的提高了用户体验。
203、根据第一参数,对先前视频帧和先前视频帧之前的场景进行图像拼接,生成拼接后的图像。
具体的,根据第一参数,对先前视频帧和先前视频帧之前的场景进行图像拼接,该拼接过程可以为:
根据单应性矩阵,用content-preserving warping方法对图像进行局部对齐,得到拼接后的图像,该图像为先前视频帧和先前视频帧之前的场景的图像拼接而成的图像;
其中,单应性矩阵即为第一参数。
上述拼接方式仅仅是示例性的,还可以通过其他方式实现该过程,本发明实施例对具体的方式不加以限定。
本发明实施例对具体的调整方式不加以限定。
其中,假设当前视频帧为第n帧视频帧,对先前视频帧和先前视频帧之前的场景进行图像拼接,生成拼接后的图像的过程可以是对n-2帧对应的场景和n-1帧进行图像拼接,生成拼接后的图像。
由于第一参数用于描述摄像头姿态,所以通过对摄像头姿态进行估计,使得重建后的场景与视频帧的真实场景相近或者相同,从而增加了场景的真实感,更进一步的提高了用户体验。
204、根据拼接后的图像和第二参数,对包含先前视频帧的场景进行重建,生成重建后的场景。
具体的,根据第二参数,对拼接后的图像进行转换,并根据转换后的图像,对包含先前视频帧的场景进行重建,生成重建后的场景。
上述过程可以是通过预设的场景重建模型实现的,也可以通过预设的场景重建算法实现的,本发明实施例对具体的实现方式不加以限定。
通过对先前视频帧的场景进行重建,使得在视频传输过程中,无需传输全部的场景数据,减少了视频传输时所占用的带宽,节省了带宽资源。
值得注意的是,步骤202至步骤204是实现根据先前视频帧和先前视频帧之前的场景进行场景重建,生成重建后的场景的过程,除了所述步骤所述的方式之外,还可以通过其他方式实现该过程,本发明实施例对具体的方式不加以限定。
205、根据先前视频帧之前的场景的姿态参数,调整重建后的场景的姿态参 数。
具体的,获取先前视频帧之前的场景的姿态参数;
根据该先前视频帧之前的场景的姿态参数,使用仿射变换算法对重建后的场景的姿态参数进行调整。
所述仿射变换算法仅仅是示例性的,还可以通过其他方式实现该过程,本发明实施例对具体的调整方式不加以限定。
由于视频在连续的几帧内场景数据是相对稳定的,所以通过根据先前视频帧之前的场景的姿态参数,调整重建后的场景数据的姿态参数,从而进一步增加了场景的真实感,更进一步的提高了用户体验。
其中,步骤205是可选步骤,在实际应用中,在步骤204之后,可以不执行步骤205,直接执行步骤206。
206、对当前视频帧内的对象以及重建后的场景进行匹配,生成匹配视频帧。
具体的,利用最邻近搜索,对当前视频帧内的对象以及重建后的场景进行匹配,生成匹配视频帧。
所述最邻近搜索的过程可以通过计算描述对象的特征点以及描述场景的特征点之间的欧式距离,并选择欧式距离最短为搜索条件。
由于重建后的场景数据相比于真实的场景数据而言,数据量较小,所以通过对当前视频帧内的对象以及重建后的场景进行匹配,生成匹配视频帧,并在编码和传输过程中,对匹配视频帧进行编码和传输,使得在视频传输过程中,无需传输全部的场景数据,减少了视频传输时所占用的带宽,节省了带宽资源。
207、根据先前视频帧,对匹配视频帧进行运动补偿。
具体的,根据先前视频帧的初始数据,对匹配视频帧内像素点或者像素块的分布进行线性补偿,以实现对匹配视频帧进行运动补偿,本发明实施例对具体的运动补偿过程不加以限定。
由于视频在连续的几帧内是相关的,所以通过对匹配视频帧进行运动补偿,消除了在数据编码和传输过程中的空域冗余,减少了数据处理量,进一步减少 了视频传输时所占用的带宽,节省了带宽资源。
其中,步骤207是可选步骤,在实际应用中,在步骤206之后,可以不执行步骤207,直接执行步骤209。
208、根据先前视频帧,对匹配视频帧进行光照估计。
具体的,根据先前视频帧,对匹配视频帧内的光照数据进行估计,以实现进行光照估计,其中,该估计过程可以是通过计算YUV空间Y的均值来实现的,本发明实施例对具体的光照估计过程不加以限定。
其中,光照数据包括光照强度和光照方向等。
由于视频在连续的几帧内是相关的,所以通过对匹配视频帧进行光照估计,减少了光照数据处理时的数据处理量,进一步减少了视频传输时所占用的带宽,节省了带宽资源。
其中,步骤208是可选步骤,在实际应用中,在步骤206之后,可以不执行步骤208,直接执行步骤209。
209、获取当前视频帧与匹配视频帧之间的残差数据。
具体的,所述前视频帧与匹配视频帧之间的残差数据是当前视频帧与匹配视频帧之间的差值,该获取过程可以是通过预设的残差计算算法实现的,本发明实施例对具体的算法不加以限定,除了预设算法之外,还可以通过其他方式实现该过程,本发明实施例对具体的获取方式不加以限定。
210、对残差数据进行变换和量化。
具体的,可以根据编码过程中的数据的相关性,对残差数据进行变换,在实际应用中,可以采用傅里叶变换、小波变换以及离散余弦变换等变换方式实现对残差数据的变换,本发明实施例对具体的变换方式不加以限定。
对残差数据进行量化,并对量化后的残差数据进行重排序,该量化过程可以通过预设的窗口函数实现,也可以通过其他方式实现,本发明实施例对具体的实现方式不加以限定。
通过对残差数据进行变换,并对量化后的残差数据进行重排序,使得可以 利用数据的相关性进行编码,从而降低了数据编码过程中的数据处理量,从而进一步减少了视频传输时所占用的带宽,节省了带宽资源。
其中,步骤210是可选步骤,在步骤209之后,可以不执行步骤210,直接执行步骤212。
需要说明的是,在步骤210之后,可并行执行步骤211和213。
211、对残差数据进行反量化和逆变换。
具体的,该反量化和逆变换过程是步骤210所述的变换和量化过程的逆过程,本发明实施例对具体的实现方式不加以限定。
212、根据残差数据与匹配视频帧,生成当前视频帧的重建帧,用作下一次场景重建时的初始数据。
根据残差数据与匹配视频帧,生成当前视频帧的重建帧的过程可以通过预设算法实现,本发明实施例对具体的预设算法不加以限定。
其中,步骤211是可选步骤,在实际应用中,在步骤209之后,可以不执行步骤211,直接执行步骤212。
213、根据残差数据,对当前视频帧进行编码,生成编码数据。
具体的,对残差数据以及描述数据进行编码,在实际应用中,可以采用哈夫曼编码以及算术编码等编码方式实现该对残差数据以及描述数据的编码,本发明实施例对具体的编码过程不加以限定。
214、向视频解码方发送重建后的场景和编码数据。
具体的,向视频解码方发送用于描述该重建后的场景的数据和编码数据,该用于描述该重建后的场景的数据包括第一参数、第二参数以及对象分割信息,以及用于描述匹配视频帧的场景数据的姿态参数的描述数据等。
该发送过程可以是通过视频方与视频解码方之间连接的通信链路实现的,本发明实施例对具体的发送方式不加以限定。
由于先前视频帧的场景已经发送至解码方,所以通过将用于描述重建后的场景的数据发送至视频解码方,使得解码方可以根据该用于描述重建后的场景 的数据,生成重建后的场景,相比于直接将重建后的场景发送至解码方,进一步减少了视频传输时所占用的带宽,节省了带宽资源。
其中,步骤214是可选步骤,在实际应用中,如果编码后的视频是以视频文件形式存储的,则无需向视频解码方发送重建后的场景和编码数据,而是将重建后的场景和编码数据存储在视频文件中。
本发明实施例提供了一种视频编码方法,通过将对当前视频帧内的对象以及重建后的场景进行匹配,生成匹配视频帧,实现了基于对象的视频编码,相比于直接传输当前视频帧,减少了视频传输时所占用的带宽,节省了带宽资源,同时使得可以在带宽资源较低的情况下实现视频的传输,以便在网络环境较差的情况下仍然可以实现即时视频,提高了用户体验。另外,由于减少了视频传输时所占用的带宽,节省了带宽资源,从而保证了在视频传输过程中通过较小的带宽即可保证视频的流畅性和视频的清晰度,提高了用户体验。另外,由于在即时视频过程中,用于对人脸所在的区域的兴趣度大于其他区域,所以对应的,该其他区域的兴趣度较小,通过以人脸作为对象,以不包括人脸的区域作为场景进行编码,使得在视频传输过程中,无需传输全部的场景数据,减少了视频传输时所占用的带宽,节省了带宽资源。另外,由于摄像头姿态和景深能够真实地描述视频帧的场景,所以通过对摄像头姿态和景深进行估计,使得重建后的场景与视频帧的真实场景相近或者相同,从而增加了场景的真实感,更进一步的提高了用户体验。另外,通过对当前视频帧的场景进行重建,使得在视频传输过程中,无需传输全部的场景数据,减少了视频传输时所占用的带宽,节省了带宽资源。另外,由于重建后的场景数据相比于真实的场景数据而言,数据量较小,所以通过对当前视频帧内的对象以及重建后的场景进行匹配,生成匹配视频帧,并在编码和传输过程中,对匹配视频帧进行编码和传输,使得在视频传输过程中,无需传输全部的场景数据,减少了视频传输时所占用的带宽,节省了带宽资源。另外,由于视频在连续的几帧内场景数据是相对稳定的,所以通过根据先前视频帧的姿态参数,调整匹配视频帧的场景数据的姿态参数, 从而进一步增加了场景的真实感,更进一步的提高了用户体验。另外,由于视频在连续的几帧内场景数据是相对稳定的,通过获取用于描述匹配视频帧的场景数据的姿态参数的描述数据,使得在视频解码方发送该描述数据后,根据该描述数据和之前已经接收到的场景数据,即可生成当前视频帧的场景,从而在视频传输过程中,只需传输该描述数据,无需传输场景数据,进一步减少了视频传输时所占用的带宽,节省了带宽资源。另外,由于视频在连续的几帧内是相关的,所以通过对匹配视频帧进行运动补偿,消除了在数据编码和传输过程中的空域冗余,减少了数据处理量,进一步减少了视频传输时所占用的带宽,节省了带宽资源。另外,通过对残差数据进行变换,并对量化后的残差数据进行重排序,使得可以利用数据的相关性进行编码,从而降低了数据编码过程中的数据处理量,从而进一步减少了视频传输时所占用的带宽,节省了带宽资源。
实施例三为本发明实施例提供的一种视频编码设备,参照图3所示,该视频编码设备包括:
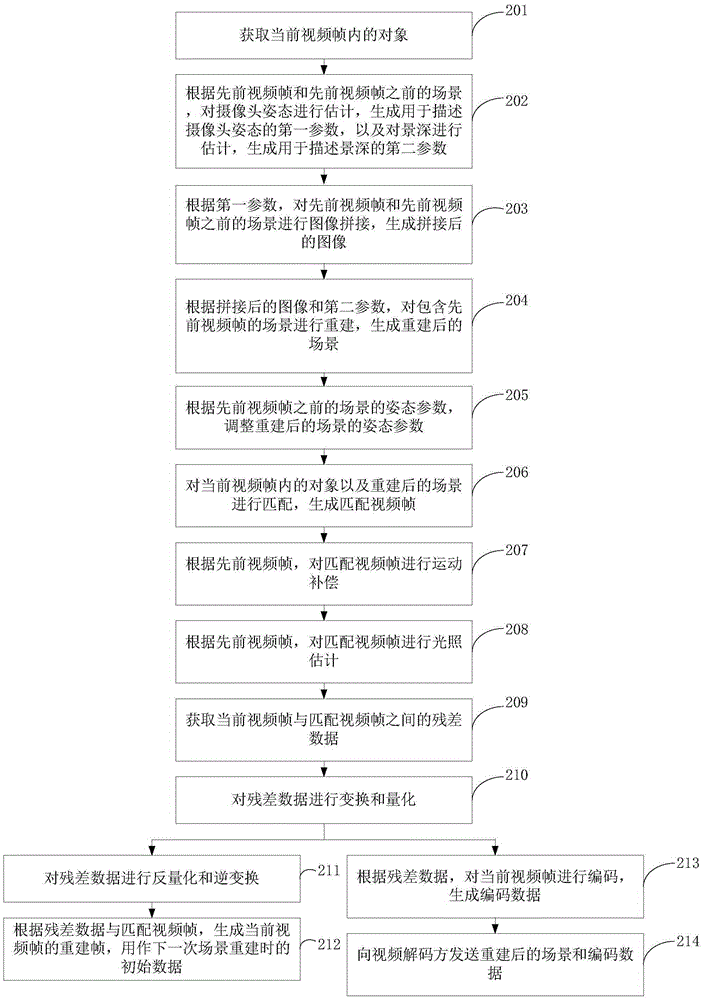
获取模块31,用于获取当前视频帧内的对象;
场景重建模块32,用于根据先前视频帧和先前视频帧之前的场景进行场景重建,生成重建后的场景;
匹配模块33,用于对当前视频帧内的对象以及重建后的场景进行匹配,生成匹配视频帧;以及
编码模块34,用于根据当前视频帧与匹配视频帧之间的残差数据,对当前视频帧进行编码,生成编码数据。
可选的,获取模块31用于:
利用显著性,对当前视频帧内的对象进行检测;以及
在检测到对象后,对对象进行分割,从当前视频帧中获取对象。
可选的,场景重建模块32用于:
根据先前视频帧和先前视频帧之前的场景,对摄像头姿态进行估计,生成用于描述摄像头姿态的第一参数,以及对景深进行估计,生成用于描述景深的 第二参数;
其中,假设当前视频帧为第n帧视频帧,对先前视频帧和先前视频帧之前的场景进行对摄像头姿态进行估计,生成用于描述摄像头姿态的第一参数的过程可以是根据n-2帧对应的场景和n-1帧对摄像头姿态进行估计,生成用于描述摄像头姿态的第一参数;同理,对景深进行估计,生成用于描述景深的第二参数的过程可以是对n-2帧对应的场景和n-1帧对应的场景对景深进行估计,生成用于描述景深的第二参数;
根据第一参数,对先前视频帧和先前视频帧之前的场景进行图像拼接,生成拼接后的图像;以及
根据拼接后的图像和第二参数进行场景重建,生成重建后的场景。
其中,假设当前视频帧为第n帧视频帧,对先前视频帧和先前视频帧之前的场景进行图像拼接,生成拼接后的图像的过程可以是对n-2帧对应的场景和n-1帧进行图像拼接,生成拼接后的图像。
可选的,视频编码设备3还包括处理模块35,用于:
根据先前视频帧之前的场景的姿态参数,调整重建后的场景的姿态参数。
可选的,匹配模块33用于:
利用最邻近搜索,对当前视频帧内的对象以及重建后的场景进行匹配,生成匹配视频帧。
可选的,处理模块35还用于:
根据先前视频帧,对匹配视频帧进行运动补偿。
可选的,处理模块35还用于:
根据先前视频帧,对匹配视频帧进行光照估计。
可选的,处理模块35还用于:
对残差数据进行变换和量化。
可选的,处理模块35还用于:
对残差数据进行反量化和逆变换;以及
根据残差数据与匹配视频帧,生成当前视频帧的重建帧,用作下一次场景重建时的初始数据。
可选的,视频编码设备3还包括发送模块36,用于:
向视频解码方发送重建后的场景和编码数据。
本发明实施例提供了一种视频编码设备,该视频编码设备通过将对当前视频帧内的对象以及重建后的场景进行匹配,生成匹配视频帧,实现了基于对象的视频编码,相比于直接传输当前视频帧,减少了视频传输时所占用的带宽,节省了带宽资源,同时使得可以在带宽资源较低的情况下实现视频的传输,以便在网络环境较差的情况下仍然可以实现即时视频,提高了用户体验。另外,由于减少了视频传输时所占用的带宽,节省了带宽资源,从而保证了在视频传输过程中通过较小的带宽即可保证视频的流畅性和视频的清晰度,提高了用户体验。
实施例四为本发明实施例提供的一种视频编码设备,参照图4所示,该视频编码设备包括存储器41以及与存储器连接的处理器42,其中,存储器41用于存储一组程序代码,处理器42调用存储器41所存储的程序代码用于执行以下操作:
获取当前视频帧内的对象;
根据先前视频帧和所述先前视频帧之前的场景进行场景重建,生成重建后的场景;
对当前视频帧内的对象以及重建后的场景进行匹配,生成匹配视频帧;以及
根据当前视频帧与匹配视频帧之间的残差数据,对当前视频帧进行编码,生成编码数据。
可选的,处理器42调用存储器41所存储的程序代码用于执行以下操作:
利用显著性,对当前视频帧内的对象进行检测;以及
在检测到对象后,对对象进行分割,从当前视频帧中获取对象。
可选的,处理器42调用存储器41所存储的程序代码用于执行以下操作:
根据先前视频帧和先前视频帧之前的场景,对摄像头姿态进行估计,生成用于描述摄像头姿态的第一参数,以及对景深进行估计,生成用于描述景深的第二参数;
其中,假设当前视频帧为第n帧视频帧,根据先前视频帧和先前视频帧之前的场景对摄像头姿态进行估计,生成用于描述摄像头姿态的第一参数的过程可以是根据n-2帧对应的场景和n-1帧对摄像头姿态进行估计,生成用于描述摄像头姿态的第一参数;同理,对景深进行估计,生成用于描述景深的第二参数的过程可以是根据n-2帧对应的场景和n-1帧对景深进行估计,生成用于描述景深的第二参数;
根据第一参数,对先前视频帧和先前视频帧之前的场景进行图像拼接,生成拼接后的图像;以及
根据拼接后的图像和第二参数进行场景重建,生成重建后的场景。
其中,假设当前视频帧为第n帧视频帧,对先前视频帧和先前视频帧之前的场景进行图像拼接,生成拼接后的图像的过程可以是对n-2帧对应的场景和n-1帧进行图像拼接,生成拼接后的图像。
可选的,处理器42调用存储器41所存储的程序代码用于执行以下操作:
根据先前视频帧之前的场景的姿态参数,调整重建后的场景的姿态参数。
可选的,处理器42调用存储器41所存储的程序代码用于执行以下操作:
利用最邻近搜索,对当前视频帧内的对象以及重建后的场景进行匹配,生成匹配视频帧。
可选的,处理器42调用存储器41所存储的程序代码用于执行以下操作:
根据先前视频帧,对匹配视频帧进行运动补偿。
可选的,处理器42调用存储器41所存储的程序代码用于执行以下操作:
根据先前视频帧,对匹配视频帧进行光照估计。
可选的,处理器42调用存储器41所存储的程序代码用于执行以下操作:
对残差数据进行变换和量化。
可选的,处理器42调用存储器41所存储的程序代码用于执行以下操作:
对残差数据进行反量化和逆变换;以及
根据残差数据与匹配视频帧,生成当前视频帧的重建帧,用作下一次场景重建时的初始数据。
可选的,处理器42调用存储器41所存储的程序代码用于执行以下操作:
向视频解码方发送重建后的场景和编码数据。
本发明实施例提供了一种视频编码设备,该视频编码设备通过将对当前视频帧内的对象以及重建后的场景进行匹配,生成匹配视频帧,实现了基于对象的视频编码,相比于直接传输当前视频帧,减少了视频传输时所占用的带宽,节省了带宽资源,同时使得可以在带宽资源较低的情况下实现视频的传输,以便在网络环境较差的情况下仍然可以实现即时视频,提高了用户体验。另外,由于减少了视频传输时所占用的带宽,节省了带宽资源,从而保证了在视频传输过程中通过较小的带宽即可保证视频的流畅性和视频的清晰度,提高了用户体验。
上述所有可选技术方案,可以采用任意结合形成本发明的可选实施例,在此不再一一赘述。
需要说明的是:上述实施例提供的视频编码设备在执行视频编码方法,仅以上述各功能模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能模块完成,即将设备的内部结构划分成不同的功能模块,以完成以上描述的全部或者部分功能。另外,上述实施例提供的视频编码设备与视频编码方法实施例属于同一构思,其具体实现过程详见方法实施例,这里不再赘述。
本领域普通技术人员可以理解实现上述实施例的全部或部分步骤可以通过硬件来完成,也可以通过程序来指令相关的硬件完成,所述的程序可以存储于一种计算机可读存储介质中,上述提到的存储介质可以是只读存储器,磁盘或 光盘等。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!