使用通信来定位声音并提供实时世界坐标的系统和方法与流程
本申请涉及于2014年1月23日提交的标题为“SYSTEM AND METHOD FOR MAPPING AND DISPLAYING AUDIO SOURCE LOCATIONS”的美国申请序列No.14/162,355和于2013年3月1日提交、在2014年4月22日以专利No.8,704,070颁发的标题为“SYSTEM AND METHOD FOR MAPPING AND DISPLAYING AUDIO SOURCE LOCATIONS”的美国申请序列No.13/782,402,所有申请由与本申请相同的发明人发明并通过引用被全部并入本文。
发明领域
本申请大体上涉及声音管理和声音定位的领域,其涉及在一个或多个限定的区域中定位声源。更具体地,本发明涉及用于声音管理和声音定位并提供预定位置的物理布局的细节、收听者的静态或动态位置和也用于区分开电子生成的声音和人类声音(例如,有声发出、说话等)的改进的技术的方法和装置。
背景
存在使用在预定区域中的麦克风来提高声音质量的很多实现。例如,当娱乐系统被首先实现时,住宅娱乐系统使用中央麦克风来收听由住宅用户布置在房间中的每个扬声器;在这样的系统中,麦克风收听来自每个扬声器的声音且处理器确定大概的物理布置。从所确定的布置中,娱乐系统调节每个扬声器的输出特性,使得优化的声音质量可由在预定位置处的用户体验,一般是在麦克风在测试期间所放置的地方的用户。其它系统可使用麦克风(定向、全向等)的阵列来在更复杂的布景中实现类似的结果。
虽然麦克风可在布置中被设计和利用以接近在预定区域中的扬声器的物理位置,但每个扬声器的精确位置常常难以得到。此外,因为预定区域常常比简单的盒式布置更复杂,所以关于预定区域的很多因素和特性对于扬声器位置的确定常常不被知道或说明。例如,很少的位置(诸如房间或场地)具有特定的或纯粹的几何结构配置;常常有切断区、加热和通风阻碍物和可影响声波越过区域和在整个区域中的传输的其它结构包含物。这一般也可导致扬声器放置的人为错误或可导致承包方将扬声器放置在对于结构放置比对于声音质量更方便的位置上。此外,这些系统常常导致声音质量的单个优选点,其可被限制到例如在较大地点中的多个用户、家具布局被修改的住宅情况以及甚至收听者在房间内移动的情况。此外,这些系统一般导致与从系统生成的电子声音相关联的声波。
因此,希望的是具有用于声音定位的改进的技术,声音定位提供预定位置的物理布局的细节、收听者的静态或动态位置且也用于区分开电子地生成的声音和人类声音(例如,有声发出、说话等)。此外,希望有额外提供使用语音识别技术来识别一个或多个人在预定区域中的存在的这样的提高的技术。本发明解决这样的需要。
概述
本发明实现这些需要并响应于本领域现状且特别是响应于在本领域中的还没有由当前可用的技术完全解决的问题和需要而被发展。
本发明的一个实施方式提供用于提高声音定位和检测的方法,其包括:输入预定位置的维度数据和对于在预定位置中的一个或多个检测设备的位置参考数据;识别由一个或多个检测设备检测的声音;以及将声音定位信息提供到一个或多个接收源;其中声音定位信息包括与一个或多个检测设备和检测到的声音有关的定位和位置信息,检测到的声音与预定位置的维度数据相关联。
本发明的另一实施方式提供存储在计算机可用介质上的计算机程序产品,其包括:用于使计算机控制应用的执行以进行用于改进声音定位和检测的方法的计算机可读程序装置,该方法包括:输入预定位置的维度数据和对于在预定位置中的一个或多个检测设备的位置参考数据;识别由一个或多个检测设备检测的一个或多个声音;以及将声音定位信息提供给一个或多个用户。
另一实施方式提供用于改进声音定位的系统,其包括:一个或多个检测设备,其布置在预定位置中,直接与位置的物理维度表示相关联;一个或多个处理器,其用于处理检测与参考声音特性有关的在预定位置中的一个或多个声音,并用于映射与预定位置的维度数据有关的检测到的一个或多个声音以用于显示;与一个或多个处理器通信的一个或多个检测设备;使检测到的声音和反射声音的到达的时间差关联的分析器;以及用于提供声音定位信息以用于显示的通信接口。
如在本文使用的,术语“麦克风”意图包括可包括阵列的一个或多个麦克风。
从通过示例示出本发明的原理的结合附图的下面的详细描述中,本发明的其它方面和优点将变得明显。
附图的简要说明
图1呈现预定区域(诸如在住宅中的房间)的一般布置。
图2根据一个或多个实施方式阐述用于根据本发明的系统和方法的操作的流程图。
图3示出根据本发明的一个或多个实施方式的适合于存储计算机程序产品和/或执行程序代码的数据处理系统。
优选实施方式的详细描述
本发明大体上涉及用于声音定位的改进技术的方法和布置,其提供预定位置的物理布局的细节、收听者的静态或动态位置和也用于区分开电子地生成的声音和人类声音。如在本文使用的确定和处理可包括语音识别技术和软件的使用和应用。本发明还提供使用语音识别技术来识别一个或多个人在预定区域中的存在。
下面的描述被提出以使本领域中的技术人员能够制造和使用本发明,并在专利申请及其要求的环境中被提供。对优选实施方式的各种修改和本文所述的一般原理和特征对本领域中的技术人员将是明显的。因此,本发明并不旨在受限于所示的实施方式,但应被给予与本文所述的原理和特征一致的最宽范围。
图1呈现预定区域110(诸如在住宅中的房间)的一般布置100。房间的物理尺寸可从实际测量或更优选地从建筑呈现或蓝图(在其中房间正被或已被构建)来确定。常常,在预定区域的配置已具有与它相关联的一些复杂度的场合,蓝图是优选的,这是由于蓝图一般也将包括结构、材料、其它基础设施系统(即电、水等)的细节和可影响在预定区域内的声音质量的其它方面。
在本发明的一个或多个实施方式中,从蓝图中做出关于在哪里寻找声音检测、监控和/或发出的确定。例如,从图1中,声音需要在120处识别的房间中被监控,因为这被识别为婴儿的房间。类似地,从图1中,声音也需要是在130(起居室)处的焦点,其中希望有来自娱乐系统的最佳的声音质量。在120和130处,还需要识别出在这些房间中存在人类语音以及电子声音,并能够区分开这两种类型。
麦克风被放置在需要具有与它相关联的声音检测、监控和/或发出的每个房间中。将容易认识到,根据特定的需要或情况,将一个或多个麦克风放置于在蓝图上识别的每个房间中可能是有利的。然后确定麦克风的放置,其中每个麦克风的2D和3D坐标实际上由物理测量确定,或实质上经由一个或多个相关联处理器对被传输以用于由麦克风接收的声波的检测来确定,声波与每个相应的麦克风有关。每个麦克风的这些所确定位置直接与蓝图相关联,使得每个麦克风具有与它相关的一组蓝图坐标。
从图1中,麦克风阵列可放置在房间120中的121-124处和房间130的131-134处,但是根据本发明的系统和方法既不被这样限制也不取决于这个示例性描述。每个所放置的麦克风具有与它相关联并被放置到与其相关联的数据库内的蓝图坐标(X,Y,Z)。
从图1中,在操作中,根据本发明的系统和方法在一个或多个实施方式中将通常利用在预定位置中的一个麦克风或麦克风的阵列,直到确定声音被检测到或存在利用多个麦克风的需要为止。例如,一旦根据本发明的系统和方法在房间120中是可操作的,可能确定只有麦克风121是活动的且开启的,同时麦克风122-124保持被动。然而,当检测到声音(诸如非人类生成的声音)出现时,根据本发明的系统和方法可立即激活麦克风122-124,使得它们是活动的,可由一个或多个麦克风确定检测到的声音位于哪里,并可将所确定信息传输到接收源。
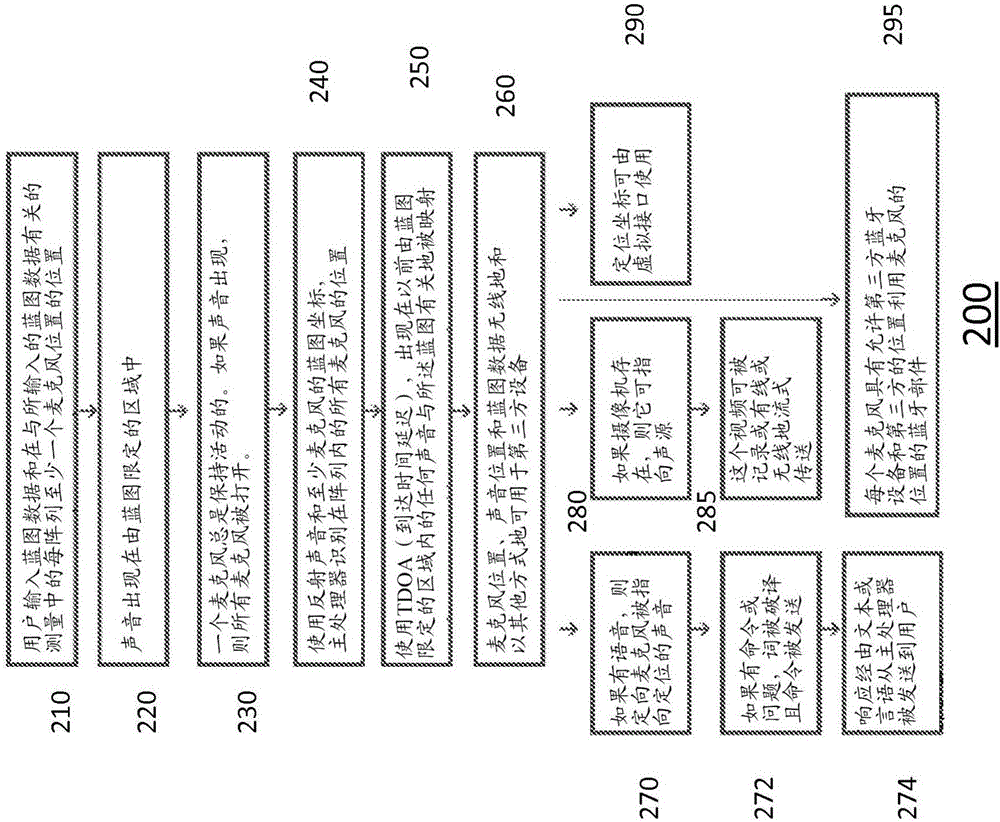
图2根据本发明的一个或多个实施方式阐述用于根据本发明的系统和方法的操作的流程图200。
从图2中,在210处提供一个或多个预定位置的蓝图数据连同与蓝图数据相关联的至少一个麦克风的位置数据。优选地,使蓝图尺寸和麦克风位置相关联的数据被存储在由根据本发明的系统和方法可访问的数据库中。在220处,根据本发明的系统和方法提供由在预定位置中的一个或多个活动的麦克风检测一个或多个声音。在230处,当由活动的麦克风检测到声音时,如果有也在预定区域中的被动或不活动的麦克风,则那些被动或不活动的麦克风也都被打开。优选地,根据本发明的系统和方法可经由可以是直接的、间接的或远程的通信命令来激活被动或不活动的检测设备(麦克风、摄像机、致动器等),并可包括中央服务器、中央处理单元(CPU)、计算机或实现数据信号到要打开的被动或不活动的设备的传输的其它设备。在操作上,通过具有单个活动麦克风,可经由根据本发明的系统和方法来减小功率消耗和资源要求。
在240处,根据本发明的系统和方法然后使用反射声音确定技术和在预定区域中的至少一个麦克风的蓝图坐标来确定在预定位置中的阵列内的所有麦克风的位置。优选地,使用反射声音来测量在每个活动麦克风处的检测到的声音和反射声音之间的时间差提供由根据本发明的系统和方法进行的处理以确定在预定位置中的麦克风的X、Y和Z坐标。优选地,根据本发明的系统和方法在240处使用来自蓝图和麦克风位置的以前存储的数据以及经由反射声音技术来确定所有麦克风的位置;在操作上,这种方法是有利的,因为常常只有单个麦克风的位置可能以前是已知的,或麦克风(和其它检测设备)可为了方便而不时地移动。
在250处,根据本发明的系统和方法使用到达时间延迟(TDOA)技术来映射与预定位置的蓝图数据有关的一个或多个检测到的声音。在260处,根据本发明的系统和方法通过诸如无线通信系统的通信机构或经由有线系统将所确定的信息提供到接收源。根据本发明的系统和方法不限于将所确定信息传递到接收源的特定方式。
在260处,根据本发明的系统和方法已经确定何种声音和声音的类型已被确定(即人类、电子地生成的等)。优选地,声音的类型(如人类或非人类)的确定与由一个或多个麦克风检测的声音的声音特性比较由根据本发明的系统和方法确定,其中电子地生成的或不是电子地生成的声音的确定可容易被确定。
在270处,在语音声音已被检测到的情况下,根据本发明的系统和方法布置可存在于预定位置中的定向麦克风以朝着检测到的声音聚焦。在272处,根据本发明的系统和方法还基于检测到的声音的特性来确定检测到的声音是否是命令或是否与问题的形式相关联并可此外检测额外的声音。例如,命令可包括但不限于词(诸如接通、断开、打开、关闭等),且可以用任何语言。命令(通用或特定的)可以是由根据本发明的系统和方法可容易访问的数据库的部分。类似地,发声模式可以是由根据本发明的系统和方法可访问的数据库的部分,其中检测到的语音声音可由根据本发明的系统和方法确定以形成在其中寻求答复的问题。在一个或多个优选实施方式中,根据本发明的系统和方法还可包括在274处以动作、文本、网页或链接的供应、电子地生成的答复的形式或类似形式直接或间接地提供对问题的答案的能力;此外,根据本发明的系统和方法可能能够将问题提交到次级源,诸如具有语音激活的操作系统的智能电话,所以次级源可对问题作出响应。
在优选实施方式中,根据本发明的系统和方法包括也存在于预定位置中的摄像机和致动设备(锁、电机、接通/断开开关等),且每个具有与它们相关联的蓝图坐标集。在280处,在声音的检测被识别出之后,致动设备可开始响应于检测到的声音而被启动,诸如将摄像机转向声源并激活摄像机以在282处无线地或有线地提供、记录、传输并以其他方式提供影像。
在290处,在由根据本发明的系统和方法检测的信息的映射之后,定位坐标可以由视觉界面利用。例如,在一个或多个实施方式中,一旦声音被检测到且信息被映射,特定房间和检测设备(麦克风、摄像机等)的位置的映射就可在智能电话上或经由URL链路被发送给用户用于访问,其中用户可观看激活并基于所接收的信息来做出适当的决定。
在295处,在一个或多个优选实施方式中,检测设备可包括发送、接收、收发器能力。这些能力可包括但不限于例如蓝牙,其中在预定位置上的一个或多个检测设备可进一步检测其它可连接的设备,使得这些其它可连接的设备可被连接到根据本发明的系统和方法,且它们的特征、特性和数据收集能力也可被使用和/或结合到根据本发明的系统和方法内以进一步帮助声音检测、声音识别、声音定位、声音管理、通信和散播。
根据本发明的系统和方法还适合于涉及人类生活的安全的救援和紧急情况。例如,在预定位置中的受伤的人可在特定的房间内大声呼救。受伤的人的大声呼叫由根据本发明的系统和方法检测为人类语音。响应于由受伤的人大声呼叫,系统可接着与适当的接收源(用户、紧急联系人、警察、计算机等)通信以传递信息和/或所确定的信息的映射。作为响应,接收源可接着按所接收的信息行动。
类似地,当火灾出现时,例如响应紧急人员可接收信息的映射,其中仍然在建筑物中的人的坐标集被识别出并与他们在住宅或建筑物中的特定位置相关联。此外,也可确定检测到的人是否是直立的或在向下的位置上,这是由于三维坐标信息可用于每个人。这样的信息可帮助紧急人员在响应中优先考虑行动的计划。
根据本发明的系统和方法提供经由一个或多个处理器的处理以检测并确定来自与一个或多个处理器通信的一个或多个检测设备的一个或多个声音。在一个或多个优选实施方式中处理还提供噪声消除技术以及不是检测的目标的反射声音和白噪声的消除。一个或多个处理也可与一个或多个可连接的设备通信,并被设想为与智能家庭、智能系统等集成在一起。
将认识到,根据本发明的系统和方法可被集成并适合于与用于限定参考声音位置并产生与在预定位置处的一个或多个声音特性有关的接近其的标记的方法一起合作,诸如在标题为“System and Method for Mapping and Displaying Audio Source Locations”的有关的美国申请序列No.13/782,402中所公开的。优选地,组合方法包括:定义待检测的至少一个声音特性;检测与至少一个声音特性有关的至少一个目标声音;以及确定与检测到的目标声音有关的参考声音位置,使检测到的声音与预定位置的维度细节相关联,并显示与预定位置的维度有关的检测到的一个或多个声音。
图3示出根据本发明的一个或多个实施方式的适合于存储计算机程序产品和/或执行程序代码的数据处理系统300。数据处理系统300包括通过系统总线306耦合到存储器元件304a-b的处理器302。在其它实施方式中,数据处理系统300可包括多于一个处理器,且每个处理器可通过系统总线直接或间接地耦合到一个或多个存储器元件。
存储器元件304a-b可包括在程序代码的实际执行期间采用的本地存储器、大存储器和缓存存储器,其提供至少一些程序代码的临时存储以便减少代码在执行期间必须从大存储器取回的次数。如所示,输入/输出或I/O设备308a-b(包括但不限于键盘、显示器、定点设备等)被耦合到数据处理系统300。I/O设备308a-b可通过中间I/O控制器(未示出)直接或间接地耦合到数据处理系统300。
此外,在图3中,网络适配器310被耦合到数据处理系统302以使数据处理系统300能够变得通过通信链路312耦合到其它数据处理系统或远程打印机或储存设备。通信链路312可以是私有或公共网络。调制解调器、电缆调制解调器和以太网卡仅仅是当前可用类型的网络适配器中的几个。
此外,在一个或多个优选实施方式中,图3的数据处理系统300还可包括根据本发明的一个或多个实施方式的适合于执行程序代码的逻辑和控制器。
例如,数据处理系统300可包括在302处的多个处理器,其中每个处理器可以预处理、处理或后处理关于检测设备、可连接的设备和与预定位置有关并与根据本发明的系统和方法的声音检测相关联的其它数据收集设备所接收或传输的数据(诸如但不限于检测设备信息、数据和传感器数据)。
多个处理器可关于它们利用根据本发明的系统和方法的处理通过系统总线306耦合到存储器元件304a-b。多个输入/输出或I/O设备308a-b可根据相应的处理器直接地或通过中间I/O控制器(未示出)间接地耦合到数据处理系统300。这样的I/O设备的例子可包括但不限于麦克风、麦克风阵列、声学摄像机、声音检测设备、光检测设备、致动设备、智能电话、基于传感器的设备等。
在一个或多个优选实施方式中,对根据本发明的系统和方法有效的软件可以是应用、远程软件或在计算机、智能电话或其它基于计算机的设备上可操作。例如,从诸如检测设备(例如,麦克风阵列)的声源检测的声音可与根据本发明的系统和方法一起使用,其中本发明的软件被布置成检测来自检测设备的声音,确定检测到的声音的类型,激活其它检测设备,确定与预定位置的维度数据有关的检测到的声音或声音位置,并提供经处理的确定作为声音定位信息,其可用作文本、超链接、基于web的三维或二维影像等。根据本发明的系统和方法能够根据本发明的一个或多个实施方式向远程设备或经由所链接的显示器提供视觉图像,包括声音定位细节的映射。设想当前的设备可在几乎任何环境和应用中使用,包括涉及但不限于娱乐、住宅使用、商业使用、紧急和政府应用、交互式电子和虚拟论坛、国土安全需要等的那些。
在另一布置中,声学摄像机和视频摄像机可用作额外的检测设备或作为可连接的设备。
系统、程序产品和方法提供用于改进的声音定位,其提供预定位置的物理布局的细节、收听者的静态或动态位置,以及也用于区分开电子地生成的声音和人类声音。根据本发明的系统和方法还提供用于使用语音识别技术来识别一个或多个人在预定区域中的存在。
在所述实施方式中,系统和方法可包括任何电路、软件、过程和/或方法,包括例如对现有的软件程序的改进。
虽然根据所示实施方式描述了本发明,但本领域中的技术人员将容易认识到,可以有对实施方式的变型,且那些变型将在本发明的精神和范围内,诸如包括电路、电子设备、控制系统和其它电子器件和处理设备。相应地,很多修改可由本领域中的技术人员做出而不偏离所附权利要求的精神和范围。也可设想本发明的很多其它实施方式。
在本文陈述的任何理论、操作机制、证据或发现意在进一步增强本发明的理解,且并不旨在以任何方式根据这样的理论、操作机制、证据或发现来制造本发明。应理解,虽然在上面的描述中更可取的、更合意的或优选的词的使用指示这样描述的特征可能是更合乎需要的,然而它不是必不可少的,且缺乏其的实施方式可被设想在本发明的范围内,该范围由接下来的权利要求限定。
- 还没有人留言评论。精彩留言会获得点赞!