基于HEVC的分层深度视频残差层数据的编码方法与流程
本发明涉及一种基于HEVC的分层深度视频残差层数据的编码方法,使得编码残差数据所需的比特数在减小的同时,尽量减少绘制的虚拟视点伪影的出现。
背景技术:
三维立体电视(3DTV)系统利用人的双眼观察物体角度的差异而辨识物体的远近这个原理,将编码后的3D视频传入人的左右眼,使观众在观看节目的同时可以体验到立体感。当前,三维视频格式包括传统立体视频表示法(Conventional stereo video,CSV)、单视点视频加深度表示法(Video-plus-depth,V+D)、多视点视频表示法(Multi-view video,MVV)和多视点视频加深度表示法(Multi-view video plus depth,MVD)。CSV表示法捕获并且传输一个视频序列对,二者具有与人眼相近的视差,在解码成像端还原捕获的场景,便可还原3D场景。它最大的优点在于其简单的原理和实现,缺点是由于只传输两路视频,接收端不能进行视角的调整设置。V+D表示法采用视频序列和相应的深度序列组合的方法来表示。该方法由于只提供了一个视点的纹理加深度序列,在终端显示的时候需要基于深度的虚拟视点绘制技术(Depth image based rendering,DIBR)得到一个虚拟视点,从而在终端显示时还原3D场景。由于能够根据不同的视角绘制出不同的虚拟视图,V+D表示法相对于传统立体视频表示法具有很大的灵活性,接收端可以进行一定的配置优化,观看者也能够调整视角而不仅仅局限于视频采集的视角。但是这种方法也存在很大的缺陷,其绘制出的虚拟视图的质量不高,存在大量的空洞、裂纹和伪影。与CSV相比,MVV表示法能够使观察者在投影区变换观看的位置,从而能够实现视角的切换,但这种方法的缺点是它需要传输多路数据,所以需要处理的数据量非常大。MVD表示法可以很好解决这个问题,MVD表示法也是传输彩色视频序列和相应的深度图序列,通过深度图绘制出某些虚拟视点再用于显示。与V+D不同的是,MVD传输多路的视频和深度序列,多路视频中的信息互补,从而使绘制的虚拟视点的质量较单向绘制的质量大大提高;但相邻的两个参考视点仍然存在很多重复的部分,对每个参考视点全部传输实际上传输了很多冗余信息。
分层深度视频(Layered depth video,LDV)源于MVD,其实质是MVD的稀疏表示形式,即在对MVD视频压缩编码之前进行预处理、以减少用于编码的数据量。LDV的改进之处在于,其传输的序列包含主视点完整的彩色序列和深度序列,其他的视点则只传输残差数据。残差数据是指主视点投影到虚拟视点上无法覆盖的区域,而辅助视点投影过去能够覆盖的部分。具体来说,就是将主视点投影到两边视点位置产生虚拟视点,由于视差和遮挡的原因,遮挡区域会重新的暴露出来产生空洞区域。分别将两边的原始视点与对应生成的虚拟视点相减,生成残差数据。由于残差的数据量很小,能够避免传输大量的冗余信息,进一步减少了需要传输的数据量。图1是LDV数据生成及绘制显示的过程。
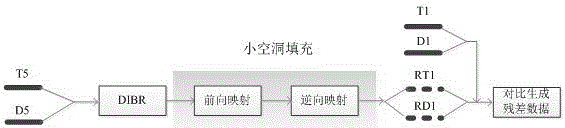
残差层数据的生成主要由投影、小空洞填充和比较三个步骤完成,如图2所示。首先,将主视点V5通过DIBR技术投影到两个侧视点V1和V9位置,生成的虚拟视点RV1和RV9。在投影过程中,由于视角的不同和前景对背景的遮挡等原因使得某些区域在参考视点V5中不可见,却在虚拟视点中可见,从而产生空洞区域。同时,某些小的未覆盖的区域也变得可见,产生很多小的空洞和裂纹。对于一般只有1个像素宽的较小裂纹,可以通过中值滤波器对背景区域深度值进行预处理,这样既可以消除噪声又可以保存图像的细节。然而,中值滤波虽然简单,但其作用有限,无法较好地填补合成图像中的较大裂缝;反向投影可以提供比中值滤波更好的填洞效果。因此,先正向映射得到虚拟视点的纹理图和深度图,对该深度图进行中值滤波,并对经过滤波填充的空洞点进行标记,然后对标记过的点进行逆向映射到参考视点下搜索对应坐标点,以搜索到的像素填补当前虚拟视点的较大裂纹。最后将经过预处理后的RV1和V1,RV9和V9分别进行对应像素的比较,如果发现RV1和RV9的像素不存在,则将V1或V9对应的像素值保存为残差数据。反之,V1和V9对应的像素值无用,即保存为空白区域。以Ballet序列为例,最终生成的纹理和深度的残差数据如图3所示。
随着视频应用的多样化和高清、超高清视频趋势,对视频压缩性能提出了更高的要求,视频编码联合组(JCT-VC)制定了新一代视频编码标准H.265/HEVC。在HEVC中,图像可以被划分为若干个互不重叠的编码树单元(Coding tree unit,CTU),在CTU的内部,采用基于四叉树的循环分层结构。同一层次上的编码单元具有相同的分割深度。一个CTU可能只包含一个CU(即没有进行划分),也可能被划分为多个CU,如图4所示。具体判断每个CU是否进行四叉树递归划分的过程如下:(1)计算一个LCU的RDcost_SKIP。(2)依次计算帧间规则和AMP模式的率失真代价,最小值作为RDcost_Inter。(3)计算帧内预测各预测方向与水平、垂直、planar模式的率失真代价,最小值为RDcost_Intra。(4)比较RDcost_SKIP、RDcost_Inter和RDcost_Intra,将三者中的最小值作为RDcost_1。(5)将当前层次的CU进行预划分为4个子CU(Sub-CU),每个子CU分别进行(1)~(4),将每个子CU计算得到的RDcost_1求和为RDcost_2。(6)比较RDcost_1与RDcost_2,如果RDcost_1小,则说明不用继续进行下一深度的划分,对每个子CU重复上诉步骤,直至划分到CU为8×8为止。
基于HEVC的3D视频编码是为了适应多视点视频加深度的发展需要提出来的。3D-HEVC的编码结构是由HEVC扩展而来,编码每个纹理图和相关的深度图都是采用基于HEVC技术的二维视频编码结构。同时针对视点间相关性,纹理与深度间相关性提出了一些视差估计、视点间运动预测等新的编码工具。LDV残差层数据量小、残差数据分布散,若直接使用3D-HEVC进行编码,编码的性能不高。为了对LDV提供更高的压缩效果,残差数据需要进行进一步的研究。在侧视点中仅仅有小部分图像区域包含残差数据,这就为得到高压缩比率提供了可能,同时因为残差数据的形状或分布并不完全符合HEVC的按块编码框架,因此需改进划分原则以及选择合适的CU尺寸。
技术实现要素:
本发明的目的是针对LDV残差层数据量小、残差数据分布散、HEVC采用块编码框架的特点,提出一种基于HEVC的分层深度视频残差层数据的编码方法,以实现在码率减小的同时,尽可能保证绘制的虚拟视点质量。
本发明具体的构思是:
本发明中选择三个视点(V1,V5和V9)进行编码;在编码端,对于中间视点V5(包括完整的纹理视频T5和深度视频D5),采取基本的3D-HEVC的编码方法。对于侧视点V1和V9(包括纹理视频T1和T9的残差数据和深度视频D1和D9的残差数据),纹理视频T1和T9的残差数据采取基于HEVC的改进的编码方法,深度视频D1和D9的残差数据采取深度图编码方式。解码端采取类似的方式,解码之后采取视点合成和图像修复的方法恢复出完整的视点。LDV视频的编解码结构图如图5所示。
对于侧视点残差数据的编码方法的主要过程是:首先需要进行LDV生成过程中的参数调整,在保证最终合成的虚拟视点质量的前提下,使得生成的残差数据量最小。然后对残差层进行块校准预处理,侧视点仅有小部分区域包含残差数据,并且残差层的信息分散分布,而HEVC是对视频进行分块编码,为了保持与HEVC中对CTU的四叉树划分原则保持一致,同时不改变每个块的划分情况,可以采取大小为8×8的网格进行块校准。最后编码块校准预处理后的残差层数据,HEVC中最大的CU块大小是64×64,根据四叉树的原则可以划分成更小的块。因为残差数据的分布并不完全符合HEVC的CU块,因此需要改进划分原则和选择合适的CU大小。
根据上述的构思,本发明采用下述技术方案:
一种基于HEVC的分层深度视频残差层数据的编码方法,具体步骤如下:
步骤1. 残差数据的生成:在LDV残差层数据生成过程中,需要滤除背景区域像素数目小于阈值p的小空洞,同时为了适当扩大Disocclusion区域,以像素宽度为q对深度值不连续的背景边界区域的像素进行标定。这里的阈值q和p需要调整,使得编码残差数据的代价尽量小,同时减少合成的虚拟视点伪影的出现;
步骤2. 残差层块校准预处理:HEVC中CU的大小范围是64×64到8×8之间,为了与HEVC中CTU的四叉树划分原则保持一致,同时不改变每个块的划分情况,采取大小为8×8的网格进行块校准;
步骤3. 残差层编码:HEVC采取四叉树的原则对块进行划分,但残差数据的形状并不完全符合HEVC的CU块,因此需改进CU划分原则以及选择合适的CU尺寸。
所述步骤1中,在LDV残差层数据生成过程需要对两个阈值p和q进行调整,具体步骤如下:
1)对于p值,由于深度值错误或噪声等原因,绘制过程中在背景区域会出现一些分散的小空洞,导致生成的残差数据中出现分散的像素点,这些散点并非真正的Disocclusion区域,对于最后LDV的合成并没有帮助,在绘制时这些空洞通过周围的像素点进行有效的修复,因此去掉像素的数目小于阈值p的相关区域,这里p值不能太大,否者会导致重要的信息丢失;
2)对于q值,LDV虚拟视点合成利用的是主视点完整的纹理和深度信息加上侧视点纹理和深度的残差信息,在合成虚拟视点时会有伪影的出现,为了减少伪影的出现,以像素宽度为q对深度值不连续的背景边界区域的像素进行标定,在生成残差数据过程中这部分像素不进行投影,从而扩大了Disocclusion区域,残差数据也相应增大,增大标定宽度q的方法能确保所有的遮挡区域的像素都包含进最终的残差数据中,提高绘制的虚拟视点质量,但同时残差数据的增大也会相应地导致编码代价的上升。
所述步骤2中:在LDV中,侧视点中仅有小部分图像区域包含残差数据,这就为得到高压缩比率提供了可能,然而空洞的分布对现有的编码框架并不友好,HEVC基于CU块进行编码,而残差层的信息分散分布,为了提高编码效率,减少编码的错误,需要进行块网格校准处理,处理的原则如下:
1)如果在一个块中存在的无意义的遮挡信息或者无遮挡信息,那么将该块置为空白块;
2)如果该块中存在有意义的遮挡信息,那么该块就用对应原始侧视点的像素进行填充;
HEVC中CU大小的范围是在64×64到8×8之间,为了保持与HEVC中对CTU的四叉树划分原则保持一致,同时不改变每个块的划分情况,使用大小为8×8的网格进行块校准,然后采用上述相同的处理原则进行像素值填充,因为HEVC中CU块的大小最小就是8×8,所以这种方法不会改变CU块的划分。
所述步骤3中,在编码残差数据时需要改进CU划分原则以及选择合适的CU尺寸,具体的改进方法如下:
a)如果一个CU块中不包含残差数据的像素,那么这个CU不划分,即提前终止CU的划分,且划分信息且包括划分的标记不包含进表示CU的比特流中;
b)如果将一个块划分成四个子块,其中三个子块中不包含任何残差数据的像素,只有一个子块包含残差数据,那么对该块进行划分,但是划分的标记信息不加入到比特流中,以节省比特率,在解码端该块的划分标记通过类似的方法获取;
c)如果一个CU块划分的四个子块中,不止一个块中包含残差数据的像素,那么采取与HEVC 相同的判断块是否划分或帧内/帧间编码的率失真优化模型。
本发明与现有技术相比较,具有如下显而易见的突出实质性特点和显著技术进步:
本发明方法能够有效降低编码残差数据的比特数,同时保证了合成的虚拟视点的质量。
附图说明
图1为LDV的三视点相机系统。
图2为残差层数据的生成过程图。
图3为生成的侧视点残差数据图。
图4为HEVC图像划分结构示意图。
图5为LDV的三维视频编解码框图。
图6为本发明方法具体流程图。
图7为经过块校准前后的残差对比图。
具体实施方式
本发明的优选实施例结合附图详述如下:
参见图6,一种基于HEVC的分层深度视频残差层数据的编码方法,具体步骤如下:
步骤1. 残差数据的生成:在LDV残差层数据生成过程中,需要滤除背景区域像素数目小于阈值p的小空洞,同时为了适当扩大Disocclusion区域,以像素宽度为q对深度值不连续的背景边界区域的像素进行标定。这里的阈值q和p需要调整,使得编码残差数据的代价尽量小,同时减少合成的虚拟视点伪影的出现;
步骤2. 残差层块校准预处理:HEVC中CU的大小范围是64×64到8×8之间,为了与HEVC中CTU的四叉树划分原则保持一致,同时不改变每个块的划分情况,采取大小为8×8的网格进行块校准;
步骤3. 残差层编码:HEVC采取四叉树的原则对块进行划分,但残差数据的形状并不完全符合HEVC的CU块,因此需改进CU划分原则以及选择合适的CU尺寸。
所述步骤1中,在LDV残差层数据生成过程需要对两个阈值p和q进行调整,具体步骤如下:
1)对于p值,由于深度值错误或噪声等原因,绘制过程中在背景区域会出现一些分散的小空洞,导致生成的残差数据中出现分散的像素点,这些散点并非真正的Disocclusion区域,对于最后LDV的合成并没有帮助,在绘制时这些空洞通过周围的像素点进行有效的修复,因此去掉像素的数目小于阈值p的相关区域,这里p值不能太大,否者会导致重要的信息丢失;
2)对于q值,LDV虚拟视点合成利用的是主视点完整的纹理和深度信息加上侧视点纹理和深度的残差信息,在合成虚拟视点时会有伪影的出现,为了减少伪影的出现,以像素宽度为q对深度值不连续的背景边界区域的像素进行标定,在生成残差数据过程中这部分像素不进行投影,从而扩大了Disocclusion区域,残差数据也相应增大,增大标定宽度q的方法能确保所有的遮挡区域的像素都包含进最终的残差数据中,提高绘制的虚拟视点质量,但同时残差数据的增大也会相应地导致编码代价的上升。
所述步骤2中:在LDV中,侧视点中仅有小部分图像区域包含残差数据,这就为得到高压缩比率提供了可能,然而空洞的分布对现有的编码框架并不友好,HEVC基于CU块进行编码,而残差层的信息分散分布,为了提高编码效率,减少编码的错误,需要进行块网格校准处理,处理的原则如下:
1)如果在一个块中存在的无意义的遮挡信息或者无遮挡信息,那么将该块置为空白块;
2)如果该块中存在有意义的遮挡信息,那么该块就用对应原始侧视点的像素进行填充;
HEVC中CU大小的范围是在64×64到8×8之间,为了保持与HEVC中对CTU的四叉树划分原则保持一致,同时不改变每个块的划分情况,使用大小为8×8的网格进行块校准,然后采用上述相同的处理原则进行像素值填充,因为HEVC中CU块的大小最小就是8×8,所以这种方法不会改变CU块的划分,如图7所示为经过块校准前后的残差对比图。
所述步骤3中,在编码残差数据时需要改进CU划分原则以及选择合适的CU尺寸,具体的改进方法如下:
a)如果一个CU块中不包含残差数据的像素,那么这个CU不划分,即提前终止CU的划分,且划分信息(包括划分的标记)不包含进表示CU的比特流中;
b)如果将一个块划分成四个子块,其中三个子块中不包含任何残差数据的像素,只有一个子块包含残差数据,那么对该块进行划分,但是划分的标记信息不加入到比特流中,以节省比特率,在解码端该块的划分标记通过类似的方法获取;
c)如果一个CU块划分的四个子块中,不止一个块中包含残差数据的像素,那么采取与HEVC 相同的判断块是否划分或帧内/帧间编码的率失真优化模型。
- 还没有人留言评论。精彩留言会获得点赞!