一种深度建模模式简化搜索方法与流程
本发明涉及一种3D视频编码。特别是涉及一种针对3D视频序列中深度视频编码建模的深度建模模式简化搜索方法。
背景技术:
近年来以自由视角电视为代表的新兴多媒体服务快速发展,为满足这些应用在高效压缩和传输上的需求,3D视频编码技术得到了广泛研究。基于视频表达格式,3D视频编码方法可以分为两类:一类是基于多视点视频(Multiview Video,MVV)格式,另一类是基于多视点加深度(Multiview Video plus Depth,MVD)格式。MVV视频编码方法能够提供良好的3D感知,但是其需要传输大量的彩色视频,在3D视频获取和编码效率方面存在一定的限制。而MVD视频编码方法减少了彩色视频的数目,同时引入了相应的深度视频,只需要在解码端利用基于深度图像的绘制(Depth Image Based Rendering,DIBR)可以绘制出其余视点的视频序列,大大提高了传输效率。
深度视频具有和彩色视频不同的特性,深度图由大面积的平滑区域和锐利的边缘构成。同时,深度图和对应的彩色图有很强的相关性,它们分别表示同一场景的相关信息,深度图与彩色图有相似的物体边界,而且与彩色图有相似的运动。在编码深度视频时,可以根据与彩色视频的关系分为两类:独立编码和联合编码。独立编码方法对深度视频采用适合其特点的编码方法。联合编码方法则利用彩色视频与深度视频之间的相关性,考虑两者之间的冗余信息,并结合虚拟视点绘制的质量优化等方法来编码深度视频。
针对深度视频的编码,3D-HEVC提出了一些新的深度视频编码工具,如深度建模模式(Depth Modeling Modes,DMMs)。深度建模模式将一个深度块分割成两个非规则区域,每一个区域用一个常量值表示。为了能够表示出分割信息,应该确定两个元素参数,分别是用于表示属于哪个区域的参数和该区域恒定的常数值。新增的两种帧内预测方法分别为采用直线进行分割的楔形模式(Wedgelets)和采用任意形状分割的轮廓模式(Contours),两者的主要区别在于分割的方式不同。除了分割信息需要传送,还要求传送不同分割区域深度值(Constant Partition Value,CPV)。每一个分割的区域深度值是一个固定的常数,该值为该区域原始深度值的均值。总而言之,根据分割模式和传送信息不同,深度视频新增的帧内编码模式分成两种方法:1)明确的楔形法:该方法是在编码端确定最佳匹配的分割,并且在比特流中传送分割信息,利用传送的分割信息,解码端可以重建该块的信号;2)分量间轮廓法:通过重建的对应块推导得到两个任意形状的区域分割。关于DMMs的优化方法,国内外的学者也进行了一些研究。Zhang等人提出了一种针对Wedgelet模式的快速算法,该快速算法先找到满足最小绝对变换误差和(Sum of Absolute Transformed Difference,SATD)的彩色视频的帧内预测方向,然后根据之前建立起来的Wedgelet模式的分割样式和角度预测的映射关系,找到最优的分割方法。Tsukuba等人则通过对16×16大小的预测单元(Prediction Unit,PU)进行图样放大以获得32×32尺寸PU的分割图样,这在一定程度上减少了搜索图样List的尺寸,进而减少了Wedgelet模式搜索的时间范围。
技术实现要素:
本发明所要解决的技术问题是,提供一种深度建模模式简化搜索方法,在保证视频质量的前提下,对当前3D-HEVC编码标准中深度图编码过程进行优化,简化深度建模模式的搜索过程,从而降低所需的编码时间,提高整个编码系统的性能。
本发明所采用的技术方案是:一种深度建模模式简化搜索方法,包括如下步骤:
1)采用角度模式对深度预测单元进行预测;
2)对深度预测单元进行边界检测,判断是否直接跳过深度建模模式;
3)构建粗糙搜索图样集合,包括:
(1)利用深度建模模式对预测单元进行预测,首先对图样查询表进行初始化,图样查询表中包含所有可能的分割情况,同时需要考虑到上采样或下采样过程;
(2)通过边界检测获得四边变化最大的点,将四边变化最大的点分别做为起点或者终点连线获得图样,由所述的图样构成粗糙搜索图样集合;
4)视点合成优化,是在获取粗糙搜索图样集合之后,分别选取集合中的图样进行视点合成优化,通过视点合成优化,选择失真最小的图样作为初步最佳匹配图样;
5)构建精细搜索图样集合,是以步骤4)中获取的最佳图样为参考,获取最佳图样的起点和终点,分别以起点和终点为中心点,在所述中心点的向上下各取2个像素点,或在所述中心点的左右各取2个像素点,以所取的像素点作为新的起点和终点进行组合,得到24种图样,形成精细搜索图样集合;
6)选取最佳预测模式,并进行编码。
步骤1)包括:
以帧为单位,把图像分割成多个编码树单元,每个编码树单元包含编码树块和语法元素,其中,编码树块是由亮度编码树块和与亮度编码树相对应的色度编码树块构成;一个亮度编码树块包含L×L个亮度分量的采样,每个色度编码树块包含L/2×L/2个色度分量的采样;亮度编码树块和色度编码树块直接作为编码块或进一步分割成多个编码块;然后,将编码树块分割为编码单元,其中编码单元按四叉树结构在编码树块内组织;一个亮度编码块、两个色度编码块和相关的语法元素共同形成了一个编码单元,每个编码单元又分为预测单元和变换单元;
利用HEVC角度预测模式对深度预测单元进行预测,通过计算绝对变换误差和(SATD),选取具有最小绝对变换误差和代价的预测模式加入到候选列表中,不同尺寸的深度预测块选取的预测模式数不同;所述最小绝对变换误差和代价JHAD用下述公式来计算
JHAD=SATD+λ·Rmode
其中,SATD是指将残差信号进行哈达玛变换后再求各元素绝对值之和,λ表示拉格朗日乘子,Rmode表示该预测模式下编码所需比特数。
步骤2)中由于深度图中存在两种类型的预测单元,一种由近乎常值或缓慢变化的深度值组成,而另一种则包含锐利的边界,为简化搜索过程,对深度预测单元进行边界检测;若检测出深度预测单元为边界块,则继续进行深度建模模式搜索过程,如果深度预测单元不含边界,则直接跳过深度建模模式。
步骤3)第(2)步中,考虑到上采样和下采样的因素,对于不同尺寸预测单元,实际粗糙集合中待搜索图样总数也会相应调整:对于双精度情况,即32×32尺寸的预测单元,共有6种图样,对于全精度情况,即16×16尺寸的预测单元,共有6种图样,而对于半精度情况,即8×8和4×4尺寸的预测单元,分别各有24种图样。
步骤6)包括:
遍历精细搜索图样集合,通过视点合成优化技术选取最佳匹配图样,把选取的最佳匹配图样放入候选列表中;在候选列表中的最佳匹配图样、通过模式粗选过程获取的角度预测模式以及通过相邻参考预测单元获取的最可能模式需要通过率失真优化过程确定最佳帧内预测模式,率失真代价JRDO的定义如下式所示:
JRDO=D+λ·R
D代表失真,用来描述重建视频质量,用均方误差和或绝对误差和表示,R表示编码所消耗的比特数,λ为拉格朗日乘子;
在进行率失真优化过程中,需遍历候选列表中的所有预测模式,选取率失真代价最小的模式作为最佳预测模式并进行编码。
本发明的一种深度建模模式简化搜索方法,通过简化深度建模模式的搜索过程,减少了编码时间,降低了运算复杂度,在保证视频质量无明显下降的情况下提高了编码速度。
附图说明
图1是本发明一种深度建模模式简化搜索方法的流程图;
图2是本发明实验结果图。
具体实施方式
下面结合实施例和附图对本发明的一种深度建模模式简化搜索方法做出详细说明。
如图1所示,本发明的一种深度建模模式简化搜索方法,包括如下步骤:
1)采用角度模式对深度预测单元进行预测;包括:
以帧为单位,把图像分割成多个编码树单元,每个编码树单元包含编码树块(Coding Tree Block,CTB)和语法元素,其中,编码树块是由亮度编码树块和与亮度编码树相对应的色度编码树块构成;一个亮度编码树块包含L×L个亮度分量的采样,每个色度编码树块包含L/2×L/2个色度分量的采样;亮度编码树块和色度编码树块直接作为编码块(Coding Block,CB)或进一步分割成多个编码块;然后,将编码树块分割为编码单元(Coding Unit,CU),其中编码单元按四叉树结构在编码树块内组织;一个亮度编码块、两个色度编码块和相关的语法元素共同形成了一个编码单元,每个编码单元又分为预测单元(Prediction Unit,PU)和变换单元(Transform Unit,TU);
利用HEVC角度预测模式对深度预测单元进行预测,通过计算绝对变换误差和(SATD),选取具有最小绝对变换误差和代价的预测模式加入到候选列表中,不同尺寸的深度预测块选取的预测模式数不同;在35种预测模式中选取3种(针对64×64,32×32,16×16大小的PU)或8种(针对8×8,4×4大小的PU)具有最小绝对变换误差和代价JHAD的预测模式加入到候选列表中。所述最小绝对变换误差和代价JHAD用下述公式来计算
JHAD=SATD+λ·Rmode
其中,SATD是指将残差信号进行哈达玛变换后再求各元素绝对值之和,λ表示拉格朗日乘子,Rmode表示该预测模式下编码所需比特数。
2)对深度预测单元进行边界检测,判断是否直接跳过深度建模模式;由于深度图中存在两种类型的预测单元,一种由近乎常值或缓慢变化的深度值组成,而另一种则包含锐利的边界,为简化搜索过程,对深度预测单元进行边界检测;若检测出深度预测单元为边界块,则继续进行深度建模模式搜索过程,如果深度预测单元不含边界,则直接跳过深度建模模式。
如果PU含有锐利边界,则PU的四条边中至少有两条边上存在深度值梯度变化最大点;反之,如果该PU没有或者只有一条边存在深度值梯度变化最大点,这种情况下该PU可以看作为平滑PU,其DMM模式可以直接跳过。基于此思想,边界检测主要过程如下:
1)对PU进行边缘检测,获取PU四边梯度变化最大点的个数n,其中梯度变化由相邻像素的差值绝对值来衡量;
2)判断n≤1;若n≤1,跳过DMM模式,直接进行RDO过程并编码;若n≥2,转到步骤3。
3)构建粗糙搜索图样集合
在边缘检测之后,若深度PU没有或者只有一条边上存在深度值梯度变化最大点时,DMM模式直接被跳过;而对于未跳过DMM模式的PU,其深度值梯度变化最大的点可以视为PU所含有的锐利边界的起点或终点,以此来构建DMM划分图样的粗糙搜索集合。构建粗糙搜索图样集合包括:
(1)利用深度建模模式对预测单元进行预测,首先对图样查询表进行初始化,图样查询表中包含所有可能的分割情况,同时需要考虑到上采样或下采样过程;具体是,初始化图样查询表时,分别取PU两条边界上的像素点作为起点和终点,连接后所得分割线把深度块划分为两个部分。同时为了提高准确度,针对不同大小的块采用的精度不同,对于32×32的块,采用双精度;16×16的块,采用全精度;8×8和4×4的块采用半精度。
(2)对于未跳过DMM模式的深度PU,需要获取边缘检测后梯度变化最大点的位置信息,将其作为图样分割线的起点或终点。以任意边梯度变化最大点作为起点或终点并连接起来,获得的每条分割线对应一种划分图样,所有可能的划分图样构成粗糙搜索集合。由所述的图样构成粗糙搜索图样集合;考虑到上采样和下采样的因素,对于不同尺寸预测单元,实际粗糙集合中待搜索图样总数也会相应调整:对于双精度情况,即32×32尺寸的预测单元,共有6种图样,对于全精度情况,即16×16尺寸的预测单元,共有6种图样,而对于半精度情况,即8×8和4×4尺寸的预测单元,分别各有24种图样。
4)视点合成优化,是在获取粗糙搜索图样集合之后,分别选取集合中的图样进行视点合成优化,通过视点合成优化,选择失真最小的图样作为初步最佳匹配图样;
深度视频中的图形信息可以直接应用于合成过程,因此深度视频有损编码会引起合成视点的失真。对观察者而言,由于深度视频最终是不可见的,因而深度视频的编码性能可以由最终合成视点的质量来衡量。在3D-HEVC的深度视频编码中,其模式选择过程的失真通过加权平均合成视点的失真和深度图的失真来度量,这一过程便是视点合成优化(View Synthesis Optimization,VSO)。通过视点合成优化选取粗糙搜索集中的初步最佳匹配图样。
具体如下:
(1)把粗糙搜索集中所有图样索引号放到集合Coarse[i]中,
(2)初始化i=0,Dmax;
(3)计算失真D,判断D≤Dmax;若D≤Dmax,Dmax=D,
(4)i++,跳转到第(3)步;
(5)i=6(32×32,16×16的PU)或i=24(8×8,4×4的PU)时循环终止。
在遍历粗糙搜索集合中的所有图样后,选取具有最小失真的图样作为初步的最佳匹配图样。
5)构建精细搜索图样集合
将粗糙搜索集中的最优图样视作最终的匹配图样,仍然存在不可接受的粗糙性。为了保证编码性能,需要进行进一步的精细搜索。以步骤4)中获取的最佳图样为参考,获取最佳图样的起点和终点,分别以起点和终点为中心点,在所述中心点的向上下各取2个像素点,或在所述中心点的左右各取2个像素点,以所取的像素点作为新的起点和终点进行组合,得到24种图样,形成精细搜索图样集合。
6)选取最佳预测模式,并进行编码,包括:
遍历精细搜索图样集合,通过视点合成优化技术选取最佳匹配图样,把选取的最佳匹配图样放入候选列表中;在候选列表中的最佳匹配图样、通过模式粗选(Rough Mode Decision,RMD)过程获取的角度预测模式以及通过相邻参考预测单元获取的最可能模式(Most Probable Modes,MPMs)需要通过率失真优化(Rate Distortion Optimization,RDO)过程确定最佳帧内预测模式,率失真代价JRDO的定义如下式所示:
JRDO=D+λ·R
D代表失真,用来描述重建视频质量,用均方误差和或绝对误差和表示,R(Rate)表示编码所消耗的比特数,λ为拉格朗日乘子;
在进行率失真优化过程中,需遍历候选列表中的所有预测模式,选取率失真代价最小的模式作为最佳预测模式并进行编码。
本专利所采用的算法通过边缘检测技术跳过DMM预测模式,同时对于未跳过DMM模式的PU,简化DMM模式预测过程中的最佳匹配图样搜索过程,从而节省了大量的编码时间。
下面结合附图说明实验效果:
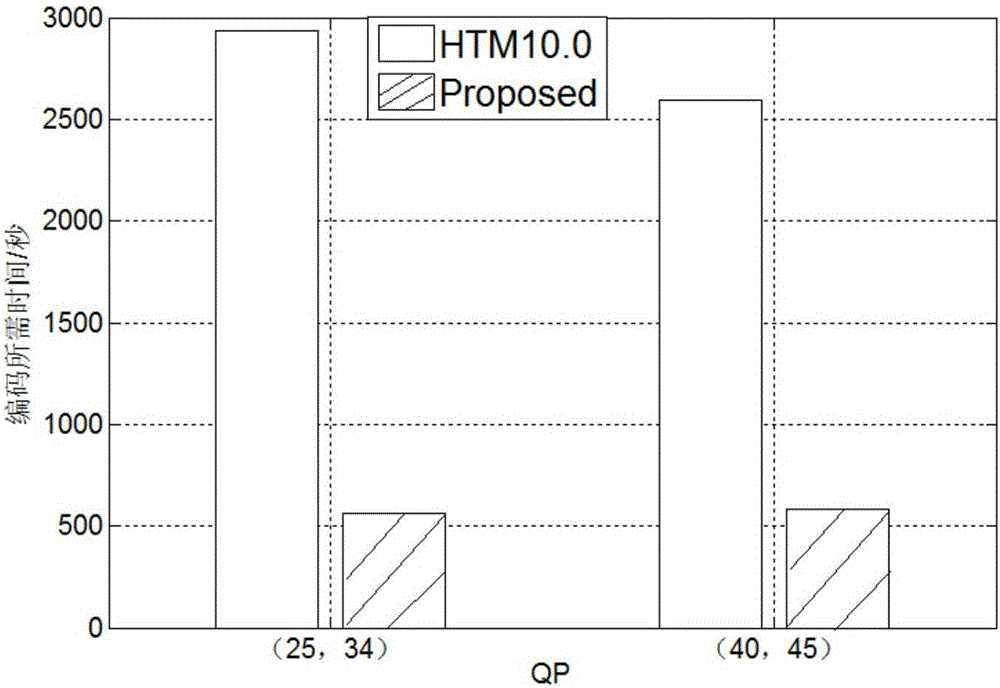
实验测试在3D-HEVC的参考软件HTM10.0上进行。采用8个标准测试视频序列在标准测试条件(CTC)下进行测试。测试的视频根据分辨率分为两类,一类是1024×768分辨率,另一类是1920×1088分辨率。彩色视频和深度视频量化参数对设置为(25,34),(30,39),(35,42)和(40,45),实验采用全帧内编码结构。为使本发明的效果具有可比性,在相同的实验条件下,通过对比本发明和HTM算法进行对比。由实验结果如图2所示,本发明可以节省75%左右的DMM编码时间。
- 还没有人留言评论。精彩留言会获得点赞!