一种基于统计特征分类的匿名协议分类方法与流程
本发明涉及匿名协议检测技术领域,尤其涉及一种基于统计特征分类的匿名协议分类方法。
背景技术:
匿名技术是访问网络时保护用户隐私的一种有效手段。它是通过一定的方法将通信流中的通信关系加以隐藏,以使攻击者无法获知双方的通信关系或通信一方。目前实际运行的匿名技术包括Tor、JAP和I2P。其中,Tor最具有代表性、使用最为广泛,是目前匿名通信领域的主要研究对象。
下面以Tor为例,介绍匿名协议的匿名实现机制。图1示出了Tor匿名网络的组成示意图。从图1可见,Tor是一个三重代理,包括:目录服务器、洋葱路由器和部署在用户端的洋葱代理程序。在Tor匿名网络中,Tor客户端先与目录服务器通信,获得在所有基于流的匿名通信系统中的活动中继节点信息,然后,再随机选择三个节点组成circuit(电路)。Tor客户端随机选择了入口节点,入口节点随机选择了中间节点,中间节点又随机选择了出口节点。这种随机选择是由精心设计的算法保证的,没有规律可循。用户流量在跳跃这三个节点(hop)之后最终到达目标网站服务器。一般来说,每隔10分钟左右就会重新选择这三个节点,以规避流量分析和蜜罐节点。
在现有技术中,匿名流量的检测算法主要有两类:基于TLS指纹的匿名流量检测算法、基于报文长度特性的匿名流量检测算法。其中,基于TLS指纹的算法仅需分析TLS流量中“Client Hello”、“Server Hello”和“Certificate”报文。该识别方法识别速度快、适用于在线识别。但若密码套件、数字证书等特征发生改变,则该识别方法需同步做出改变。因此,基于TLS指纹的算法不具有通用性。另外,何高峰等人提出了一种利用报文长度分布的识别方法。确切的说,该识别方法只利用了报文长度熵这一个特征。该识别方法不需要根据证书的变化做出改变,通用性高,而且,该识别方法针对同一网站的检测率可以达到90%以上。但是,当匿名流量和非流量样本涉及多个不同网站时,由于各网站报文长度熵的阈值不同,该识别方法几乎失效。
鉴于现有的两种检测算法的不足,亟需一种能针对不同网站的流量进行检测、通用性高、检测准确度高、计算量小的新的匿名流量识别方法。
技术实现要素:
本发明的目的在于提出一种能针对不同网站的流量进行检测、通用性高、检测准确度高、计算量小的新的匿名流量识别方法。
本发明提出了一种基于统计特征分类的匿名协议分类方法,所述方法包括以下步骤:
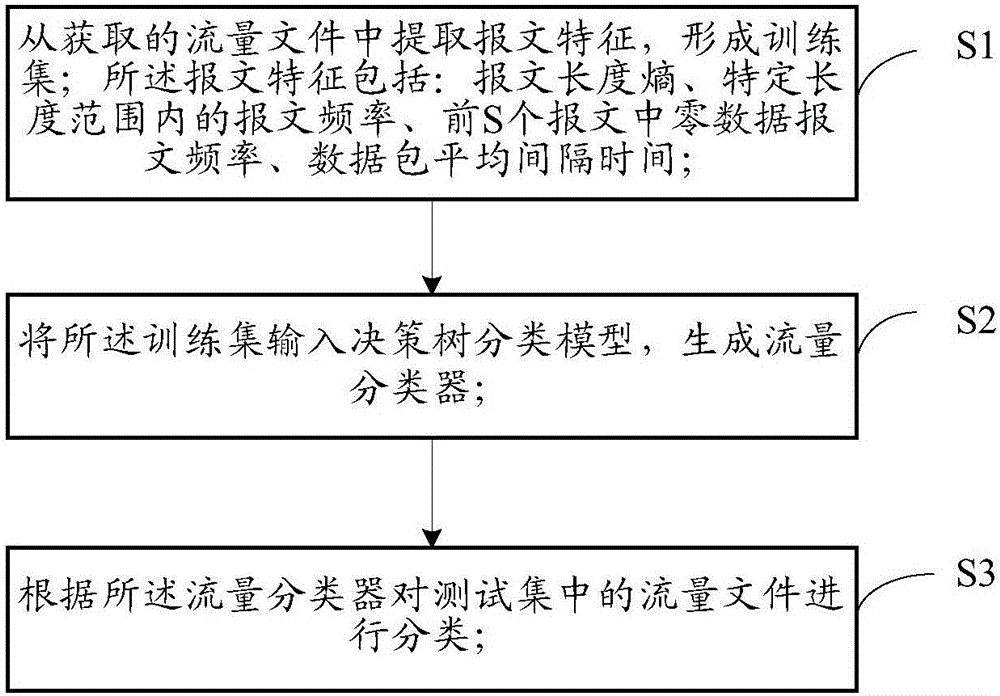
S1、从获取的流量文件中提取报文特征,形成训练集;所述报文特征包括:报文长度熵H(x)、特定长度范围内的报文频率PM、前S个报文中零数据报文频率P0、数据包平均间隔时间Ta;
S2、将所述训练集输入决策树分类模型,生成流量分类器;
S3、根据所述流量分类器对测试集中的流量文件进行分类;
其中,S为大于1的整数。
较佳的,在步骤S1中,根据公式1计算报文长度熵H(x);
式中,x是报文长度随机变量,pi为相同长度报文出现的频率,i=1,2…m。
较佳的,根据公式2计算pi;
pi=fi/n 公式2
式中,fi是相同长度报文出现的频数,i=1,2…m。
较佳的,在步骤S1中,根据公式3计算特定长度范围内的报文频率PM;
PM=fM/n 公式3
式中,fM为特定长度范围内的报文总频数。
较佳的,在步骤S1中,根据公式4计算前S个报文中零数据报文频率P0;
P0=f0/S 公式4
式中,f0为前S个报文中零数据报文的频数。
较佳的,在步骤S1中,根据公式5计算数据包平均间隔时间Ta;
式中,Ti是第i个数据包与第i+1个数据包之间的时间间隔。
较佳的,步骤S2包括:
S21、针对每个报文特征,分别计算每个分裂阈值的信息增益Gain(A);
S22、针对每个报文特征,将信息增益最大的分裂阈值作为该报文特征的分裂点;
S23、针对每个报文特征,根据所述分裂点计算信息增益率GainRatio(A);
S24、将信息增益率最大的报文特征作为根节点,根据所述根节点的分裂点建立数的分支;
S25、进行递归操作,直至所有叶子节点都属于同一类。
较佳的,在步骤S21中,根据公式6计算信息增益Gain(A);
Gain(A)=Info(D)-InfoA(D) 公式6
式中,Info(D)为对训练集中的元组分类所需的期望信息度量值,InfoA(D)为根据特征A将训练集划分之后所需的信息度量值。
较佳的,Info(D)、InfoA(D)满足:
式中,|D|是训练集中的元组个数,|Dj|是第j种划分得到的正例元组个数。
较佳的,在步骤S23中,根据公式9计算信息增益率GainRatio(A);
并且,SplitInfo(A)满足:
式中,SplitInfo(A)为分裂信息值。
从以上技术方案可以看出,基于统计特征分类的匿名协议分类方法主要包括以下步骤:从获取的流量文件中提取报文特征,形成训练集,所述报文特征包括:报文长度熵H(x)、特定长度范围内的报文频率PM、前S个报文中零数据报文频率P0、数据包平均间隔时间Ta;将所述训练集输入决策树分类模型,生成流量分类器;根据所述流量分类器对测试集中的流量文件进行分类。本发明可以从未知流量中快速、准确的检测出匿名流量,从而为以后探测匿名流量上层应用分类、以及匿名访问内容解析提供了基础。
附图说明
通过以下参照附图而提供的具体实施方式部分,本发明的特征和优点将变得更加容易理解,在附图中:
图1是Tor匿名网络的组成示意图;
图2是本发明实施例中的基于统计特征分类的匿名协议分类方法流程示意图;
图3是本发明实施例中的决策树分类算法流程图。
具体实施方式
下面参照附图对本发明的示例性实施方式进行详细描述。对示例性实施方式的描述仅仅是出于示范目的,而绝不是对本发明及其应用或用法的限制。
匿名网络在保护用户隐私信息的同时,也可能为不法分子所利用。许多犯罪分子通过匿名网络保护自身信息、突破网络管理限制访问非法网站,甚至进行枪支、毒品买卖、雇凶杀人等网络犯罪活动。因此,有必要对匿名通信流量进行检测。
在现有技术中,匿名流量检测算法主要分为两类:基于TLS指纹的匿名流量检测算法、基于报文长度特性的匿名流量检测算法。鉴于这两种检测算法均存在各自的缺陷,本发明的发明人提出了一种新的流量检测方法,以提高检测准确度、减小检测计算量,同时又能保证检测方法的通用性。
下面结合附图和具体实施例对本发明的技术方案进行详细说明。在该实施例中,我们以Tor匿名协议为例进行说明。但是,需要指出的是,本发明不仅适用于Tor匿名协议的检测,而且适用于JAP和I2P等其他匿名协议的检测。
图2示出了本发明实施例的基于统计特征分类的匿名协议分类方法流程示意图。从图2可见,该方法主要包括步骤S1~S3。
步骤S1、从获取的流量文件中提取报文特征,形成训练集;所述报文特征包括:报文长度熵H(x)、特定长度范围内的报文频率PM、前S个报文中零数据报文频率P0、数据包平均间隔时间Ta。
在具体介绍该步骤之前,首先对Tor信元结构进行介绍。为了防止流量分析攻击,Tor的上层流量封装成固定长度,并外加控制字段。通常,该固定长度被称为信元。表1示出了Tor的信元结构。从表1可见,Tor的信元长度为512字节。其中,应用层数据为498字节,不够498字节的进行填充。Tor信元经TLS层加密后交由网络层传输,对应的TLS层报文长度为586字节,如表2所示。
表1 Tor信元结构
表2 TLS层报文结构
匿名通信层长度信元交由网络层TCP/IP协议传输,然而网络层报文并非等长度。为了提高传输效率,TCP往往会将一个或多个信元一起发送,再加上网络MTU的限制,Tor报文长度的变化范围有限。经过分析,Tor报文长度在600左右的数据包占很大比例。
根据以上分析,本发明在步骤S1中提取了四个报文特征,分别是报文长度熵H(x)、特定长度范围内的报文频率PM、前S个报文中零数据报文频率P0、数据包平均间隔时间Ta。
具体的,步骤S1包括以下步骤:获取数据包的前n个长度大于0的报文,记录其长度Li,i=1,2…n;统计相同长度报文出现的频数fi,以及相同长度报文出现的频率pi,i=1,2…m;统计每个数据报文到达的时间戳,记录相邻两个报文之间的时间间隔Ti,i=1,2…n-1,以及计算数据包平均间隔时间Ta;统计特定长度范围内的报文频率PM;计算报文长度熵H(x);计算前S个报文中零数据报文的频率P0。
在具体实施时,根据公式1计算报文长度熵H(x);
式中,x是报文长度随机变量,pi为相同长度报文出现的频率,i=1,2…m。并且,pi满足:pi=fi/n,fi是相同长度报文出现的频数,i=1,2…m。
在具体实施时,根据公式3计算特定长度范围内的报文频率PM;
PM=fM/n 公式3
式中,fM为特定长度范围内的报文总频数。在该实施例中,较佳的,所述特定长度范围为:580~620。
在具体实施时,根据公式4计算前S个报文中零数据报文频率P0;
P0=f0/S 公式4
式中,f0为前S个报文中零数据报文的频数。在该实施例中,较佳的,S取10。
在具体实施时,根据公式5计算数据包平均间隔时间Ta;
式中,Ti是第i个数据包与第i+1个数据包之间的时间间隔。
步骤S2、将所述训练集输入决策树分类模型,生成流量分类器。
在对步骤S2进行详细介绍之前,我们首先对决策树方法的一般步骤进行说明。在决策树方法中,首先利用信息增益寻找具有最大信息量的属性字段,建立决策树的一个结点,然后根据该属性字段的不同取值建立树的分支,再在每个分支子集中重复建立树的下层结点和分支。决策树方法具有以下优点:结构简单,便于理解;计算效率高,对训练集数据量较大的情况较为适合;具有较高的分类精确度。
鉴于决策树方法的上述优点,我们在该实施例中采用了决策树方法构建流量分类器。其中,设D是未知流量训练集,流量属性具有m个不同值,2个不同类Ci(i={1,2}),CiD是D中Ci类的元组的集合,|D|和|CiD|分别是D和CiD中的元组个数。
图3示出了该实施例中基于决策树构建流量分类器的流程示意图。从图3可见,该流程始于步骤S21。
S21、针对每个报文特征,分别计算每个分裂阈值的信息增益Gain(A)。
其中,根据公式6计算信息增益Gain(A);
Gain(A)=Info(D)-InfoA(D) 公式6
式中,Info(D)为对训练集中的元组分类所需的期望信息度量值,InfoA(D)为根据特征A将训练集划分之后所需的信息度量值。并且,Info(D)、InfoA(D)满足:
式中,|D|是训练集中的元组个数,|Dj|是第j种划分得到的正例元组个数。
S22、针对每个报文特征,将信息增益最大的分裂阈值作为该报文特征的分裂点。
S23、针对每个报文特征,分别计算信息增益率GainRatio(A)。
其中,根据公式9计算信息增益率GainRatio(A);
并且,SplitInfo(A)满足:
式中,SplitInfo(A)为分裂信息值。
S24、将信息增益率最大的报文特征作为根节点,根据所述根节点的分裂点建立数的分支。
S25、进行递归操作,直至所有叶子节点都属于同一类。
具体的,在步骤S24以后,首先判断是否所有叶子节点都属于同一类别。如果是,则结束整个算法流程。如果否,则进一步判断树的深度是否达到10层。如果树的深度没有达到10层,仅重复步骤S21~S24,进行递归计算。如果树的深度已经达到10层,则将数量较多的类别作为最终分类,从而结束整个算法流程。
步骤S3、根据所述流量分类器对测试集中的流量文件进行分类。
在得到流量分类器以后,我们可以将测试集中的流量文件输入该分类器,从而可以快速的将未知流量分为Tor流量与正常流量。
在本发明实施例中,通过对匿名流量进行特征提取、以及利用决策树构建流量分类器,可以检快速检测出测试集中的匿名流量。实验证明,当特定长度范围满足[580,620],且s取10时,该分类方法对Tor匿名流量的检测率可以达到95%以上,误检率控制在1%以内。
虽然参照示例性实施方式对本发明进行了描述,但是应当理解,本发明并不局限于文中详细描述和示出的具体实施方式,在不偏离权利要求书所限定的范围的情况下,本领域技术人员可以对所述示例性实施方式做出各种改变。
- 还没有人留言评论。精彩留言会获得点赞!