向多媒体服务器上传视频文件的方法和装置与流程
本发明涉及互联网技术领域,特别涉及一种向多媒体服务器上传视频文件的方法和装置。
背景技术:
随着互联网技术的发展,直播应用的功能越来越多,直播应用不仅具有直播功能,还具有播放视频功能;主播用户可以向多媒体服务器上传视频文件,观众用户在直播应用中观看该视频文件。例如,主播用户拍摄一个视频片段,向多媒体服务器上传该视频片段,观众用户在直播应用中观看该视频片段。
目前,主播用户向多媒体服务器上传视频片段时,主播用户使用摄像设备(例如,摄像机)拍摄得到视频数据,将该视频数据拷贝到用户终端中,向用户终端输入该视频片段的文字信息,文字信息包括字幕信息和视频片段的基础信息(例如,导演名称、演员名称、片名、简介、赞助商等信息);用户终端将该字幕信息添加到该视频数据中得到一个视频片段,用户终端通过直播应用登录多媒体服务器,向多媒体服务器上传该视频片段。
在实现本发明的过程中,发明人发现现有技术至少存在以下问题:
上述方法需要摄像设备和用户终端配合才能向多媒体服务器上传视频片段,从而上述方法中需要经过拷贝视频数据、登录多媒体服务器以及上传视频片段等多个繁琐的操作,才能向多媒体服务器上传视频片段,从而导致上传效率低。
技术实现要素:
为了解决现有技术的问题,本发明提供了一种向多媒体服务器上传视频文件的方法和装置。技术方案如下:
一种向多媒体服务器上传视频文件的方法,所述方法包括:
在主播用户的直播界面中显示录制按钮,检测到所述录制按钮被触发时,开始进行拍摄,得到视频数据;
在拍摄过程中,获取拍摄得到的所述视频数据对应的文字信息;
根据所述视频数据和所述文字信息,生成视频文件,并向多媒体服务器上传所述视频文件。
可选的,所述文字信息包括字幕信息和基本信息;
所述获取拍摄得到的所述视频数据对应的文字信息,包括:
提取所述视频数据中的语音信息,识别所述语音信息,得到所述字幕信息;
获取所述主播用户输入的所述视频数据的基本信息。
可选的,所述根据所述视频数据和所述文字信息,生成视频文件,包括:
在所述直播界面中显示合成按钮,检测到所述合成按钮被触发时,获取所述视频数据的片头信息和片尾信息;
将所述片头信息、所述片尾信息和所述视频数据进行拼接,将所述文字信息插入拼接后的所述视频数据中,得到视频文件。
可选的,所述获取所述视频数据的片头信息和片尾信息,包括:
通过第一预设提取算法,提取所述视频数据的第一关键帧,得到所述视频数据的片头信息;
通过第二预设提取算法,提取所述视频数据的第二关键帧,得到所述视频数据的片尾信息。
可选的,所述获取所述视频数据的片头信息和片尾信息,包括:
获取所述主播用户从图像库中选择的第三关键帧,得到所述视频数据的片头信息,所述图像库中包括多个图像帧;
获取所述主播用户从所述图像库中选择的第四关键帧,得到所述视频数据的片尾信息。
可选的,所述方法还包括:
在所述直播界面中显示直播按钮,检测到所述直播按钮被触发时,在拍摄过程中,通过所述多媒体服务器向观众终端发送所述视频文件。
一种向多媒体服务器上传视频文件的装置,所述装置包括:
拍摄模块,用于在主播用户的直播界面中显示录制按钮,检测到所述录制按钮被触发时,开始进行拍摄,得到视频数据;
获取模块,用于在拍摄过程中,获取拍摄得到的视频数据对应的文字信息;
生成模块,用于根据所述视频数据和所述文字信息,生成视频文件;
上传模块,用于向多媒体服务器上传所述视频文件。
可选的,所述获取模块,包括:
识别单元,用于提取所述视频数据中的语音信息,识别所述语音信息,得到所述字幕信息;
第一获取单元,用于获取所述主播用户输入的所述视频数据的基本信息。
可选的,所述生成模块,包括:
第二获取单元,用于在所述直播界面中显示合成按钮,检测到所述合成按钮被触发时,获取所述视频数据的片头信息和片尾信息;
插入单元,用于将所述片头信息、所述片尾信息和所述视频数据进行拼接,将所述文字信息插入拼接后的所述视频数据中,得到视频文件。
可选的,所述第二获取单元,包括:
第一提取子单元,用于通过第一预设提取算法,提取所述视频数据的第一关键帧,得到所述视频数据的片头信息;
第二提取子单元,用于通过第二预设提取算法,提取所述视频数据的第二关键帧,得到所述视频数据的片尾信息。
可选的,所述第二获取单元,包括:
第一获取子单元,用于获取所述主播用户从图像库中选择的第三关键帧,得到所述视频数据的片头信息,所述图像库中包括多个图像帧;
第二获取子单元,用于获取所述主播用户从所述图像库中选择的第四关键帧,得到所述视频数据的片尾信息。
可选的,所述装置还包括:
发送模块,用于在所述直播界面中显示直播按钮,检测到所述直播按钮被触发时,在拍摄过程中,通过所述多媒体服务器向观众终端发送所述视频文件。
在本发明实施例中,用户终端可以直接通过直播应用的直播界面进行拍摄得到视频数据,并获取该视频数据对应的文字信息,用户终端直接将该视频数据和文字信息合成视频文件,并向多媒体服务器上传该视频文件,省略了拷贝视频数据等步骤,操作过程简单,提高了用户终端向多媒体服务器上传视频文件时的上传效率。
附图说明
图1是本发明实施例提供的一种向多媒体服务器上传视频文件的方法流程图;
图2-1是本发明实施例提供的一种向多媒体服务器上传视频文件的方法流程图;
图2-2是本发明实施例提供的一种基本信息输入界面的示意图;
图3是本发明实施例提供的一种向多媒体服务器上传视频文件的装置结构示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明实施方式作进一步地详细描述。
为了实现在用户终端中生成视频文件,并提高向多媒体服务器上传视频文件的上传效率;在主播用户的直播界面中增加录制按钮,主播用户可以通过点击该录制按钮,以触发用户终端开始进行拍摄;检测到该录制按钮被触发时,用户终端开始进行拍摄,得到视频数据;在拍摄过程中,获取拍摄得到的视频数据对应的文字信息,根据该视频数据和该文字信息,生成视频文件,向多媒体服务器上传视频文件,从而实现借助于直播应用,在用户终端中生成视频文件,并直接在直播应用中向多媒体服务器上传该视频文件,提高了上传效率。
本发明实施例提供了一种向多媒体服务器上传视频文件的方法,该方法的执行主体是用户终端。其中,用户终端可以是手机或平板电脑等移动终端,也可以是PC(Personal Computer,个人计算机)终端。多媒体服务器可以为直播应用服务器或者视频播放服务器等。
用户终端可以包括输入设备、存储器、处理器和输出设备。其中,该输入设备可以是麦克风和摄像头,可以用于进行拍摄,得到视频数据。存储器可以用于存储执行向多媒体服务器上传视频文件的应用程序代码;处理器可以用于根据该存储器中存储的应用程序代码,在拍摄过程中,获取拍摄得到的视频数据对应的文字信息,根据视频数据和文字信息,生成视频文件,并向多媒体服务器上传视频文件。该输出设备可以是显示屏和扬声器等。另外,该用户设备还可以包括电源、传感器等部件。
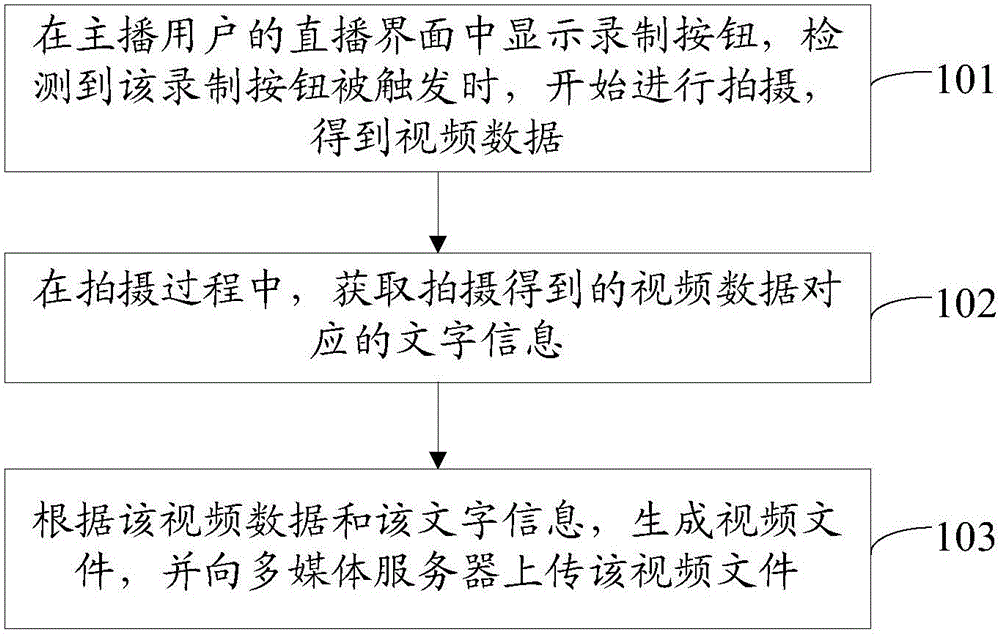
本发明实施例提供了一种向多媒体服务器上传视频文件的方法,该方法的执行主体是用户终端,参见图1,该方法包括:
步骤101:在主播用户的直播界面中显示录制按钮,检测到该录制按钮被触发时,开始进行拍摄,得到视频数据。
步骤102:在拍摄过程中,获取拍摄得到的视频数据对应的文字信息。
步骤103:根据该视频数据和该文字信息,生成视频文件,并向多媒体服务器上传该视频文件。
可选的,该文字信息包括字幕信息和基本信息;
获取拍摄得到的该视频数据对应的文字信息,包括:
提取视频数据中的语音信息,识别该语音信息,得到字幕信息;
获取主播用户输入的该视频数据的基本信息。
可选的,根据该视频数据和文字信息,生成视频文件,包括:
在直播界面中显示合成按钮,检测到该合成按钮被触发时,获取该视频数据的片头信息和片尾信息;
将该片头信息、该片尾信息和该视频数据进行拼接,将该文字信息插入拼接后的该视频数据中,得到视频文件。
可选的,获取该视频数据的片头信息和片尾信息,包括:
通过第一预设提取算法,提取该视频数据的第一关键帧,得到该视频数据的片头信息;
通过第二预设提取算法,提取该视频数据的第二关键帧,得到该视频数据的片尾信息。
可选的,获取该视频数据的片头信息和片尾信息,包括:
获取主播用户从图像库中选择的第三关键帧,得到该视频数据的片头信息,图像库中包括多个图像帧;
获取主播用户从图像库中选择的第四关键帧,得到该视频数据的片尾信息。
可选的,该方法还包括:
在直播界面中显示直播按钮,检测到该直播按钮被触发时,在拍摄过程中,通过多媒体服务器向观众终端发送该视频文件。
在本发明实施例中,用户终端可以直接通过直播应用的直播界面进行拍摄得到视频数据,并获取该视频数据对应的文字信息,用户终端直接将该视频数据和文字信息合成视频文件,并向多媒体服务器上传该视频文件,省略了拷贝视频数据等步骤,操作过程简单,提高了用户终端向多媒体服务器上传视频文件时的上传效率。
本发明实施例提供了一种向多媒体服务器上传视频文件的方法,该方法的执行主体是用户终端,参见图2-1,该方法包括:
步骤201:在主播用户的直播界面中显示录制按钮,用户终端检测到该录制按钮被触发时,开始进行拍摄,得到视频数据。
为了实现在直播应用中生成视频文件,在主播用户的直播界面中增加录制按钮;该录制按钮用于触发开始拍摄命令给用户终端。用户终端检测到该录制按钮被触发时,生成开始拍摄命令,根据该开始拍摄命令,开启用户终端的摄像头,通过该摄像头进行拍摄,得到视频数据。其中,视频数据包括语音信息和图像信息。
为了方便主播用户控制拍摄过程,在主播用户的直播界面中增加暂停按钮、恢复按钮、暂停与保存按钮和结束按钮中的至少一个按钮。暂停按钮用于触发暂停拍摄命令给用户终端;恢复按钮用于触发恢复拍摄命令给用户终端;暂停与保存按钮用于触发暂停拍摄命令和保存命令给用户终端;结束按钮用于触发结束拍摄命令给用户终端。
例如,在主播用户的直播界面中显示暂停按钮和恢复按钮;当主播用户想要暂定录制时,主播用户可以点击该暂停按钮以触发暂停拍摄命令给用户终端;当主播用户想要恢复录制时,主播用户可以点击该恢复按钮以触发恢复拍摄命令给用户终端。用户终端检测到该暂停按钮被触发时,生成暂停拍摄命令;根据该暂停拍摄命令,停止拍摄。用户终端检测到该恢复按钮被触发时,生成恢复拍摄命令,根据该恢复拍摄命令,继续进行拍摄,得到视频数据。
再如,在主播用户的直播界面中显示暂停与保存按钮;当主播用户想要暂定录制并保存已录制的视频数据时,主播用户可以点击该暂停与保存按钮以触发暂停拍摄命令和保存命令给用户终端。用户终端检测到该暂停与保存按钮被触发时,生成暂停拍摄命令和保存命令;根据该暂停拍摄命令,停止进行拍摄;根据该保存命令,存储拍摄得到的视频数据。
再如,在主播用户的直播界面中显示结束按钮;当主播用户想要结束录制时,主播用户可以点击该结束按钮以触发停止拍摄命令给用户终端。用户终端检测到该结束按钮被触发时,生成结束拍摄命令;根据该结束拍摄命令,关闭用户终端的摄像头,停止拍摄。
步骤202:在拍摄过程中,用户终端获取拍摄得到的该视频数据对应的文字信息。
该文字信息包括字幕信息和基本信息,字幕信息为用户终端拍摄得到的视频数据中语音信息对应的字幕信息。基本信息至少包括该视频数据的拍摄者(例如,导演)、参与者(例如,演员)、名称、简介等;基本信息还可以包括该视频数据的赞助、音频信息名称、拍摄地点、拍摄时间等信息。本发明实施例对基本信息的内容并不作具体限定。
用户终端获取拍摄得到的视频数据对应的文字信息可以通过以下步骤2021-2022实现,包括:
步骤2021:用户终端提取该视频数据中的语音信息,识别语音信息,得到字幕信息。
用户终端提取该视频数据中的语音信息,从该语音信息提取出语音特征序列,根据语音识别算法和该语音特征序列,将该语音信息转化为字幕信息。
进一步地,用户终端将语音信息转换为字幕信息之后,对于该语音信息中的每个语音片段(例如,一句话),用户终端获取该语音片段对应的图像帧和字幕信息,存储该字幕信息和该图像帧的对应关系,以便于后续根据该字幕信息,获取该图像帧,从而将该字幕信息添加到该图像帧中。
进一步地,用户终端在拍摄过程中,还可以在直播界面中实时播放该视频数据。
步骤2022:用户终端获取主播用户输入的该视频数据的基本信息。
主播用户可以在拍摄视频数据之前,向用户终端输入该视频数据的基本信息;也可以在将语音信息转化为字幕信息之后,向用户输入该视频数据的基本信息。
在拍摄视频数据之前,主播用户向用户终端输入该视频数据的基本信息的过程可以为:
直播界面中显示输入按钮,该输入按钮用于触发用户终端显示基本信息输入界面;主播用户向用户终端输入该视频数据的基本信息时,主播用户可以点击该输入按钮;用户终端检测到该输入按钮被触发时,显示基本信息输入界面;主播用户可以在该基本信息输入界面中输入该视频数据的基本信息;用户终端获取主播用户在该基本信息输入界面中输入的该视频数据的基本信息,并将该基本信息存储到指定存储区域中(例如,指定文件夹中)。
相应的,本步骤可以为:
用户终端检测指定存储区域中是否存储该视频数据的基本信息;如果存储,获取已存储主播用户输入的该视频数据的基本信息。
如果不存储,用户终端弹出基本信息输入界面,获取主播用户在该基本信息输入界面输入的基本信息。
例如,基本信息包括拍摄者、参与者、名称和简介;参见图2-2,则基本信息输入界面中包括拍摄者对应的第一输入框、参与者对应的第二输入框、名称对应的第三输入框和简介对应的第四输入框;主播用户可以在第一输入框中输入拍摄者姓名,在第二输入框中输入参与者姓名,在第三输入框中输入视频文件的名称,在第四输入框中输入视频文件的简介。
用户终端获取第一输入框中的拍摄者姓名、第二输入框中的参与者姓名、第三输入框中的视频文件的名称以及第四输入框中的该视频文件的简介。
进一步地,用户终端获取到该视频数据的基本信息时,还可以修改该基本信息,具体过程可以为:
用户终端获取主播用户输入的该视频数据的基本信息时,显示提示框,提示框中包括该基本信息、修改按钮和确认按钮。如果直播用户不需要修改该基本信息,则主播用户可以点击该确认按钮;用户终端检测到该确认按钮被触发时,执行步骤203。如果主播用户需要修改该基本信息,则主播用户可以点击该修改按钮;用户终端检测到该修改按钮被触发时,显示基本信息输入界面,该基本信息输入界面中包括主播用户已输入的基本信息;主播用户可以在该基本信息输入界面中修改该基本信息;用户终端获取主播用户修改后的基本信息,执行步骤203。
步骤203:用户终端根据该视频数据和文字信息,生成视频文件。
本步骤可以通过以下步骤2031-2032实现,包括:
步骤2031:用户终端在直播界面中显示合成按钮,检测到该合成按钮被触发时,获取该视频数据的片头信息和片尾信息。
直播界面中显示合成按钮,主播用户可以点击该合成按钮以触发合成命令给用户终端。用户终端检测到该合成按钮被触发时,生成合成命令,根据该合成命令,获取该视频数据的片头信息和片尾信息。
用户终端获取该视频数据的片头信息和片尾信息时,可以根据预设提取算法自动提取片头信息和片尾信息,也即以下第一种实现方式;也可以由主播用户手动选择图像帧得到片头信息和片尾信息,也即以下第二种实现方式。
对于第一种实现方式,用户终端获取该视频数据的片头信息和片尾信息可以通过以下步骤2031-1和2031-2实现,包括:
步骤2031-1:用户终端通过第一预设提取算法,提取视频数据的第一关键帧,得到视频数据的片头信息。
第一关键帧包括多个第一图像帧,则用户终端根据第一预设提取算法,从该视频数据中提取多个第一图像帧,并将该多个第一图像帧进行拼接,得到该视频数据的片头信息。
其中,第一预设提取算法可以根据需求进行设置并更改,本发明实施例中对于第一预设提取算法不作具体限定。例如,第一预设提取算法可以为基于采样的关键帧提取算法或者基于图像特征的关键帧提取算法等。
例如,第一预设提取算法为基于采样的关键帧提取算法,且采样周期为10;则用户终端根据第一预设提取算法,从该视频数据中提取多个第一图像帧的步骤可以为:
用户终端从该视频数据包括的图像帧中,每隔10帧图像选择一帧图像,得到多个第一图像帧。
再如,第一预设提取算法为基于图像特征的关键帧提取算法,则用户终端根据第一预设提取算法,从该视频数据中提取多个第一图像帧的步骤可以为:
用户终端计算该视频数据包括的每帧图像的特征值,根据每帧图像的特征值,从该视频数据中选择特征值最大的预设数目个第一图像帧。
预设数目可以根据需要进行设置并更改,在本发明实施例中,对预设数目不作具体限定;例如,预设数目可以为5或者10等。
步骤2031-2:用户终端通过第二预设提取算法,提取视频数据的第二关键帧,得到视频数据的片尾信息。
第二关键帧包括多个第二图像帧,则用户终端根据第二预设提取算法,从该视频数据中提取多个第二图像帧,并将该多个第二图像帧进行拼接,得到该视频数据的片尾信息。
第二预设提取算法可以根据需求设置并更改,在本发明实施例中对第二预设提取算法并不作具体限定。并且,第二预设提取算法可以与第一预设提取算法相同,也可以与第一预设提取算法不同。例如,第二预设提取算法为基于采样的关键帧提取算法或者基于图像特征的关键帧提取算法等。
对于第二种实现方式,用户终端获取该视频数据的片头信息和片尾信息可以通过以下步骤2031-3和2031-4实现,包括:
步骤2031-3:用户终端获取主播用户从图像库中选择的第三关键帧,得到视频数据的片头信息。
第三关键帧包括多个第三图像帧;用户终端显示第一选择界面,该第一选择界面中包括图像库中的每个图像帧的缩略图,主播用户可以根据每个图像帧的缩略图中,从图像库中选择多个第三图像帧;用户终端获取主播用户选择的多个第三图像帧,将多个第三图像帧进行拼接,得到该视频数据的片头信息。
图像库中可以包括该视频数据包括的每个图像帧,也可以包括多媒体服务器中设置的预设图像帧。
步骤2031-4:用户终端获取主播用户从图像库中选择的第四关键帧,得到视频数据的片尾信息。
第四关键帧包括多个第四图像帧,用户终端显示第二选择界面,该第二选择界面中包括图像库中的每个图像帧的缩略图,主播用户可以在根据每个图像帧的缩略图中,从图像库中选择多个第四图像帧;用户终端获取主播用户选择的多个第四图像帧,将多个第四图像帧进行拼接,得到该视频数据的片尾信息。
步骤2032:用户终端将片头信息、片尾信息和视频数据进行拼接,将文字信息插入拼接后的视频数据中,得到视频文件。
其中,用户终端将片头信息、片尾信息和视频数据进行拼接的步骤可以为:
用户终端将该片头信息的最后一帧图像与该视频数据的第一帧图像进行拼接,将该视频数据的最后一帧图像和该片尾信息的第一帧图像进行拼接,得到拼接后的视频数据。
其中,用户终端将文字信息插入该拼接后的视频数据中,得到视频文件的步骤可以通过以下步骤2032-1和2032-2实现,包括:
步骤2032-1:用户终端将文字信息中的字幕信息插入该拼接后的视频数据中。
对于拼接后的视频数据中的每个图像帧,用户终端根据该图像帧,从图像帧和字幕信息的对应关系中,获取该图像帧对应的字幕信息,将该字幕信息插入该图像帧中。
需要说明的是,用户终端可以将该字幕信息插入该图像帧中的任一位置;例如,将该字幕信息插入该图像帧的底部或者上部等。
步骤2032-2:用户终端将文字信息中的基本信息插入该拼接后的视频数据中,得到视频文件。
用户终端将文字信息中的基本信息插入到拼接后的视频数据中的片头信息和片尾信息包括的图像帧中。
用户终端根据该基本信息,从片头信息和片尾信息中选择显示该基本信息的图像帧,将该基本信息显示在选择的图像帧中。
例如,基本信息包括拍摄者、参与者;用户终端可以将基本信息中的拍摄者和参与者插入片头信息的前100帧图像帧中,将基本信息中的名称、简介等插入到片头信息的第100-200帧图像帧中。将基本信息中的赞助、背景音频名称、拍摄地点、拍摄时间等插入到片尾信息的图像帧中。
进一步地,用户终端还可以获取音频信息,将音频信息插入到该视频文件中;其中,音频信息可以为音乐文件。
步骤204:用户终端向多媒体服务器上传该视频文件。
直播界面中显示上传按钮,主播用户可以点击该上传按钮以触发上传命令给用户终端。用户终端检测到直播界面的上传按钮被触发时,生成上传命令,根据该上传命令,获取主播用户的用户标识,向多媒体服务器上传主播用户的用户标识和视频文件。
主播的用户标识可以为主播在多媒体服务器中注册的用户账号或者昵称等。
多媒体服务器接收用户终端发送的该主播用户的用户标识和该视频文件,将该视频文件的视频标识添加到该主播用户的视频列表中。
进一步地,用户终端还可以向多媒体服务器上传该视频文件的封面,多媒体服务器接收用户终端发送的该视频文件的封面,关联该封面和该视频文件的播放地址,将该封面添加到该主播用户的主界面中。例如,多媒体服务器将该视频文件的封面添加到该主播用户的个人作品中心。
主播用户或者观众用户可以点击该视频文件的封面,以请求观看该视频文件;多媒体服务器检测到该封面被点击时,根据该封面,从封面和视频文件的播放地址的对应关系中获取该视频文件的播放地址,根据该播放地址,向用户终端或者观众终端发送该视频文件的视频流。
可选的,主播用户还可以在录制视频文件过程中,实时向观众用户发送该视频文件,具体过程可以为:
在直播界面中显示直播按钮,用户终端检测到该直播按钮被触发时,在拍摄过程中,通过多媒体服务器向观众用户终端发送该视频文件。
其中,用户终端通过多媒体服务器向观众用户终端发送该视频文件的步骤可以为:
用户终端获取主播用户的用户标识,向多媒体服务器发送该主播用户的用户标识和视频文件。多媒体服务器接收该主播用户的用户标识和视频文件,根据该直播用户的用户标识,获取当前观看该主播用户的观众用户的用户标识,根据当前观看该主播用户的观众用户的用户标识,向用户终端发送该视频文件的视频流。
观众终端接收多媒体服务器发送的视频文件的视频流,播放该视频流,从而实现主播用户在拍摄过程中将视频文件直播给观众用户。
需要说的是,如果主播用户在拍摄过程中将视频文件直播给观众用户时,该视频文件仅包括字幕信息,不包括片头信息和片尾信息。
在本发明实施例中,用户终端可以直接通过直播应用的直播界面进行拍摄得到视频数据,并获取该视频数据对应的文字信息,用户终端直接将该视频数据和文字信息合成视频文件,并向多媒体服务器上传该视频文件,省略了拷贝视频数据等步骤,操作过程简单,提高了用户终端向多媒体服务器上传视频文件时的上传效率。
本发明实施例提供了一种向多媒体服务器上传视频文件的装置,该装置可以应用在用户终端,用于执行上述向多媒体服务器上传视频文件的方法。
参见图3,该装置包括:
拍摄模块301,用于在主播用户的直播界面中显示录制按钮,检测到录制按钮被触发时,开始进行拍摄,得到视频数据;
获取模块302,用于在拍摄过程中,获取拍摄得到的视频数据对应的文字信息;
生成模块303,用于根据视频数据和文字信息,生成视频文件;
上传模块304,用于向多媒体服务器上传视频文件。
可选的,该获取模块302,包括:
识别单元,用于提取视频数据中的语音信息,识别语音信息,得到字幕信息;
第一获取单元,用于获取主播用户输入的视频数据的基本信息。
可选的,该生成模块303,包括:
第二获取单元,用于在直播界面中显示合成按钮,检测到合成按钮被触发时,获取视频数据的片头信息和片尾信息;
插入单元,用于将片头信息、片尾信息和视频数据进行拼接,将文字信息插入拼接后的视频数据中,得到视频文件。
可选的,该第二获取单元,包括:
第一提取子单元,用于通过第一预设提取算法,提取视频数据的第一关键帧,得到视频数据的片头信息;
第二提取子单元,用于通过第二预设提取算法,提取视频数据的第二关键帧,得到视频数据的片尾信息。
可选的,该第二获取单元,包括:
第一获取子单元,用于获取主播用户从图像库中选择的第三关键帧,得到视频数据的片头信息,图像库中包括多个图像帧;
第二获取子单元,用于获取主播用户从图像库中选择的第四关键帧,得到视频数据的片尾信息。
可选的,该装置还包括:
发送模块,用于在直播界面中显示直播按钮,检测到直播按钮被触发时,在拍摄过程中,通过多媒体服务器向观众终端发送视频文件。
在本发明实施例中,用户终端可以直接通过直播应用的直播界面进行拍摄得到视频数据,并获取该视频数据对应的文字信息,用户终端直接将该视频数据和文字信息合成视频文件,并向多媒体服务器上传该视频文件,省略了拷贝视频数据等步骤,操作过程简单,提高了用户终端向多媒体服务器上传视频文件时的上传效率。
需要说明的是:上述实施例提供的向多媒体服务器上传视频文件的装置在向多媒体服务器上传视频文件时,仅以上述各功能模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能模块完成,即将装置的内部结构划分成不同的功能模块,以完成以上描述的全部或者部分功能。另外,上述实施例提供的向多媒体服务器上传视频文件的装置与向多媒体服务器上传视频文件的方法实施例属于同一构思,其具体实现过程详见方法实施例,这里不再赘述。
本领域普通技术人员可以理解实现上述实施例的全部或部分步骤可以通过硬件来完成,也可以通过程序来指令相关的硬件完成,所述的程序可以存储于一种计算机可读存储介质中,上述提到的存储介质可以是只读存储器,磁盘或光盘等。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!