一种自动识别web爬虫的方法与流程
本发明涉及web爬虫领域,具体涉及一种自动识别web爬虫的方法。
背景技术:
当前网站对网络爬虫识别的方法多种多样,最有效并且广为使用的方法是提供交互式的组件,来鉴别客户端是真实用户还是网络爬虫,例如验证码等。但是此方式会在某种程度上影响用户的上网体验。
爬虫在抓取网站页面的过程中,会对首页进行爬取。同时由于爬虫通常不会重复爬取具有相同URL的页面,可以以此来识别请求是否来自爬虫程序。现有技术中,在页面中放置暗链做蜜罐来识别爬虫,或者根据爬虫的特征信息(HTTP头部等)作为识别依据。但暗链是可被识别的,计算头部信息需要额外的资源消耗。
相关术语:
onload:浏览器会在页面加载完后执行onload中的函数;爬虫:用来抓取网页信息的应用程序;重定向:就是通过各种方法将网络请求重新定位到其他位置,(如:网页重定向,域名重定向等);网页去重:爬虫抓取网页信息时,通过计算两个页面的相似度来判断两个页面是否相似或相同,从而避免重复爬取;URL:统一资源定位符,俗称为网址;Cookie:网站为了辨别用户身份存储于用户处的数据。
技术实现要素:
本发明所要解决的技术问题是提供一种自动识别web爬虫的方法,通过多次重定向和设置cookie来拦截来自网络爬虫的请求,不影响用户上网体验。
为解决上述技术问题,本发明采用的技术方案是:
一种自动识别web爬虫的方法,包括以下步骤:
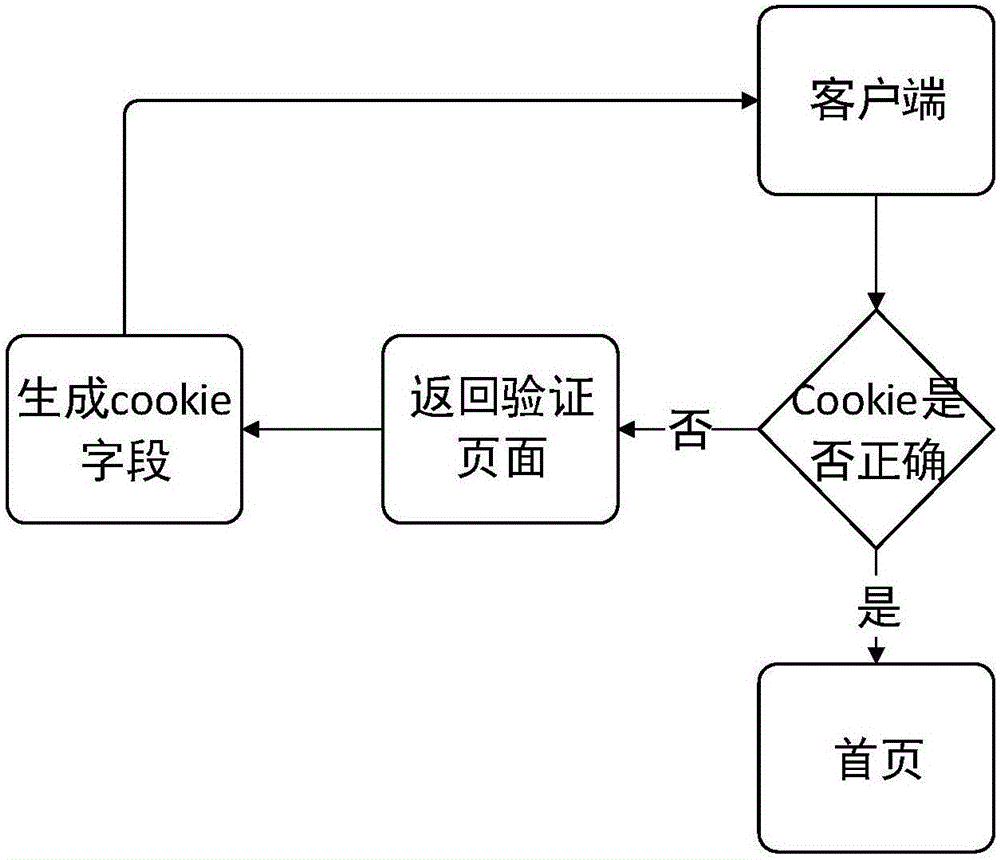
步骤1:服务器首页返回只包含JS代码的页面,这段代码位于onload函数中,在页面完全加载后被执行;
步骤2:步骤1所述的JS代码采用第一种对称加密算法通过Set-Cookie头部设定一个cookie字段,然后使用window.location跳转到首页;服务器检测cookie合法则返回另一段JS代码,另一段JS代码采用第二种对称加密算法设定cookie字段;
步骤3:当所有的cookie字段都合法,则返回正常的首页URL;
步骤4:若客户端没有进行重定向操作,或者cookie值不正确,则设置badcookie,标记为爬虫。
根据上述方案,所述步骤1、2、3重复若干次,但不超过浏览器设置的重定向上限。
根据上述方案,所述第一种对称加密算法为DES、TripleDES、RC2、RC4、RC5和Blowfish中的一种,所述第二种对称加密算法为DES、TripleDES、RC2、RC4、RC5和Blowfish中的一种,且与第一种对称加密算法不相同。
与现有技术相比,本发明的有益效果是:1)能阻挡大部分静态爬虫的访问,如果爬虫无法执行首页的JS代码,则只能爬到服务器返回的只有JS代码的首页,无法获取真实首页。2)只要爬虫具有去重功能,也会因为跳转到相同页面导致无法继续爬取。3)本方法适用的页面包括但不限于首页,可以在网站的任意页面中采用,有效防止爬虫采集信息。
附图说明
图1是本发明一种自动识别web爬虫的方法流程示意图。
具体实施方式
下面结合附图和具体实施方式对本发明作进一步详细的说明。通过在网页中嵌入javascript一次或者多次重定向到同一页面,同时返回状态码,使得爬虫因为去重无法正常爬取页面。执行onload中的javascript代码指定的cookie或者badcookie,识别请求是否来自爬虫。
服务器首页返回只包含JS代码(JavaScript编写的脚本文扩件的代码)的页面,这段代码位于onload函数中,在页面完全加载后被执行。这段JS代码会采用某种算法(IP,头部等信息作为算法参数)设定一个cookie字段,然后使用window.location跳转到首页(本页面)。服务器检测cookie合法则返回另一段JS,该JS代码采用另一种算法设定cookie字段。根据网站需要,前述步骤可以重复若干次,但不能超过浏览器设置的重定向上限。只有所有的cookie字段都合法的情况下,才会返回正常的首页URL。若客户端没有进行重定向操作,或者cookie值不正确,则可以设置badcookie,标记为爬虫。同时可以根据服务器请求记录中的请求次数判定是爬虫,比如第一次get请求就包含所有正确cookie的一定是爬虫。
本发明所涉及的算法为对称的加密算法,主要有DES、TripleDES、RC2、RC4、RC5和Blowfish。为了防止用户预先在浏览器中访问页面获取正确cookie,可在网站的每一级页面目录中都添加一个具有同样功能的页面,来强化反爬虫的效果。
- 还没有人留言评论。精彩留言会获得点赞!