基于事件滑动窗口的攻击模式检测方法与流程
本发明涉及数据挖掘在网络攻击识别等领域的应用,具体的讲是基于事件滑动窗口的攻击模式检测方法。
背景技术:
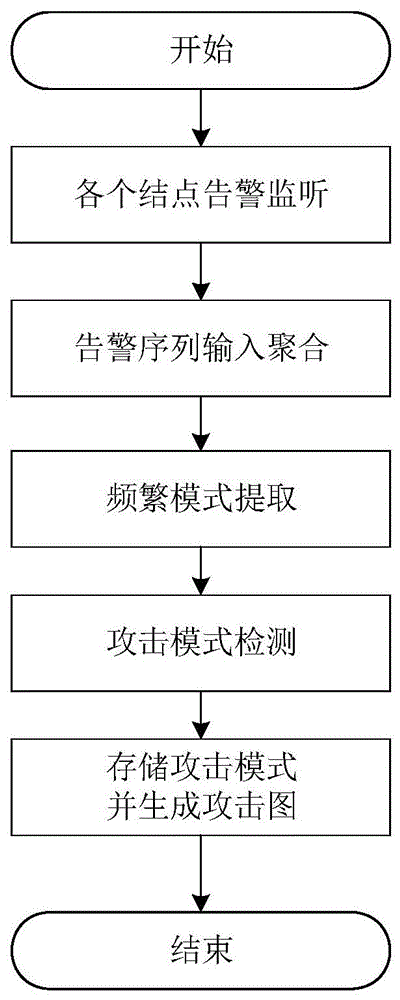
:分布式计算的出现和普及,为处理海量数据提供了便捷的操作。同时,网络安全也是当前各领域关注的问题。针对网络环境中的关键信息的资源和威胁数量都在急剧上升,如何通过相关数据进行分布式分析,对网络攻击行为做出主动反应,是网络安全领域近年来的研究热点。在通过分析日志文件对网络安全态势进行评估已得到越来越广泛的认可。然而在目前的分布式日志关联分析和其它分析的系统中,都是对已知可见的小规模数据分块进行并安全性分析,但应对目前不断更新且海量规模的日志文件,特别是日志流和异构网络环境时,其工具和分析方式,都无法较好的胜任采集与分析任务,并且缺乏对整体日志数据的综合分析,并不能够及时应对日志分析和安全防护。而且在大型特别是集群系统中,由于其网络的复杂性,由其它网络安全设备、负载均衡设备带来的诸多不确定因素,也需要采集、分析能力更为强劲,部署更为灵活的分布式日志关联分析系统。告警日志文件在当今的系统和集群管理中,承担了越来越重要的角色。因为告警日志文件中的一些有价值的事件记录,例如错误、执行跟踪或者程序内部状态的统计信息,能够反映访问者的意图。因此对于异常检测来说,告警日志的挖掘能够帮助我们更好的识别潜在或者已经存在的攻击模式。技术实现要素:本发明提供了一种基于事件滑动窗口的攻击模式检测方法,以更高效准确的挖掘告警日志中存在的攻击模式,并实现识别或者拦截新的入侵访问行为。本发明基于事件滑动窗口的攻击模式检测方法,包括:S1.由于检测环境是分布式集群,且每一种应用对应着一种告警源,因此首先需要进行告警聚合,并且在聚合的过程中完成收集、预处理和压缩:监听各告警源的告警信息,并将各告警信息归一化,使各告警信息都有相同的属性,将各告警信息按照属性进行整合压缩和预处理,以删除无效告警或重复告警等干扰分析判断的数据,然后将属性相似度接近的告警信息聚合为超告警,所述属性可以包括目的地址、源地址和/或目的端口、告警等级等;S2.对指定时间范围内超告警的频繁项根据因果关联矩阵规约为频繁关联序列模式;S3.在每一次提取频繁项的过程中,不同告警信息之间的关联系数会出现波动,因此需要在提取过程中,调整所述因果关联矩阵中的每一个值,需要对每一次新的频繁关联序列模式,以及有不同属性的频繁关序列联模式的告警对,根据其属性之间的特性计算新的关联系数,然后将各参与计算关联系数的属性按权重进行加权平均,计算后的结果放入因果关联矩阵对应的单元格中;S4.将新得到的频繁关联序列模式生成符合入侵特征的攻击模式图。本发明通过对告警信息的日志数据进行预处理、聚合,按照时间存入告警日志流后,基于事件滑动窗口的攻击模式挖掘方法提取出其中的频繁关联序列模式,并计算用于更新因果关联矩阵,从而根据新得到的攻击模式生成符合入侵特征的攻击模式图。并且测试得知,本发明的方法在海量且看似无意义的告警日志中挖掘攻击模式的准确率和速率较传统的序列模式挖掘方法均有显著的提升效果。一种优选的方式为,步骤S2中,对所述超告警按单元时间分块,单元时间可以为小时或分钟等。每个分块内切分为指定大小的窗口,并记录每个窗口号的大小,对每个窗口超告警的频繁项进行所述规约。进一步的,所述每个窗口的超告警包括相邻ρ个窗口内的超告警,ρ为回溯系数。这样可以进行跨窗口的频繁项提取。回溯系数ρ的值决定了搜索窗口的数量,以便发现更长的关联模式。进一步的,步骤S3所述告警对的不同属性可以包括告警对的各频繁关序列联模式的时间属性或窗口号属性。一种优选的方式是步骤S4所述的攻击模式图为攻击树。攻击树有根节点和子节点,能够很清楚的反映出各种告警信息之间的关联关系。所述攻击树的一种生成方法为,先对新得到的频繁关联序列模式取出具有相同开头的序列,然后将序列的开头结点插入到只含有空结点的树结构中,再将其它结点按顺序插入到符合当前结点关联性的结点下,最后生成攻击树。可选的,步骤S1中通过IDMEF格式(入侵检测消息交换格式)对各告警信息归一化,也可以采用其它适合的格式或自定义格式。本发明基于事件滑动窗口的攻击模式检测方法,能够更加高效、准确的挖掘告警日志中存在的攻击模式,并快速实现识别或者拦截新的入侵访问行为,在海量且看似无意义的告警日志中挖掘攻击模式的准确率和速率均有大幅度的提升。以下结合实施例的具体实施方式,对本发明的上述内容再作进一步的详细说明。但不应将此理解为本发明上述主题的范围仅限于以下的实例。在不脱离本发明上述技术思想情况下,根据本领域普通技术知识和惯用手段做出的各种替换或变更,均应包括在本发明的范围内。附图说明图1为本发明基于事件滑动窗口的攻击模式检测方法的流程图。具体实施方式如图1所示本发明基于事件滑动窗口的攻击模式检测方法,包括:S1:告警聚合:由于检测环境是分布式集群,且每一种应用对应着一种告警源,在聚合的过程中完成收集、预处理和压缩,步骤为:S11:通在不同的告警源头上设置代理,每个代理感知对应告警源产生的信息,并按照一定的比率监测,如果监测到新的告警,则发送到传输队列中。利用Flume日志收集开源技术,对收集代理源、传输管道和收集沉降进行有效的配置。S12:对产生的告警信息,进行信息转化,转化为告警日志后,再进行传输。S13:对传输队列中的告警,按照IDMEF(入侵检测消息交换格式)标准或者类似的自定标准格式进行数据格式归一化,使每一种告警都拥有同样的属性,以便后期挖掘更多的信息。S14:按照来源IP、目的IP和/或告警等级等属性对汇聚的日志信息进行整合压缩和预处理工作,删除无效告警或重复告警等干扰分析判断的数据。通过判定两条告警信息之间的相似度,如果在某些特定的属性,如目的地址,源地址、目的端口等属性相似度高,则判定为重复告警,进行告警聚合为超告警。假设告警信息的集合为A={δi,i=1,2...},其中δi是一个超告警,δi聚合了众多聚合后的告警信息δi={a(i,1),a(i,2),a(i,3),....a(i,n)},其中1<i<n,n为a告警的数目,这些告警信息含有相同的属性,如同端口或同源IP地址,但是在记录的时间上稍有不同,其中每个告警信息由若干个属性值组成,如a(i,j)=(u1,u2,u3...),ui为属性。聚合后的超告警,按照记录时间存储到离线告警数据库中。S2:提取指定日期范围的超告警,提取其中的频繁项,过程为:S21:将取指定日期范围的告警信息按照小时进行分块,每个分块内按照指定的窗口大小Δ=L切分为若干个窗口,并记录每个窗口号的大小。S22:设定最小支持度min_sup,和告警的重要系数计算函数I(a),重要系数计算函数I(a)决定了因子为出现次数、告警的等级(Error、Warning、Info)等,视不同的场景决定。对每个窗口内的告警信息进行频繁项的提取。同时对于不同的告警,根据告警的属性(如次数、等级)设定相对应的重要因子,将重要因子代入重要系数计算函数I(a),则为:Ι:ID→(0,∞),其中ID为重要因子,输入为告警类型,返回一个重要因子,重要因子数值越高,重要性越大,则对应的最小支持度阈值越低。告警类型a的最小支持度为:S23:设定回溯系数ρ,相邻ρ个窗口内,进行跨窗口频繁项提取,回溯系数决定了搜索窗口的数量,以便发现更长的关联模式。S24:提取出的频繁项根据因果关联矩阵进行规约,规约后的频繁项称之为频繁关联序列模式。其中两种告警之间的最小置信度为min_conf。S25:对每个分块都执行S22、S23和S24三个步骤,将相邻分块的输出再进行跨窗口关联,调用S23、S24步骤,将新生成的频繁关联序列模式存入攻击模式库中。例如有如下的攻击序列:AKAKACDAKK|BCBBCCCDCF|FDDAFDAFAD我们令L=10,最小支持度min_sup=3,最小阈值τ=0.5,其中L为上述攻击序列中每个分块的字母个数,min_sup和τ都为根据实际场景中的经验计算得到的经验值,可以根据本领域中数据挖掘的关联规则进行设定和计算,由于上述攻击序列为3个窗口,因此设置回溯系数ρ≥2,攻击类型对应的因果关联矩阵CCM如表1所示,表1中的数据参见“RamakiAA,AminiM,AtaniRE.RTECA:Realtimeepisodecorrelationalgorithmformulti-stepattackscenariosdetection[J].Computers&Security,2014”,第49期的期刊的206~219页。同时假设每个告警的重要系数相同,即计算的支持度大小均为min_sup。表1:AlertABCDKFA0.20.70.10.30.60.2B0.20.30.10.80.10.7C0.40.10.20.70.30.4D0.30.40.10.30.80.2K0.30.20.90.10.40.3F0.10.90.20.50.10.3当接收到第一个窗口内的告警时,计算出该窗口内的MSPs(最大序列模式),例如表1所示,根据对支持度的计算,对比出现的频数是否大于最小支持度min_sup,得到最大频繁关联序列模式AK,并根据最大频繁关联序列模式,查找CCM,过滤其中不符合最小阈值τ的频繁关联序列模式,如表2所示,并标记上窗口号为1。KA不满足因果关联矩阵CCM的最小阈值,所以不计入FCSP(频繁关联序列模式)表格中:表2:窗口号最大序列模式(MSP)1AK表3为第一个窗口提取到的频繁关联序列模式:表3:频繁关联序列模式(FCSP)窗口号A1K1AK1当收到下一个窗口的告警时,先挖掘出此窗口内的MSPs,然后生成FCSPs如表4。在此窗口中BC是一个频繁模式,但是根据因果关联矩阵CCM,BC的因果关联度小于最小阈值τ,因此BC并不能加到频繁关联序列模式表中。表4:窗口号最大频繁序列模式(MSP)1AK2BC同时,从频繁关联序列模式表中已有的项中,可以挖掘出更长的FCSPs。例如,AK是一个FCSP,此FCSP属于第一个滑动窗口。AK在C之前出现,所以根据因果关联矩阵,K和C是相关的,因为AK和KC都是频繁关联的,而AKC的支持度已经大于最小支持度min_sup了,所以相邻的频繁模式在关联矩阵中且大于最小阈值τ,因此AKC也是一个FCSP。所有的FCSP都可以通过此种方法生成,见表5所示的前三个窗口频繁关联序列模式(第3个窗口没有FCSP)。表5:频繁关联序列模式(FCSP)窗口号A,K,AK1B,C,AB2KC2AKC2表5中的窗口号以字母最后出现的窗口为准。第三个窗口也可以按照上述的描述生成进行操作。表6和表7是前三个窗口生成的最大频繁序列模式MSPs和频繁关联序列模式FCSPs。表6:窗口号最大频繁序列模式(MSP)1AK2BC3FD,A表7:频发关联序列模式(FCSP)窗口号A,K,AK1B,C,AB2KC,AKC2F,D,FD,3BF3ABF3BD3BFD3ABFD3CD3KCD3AKCD3S3:因果关联矩阵更新:在每一次提取频繁项的过程中,不同告警信息之间的关联系数会出现波动,因此需要在提取的过程中,调整因果关联矩阵中的每一个值:S31:根据告警数据库的历史记录,对上述MSP和FCSP所示表格的矩阵进行初始化,包括对数据的预处理、格式规整等,方便后续处理。每一次新的频繁关联模式,根据属性之间的特性计算新的关联系数,例如对IP地址属性可以采用公式IP(ips1,ips2)计算关联系数:IPSim函数ipsim(IPi,IPj)=k/32用来计算两个IP之间的相似度,其中k表示两个IP地址之间相同的比特位数,IPSim公式用来计算相似系数。同理还可以推出端口相似系数计算函数,如下公式,函数Portmatching用于计算两组端口之间的相似度,如果两个端口号相同,则函数值为1,否则为0。利用上述方法,两组超告警信息a1和a2之间的相似系数如下公式:sim(a1,a2)=w1IPSim(ipsi,ipsj)+w2PortMatching(portsi,portsj)其中IP的相似度w1和端口w2表示对应的权重,大部分情形下设定w1>w2,因为IP的相似度比端口相似度更重要。S32:如果提取的频繁关序列联模式的告警对,存在时间上的间隔的变化,或者窗口号间隔的变化,则重新计算这两种告警信息之间的关联系数。参与计算的属性还有如目的端口、源端口、目的地址等属性,此处不采用源地址属性,因为现有的攻击模式大多存在伪造IP行为,因此源地址并不具备实际意义。S33:将每一种参与计算关联系数的属性按照权重进行加权平均,计算后的结果放入到因果关联矩阵对应的单元格中。将提取的新的攻击模式放入到攻击策略挖掘库中,这些攻击模式可能是以下情形之一:①误警②良性告警片段③未知攻击模式。为了从这些未知告警中区分出误警。对于一个序列片段如e=<A1,...,An>,其中n>1,并且Ai是一个超告警,如果一个片段满足下列条件之一,则定义为了一个有害序列模式。1、在因果关联矩阵中,如果序列片段e中的一个超告警Ak不在其中,即告警类型为新的。2、3、4、5、θ2为平均阈值。其中n为进入有效统计的告警总数。以上公式表明,一些属性之间的相似度计算的平均值,如果大于了给定的阈值θ1,则认定为有害告警。而对于公式1中新的告警类型,则将其加入到因果关联矩阵中,即添加一行一列,对新增的每一个单元格设定初始值为0,并将以后挖掘到的包含此告警类型的序列纳入攻击模式分析中。S4:离线分析结束后,将提取出的频繁项构建生成攻击树,步骤为:S41:对频繁项中的多个频繁关联序列模式,取出具有相同的开头的序列。S42:将S41中序列的开头结点插入到只含有空结点的树中,此后将其它的结点按照S41中的顺序依次插入到符合当前结点关联性的结点下。S43:生成攻击树,存储到告警攻击模式结果数据库中。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1