根据软采信令的自适应指纹定位方法与流程
本发明涉及移动通信领域中的无线业务支撑领域,具体涉及一种根据软采信令的自适应指纹定位方法。
背景技术:
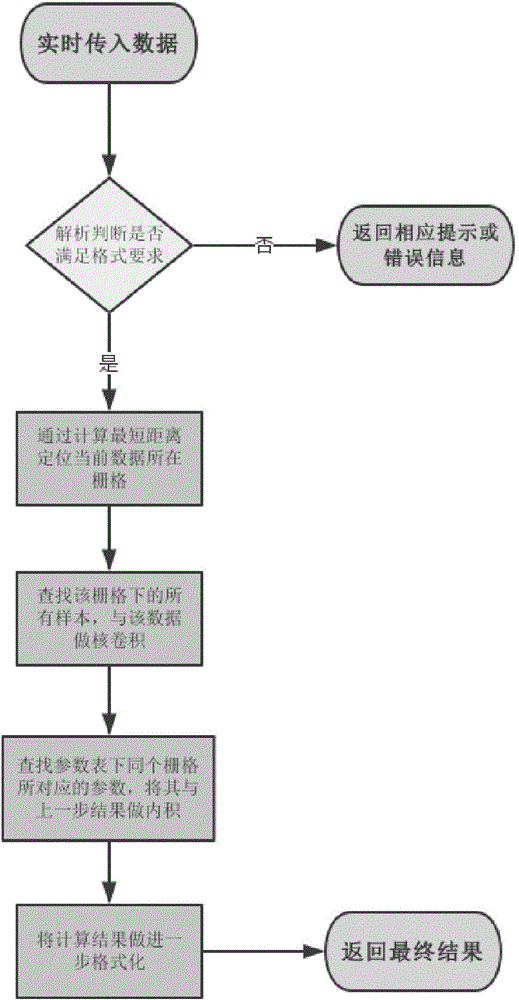
:在商业应用领域里,移动通信网络定位技术主要应用在基于位置的服务(LocationBasedService,LBS)方面。移动定位技术在其商业应用的开发来说,目前不过是刚刚起步,除了某些特定的跟踪或监测用途,作为民用的巨大商业潜力尚待进一步的开发。根据移动用户的位置,为用户提供与位置相关的各项服务,如用户定位、服务推介等,将成为未来手机业务中的主流趋势。现有的移动终端定位方法主要有以下几种:(1)通过卫星定位(以GPS为代表)。(2)通过信号到达时间(TOA)、到达时间差、信号到达角度(AOA)或者以上几种指标综合使用的混合定位方法。(3)使用小区ID+时间提前量(CellID+TA)定位方法,即利用移动台所占用的服务小区位置信息以及服务小区的TA进行定位。现有移动终端定位方案存在以下问题:(1)通过卫星定位(以GPS为代表),在室外可以获得较高的定位精度(误差在10-50米)。然而,GPS定位需要手机终端具有GPS定位功能,一般只有智能手机满足,普通的手机无法满足;GPS无法在室内进行定位,且GPS定位是基于智能手机第三方的软件的,网络侧很难获得用户的定位信息,即使获得第三方软件的数据,也涉及到数据解密等步骤而难以应用。(2)通过信号到达时间(TOA)、到达时间差、信号到达角度(AOA)或者混合定位方法,定位误差一般都在200米以上,无法满足高精度的定位要求。(3)使用小区ID+时间提前量(CellID+TA)定位方法,即利用移动台所占用的服务小区位置信息以及服务小区的TA进行定位,这种方式对通信网络增加的负担较小,但是定位精度较低。另外也有通过测量信号强度,然后用传播模型计算距离的方法来定位的技术,但由于无线传播环境的不同,这种方法也存在误差比较大的问题。鉴于此,现有技术针对GSM网络提出了多种基于SVR(支持向量回归)的指纹匹配定位技术。通过对终端设备向基站上传的测量报告(MeasurementReport,MR)及不同网络覆盖区域的指纹样本库进行相关计算,得到最佳匹配位置。随着移动通信网络的演进,新型的LTE网络开始普及;然而,在LTE网络扁平化后,原来在2、3G时代能直接采集的测量报告(MR)数据,无法方便的采集到,这给指纹定位方法在LTE网络中的实施造成了阻碍;而通过LTE的信令软采集方式,可以从主设备上获取到这些MR数据和Uu口相关消息;因此,在LTE软采集信令分析系统上实现指纹定位技术变得可能。现在,急需涉及一种,根据LTE软采信令进行高精度指纹定位的方法。技术实现要素:针对现有技术中存在的缺陷,本发明的目的在于提供一种根据软采信令的自适应指纹定位方法,通过该方法能够有效提高定位精度。本发明采用的方案为:根据软采信令的自适应指纹定位方法包括以下步骤:第一步,离线路测采样和模型训练阶段,具体包括:(1)离线路测采集阶段:通过路测终端采集路测信息,得到测量报告;所述测量报告中包括路测终端的位置坐标、测量报告中所涉及到的小区的标识信息以及测量报告在其所涉及到的每个小区上的场强数据、时延数据和方向角数据;(2)模型训练阶段:将每个测量报告作为一条训练样本,构建定位指纹库,并根据定位指纹库生成在线定位模型,包括:(2-1)将所述移动网络覆盖区域划分为边长为L的栅格,并将栅格编号根据路测终端的位置坐标,将训练样本分配到对应的栅格中;(2-2)将栅格的编号作为位于该栅格的训练样本的分类标识,分类标识和训练样本共同组成指纹数据记录储存在定位指纹库中;(2-3)采用支持向量回归算法对同一栅格内的训练样本进行处理,得到每个栅格的SVR定位模型,用于计算带定位移动终端所处的经度和纬度;(2-4)将所述SVR定位模型作为在线定位模型进行存储;第二步,在线定位阶段,具体包括:通过信令软采集获取待定位移动终端的测量报告,获取测量报告中所涉及到的小区的标识信息以及测量报告在其所涉及到的每个小区上的场强数据、时延数据和方向角数据;根据该测量报告中所涉及到的小区的标识信息,从定位指纹库中筛选涉及相同小区的指纹数据记录;将筛选出的每个指纹数据记录所包含的训练样本与在线传入的移动终端的测量报告计算欧氏距离;并从中筛选得到欧氏距离最小的训练样本,根据其所对应的栅格,选定该栅格为目标栅格;将目标栅格下的样本数据与SVR定位模型离线学习得到的参数,进行卷积计算,得到最终的预测经纬度。第三步,定位指纹数据库自适应更新阶段和SVR定位模型自适应更新阶段,具体包括:定位指纹数据库自适应更新阶段:根据步骤(1)采集新的测量报告,并根据步骤(2-1)和(2-2)形成备用指纹数据记录;根据所处栅格的SVR定位模型量化每一条指纹数据记录对于定位计算结果的影响程度,并标记每一条指纹数据记录的入库时间;根据量化的影响程度和入库时间更新定位指纹库,包括:根据指纹数据记录的入库时间,筛选入库的时长超过设定时间段的指纹数据记录;将筛选出的记录中量化的影响程度小于设定值的记录剔除;如果定位指纹数据库内指纹数据记录的数量低于设定数量,则补充新采集的备用指纹数据记录进指纹数据库;SVR定位模型自适应更新阶段,包括:如果某一栅格内的指纹数据记录被剔除和/或补入,则根据剔除和/或补入后的指纹数据记录更新该栅格的SVR定位模型。本方案的有益效果在于:本方案通过信令软采实现了移动终端的精确定位,适合于应用到当前最新的LTE通信网络;通过最小欧氏距离值进行栅格删选,实施简单且有效,工作效率高;因为SVR定位算法输出精度受样本数据的质量、数量影响较大,因此在达到一定数量前需要持续的补入以满足数量上的需要;同时需按照样本数据的质量(其对于定位结果的量化后的影响程度)剔除影响较小的样本数据并更新SVR定位模型,避免SVR定位模型有过多的无效计算而增加有效计算;因此通过定位指纹库的自我更新迭代机制,将使得整个定位方法的精度在一定程度上不断提高。另外栅格内的电磁环境也会因为栅格内建筑物、树木等障碍物的改变而不断发生变化,导致原先采集的样本数据丧失准确性,本方法,采取持续采集新样本数据的步骤,通过周期性的剔除旧的样本数据以及添入新采集的样本数据,保证了定位模型的效力不因栅格环境因素发生过大改变而下降。通过不断更新指纹库,使得指纹库样本达到相对优选的数量,同时通过更新迭代保持样本数据的质量、准确性维持在较高水平,进而随每次更新所产生的SVR定位模型更为精确,从而保证了整个方法的定位精度。综上所述,本方案通过定位指纹库的自我更新迭代机制,将使得整个定位方法的精度在一定程度上不断提高。可选的,步骤(2)中,构建定位指纹库之前,对采集到的测量报告进行筛选,将符合要求的测量报告数据用于构建定位指纹库;所述标准为:①测量报告数据中所涉及的小区个数大于等于4;②时延数据数值小于等于所采用测量报告数据标准允许的最大值;③测量报告数据所涉及的小区与该数据采样点的距离小于等于3000米。这样,保证每个测量报告都是可靠的以及携带了足够的信息,保证指纹库内存在的制文数据记录的质量。可选的,步骤(2)中,构建定位指纹库之前,将测量报告中的各测量值进行归一化预处理,将处理后的测量报告作为训练样本,构建定位指纹库。这样每个维度对于预测的影响程度得到了平衡,不会因为某个数值的绝对值较大而对定位计算产生更多影响;平衡后的各参数值使得定位结果更为精确。可选的,第三步中指纹数据记录的剔除步骤具体还包括:为每一条指纹数据记录添加删除/保留标记;以及,将根据入库时间筛选出记录中量化的影响程度小于设定值的记录标记为删除;当到达更新定位指纹库的指定时间时,从所述定位指纹库中剔除所有标记为删除的指纹数据记录。可选的,在第三步中的定位指纹数据库自适应更新阶段,如果定位指纹数据库内指纹数据记录的数量低于设定数量,则当到达更新定位指纹库的指定时间时,补充新采集的备用指纹数据记录进指纹数据库。可选的,还包括为每一条指纹数据记录添加版本标记的步骤,并且在第三步中的SVR定位模型自适应更新阶段,将新添加的记录的通过版本标记进行标记;当到达更新定位指纹库的指定时间时,通过版本标记和删除/保留标记判断一栅格内的指纹数据记录是否被剔除和/或补入,如果是,则根据剔除和/或补入后的指纹数据记录更新该栅格的SVR定位模型。这样的做法,方便于通过数据库对各指纹记录进行管理,智能化程度高。可选的,所述设定时间段为24小时。这样的更新频率足以保证定位精度,同时也不会为执行本方法的系统带来过多的工作负荷。可选的,所述样本的设定数量为2000条/栅格。样本数大则定位更精确,但也要付出定位模型平均训练时间增加的代价,该设定数量使得模型的最大平均训练时间和平均定位精度达到一个平衡,适合于本方法的应用实施。附图说明图1为本发明实施例中采用SMO启发式算法进行模型的学习训练的流程图;图2为本发明实施例中在线定位阶段的流程图;图3为本发明实施例中SVR定位模型自适应更新阶段的流程图;图4为采用本发明实施例进行定位时的预测平均误差以及平均训练时间相对于每个栅格的样本数量设定值变化的曲线图。具体实施方式本实施例,针对中国移动的LTE网络,并以计算机程序的方式将方案部署在信令软采分析系统内;采用的方案为:第一步,MR数据采样和模型训练阶段,具体包括:(1)MR数据采集阶段:采用符合中国移动集团所定标准的ATU(AuxiliaryTestUnit),即测试自动路测工具,进行MR数据的采集,该工具集成有GPS模块,因此,所述MR数据除了包括小区标识信息以及其所涉及到的每个小区的场强数据、时延数据和方向角数据外,还包括有每个采样点的经纬度。(2)模型训练阶段:通过导入设备,将ATU中采集的数据上到系统主机的存储设备内;筛选符合条件的MR数据,本实施例采用了以下标准:1、所涉及的cell个数大于等于4;2、TA数值小于等于37;3、数据所涉及的小区与数据采样的距离需小于等于3000米;将每个经过筛选符合条件的MR数据作为一条训练样本,构建定位指纹库;并根据定位指纹库生成在线定位模型,包括:(2-1)将所述移动网络覆盖区域划分为边长为L的栅格,并将栅格编号,根据每条MR数据的采样点位置坐标,将训练样本分配都对应的栅格中;(2-2)将栅格的编号作为位于该栅格的训练样本的分类标识,分类标识和训练样本共同组成指纹数据记录储存在定位指纹库中。本实施例采用PostgreSQL数据库建立指纹库,每条指纹数据记录表共有个基本字段,分别是:areaid:栅格编号,Long型;sampleid:同一栅格下的记录编号,Int型;longitude:该条记录采样的经度,Double型;latitude:该条记录采样的纬度,Double型;servingCellid:服务小区的识别信息,Int型;cellid0-7:7个非服务小区(邻近小区)的识别信息,可以为空,Int型;servingCellRsrp:服务小区的识别信息,对应的场强数据(电平),Double型;rsrp0-7:7个非服务小区(邻近小区)非服务小区对应的场强数据(电平),非服务小区识别信息空则为空,Double型;ta:与服务小区的时延,Int型;aoa:与服务小区的方向角,Int型。(2-3)采用支持向量回归算法(SVR)对同一栅格内的训练样本进行处理,得到每个栅格的SVR定位模型,用于计算带定位移动终端所处的经度和纬度;在进行处理前,更为优选的做法是将10个指纹数据(servingCellRsrp、rsrp0-7、ta、aoa,即算法所需的10个向量维度)的值根据中国移动所制定的标准进行归一化处理,具体的做法为:将servingCellRsrp、rsrp0-7的值除以140,ta的值除以37,aoa的值除以360,得到最后的算法输入数据,这样每个维度对于预测的影响程度得到了平衡。(2-4)将所述SVR定位模型作为在线定位模型进行存储;输入数据通过核的映射,在高纬的空间里实现SVR回归;在进一步的测试评估中,发现径向基核函数(RBF,又称高斯核函数)表现出较好的效果,故本实施里中采用的定位算法中SVR训练采用径向基核函数进行映射。例如,假设如下样本:4个样本,每个样本4个维度,则当j=1,即第一个样本的核卷积输出为:其中(xi-x1)2为向量内积,此处σ取值为2。构架模型时,对每个训练样本做卷积,最终形成kernelvalue矩阵,。本实施例中,在所述高纬空间下构造ε不敏感回归估计如下:其中ε为误差容忍度,ξ表示实际样本超出ε的距离,C为惩戒参数,是否具有上标*表示该点位于回归线上方或者下方。本实施例采用SMO启发式算法进行模型的学习训练,匹配每个样本的参数,具体为:用K表示上文中kernelvalue矩阵,根据SVR模型,迭代过程中第i个样本输入后,其预测输出f(回归计算结果)及该预测输出f与实际值y之间的误差E计算以如下:Ei=fi-yi(30)因此,学习训练的目的则是,为每个训练样本匹配最优的lagrange乘子和b,以最小化E;在本实施例中E具体为,模型根据训练样本数据预测出的经度和纬度与指纹数据记录中记录的该训练样本的采样经度和纬度。由于在启发式SMO学习训练中,每次我们只优化两个lagrange乘子,择有外层循环:1.首先在λi∈(-C,0)∪(0,C)中寻找违反KKT的λi,违反KKT条件可表示为:|yi-fi|≠ε(31)其中ε一般设置为10-3。2.当λi∈(-C,0)∪(0,C)中所有λi都没有违反KKT条件,则遍历整个样本中违反KKT的λi,违反KKT可表示为:如此直到所有样本的遵循KKT条件。内层循环:1.同样在λi∈(-C,0)∪(0,C)中寻找对应λi更新步长最大的λj,其中更新步长最大为寻找最大的ΔE:2.得到目标λi,λj,接下来做进一步的迭代更新:其中为外循环及内循环得到的λi,λj。η=Kvv+Kuu-2Kuv(35)进一步第一次更新λi=s*-λj(38)对于的情况做进一步的调整:若且|λi|≥Δ∧|λj|≥Δ,则:若且|λi|≥Δ∧|λj|≥Δ该条件不满足,则:其中step为不为0时取1。继上述(39)(40)判别调整之后,再做进一步的剪辑,保证λj落在可行域之内,其中:则剪辑后可得:最后更新阈值b:当λu以及λv都在[-C,C]范围内,则:b=bu=bv(43)当λu以及λv中有任何一个不落在[-C,C]范围内时,则:其中:在本实施例中,该算法具体的实施方法如图1所示,此处,用alpha表示上文中的每个样本所对应的a所组成的向量(其维度为训练样本的个数);首先初始化数据,根据所有的样本建立kernelvalue矩阵,而后设置alpha和b的初始值为0,而具体的搜索包括:1non-bounded启发式搜索i.首先遍历alpha满足条件域(-C,0)∪(0,C),称该些点为non-bounded,因为该些点在最终预测输出中起着主导作用。ii.其次遍历违反KKT条件的alpha,关于KKT条件,具体见式(31),此外若不满足该判断,则跳出条件,返回alpha,b。iii.接着寻找更新步长最大的第二个alpha,在non-bounded集合中遍历,同时存贮当前第一,第二个alpha,以便后面做进一步计算;iv.进一步更新目标alpha,全过程对应上文公式(34)~(42),为SMO核心部分;v.对上文得到的alpha做判别,第一次判断其是否有足够的更新步长,第二次判断bounded的alpha集合是否为空,为空则没必要继续更新下去,第三次判断,与上文相同,对应公式(34)~(42)中的(39),(40),第四次判断仍旧判断alpha是否有足够的步长,至此,non-bounded启发式更新alpha完成一次迭代;vi.最后更新b值同时返回alpha及b。如此,迭代完一次non-bounded集合,更新了违反KKT的alpha,将其封装在nonBoundedLoop函数中。2.Bounded启发式搜索Bounded启发式搜索与上文的non-bounded相似,不同之处在于前者是在0,±C中更新alpha每个维度的值,由于过程中对结果起重要作用的是支持向量(即上文中每个维度取值在(-C,0)∪(0,C)集合内的alpha),故alpha每个维度取值为0,±C的属次要,但其更新仍会影响支持向量发生相应变化,故其仍需做进一步遍历迭代,过程如下:i.首先遍历alpha满足条件域0,±C,称该些点为bounded,该些点在最终预测输出中起着次要作用;ii.其次遍历违反KKT条件的alpha,此外若不满足该判断,则跳出条件,返回alpha,b;iii.接着寻找更新步长最大的第二个alpha,在全样本集合中遍历,同时存贮当前第一,第二个alpha,以便后面做进一步计算;iv.进一步更新alpha,由于对内层alpha的搜索是在全样本中,故无需再进行判断搜索结果集是否为空,同时由于bounded集上的alpha在预测中起次要作用,故不再进一步判断其是否有足够更新(这其中也有一部分原因是,该点在全样本中搜索,即使更新步长不够大,也无法再更换其他点),全过程对应上文公式(34)~(42);v.最后更新b值同时返回alpha及b;如此,迭代完一次bounded集合,更新了违反KKT的alpha,将其封装在BoundedLoop函数中。3.总的遍历及判断总的遍历及判断条件为:最高步数与全样本改变量,两者为与关系,后者又分为:改变量次数或是否遍历全样本,两者为或关系。由于算法中alpha初始化为0向量,经过1次遍历之后,判断是否遍历了全样本,若为否,再判断其alpha改变次数是否为0,不为0则遍历bounded集直到alpha改变量为0,再转至non-bounded集遍历,最终当达到最高步数,或者遍历了全部样本且在non-bounded上的改变量为0,跳出循环,输出结果。在结果输出中,由于每个栅格需各自训练一次,所以每个栅格均对应有各自的参数输出,下面针对某个栅格举例,该栅格的参数表输出如表1所示,参数表包含6个字段,其中Area_ID(栅格编号)未列出,id为该栅格下每个样本的编号,alpha_lng,b_lng对应经度模型的学习结果,alpha_lat,b_lat对应纬度模型的学习结果。idalpha_lngb_lngalpha_latb_lat1-7.07E-07113.1146114-1.15E-0623.111044122-7.95E-07113.11461141.72E-0723.111044123-7.42E-07113.1146114-1.77E-0623.111044124-7.10E-07113.1146114-1.98E-0723.1110441251.03E-07113.1146114-1.24E-0623.1110441268.93E-07113.11461142.24E-0723.1110441272.40E-07113.11461145.48E-0823.111044128-1.19E-06113.1146114-1.74E-0723.111044129-6.08E-07113.11461142.93E-0723.1110441210-5.92E-07113.11461143.79E-0723.1110441211-5.95E-07113.1146114-1.12E-0623.1110441212-7.36E-07113.1146114-1.20E-0623.11104412132.45E-06113.1146114-4.03E-0723.1110441214-1.13E-06113.1146114-1.53E-0723.11104412153.91E-07113.1146114-1.07E-0623.11104412161.17E-06113.1146114-2.33E-0723.11104412172.08E-07113.1146114-1.03E-0523.11104412183.32E-07113.1146114-1.17E-0623.11104412199.36E-07113.1146114-3.25E-0723.1110441220-1.62E-07113.11461144.72E-0723.1110441221-4.82E-08113.11461142.60E-0723.11104412224.07E-07113.1146114-1.04E-0723.1110441223-9.68E-07113.11461141.49E-0723.1110441224-6.53E-06113.1146114-1.20E-0523.11104412252.14E-07113.1146114-1.17E-0623.11104412表1输出的参数表示例第二步,在线定位阶段,具体包括:通过信令软采获取待定位移动终端的实时MR数据,获取实时MR数据中所涉及到的小区的标识信息以及实时MR数据在其所涉及到的每个小区上的场强数据、时延数据和方向角数据;根据该实时MR数据中所涉及到的小区的标识信息,从定位指纹库中筛选涉及相同小区的指纹数据记录;根据涉及到的每个小区上的场强数据、时延数据和方向角数据,计算实时MR数据与上一步中筛选出的每一条指纹数据记录的欧拉距离;从而将该待定位移动终端初步定位到上一步中欧拉距离值最小的职位数据记录所在的栅格中;于是,调取该栅格下的所有指纹数据记录和参数表,做以下操作:(1)当训练样本与实时传入的检测报告中的所有cell都相同表2如表2所示,假设实时传入的数据包含4个cell,且该4个cell与第7个样本下覆盖的cell一致,则该核卷积通过rsrp、TA、AOA数据直接作如下处理:其中x实时为实时传入数据,x7为指纹库中第七个样本数据,(-0.06,0.5,-0.13,0.5)为x实时与x74个小区下对应的rsrp数据相减得到,0.2为x实时与x7的TA数据相减得到,0.3x实时与x7的AOA数据相减得到,之后做向量内积,得到0.6505,将dx代入下面公式得到:(2)当样本与实时传入的数据部分cell相同,则取相同部分相减,不同部分补0对应,再相减,再求内积,核卷积,举例如下:表3由表3可以看到实时传入的数据与样本数据第1个有三个小区相同,分别为:6723891、6723893、6700472,对于这3个,只需直接相减即可,而对于实时数据中的cell6723895,在样本1里没有出现,则相减的时候,把样本1对应位置补0,同样,样本1中cell6719203,在实时传入数据中没有,则相减的时候,在实时传入数据对应位置补0,同时TA与AOA计算如上部分,同样计算如下:其中x实时为实时传入数据,x1为指纹库中第1个样本数据,(-0.93,-0.05,-0.12,-0.056,0.8887)为x实时与x14个小区下对应的rsrp数据相减得到,0.4为x实时与x1中TA数据相减得到,0.3为x实时与x1中AOA数据相减得到,之后做向量内积,得到1.924724,将dx代入下面公式得到:此即为当样本与实时传入的数据部分cell相同时的卷积计算。(3)当样本与实时传入的数据cell完全不同,则全部采取补0相减,计算过程与上述相同,TA与AOA计算如上部分。在核卷积遍历目标栅格下的所有样本后,便形成了目标样本的kernel_value向量;再根据算式(30)取每个样本对应的kernel_value中的项以及参数表中alpha_lng列下的项做相乘求和计算后再加b,即可得到经度的预测值输出,维度的预测输出也是同样的道理,不同在于其使用的参数列为alpha_lat。第三步,定位指纹数据库自适应更新阶段和SVR定位模型自适应更新阶段,具体包括:定位指纹数据库自适应更新阶段:定时根据第一步中的方法采集新的MR数据,并形成备用指纹数据记录;根据所处栅格的SVR定位模型量化每一条指纹数据记录对于定位计算结果的影响程度,并为每一条指纹数据记录添加删除/保留标记、版本标记以及该指纹数据记录的入库时间,并根据删除/保留标记和入库时间更新定位指纹数据库。在本实施例中,每条指纹数据记录还包含三个标记字段:Version:版本号,integer型;Delete:删除/保留标记,Boolean型;Updatetime:入库时间,timestampwithouttimezone型。该阶段中指纹数据记录的更新过程如下:根据指纹数据记录的入库时间,筛选入库的时长超过设定时间段的指纹数据记录,本实施例中设定时间为24小时;由于Alpha值的大小在SVR定位模型中代表了样本对结果预测的影响程度大小,在上一步骤的基础上,标记所属Alpha值中的任意一个小于10-7的样本为删除,即Delete字段的值为ture;本实施例中指纹数据记录每日更新一次,当到达指定每日的更新时间点时,从定位指纹数据库中剔除所有Delete字段的值为TURE的指纹数据记录;如果此时定位指纹数据库中归属于某一栅格的指纹数据记录的数量低于2000时,则将备用指纹数据记录添加到定位指纹数据库内。SVR定位模型自适应更新阶段,在本实施例中该阶段如图3所示:是否更新SVR定位模型的判断条件为:是否指定位指纹库内该栅格下存在Version字段为NULL的数据;是否指定位指纹库内该栅格下存在Delete字段标记为TRUE的数据;如果某一栅格下的指纹数据记录满足上述条件之一则表示该栅格内的指纹数据记录发生更新,进而根据更新后的指纹数据记录更新该栅格的SVR定位模型;SVR定位模型的更新,同样采用图1中所示的流程重新寻找最优参数,并输出参数表。更新后,将该栅格内每个指纹数据记录的版本标记设定为较当前版本次一级新的版本,即,Version字段的值为NUll的,将被重新设定为1,其他Version字段的值非NULL的则直接加1,这样,多次更新后便有了多个版本(Version字段的值为1、2、3……)的指纹数据记录。下面通过测量精度说明本实施例的定位效果:具体的,采用栅格的边长L为100米,每个栅格的样本数设定值为2000,由于采用了更新原则,每个栅格的样本数逐步增加,最终保持在1500到2000以内。参数设定如下:在经度SVR模型中:惩戒参数C=100,最大搜寻步数maxStep=10000,σ取值guassian_delta=0.055;纬度SVR模型种仅有的不同为采用另一的σguassian_delta=0.08;表41000条预测样本定位误差统计从表4中可以看出,在1000条预测样本中,10米误差内的比例约为84%,20米误差内的比例为91%。表5另外,此处定义预测平均误差为:经度平均误差为所有经度预测值与实际经度值的差值之和除以预测样本数量;纬度平均误差为所有纬度预测值与实际经度值的差值之和除以预测样本数量;预测平均误差=(纬度平均误差+经度平均误差)/2。图4中由左至右下降的曲线表示预测平均误差,由左至右上升的曲线表示平均训练时间,如表5以及图4所示,通过改变每个栅格的样本数量设定值,作出的对于计算时间和定位精度的对比得知,虽然样本数量增大可以使结预测平均误差越小,但却是以平均训练时间为代价的;而当样本数量控制在(1500,2000]范围内时,平均训练时间仅为895秒,预测平均误差达到了5.46663E-05的水平;将样本数量提升至(2000,3000]内时,平均训练时间猛增至2557,增加了接近两倍,预测平均误差仅下降至4.12434E-05水平,带来的下降十分有限;因此本实施例中的选择将样本数量控制在(1500,2000]范围内。以上所述的仅是本发明的实施例,方案中公知的具体结构及特性等常识在此未作过多描述,所属领域普通技术人员知晓申请日或者优先权日之前发明所属
技术领域:
所有的普通技术知识,能够获知该领域中所有的现有技术,并且具有应用该日期之前常规实验手段的能力,所属领域普通技术人员可以在本申请给出的启示下,结合自身能力完善并实施本方案,一些典型的公知结构或者公知方法不应当成为所属领域普通技术人员实施本申请的障碍。应当指出,对于本领域的技术人员来说,在不脱离本发明结构的前提下,还可以作出若干变形和改进,这些也应该视为本发明的保护范围,这些都不会影响本发明实施的效果和专利的实用性。本申请要求的保护范围应当以其权利要求的内容为准,说明书中的具体实施方式等记载可以用于解释权利要求的内容。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1