基于PCIE的高速隔离网络方法及终端与流程
本发明涉及多媒体通信技术领域,尤其涉及一种基于PCIE的高速隔离网络方法及终端。
背景技术:
随着人们对高清视频的需求越来越高,对视频会议终端的编解码能力也有了更高的要求,传统的单台视频会议终端使用一个处理器来进行多路编码、解码的方案已经不可行,而是需要同一台视频会议终端,内部有多个处理器进行协同作业,来分担编解码的压力,进而提供更大的图像能力,为用户提供更好的效果体验。
目前,基于同一个视频会议终端多个处理器协同作业时大都采用以太网还传输数据,然而上述的方案中,以太网传输方式不适合同一个局域网内部署多台终端涉及大量处理器的场景,每个处理器都要分配网络资源,而同一个网段内网络资源有限,需要客户去重新规划网络资源划分vlan等,额外的增加了客户的开销;以太网传输方式,具有更大的作用域,局域网内有多个终端,各个终端的多个处理器之间是可以网络连通的,这样就很容易互相干扰,不具备封闭性;以太网目前最大只能支持千兆网,1000Mbsp的速率,而视频会议系统中对实时性要求是非常高的,上述的传输速率并不能满足传输要求。
技术实现要素:
为解决至少一上述技术问题,本发明的主要目的是提供一种基于PCIE的高速隔离网络终端。
为实现上述目的,本发明采用的一个技术方案为:提供一种基于PCIE的高速隔离网络终端,包括:
PCIE总线,
多个处理器,每一所述处理器分配有唯一的IP地址;
PCIE数据交换芯片,所述PCIE数据交换芯片分别与各处理器通过PCIE总线连接,以使任一处理器与一个或一个以上的处理器通讯连接;
虚拟网卡,所述虚拟网卡用以在一处理器发送数据时,在物理层截获传输给以太网的数据,并根据不同IP地址将数据通过PCIE总线传输至对应的处理器,以及在对应处理器接收数据时,解析数据并转换成对应的IP地址后,提交发给网络协议栈,以实现不同处理器的数据收发。
优选地,所述处理器的数量为六个,六个处理器分别通过PCIE总线与PCIE数据交换芯片电连接,以实现任一处理器与一个或一个以上的处理器通讯连接。
优选地,所述处理器设置有一数据缓存区,用以在拷贝数据时,同步不同处理器收发的数据。
优选地,所述处理器的型号为TI8168。
优选地,所述PCIE数据交换芯片的型号为PI7C9X2G608GP。
为实现上述目的,本发明采用的另一个技术方案为:提供一种基于PCIE的高速隔离网络方法,包括如下步骤:
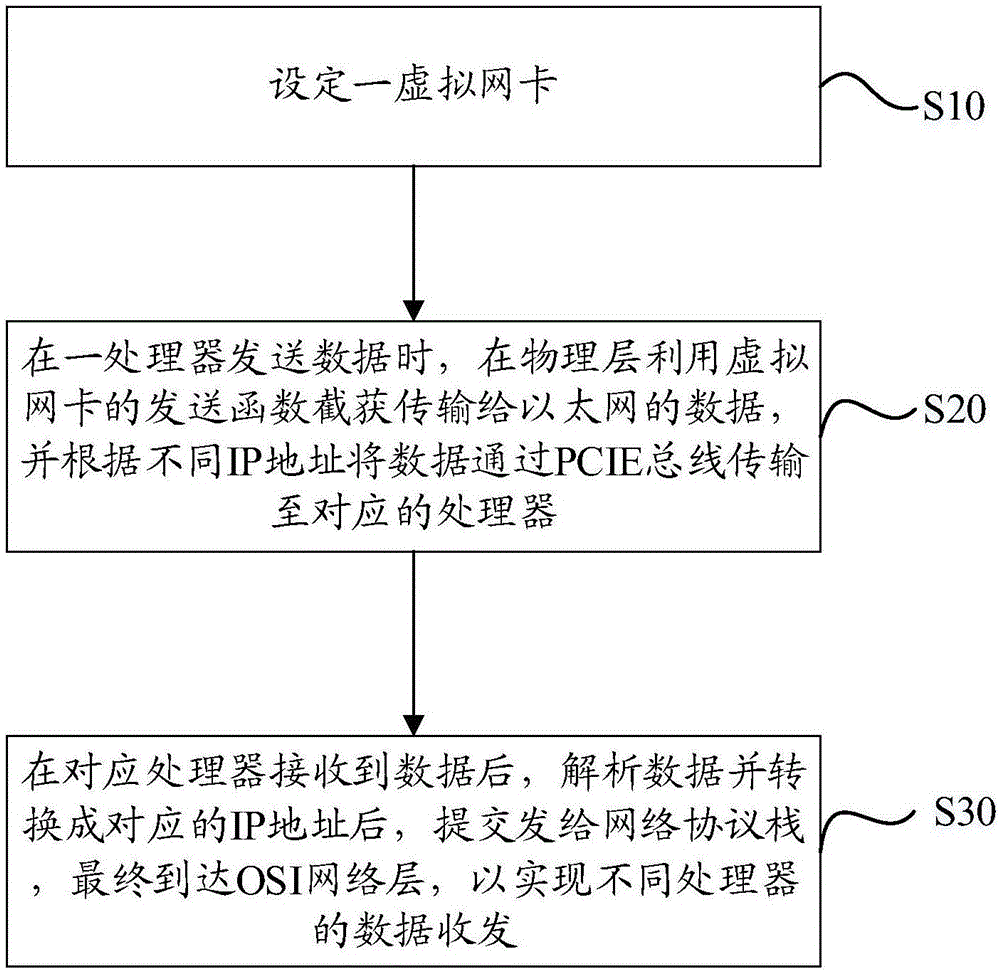
设定一虚拟网卡;
在一处理器发送数据时,在物理层利用虚拟网卡的发送函数截获传输给以太网的数据,并根据不同IP地址将数据通过PCIE总线传输至对应的处理器;
在对应处理器接收到数据后,解析数据并转换成对应的IP地址后,提交发给网络协议栈,最终到达OSI网络层,以实现不同处理器的数据收发。
优选地,所述在一处理器发送数据时,在物理层利用虚拟网卡的发送函数截获传输给以太网的数据,并根据不同IP地址将数据通过PCIE总线传输至对应的处理器的步骤之前,还包括:
对各处理器进行编号,以根据编号为各处理器绑定唯一内网IP地址。
优选地,所述在对应处理器接收到数据后,解析数据并转换成对应的IP地址后,提交发给网络协议栈,最终到达OSI网络层,以实现不同处理器的数据收发的步骤之前,还包括:
在处理器维护数据缓冲区时,根据PCIE总线中断或轮训机制来检测是否有新数据到达。
优选地,在所述对应处理器接收到数据时的步骤,还包括:
同步不同处理器之间的收发数据。
优选地,所述在对应处理器接收到数据后,解析数据并转换成对应的IP地址后,提交发给网络协议栈,最终到达OSI网络层,以实现不同处理器的数据收发的步骤之后还包括:
选择一处理器为主处理器,并利用主处理器定期检测其他处理器中是否存在挂死的问题处理器,
如果存在挂死的问题处理器,则重启问题处理器。
本发明的技术方案通过采用在一终端设置多个处理器、PCIE数据交换芯片以及虚拟网卡,该多个处理器分别与PCIE数据交换芯片通过PCIE总线电连接,可实现一处理器与多个处理器的通讯连接,利用多处理器协同合作的实现方案,使得终端完全可以为客户提供良好的使用体验;利用虚拟的PCIE网卡,数据的收发对上层网络结构透明,即上层网络结构还是走的标准网络协议栈来进行数据封装,底层物理层我们是通过PCIE总线来进行数据传输的,而不是走的以太网,如此,可以大大提升内部码流传输的效率、也增强了系统的封闭性。由于软件的上层是透明的,不需要实现新的功能代码,还是按照原有的代码逻辑来收发数据即可,减少了代码编写和维护的工作量,并且虽然局域网内多个视频会议终端同处于一个网络内,但是各个终端内部的多处理器是封闭的,只和本终端内的其他处理器网络通信,而且不需要划分vlan,便于实现。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图示出的结构获得其他的附图。
图1为本发明一实施例基于PCIE的高速隔离网络终端架构示意图;
图2为本发明一实施例基于PCIE的高速隔离网络方法的流程示意图。
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
需要说明,本发明中涉及“第一”、“第二”等的描述仅用于描述目的,而不能理解为指示或暗示其相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括至少一个该特征。另外,各个实施例之间的技术方案可以相互结合,但是必须是以本领域普通技术人员能够实现为基础,当技术方案的结合出现相互矛盾或无法实现时应当认为这种技术方案的结合不存在,也不在本发明要求的保护范围之内。
为更好的描述本方案,下面对现有的OSI网络模型和PCIE进行简要描述。
OSI网络模型:由底层到高层依次包括物理层(Physical Layer)、数据链路层(Data Link Layer)、网络层(Network Layer)、传输层(Transport Layer)、会话层(Session Layer)、表示层(Presentation Layer)及应用层(Application Layer)。
PCIE:PCIE为PCI-Express,原名为3GIO(The 3rd Generation Input Output)。CI-Express已经推出了3个版本,分别是:
1)2002年4月推出的PCI-Express 1.0,单通道带宽为2.5Gbps*2(因为PCE-Express收发通道独立,可以同时工作,所以带宽加倍),有效带宽为2.5Gbps*2*0.8=4Gbps=500MByte/s(PCI-Express通道中传输的数据经过了8B/10B编码,编码效率为80%);
2)2006年推出的PCI-Express 2.0,单通道带宽为5Gbps*2,有效带宽为5Gbps*2*0.8=8Gbps=1GByte/s;
3)2008年推出的PCI-Express 3.0,单通道带宽为10Gbps*2,有效带宽为10Gbps*2*0.8=16Gbps=2GByte/s。
PCI-Express总线的基本架构包括根组件(Root Complex)、交换器(Switch)和各种终端设备(Endpoint)。根组件可以集成在北桥芯片中,用于处理器和内存子系统与I/O之间的连接;交换器的功能通常以软件的形式提供,包括多个逻辑PCI到PCI的桥连接,以及与传统PCI设备的兼容性,在PCI-Express架构中出现的新设备是交换器,主要用来为I/O总线提供输出端,它也支持在不同终端设备间进行对等数据传输。
请参照图1,在本发明实施例中,该基于PCIE的高速隔离网络终端,包括:
PCIE总线30,
多个处理器10,每一所述处理器10分配有唯一的IP地址;
PCIE数据交换芯片20,所述PCIE数据交换芯片20分别与各处理器10通过PCIE总线30连接,以使任一处理器10与一个或一个以上的处理器10通讯连接;
虚拟网卡,所述虚拟网卡用以在一处理器10发送数据时,在物理层截获传输给以太网的数据,并根据不同IP地址将数据通过PCIE总线30传输至对应的处理器10,以及在对应处理器10接收数据时,解析数据并转换成对应的IP地址后,提交发给网络协议栈,以实现不同处理器10的数据收发。
本实施例中,上述处理器10的型号为TI8168,同一终端内我们搭配了多个TI8168芯片来进行并行的编解码的处理,基于TI1868芯片强大的视频能力和系统设计的多处理器10协同合作的实现方案,使得产品完全可以为客户提供良好的使用体验。多个处理器10之间采用PCIE总线30来连接,进行数据通信,由于PCIE是端到端的总线,而我们需要更加灵活的实现一到多的任意两个处理器10的连接,如此,增加了PCIE数据交换芯片20的型号为PI7C9X2G608GP,所有处理器10均与PCIE数据交换芯片20连接,该PCIE数据交换芯片20可以提供任意两点之间的桥接。虚拟一个PCIE网卡,数据的收发对上层透明,即上层还是走的标准网络协议栈来进行数据封装,只是物理层我们是通过PCIE来进行数据传输的,而不是走的以太网,大大提升内部码流传输的效率、也增强了系统的封闭性。
本发明的技术方案通过采用在一终端设置多个处理器10、PCIE数据交换芯片20以及虚拟网卡,该多个处理器10分别与PCIE数据交换芯片20通过PCIE总线30电连接,可实现一处理器10与多个处理器10的通讯连接,利用多处理器10协同合作的实现方案,使得终端完全可以为客户提供良好的使用体验;利用虚拟的PCIE网卡,数据的收发对上层网络结构透明,即上层网络结构还是走的标准网络协议栈来进行数据封装,底层物理层我们是通过PCIE总线30来进行数据传输的,而不是走的以太网,如此,可以大大提升内部码流传输的效率、也增强了系统的封闭性。由于软件的上层是透明的,不需要实现新的功能代码,还是按照原有的代码逻辑来收发数据即可,减少了代码编写和维护的工作量,并且虽然局域网内多个视频会议终端同处于一个网络内,但是各个终端内部的多处理器10是封闭的,只和本终端内的其他处理器10网络通信,而且不需要划分vlan,便于实现。
在一具体的实施例中,所述处理器10的数量为六个,六个处理器10分别通过PCIE总线30与PCIE数据交换芯片20电连接,以实现任一处理器10与一个或一个以上的处理器10通讯连接。
本实施例中,同一终端内我们搭配了六个TI8168芯片来进行并行的编解码的处理,基于TI1868芯片强大的视频能力和系统设计的多处理器10协同合作的实现方案,使得产品完全可以为客户提供良好的使用体验。
在一具体的实施例中,所述处理器10设置有一数据缓存区,用以在拷贝数据时,同步不同处理器10收发的数据。
本实施例中,,由于每个处理器10都有一个数据缓存区(ddr),数据从另一个处理器10的数据缓存区拷贝到当前处理器10的数据缓存区,那么涉及到处理器10的cache问题,需要程序中自动完成cache同步。
请参照图2,本发明的实施例中,该基于PCIE的高速隔离网络方法,包括如下步骤:
步骤S10、设定一虚拟网卡;
步骤S20、在一处理器发送数据时,在物理层利用虚拟网卡的发送函数截获传输给以太网的数据,并根据不同IP地址将数据通过PCIE总线传输至对应的处理器;
步骤S30、在对应处理器接收到数据后,解析数据并转换成对应的IP地址后,提交发给网络协议栈,最终到达OSI网络层,以实现不同处理器的数据收发。
以中两个处理器之间网络ping包为例进行具体说明:
1、虚拟一个网卡,将IP地址设置为不可能和外界冲突的IP范围,假设当前处理器编号为0的机器,我们设定的IP地址是193.170.199.200,对端处理器编号为1的机器,IP地址是193.170.199.201;
2、CPU0发起一个ping包请求CPU 1,首先ping的实现是发送一个icmp报文,通过socket来进行发送,当发送的包通过协议栈最终陷入到虚拟网卡驱动后,通过虚拟网卡的发送函数可捕获到这一组数据包,捕获到数据包以后,将其放入一组发送队列,然后唤醒发送线程,发送线程被唤醒之后,从队列中获得数据包,为其分配一个物理内存空间存放;
3、CPU 0发送通知消息给CPU 1,告知对方本端某个内存地址有发送给他的数据,CPU 1对每个处理器都有一条专用的消息队列,定期的中断货轮训方式探测这个消息队列;
4、CPU 1收到消息后,分配本端存放的物理地址,将数据包拷贝到分配的物理地址,然后刷新cache,确保数据全部同步到物理内存,分配edma资源,然后根据PCIE地址和数据缓存区(ddr)地址对应关系,访问CPU 0的PCIE空间,根据映射关系即可访问到CPU0的物理内存,然后通过edma将数据拷贝到本端数据缓存区(ddr);
5、CPU 1获取到数据之后,分配skb,然后刷新cache将内存数据拷贝到skb,提交给网络协议栈,最终到达OSI网络层,完成数据的收发流程。
通过以上方案设计、代码编写,功能调试等等,最后实现了多个处理器任意调度,任意数据传输,共同协作处理编解码任务的工作,实现编解码任务的负载均衡,极大的提升了系统的码流传输性能,为提供更多路的编解码需求提供了有力的保障。
在一具体的实施例中,所述在一处理器发送数据时,在物理层利用虚拟网卡的发送函数截获传输给以太网的数据,并根据不同IP地址将数据通过PCIE总线传输至对应的处理器的步骤S20之前,还包括:
对各处理器进行编号,以根据编号为各处理器绑定唯一内网IP地址。
本实施例中,该方法可以支持一对多的数据传输,所以需要每个处理器对另外的几个处理器有个类似IP地址一样的区分,通过给各个处理器编号来实现,并对各个编号绑定一个内网IP地址,便于数据收发操作。
在一具体的实施例中,所述在对应处理器接收到数据后,解析数据并转换成对应的IP地址后,提交发给网络协议栈,最终到达OSI网络层,以实现不同处理器的数据收发的步骤S30之前,还包括:
在处理器维护数据缓冲区时,根据PCIE总线中断或轮训机制来检测是否有新数据到达。
本实施例中,不同的处理器维护不同的数据缓冲区,通过PCIE总线中断或轮训机制来检测是否有新数据到达,并且动态调整中断相应机制。如果某一时刻中断较多,则会对系统性能影响较大,则暂时关闭中断,使用轮训机制来处理消息,并且每次轮训到数据,读取多条消息去并行处理,在不影响系统性能的前提下,充分利用系统资源。
在一具体的实施例中,在所述对应处理器接收到数据时的步骤,还包括:
同步不同处理器之间的收发数据。
本实施例总,由于每个处理器都有一个数据缓存区(ddr),数据从另一个处理器的数据缓存区(ddr)拷贝到当前处理器的数据缓存区(ddr),那么涉及到处理器的cache问题,需要程序中自动完成cache同步。
在一具体的实施例中,所述在对应处理器接收到数据后,解析数据并转换成对应的IP地址后,提交发给网络协议栈,最终到达OSI网络层,以实现不同处理器的数据收发的步骤S30之后还包括:
选择一处理器为主处理器,并利用主处理器定期检测其他处理器中是否存在挂死的问题处理器,
如果存在挂死的问题处理器,则重启问题处理器。
本实施例中,使用主处理器来定期检测各个协同处理器的工作状态,发现挂死后,会重启出问题的处理器,增加系统的容错性,使得终端具有自动回复功能。
另外,每个处理器都可以作为独立的调度器,来和其他处理器协同操作,各个处理器相互不影响,又相互探测彼此的工作状态,可以随意调度编解码任务到其他空闲处理器,实现灵活的系统调度。
以上所述仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是在本发明的发明构思下,利用本发明说明书及附图内容所作的等效结构变换,或直接/间接运用在其他相关的技术领域均包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!