提取及校验URL的方法与流程
本发明涉及通信领域,具体涉及一种提取及校验URL的方法。
背景技术:
URL即Uniform Resource Locator,意思是统一资源定位符,也就是俗称的网页地址。URL是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。URL相当于一个文件名在网络范围的扩展。因此URL是与因特网相连的机器上的任何可访问对象的一个指针。
URL的语法通常是这样的“协议://用户名:密码@子域名.域名.顶级域名:端口号/目录/文件名.文件后缀?参数=值#标志”。实际使用时往往会根据自己的需要,选择其中的部分项。由于互联网内容的多样性,从海量内容中提取URL,往往会存在两方面的问题:一是如何正确地提取URL;二是提取到的URL如何实现纠错。
传统的解决方法是通过查找“http://”标识过滤出URL,再通过人工方式实现URL的纠错,这种方法费时费力,且不够实用。
技术实现要素:
本发明克服了现有技术中的不足,提供一种提取及校验URL的方法。
为解决上述的技术问题,本发明采用以下技术方案:
一种提取及校验URL的方法,它包括以下步骤:
步骤1,构建提取和校验URL的模板库,所述模板库包括协议模板库、域名模板库和IP地址模板库;
步骤2,从海量内容源中读取内容,并把内容转换成输入流的方式进行读取,所述内容源包括来至互联网的网页内容、来至社交工具收集到的用户行为数据内容或来至传感器记录下的日志数据内容;
步骤3,根据协议模板库,按照协议类别对输入的内容流进行匹配,过滤出满足协议模板库的URL数据;
步骤4,根据域名模板库,按照域名级别、域名种类对输入的内容流进行匹配,过滤出满足域名模板库的URL数据;
步骤5,根据IP地址模板库,按照IPv4和IPv6对输入的内容流进行匹配,过滤出满足IP地址模板库的URL数据;
步骤6,根据步骤3-步骤5匹配的结果,对匹配后的URL数据进行分类存储;
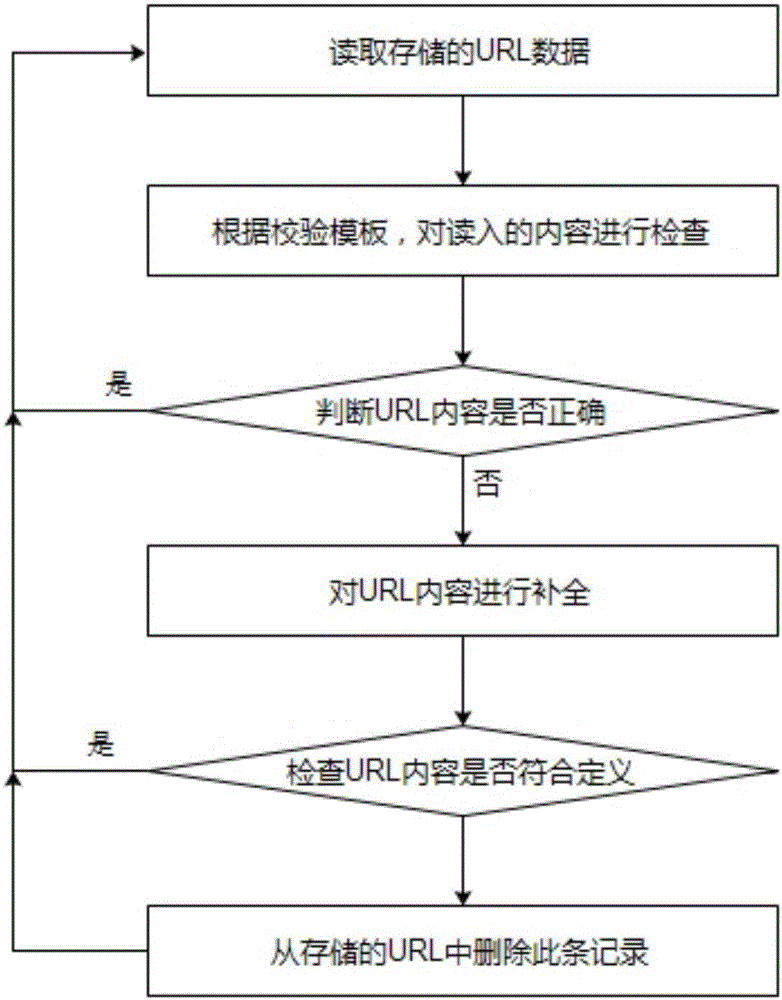
步骤7,从分类存储的URL数据中依次读取URL数据;
步骤8,根据协议模板库,对读取的URL数据根据协议规定和协议特征进行精确检查;
步骤9,根据步骤8的精确检查结果,确定URL数据是否为正确的数据,如果URL数据正确,那么转向步骤7,继续读取下一条存储的URL数据,如果URL数据不正确,那么转向步骤10;
步骤10,对URL数据进行补全;
步骤11,对补全后的URL数据进行再次检查,查看URL数据是否依然符合定义,如果URL数据符合定义,那么把补全后的URL数据写入分类存储中,并转向步骤7,继续读取下一条存储的URL数据。如果URL数据不符合定义,则表示补全的URL数据无效,转向步骤12;
步骤12,删除URL数据。
更进一步的技术方案是,所述协议模板库包括HTTP协议模板、HTTPS协议模板、STMP协议模板、FTP协议模板、UDP协议模板、Telnet协议模板或NFS协议模板。
更进一步的技术方案是,所述协议模板库包括协议规定和协议特征。
更进一步的技术方案是,所述域名模板库是根据域名规定设计的按域名级别、域名种类构建的域名模板的集合。
更进一步的技术方案是,所述IP地址模板库是指根据IPv4和IPv6设计的域名模板的集合。
更进一步的技术方案是,所述步骤3-5中的匹配方法采用近似匹配和模糊匹配。
更进一步的技术方案是,所述步骤7中的依次读取是指按类别或按记录条数逐条读取URL数据。
与现有技术相比,本发明的有益效果是:
本发明提供的方法是某些业务场景进行大数据分析的基础方法,有较强的实用价值。
附图说明
图1为本发明一种实施例的提取及校验URL的方法流程图。
图2为本发明另一中实施例的提取及校验URL的方法的流程图。
具体实施方式
下面结合附图对本发明作进一步阐述。
如图1和图2所示的提取及校验URL的方法,它包括以下步骤:
步骤1,构建提取和校验URL的模板库,模板库包括协议模板库、域名模板库和IP地址模板库;
协议模板库包括HTTP协议模板、HTTPS协议模板、STMP协议模板、FTP协议模板、UDP协议模板、Telnet协议模板或NFS协议模板。
协议模板库包括协议规定和协议特征。
域名模板库是根据域名规定设计的按域名级别、域名种类构建的域名模板的集合。
IP地址模板库是指根据IPv4和IPv6设计的域名模板的集合。
同时构建模板库可以根据需求动态添加,从而可以支撑更多的协议和更多的域名类型。
步骤2,从海量内容源中读取内容,并把内容转换成输入流的方式进行读取,内容源包括来至互联网的网页内容、来至社交工具收集到的用户行为数据内容或来至传感器记录下的日志数据内容。
步骤3,根据协议模板库,按照协议类别对输入的内容流进行匹配,过滤出满足协议模板库的URL数据;匹配方法采用近似匹配和模糊匹配的方法。
步骤4,根据域名模板库,按照域名级别、域名种类对输入的内容流进行匹配,过滤出满足域名模板库的URL数据;匹配方法采用近似匹配和模糊匹配的方法。
步骤5,根据IP地址模板库,按照IPv4和IPv6对输入的内容流进行匹配,过滤出满足IP地址模板库的URL数据;匹配方法采用近似匹配和模糊匹配的方法。
步骤6,根据步骤3-步骤5匹配的结果,对匹配后的URL数据进行分类存储;存储的数据库可以为关系数据库,也可以是文件系统,还可以是NoSQL数据库。
步骤7,从分类存储的URL数据中依次读取URL数据;依次读取是指按类别或按记录条数逐条读取URL数据。
步骤8,根据协议模板库,对读取的URL数据根据协议规定和协议特征进行精确检查。
步骤9,根据步骤8的精确检查结果,确定URL数据是否为正确的数据,如果URL数据正确,那么转向步骤7,继续读取下一条存储的URL数据,如果URL数据不正确,那么转向步骤10。
步骤10,对URL数据进行补全,例如经常会遇到URL部分内容省略的情况,比如“news.qq.com”通常省略了“http://”的内容,而应该补全为“http://news.qq.com/”。
步骤11,对补全后的URL数据进行再次检查,查看URL数据是否依然符合定义,如果URL数据符合定义,那么把补全后的URL数据写入分类存储中,并转向步骤7,继续读取下一条存储的URL数据。如果URL数据不符合定义,则表示补全的URL数据无效,转向步骤12。
步骤12,删除URL数据,具体为从分类存储的URL记录中删除此条记录,并转向步骤7,继续读取下一条存储的URL数据。直至所有的URL记录处理完成。
以上具体实施方式对本发明的实质进行详细说明,但并不能对本发明的保护范围进行限制,显而易见地,在本发明的启示下,本技术领域普通技术人员还可以进行许多改进和修饰,需要注意的是,这些改进和修饰都落在本发明的权利要求保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!