一种媒体大数据hadoop集群监控的方法与流程
本发明涉及系统运维领域,具体涉及一种媒体大数据hadoop集群监控的方法。
背景技术:
当前时代,大数据席卷全球,而Hadoop作为优秀的大数据产品,也被引入并在许多业务中使用,例如非结构化数据的存储、历史数据的归档等。而且随着业务的发展,将会有越来越多的Hadoop集群投入生产,Hadoop集群的使用为媒体大数据业务的开展提供了有力的保障,但与此同时,传统的监控方法也难以准确监控Hadoop集群的运行状态。
目前,媒体大数据监控平台对于开放系统监控已经相对完善,但是对于较新的Hadoop集群,监控指标未成体系,集群监控主要依赖于运维部门单独实现的特色监控,例如监控日志关键字、监控进程等。由于Hadoop是由众多服务器组成的集群,因此对于该计算机集群的监控就成为了一大难点。随着越来越多的Hadoop集群投入生产,一方面各Hadoop集群按单台设备进行监控实现导致效率低下,另一方面也存在监控指标不完善的情况,从而产生运行隐患。而且,传统的方法只能对每台设备进行监控,而Hadoop作为一个集群,无法实现对其整体的监控,从而导致监控结果可能存在误差,难以准确判断故障对系统的实际影响。因此,拟从集群整体的角度,建立完整的Hadoop监控体系,梳理Hadoop各类监控指标对系统及业务的影响,并利用媒体大数据的集中监控系统,实现对Hadoop集群监控的快速配置。
技术实现要素:
本发明为了解决传统方法只能对每台设备进行监控,而Hadoop作为一个集群,无法实现对其整体的监控,从而导致监控结果可能存在误差,难以准确判断故障对系统的实际影响的问题,提供了一种媒体大数据hadoop集群监控的方法,具体技术实施方案如下:
本发明的一种媒体大数据hadoop集群监控的方法,该方法的步骤如下:
步骤一、设置监控管理机和短信网关,并将短信网关与监控管理机相连,监控管理机与hadoop集群连接;
步骤二、监控进程,接收监控管理机的控制命令:启动、停止、更新监控阈值、更新监控指标、更新监控脚本,按时间片判断监控时间间隔,如到达时间间隔则进行监控指标采集循环;对hadoop的关键服务通过进程状态查询命令得到这些服务的状态;对hadoop的Syslog日志文件进行读取,运行监控脚本读取其中的关键字和关键指标;对系统资源通过内存、存储、cpu使用率查询命令得到指标数据指标,将采集的指标与阈值进行比较,达到则产生告警事件数据,将告警事件数据推送给监控管理机;
步骤三、提供操作界面供用户设置监控指标、阈值、监控脚本、告警短信接收号码等,向监控进程推送监控指标、阈值、监控脚本,提供操作界面供用户发出监控开始、停止命令,将命令推送至监控进程,接收监控进程推送来的监控事件告警数据后,转换为短信网关接口格式,添加接收号码,发送至短信网关,实现告警短信发送。
本发明的一种媒体大数据hadoop集群监控的方法,该方法的优点如下:实现了Hadoop集群监控指标的建立以及与媒体大数据集中监控平台的对接,解决了目前媒体大数据Hadoop监控存在的指标不完善、需人工按单台设备实现等问题,降低了运维风险,提高了工作效率。
附图说明
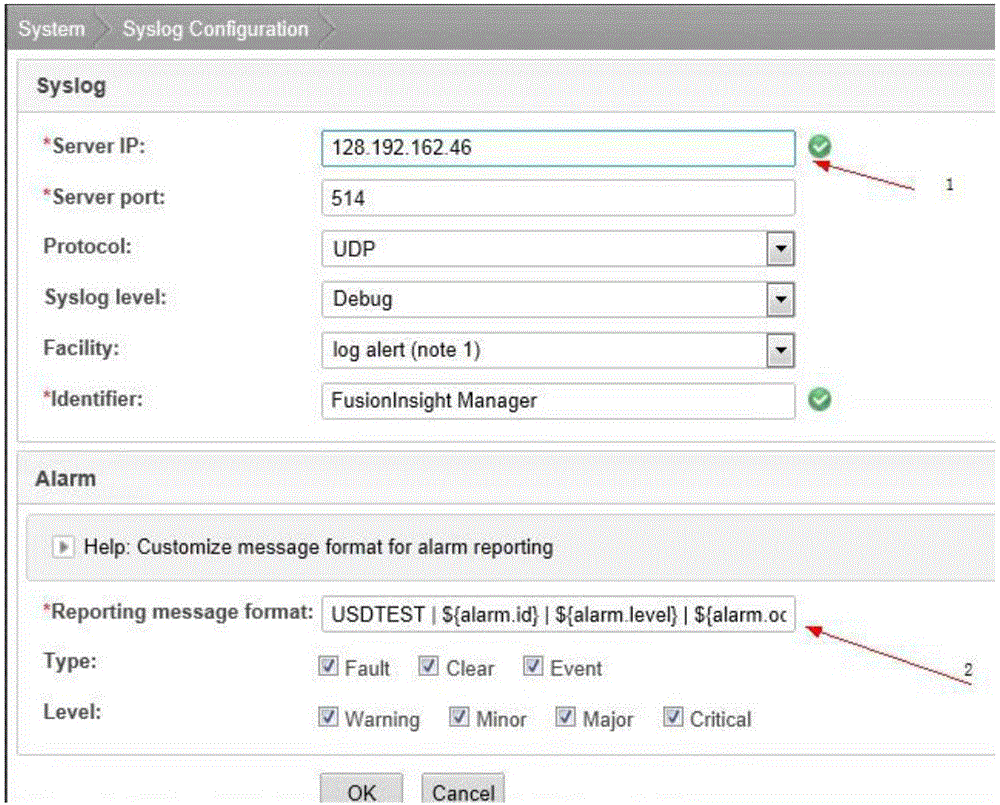
图1本发明的架构图,图2是Hadoop监控配置示例图。
具体实施方式
具体实施方式一:本实施方式的方法是这样实现的:首先设置监控管理机和短信网关,并将短信网关与监控管理机相连,监控管理机与hadoop集群连接;其次部署和启动监控进程,接收监控管理机的控制命令:启动、停止、更新监控阈值、更新监控指标、更新监控脚本,按时间片判断监控时间间隔,如到达时间间隔则进行监控指标采集循环;对hadoop的关键服务通过进程状态查询命令得到这些服务的状态;对hadoop的Syslog日志文件进行读取,运行监控脚本读取其中的关键字和关键指标;对系统资源通过内存、存储、cpu使用率查询命令得到指标数据指标,将采集的指标与阈值进行比较,达到则产生告警事件数据,将告警事件数据推送给监控管理机;然后提供操作界面供用户设置监控指标、阈值、监控脚本、告警短信接收号码等,向监控进程推送监控指标、阈值、监控脚本,提供操作界面供用户发出监控开始、停止命令,将命令推送至监控进程,与断行网关连接,接收监控进程推送来的监控事件告警数据后,转换为短信网关接口格式,添加接收号码,发送至短信网关,实现告警短信发送。
具体实施方式二:本实施方式的监控管理机采用小型计算机。
具体实施方式三:本实施方式的不同的Hadoop集群的监控解析代码通用,且统一部署在syslog服务器后台运行,因此,对于未来新增的Hadoop集群,只需按图2所示进行相关配置即可实现对Hadoop集群的监控。
具体实施方式四:本实施方式的短信网关将监控信息发至短信运营商。
监控Hadoop服务:监控Hadoop集群运行的各种服务,包含关键服务和非关键服务两类。关键服务指Hadoop正常运行所必须的服务进程,若出现故障,会影响Hadoop集群的正常运行。例如HDFS服务、MapReduce服务等,若出现故障会影响Hadoop集群的数据存储和数据处理,也会影响其他相关服务的正常运行。非关键服务一般指部署在管理节点的服务进程,若出现故障,会影响管理节点对Hadoop集群的管理,但不会影响Hadoop集群的正常运行。例如OKerberos资源异常,会导致用户无法登陆Hadoop集群的管理界面。需要指出的是,Hadoop是高可用集群,此类指标是从集群整体的角度监控的,若某一服务发生异常但顺利实现主备切换等高可用性操作,则不在该类监控指标下。该监控共有20个监控指标。
监控Hadoop高可用性:高可用性是Hadoop的基本设计思想,集群中出现的服务器故障、底层软件故障等一般并不会影响Hadoop的正常运行。在管理节点和控制节点,Hadoop多采用主备机方式实现高可用性,若主机出现故障服务会自动切换到备机。对于数据节点,Hadoop会始终监控其运行状态,若出现故障会自动将其隔离,待恢复后重新加入集群。此类指标可用来监控Hadoop实现高可用的过程,例如服务发生主备切换、主备数据同步异常等。同时,通过该监控也能够提示运维人员及时关注并处理主节点发生的异常。该监控类型共有15个监控指标。
监控资源使用情况:Hadoop每类服务都会占用相应的资源,此类指标监控各服务的资源使用情况,例如HDFS磁盘空间使用率超过阈值、NameNode内存使用率超过阈值等。此类监控可配合前两类监控共同分析Hadoop状态,以便实现集群故障点的快速定位。该监控类型共有8个监控指标。
- 还没有人留言评论。精彩留言会获得点赞!