音效处理方法和系统与流程
本发明涉及信号处理
技术领域:
,特别是涉及一种音效处理方法和系统。
背景技术:
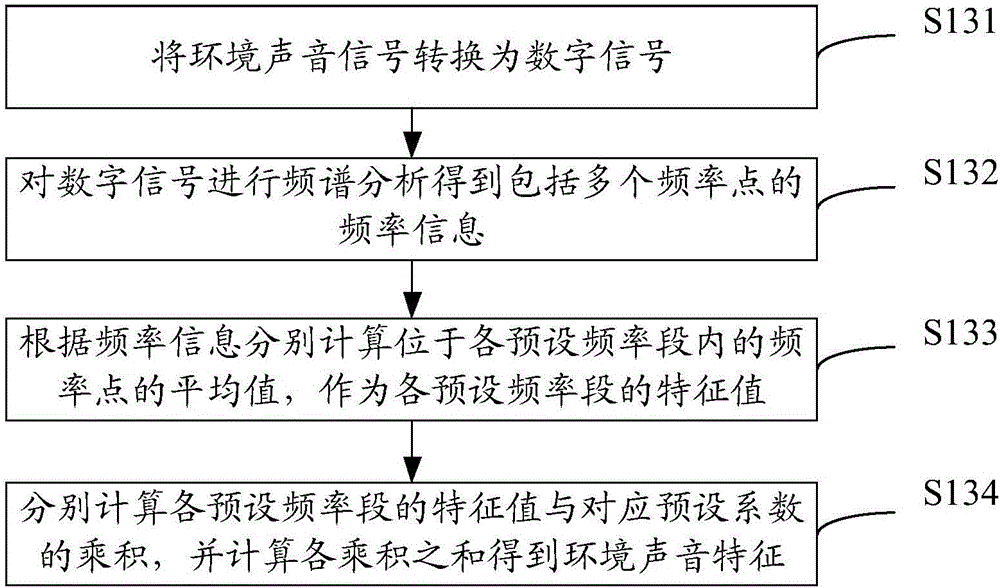
:音视频播放装置进行音视频或节目播放时,可以根据需要设置不同的音效模式。以电视机为例,传统的更换音效模式的方法是用户使用遥控器在显示的菜单界面进行选择,电视机的处理系统根据用户选择的音效模式对声音信号进行处理后输出。然而,电视机所处的外界环境中通常存在噪声,用户并不知道对应于当前的环境,最适合的音效模式是哪种,容易出现电视机的音效处理结果与当前环境不符合的情况,音效处理效果差。技术实现要素:基于此,有必要针对上述问题,提供一种处理效果好的音效处理方法和系统。一种音效处理方法,包括:采集预设时间范围内的环境声音信号;对所述环境声音信号进行特征提取,得到环境声音特征;从预设的多个参考声音特征中选取与所述环境声音特征相似度最大的参考声音特征;查找与选取的参考声音特征对应的预设音效模式,得到匹配音效模式;根据所述匹配音效模式对待播放声音信号进行音效处理。一种音效处理系统,包括:环境声音信号采集模块,用于采集预设时间范围内的环境声音信号;环境声音特征获取模块,用于对所述环境声音信号进行特征提取,得到环境声音特征;参考声音特征选取模块,用于从预设的多个参考声音特征中选取与所述环境声音特征相似度最大的参考声音特征;匹配音效模式查找模块,用于查找与选取的参考声音特征对应的预设音效模式,得到匹配音效模式;音效处理模块,用于根据所述匹配音效模式对待播放声音信号进行音效处理。上述音效处理方法和系统,通过采集预设时间范围内的环境声音信号,对环境声音信号进行特征提取得到环境声音特征;然后从预设的多个参考声音特征中选取与环境声音特征相似度最大的参考声音特征,查找与选取的参考声音特征对应的预设音效模式得到匹配音效模式,并根据匹配音效模式对待播放声音信号进行音效处理。如此,可根据环境声音信号的环境声音特征,自动选取最适合的匹配音效模式,音效处理效果好;同时,无需用户操作,提高用户使用的便利性。附图说明图1为一实施例中音效处理方法的流程图;图2为一实施例中对环境声音信号进行特征提取,得到环境声音特征的具体流程图;图3为一实施例中从预设的多个参考声音特征中选取与环境声音特征相似度最大的参考声音特征的具体流程图;图4为一实施例中音效处理系统的模块图。具体实施方式参考图1,一实施例中的音效处理方法,包括如下步骤。S110:采集预设时间范围内的环境声音信号。预设时间范围指时间段预设设置或时长预先设置的时间范围。声音信号具体可以通过麦克风采集周围环境的声音得到。在一实施例中,预设时间范围为以接收播放指令的时刻为起始时刻、以预设值为时长的时间范围。其中,播放指令指用于指示开启音/视频播放或电视节目播放的指令,例如电视机开机时唤醒处理系统的指令。预设值可以根据实际需要具体设置。本实施例中,预设值为5秒;接收播放指令的时刻对应为电视机开机时刻时,预设时间范围为电视机开机后的前5秒。通常在接收播放指令后,处理系统需要较短的响应时间后才播放音/视频。通过选取接收播放指令的时刻为起始时刻、预设值为时长的时间范围进行声音信号的采集,得到的环境声音信号为启动播放音/视频的之前的声音信号,避免了实际播放的声音对环境声音信号采集的影响,可提高声音信号采集的准确性。可以理解,在其他实施例中,预设时间范围也可以其他时间范围,例如以当前时刻为起始时刻、以预设值为时长的时间范围,当前时刻可以实时设定,实现在播放音/视频的过程中同时采集环境声音信号。S130:对环境声音信号进行特征提取,得到环境声音特征。对环境声音信号进行特征提取得到的环境声音特征可以是数值或图像。在一实施例中,环境声音特征为数值。参考图2,步骤S130包括步骤S131至步骤S134。S131:将环境声音信号转换为数字信号。采集的环境声音为模拟信号,通过模数转换可以将模拟信号转换为数字信号。S132:对数字信号进行频谱分析得到包括多个频率点的频率信息。对数字信号进行频谱分析,具体可以是采用傅里叶变换进行分析,得到数字信号内包含的频率点。S133:根据频率信息分别计算位于各预设频率段内的频率点的平均值,作为各预设频率段的特征值。预设频率段有多个,可以根据实际人耳可听到的声音频率范围设置。将频率信息中不属于任意一个预设频率段的频率点舍弃,按照频率点的大小对各频率点进行分类,对同属于一个预设频率段内的频率点计算平均值,可以得到对应预设频率段的特征值。具体地,若同一个预设频率段内频率点为连续值,则平均值的计算可以是通过对预设频率段内的频率点积分后除以频谱长度;若同一个预设频率段内的频率点为离散值,则平均值可以是通过直接计算各频率点之和后除以频率点数目得到,例如,频率信息中30hz(赫兹)、50hz、100hz、110hz属于同一个预设频率段,则计算30、50、100和110的平均值作为该预设频率段的特征值。在一实施例中,预设频率段包括20hz-200hz、200hz-700hz、700hz-2000hz、2000hz-7000hz及7000hz-15000hz。如此,将通常情况下人耳听到的声音频率范围进行划分,有针对性的进行特征提取,提高数据处理效率。可以理解,在其他实施例中,预设频率段也可以设置为其他数值。S134:分别计算各预设频率段的特征值与对应预设系数的乘积,并计算各乘积之和得到环境声音特征。每一个预设频率段预先对应有一个预设系数,且通过步骤S133,每一个预设频率段对应有一个特征值。通过将各预设频率段的特征值与该预设频率段对应的预设系数相乘,各预设频率段对应得到一个乘积,计算乘积之和则可得到环境声音特征。本实施例中,各个预设频率段20hz-200hz、200hz-700hz、700hz-2000hz、2000hz-7000hz及7000hz-15000hz分别对应的预设系数为:-100、-10、0、10及100。通过对环境声音信号进行频率分析,将根据频率分析得到的频率信息进行计算得到的数值作为环境声音特征,采用量化的形式进行表示,便于数据分析处理。可以理解,在其他实施例中,还可以采用其他方法提取声音特征,例如,对环境声音信号模数转换后的数字信号进行频谱分析,将频谱分析得到的频谱图直接作为环境声音信号。S150:从预设的多个参考声音特征中选取与环境声音特征相似度最大的参考声音特征。参考声音特征指预先设置用于参照比较的声音特征。若环境声音特征为数值,则参考声音特征同样为数值,参考声音特征与环境声音特征的相似度通过计算两者的差值得到,差值越小,则相似度越最大。若环境声音特征为图像,则参考声音特征同样为图像,参考声音特征与环境声音特征的相似度通过图像比较得到,图像比较差异越小,则相似度越大。其中,参考声音特征可以通过预先采集分析得到。在一实施例中,参考图3,步骤S110之前还包括步骤S101至步骤S103。S101:分别对多个模型场景采集预设时长内的声音信号,得到多个参考声音信号。模型场景指的是实际生活场景。模型场景的数量与参考声音特征的数量相等,模型场景的声音信号具体可通过麦克风采集。本实施例中,模型场景包括日间客厅、夜间客厅、酒店、卖场和饭堂五种,分别对应人声嘈杂、寂静、安静、混杂和空旷五种情况。可以理解,在其他实施例中,模型场景还可以为其他场景。预设时长大于预设时间范围对应的时长。通过设置长时间进行模型场景声音信号的采集,得到的声音信号可以准确的表示模型场景对应的环境声音情况,使得得到的参考声音信号更准确。本实施例中,预设时长为10000秒。S102:根据预设时长与预设时间范围对应的时长之比,将各参考声音信号分为多个信号段。预设时长与预设时间范围对应的时长之比可能是大于1的整数值,也可能是大于1的非整数值。参考声音信号为预设时长内各个时刻的声音信号连续集合,将各参考声音信号分为多个信号段,具体可以是以预设时间范围对应的时长为时间间隔、按照时间先后顺序对参考声音信号进行截取分段,最后不足一个时间间隔内的声音信号作为一个信号段。如此,可将每一个模型场景对应的参考声音信号分为多个信号段。S103:提取各信号段的声音特征,根据各信号段的声音特征获取对应的参考声音信号的声音特征得到参考声音特征。提取各信号段的声音特征的具体方法,与提取环境声音信号的声音特征的具体方法相同,在此不做赘述。若提取得到的声音特征为数值,则根据各信号段的声音特征获取对应的参考声音信号的声音特征,具体可以是将各信号段的数值的平均值作为参考声音特征;若提取得到的声音特征为图像,则根据各信号段的声音特征获取对应的参考声音信号的声音特征,具体可以是对各信号段的图像进行图像处理分析,得到代表整个参考声音信号的图像作为参考声音特征。通过采用步骤S101至步骤S103的方式预先采集多个模型场景的参考声音信号,并进行特征提取得到各模型场景的参考声音特征,得到的参考声音特征代表性强且准确性高。S170:查找与选取的参考声音特征对应的预设音效模式,得到匹配音效模式。每一种参考声音特征预先对应有一种预设音效模式,具体可以通过预先将参考声音特征与预设音效模式对应存储,从而根据参考声音特征即可查找到对应的预设音效模式。本实施例中,预设音效模式包括新闻、夜间、影院、标准和音乐五种模式,分别对应日间客厅、夜间客厅、酒店、卖场和饭堂五种模型场景的参考声音特征。音效模式的设置中,通常用到三种标准技术:total-sonic、totalvolume和totalsurround,total-sonic有on/off两种状态,totalvolume有normal/night/off三种状态,totalsurround有on/off两种状态。各预设音效模式对应采用的标准技术的状态如下表1所示。表1total-sonictotalvolumetotalsurround新闻onnormaloff夜间onnightoff影院onoffon标准offoffoff音乐onoffoffS190:根据匹配音效模式对待播放声音信号进行音效处理。获取匹配音效模式后,根据匹配音效模式进行音效处理,具体是采用匹配音效模式对应的标准技术自动对待播放声音信号进行音效处理,使得输出的待播放声音信号适应于当前所处的环境。例如,若匹配音效模式为音乐,则设置total-sonic、totalvolume和totalsurround三种标准技术的状态分别为on、off、off。待播放声音信号可以是电视机的电视声音信号。上述音效处理方法,通过采集预设时间范围内的环境声音信号,对环境声音信号进行特征提取得到环境声音特征;然后从预设的多个参考声音特征中选取与环境声音特征相似度最大的参考声音特征,查找与选取的参考声音特征对应的预设音效模式得到匹配音效模式,并根据匹配音效模式对待播放声音信号进行音效处理。如此,可根据环境声音信号的环境声音特征,自动选取最适合的匹配音效模式,音效处理效果好;同时,无需用户操作,提高用户使用的便利性。上述音效处理方法可以应用于电视机的处理系统,使得电视机可以根据环境自动选择匹配音效模式进行音效处理。上述音效处理方法也可以应用于其他音视频播放装置,例如手机、平板等,使得音视频播放装置在打开播放器时,可以根据环境自动选择匹配音效模式进行音效处理。参考图4,一实施例中的音效处理系统,包括环境声音信号采集模块110、环境声音特征获取模块130、参考声音特征选取模块150、匹配音效模式查找模块170和音效处理模块190。环境声音信号采集模块110用于采集预设时间范围内的环境声音信号。预设时间范围指时间段预设设置或时长预先设置的时间范围。声音信号具体可以通过麦克风采集周围环境的声音得到。在一实施例中,预设时间范围为以接收播放指令的时刻为起始时刻、以预设值为时长的时间范围。其中,播放指令指用于指示开启音/视频播放或电视节目播放的指令,例如电视机开机时唤醒处理系统的指令。预设值可以根据实际需要具体设置。本实施例中,预设值为5秒;接收播放指令的时刻对应为电视机开机时刻时,预设时间范围为电视机开机后的前5秒。通常在接收播放指令后,处理系统需要较短的响应时间后才播放音/视频。通过选取接收播放指令的时刻为起始时刻、预设值为时长的时间范围进行声音信号的采集,得到的环境声音信号为启动播放音/视频的之前的声音信号,避免了实际播放的声音对环境声音信号采集的影响,可提高声音信号采集的准确性。环境声音特征获取模块130用于对环境声音信号进行特征提取,得到环境声音特征。对环境声音信号进行特征提取得到的环境声音特征可以是数值或图像。在一实施例中,环境声音特征为数值。环境声音特征获取模块130包括模数转换单元(图未示)、频谱分析单元(图未示)、特征值计算单元(图未示)和环境声音特征计算单元(图未示)。模数转换单元用于将环境声音信号转换为数字信号。频谱分析单元用于对数字信号进行频谱分析得到包括多个频率点的频率信息。对数字信号进行频谱分析,具体可以是采用傅里叶变换进行分析,得到数字信号内包含的频率点。特征值计算单元用于根据频率信息分别计算位于各预设频率段内的频率点的平均值,作为各预设频率段的特征值。若同一个预设频率段内频率点为连续值,则平均值的计算可以是通过对预设频率段内的频率点积分后除以频谱长度;若同一个预设频率段内的频率点为离散值,则平均值可以是通过直接计算各频率点之和后除以频率点数目得到。在一实施例中,预设频率段包括20hz-200hz、200hz-700hz、700hz-2000hz、2000hz-7000hz及7000hz-15000hz。如此,将通常情况下人耳听到的声音频率范围进行划分,有针对性的进行特征提取,提高数据处理效率。环境声音特征计算单元用于分别计算各预设频率段的特征值与对应预设系数的乘积,并计算各乘积之和得到环境声音特征。本实施例中,各个预设频率段20hz-200hz、200hz-700hz、700hz-2000hz、2000hz-7000hz及7000hz-15000hz分别对应的预设系数为:-100、-10、0、10及100。通过采用模数转换单元、频谱分析单元、特征值计算单元和环境声音特征计算单元,对环境声音信号进行频率分析,将根据频率分析得到的频率信息进行计算得到的数值作为环境声音特征,采用量化的形式进行表示,便于数据分析处理。参考声音特征选取模块150用于从预设的多个参考声音特征中选取与环境声音特征相似度最大的参考声音特征。若环境声音特征为数值,则参考声音特征同样为数值,参考声音特征与环境声音特征的相似度通过计算两者的差值得到,差值越小,则相似度越最大。若环境声音特征为图像,则参考声音特征同样为图像,参考声音特征与环境声音特征的相似度通过图像比较得到,图像比较差异越小,则相似度越大。参考声音特征可以通过预先采集分析得到。在一实施例中,上述音效处理系统还包括参考声音信号采集模块(图未示)、参考声音信号分段模块(图未示)和参考声音特征获取模块(图未示)。参考声音信号采集模块用于分别对多个模型场景采集预设时长内的声音信号,得到多个参考声音信号。其中,模型场景的数量与参考声音特征的数量相等,预设时长大于预设时间范围对应的时长。本实施例中,模型场景包括日间客厅、夜间客厅、酒店、卖场和饭堂五种,分别对应人声嘈杂、寂静、安静、混杂和空旷五种情况。可以理解,在其他实施例中,模型场景还可以为其他场景。本实施例中,预设时长为10000秒。参考声音信号分段模块用于根据预设时长与预设时间范围对应的时长之比,将各参考声音信号分为多个信号段。参考声音信号为预设时长内各个时刻的声音信号连续集合,将各参考声音信号分为多个信号段,具体可以是以预设时间范围对应的时长为时间间隔、按照时间先后顺序对参考声音信号进行截取分段,最后不足一个时间间隔内的声音信号作为一个信号段。如此,可将每一个模型场景对应的参考声音信号分为多个信号段。参考声音特征获取模块用于提取各信号段的声音特征,根据各信号段的声音特征获取对应的参考声音信号的声音特征得到参考声音特征。通过采用参考声音信号采集模块、参考声音信号分段模块和参考声音特征获取模块,预先采集多个模型场景的参考声音信号,并进行特征提取得到各模型场景的参考声音特征,得到的参考声音特征代表性强且准确性高。匹配音效模式查找模块170用于查找与选取的参考声音特征对应的预设音效模式,得到匹配音效模式。本实施例中,预设音效模式包括新闻、夜间、影院、标准和音乐五种模式,分别对应日间客厅、夜间客厅、酒店、卖场和饭堂五种模型场景的参考声音特征。音效模式的设置中,通常用到三种标准技术:total-sonic、totalvolume和totalsurround,total-sonic有on/off两种状态,totalvolume有normal/night/off三种状态,totalsurround有on/off两种状态。音效处理模块190用于根据匹配音效模式对待播放声音信号进行音效处理。获取匹配音效模式后,根据匹配音效模式进行音效处理,具体是采用匹配音效模式对应的标准技术自动对待播放声音信号进行音效处理,使得输出的待播放声音信号适应于当前所处的环境。其中,待播放声音信号可以是电视机的电视声音信号。上述音效处理系统,通过环境声音信号采集模块110采集预设时间范围内的环境声音信号,环境声音特征获取模块130对环境声音信号进行特征提取得到环境声音特征;然后参考声音特征选取模块150从预设的多个参考声音特征中选取与环境声音特征相似度最大的参考声音特征,匹配音效模式查找模块170查找与选取的参考声音特征对应的预设音效模式得到匹配音效模式,音效处理模块190根据匹配音效模式对待播放声音信号进行音效处理。如此,可根据环境声音信号的环境声音特征,自动选取最适合的匹配音效模式,音效处理效果好;同时,无需用户操作,提高用户使用的便利性。以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1