一种消息免打扰的权限控制方法及装置与流程
本发明涉及声控技术领域,更具体地,涉及一种消息免打扰的权限控制方法及装置。
背景技术:
随着谷歌、苹果、三星、华为等电子巨头相继进入可穿戴设备市场,在过去的几年当中,越来越多的企业加入当这个新兴行业当中来。可穿戴设备在2015年可谓是大放异彩,吸引了众多消费者的注意。根据中国信息通信研究院发布的《可穿戴设备研究报告》显示,2015年中国智能可穿戴设备市场规模为125.8亿元,增速高达471.8%。而儿童可穿戴设备作为其中的一个分支方向,发展势头非常迅猛。
无论是在国内还是国外,早有大量的企业着手布局儿童可穿戴设备市场。儿童可穿戴设备的功能主要涉及儿童安全、儿童健康的定位服务、健康体征检测、通讯交流、教育等方面。但是,目前的可穿戴设备为了获得足够的功能和体验,需要用户不断的对产品“服务”,需要有不少的手动操作。主要表现在,一方面:功能模式的切换(上课、睡眠模式等),如果用户自己忘记了切换,就无法实现对应功能。另一方面:如果用户没有及时准确的切换到适当的功能模式,就有可能受到外来通知的打扰,例如上课的时候,家长来电,打扰课堂。如何减少用户在使用产品时投入的精力和时间,是目前可穿戴设备迈向智能化过程中亟待解决的问题。
技术实现要素:
鉴于上述问题,本发明提出了一种消息免打扰的权限控制方法及装置,能够根据环境自动切换功能模式,提高用户体验。
本发明实施例中提供了一种消息免打扰的权限控制方法,包括:
通过声音接收器获取在预设时长内的环境音;
根据所述环境音的音量大小和声纹数量,判断用户所处状态;
当所述音量大小低于第一预设值,和/或所述声纹数量少于阈值时,判断用户处于会议状态,开启与会议状态相应的会议模式的通信提醒。
优选地,所述开启与会议状态相应的会议模式的通信提醒的步骤之后,包括:
当接收到短信消息时,通过振动器以振动方式提醒用户。
优选地,所述开启与会议状态相应的会议模式的通信提醒的步骤之后,包括:
当接收到通话来电时,通过振动器以振动方式提醒用户。
优选地,当所述音量大小高于第二预设值,且所述声纹数量多于所述阈值时,判断用户处于户外状态,开启与户外状态相应的户外模式的通信提醒。
优选地,所述开启与户外状态相应的户外模式的通信提醒的步骤之后,包括:
当接收到短信消息时,通过振动器和扬声器以振动和响铃方式提醒用户。
优选地,所述开启与户外状态相应的户外模式的通信提醒的步骤之后,包括:
当接收到通话来电时,通过振动器和扬声器以振动和响铃方式提醒用户。
优选地,所述根据所述环境音的音量大小和声纹数量,判断用户所处状态的步骤,包括:
分析所述环境音中的声纹,当辨别其中一个声纹与模型库中的特征声纹相符时,判断用户处于忙碌状态;
将用户处于忙碌状态时接收到的短信消息或通话来电,在所述忙碌状态解除后再以通知方式提醒用户。
优选地,通过声音接收器获取在预设时长内的环境音的步骤之前,包括:
采集预设说话人的声纹,作为特征声纹录入模型库。
优选地,识别其中一个声纹与模型库中的特征声纹相符的步骤,具体包括:
Sp1,在所述环境音的声纹集合中选取一个测试声纹;
Sp2,对该测试声纹采用预设算法在模型库的特征声纹码书中查找与其距离最近的M个码字;
Sp3,对M个码字分别查找其所对应的特征声纹码书ID并对其所对应的说话人Scores[i]进行加分,Scores[i]=Scores[i]+1;
重复所述Sp1至所述Sp3直到所述环境音的声纹集合为空;
在Scores[i]中选出得分高于阈值的目标说话人,辨别该目标说话人的声纹与模型库中的特征声纹相符。
优选地,所述预设算法包括:
针对模型库中N个目标说话人的特征声纹码书,以及每个码书中存在L个码字,构建N*L个码字的VPT树;
采用VPT树进行码字索引,查找与所述测试声纹距离最近的M个码字。
相应地,本发明实施例提供了一种消息免打扰的权限控制装置,包括:
声音接收单元,用于通过声音接收器获取在预设时长内的环境音;
状态判断单元,用于根据所述环境音的音量大小和声纹数量,判断用户所处状态;
模式切换单元,用于当所述音量大小低于第一预设值,和/或所述声纹数量少于阈值时,判断用户处于会议状态,开启与会议状态相应的会议模式的通信提醒。
优选地,所述模式切换单元,包括:
第一短信提醒单元,用于当接收到短信消息时,通过振动器以振动方式提醒用户。
优选地,所述模式切换单元,包括:
第一来电提醒单元,用于当接收到通话来电时,通过振动器以振动方式提醒用户。
优选地,模式切换单元,还用于当所述音量大小高于第二预设值,且所述声纹数量多于所述阈值时,判断用户处于户外状态,开启与户外状态相应的户外模式的通信提醒。
优选地,所述模式切换单元,包括:
第二短信提醒单元,用于当接收到短信消息时,通过振动器和扬声器以振动和响铃方式提醒用户。
优选地,所述模式切换单元,包括:
第二来电提醒单元,用于当接收到通话来电时,通过振动器和扬声器以振动和响铃方式提醒用户。
优选地,所述状态判断单元,包括:
声纹辨别单元,用于分析所述环境音中的声纹,当辨别其中一个声纹与模型库中的特征声纹相符时,判断用户处于忙碌状态;
延迟通知单元,用于将用户处于忙碌状态时接收到的短信消息或通话来电,在所述忙碌状态解除后再以通知方式提醒用户。
优选地,包括:
声纹录入单元,用于采集预设说话人的声纹,作为特征声纹录入模型库。
优选地,所述声纹辨别单元,具体用于执行以下步骤,
Sp1,在所述环境音的声纹集合中选取一个测试声纹;
Sp2,对该测试声纹采用预设算法在模型库的特征声纹码书中查找与其距离最近的M个码字;
Sp3,对M个码字分别查找其所对应的特征声纹码书ID并对其所对应的说话人Scores[i]进行加分,Scores[i]=Scores[i]+1;
重复所述Sp1至所述Sp3直到所述环境音的声纹集合为空;
在Scores[i]中选出得分高于阈值的目标说话人,辨别该目标说话人的声纹与模型库中的特征声纹相符。
优选地,所述声纹辨别单元,包括:VPT算法单元;
所述VPT算法单元,用于针对模型库中N个目标说话人的特征声纹码书,以及每个码书中存在L个码字,构建N*L个码字的VPT树;采用VPT树进行码字索引,查找与所述测试声纹距离最近的M个码字。
相对于现有技术,本发明提供的方案,通过声音接收器获取在预设时长内的环境音,例如通过听筒获取一段时长的环境音进行分析,根据所述环境音的音量大小和声纹数量,判断用户所处状态。当所述音量大小低于第一预设值,和/或所述声纹数量少于阈值时,判断用户处于会议状态,开启与会议状态相应的会议模式的通信提醒。例如,在睡觉的时候,音量低于第一预设值,开启与会议状态相应的会议模式的通信提醒,以免打扰睡眠。又例如,在上课的时候,音量比户外环境要低,只有老师和少数同学的声音,声纹数量少于阈值,此时,也开启与会议状态相应的会议模式的通信提醒,以免打扰孩子上课。
本发明附加的方面和优点将在下面的描述中部分给出,这些将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明一种消息免打扰的权限控制方法的流程图。
图2为本发明一种消息免打扰的权限控制方法的第一实施例流程图。
图3为本发明一种消息免打扰的权限控制方法的第二实施例流程图。
图4为本发明一种消息免打扰的权限控制装置的示意图。
图5为本发明一种消息免打扰的权限控制装置的第一实施例示意图。
图6为本发明一种消息免打扰的权限控制装置的第二实施例示意图。
具体实施方式
为了使本技术领域的人员更好地理解本发明方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。
在本发明的说明书和权利要求书及上述附图中的描述的一些流程中,包含了按照特定顺序出现的多个操作,但是应该清楚了解,这些操作可以不按照其在本文中出现的顺序来执行或并行执行,操作的序号如101、102等,仅仅是用于区分开各个不同的操作,序号本身不代表任何的执行顺序。另外,这些流程可以包括更多或更少的操作,并且这些操作可以按顺序执行或并行执行。需要说明的是,本文中的“第一”、“第二”等描述,是用于区分不同的消息、设备、模块等,不代表先后顺序,也不限定“第一”和“第二”是不同的类型。
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
图1为本发明一种消息免打扰的权限控制方法的流程图,包括:
S101:通过声音接收器获取在预设时长内的环境音;
S102:根据所述环境音的音量大小和声纹数量,判断用户所处状态;
S103:当所述音量大小低于第一预设值,和/或所述声纹数量少于阈值时,判断用户处于会议状态,开启与会议状态相应的会议模式的通信提醒。
相对于现有技术,本发明提供的方案,通过声音接收器获取在预设时长内的环境音,例如通过听筒获取一段时长的环境音进行分析,根据所述环境音的音量大小和声纹数量,判断用户所处状态。当所述音量大小低于第一预设值,和/或所述声纹数量少于阈值时,判断用户处于会议状态,开启与会议状态相应的会议模式的通信提醒。例如,在睡觉的时候,音量低于第一预设值,开启与会议状态相应的会议模式的通信提醒,以免打扰睡眠。又例如,在上课的时候,音量比户外环境要低,只有老师和少数同学的声音,声纹数量少于阈值,此时,也开启与会议状态相应的会议模式的通信提醒,以免打扰孩子上课。
需要补充说明的是,本发明除了能够应用于可穿戴设备,同样能够应用于手机、IPAD等智能终端。
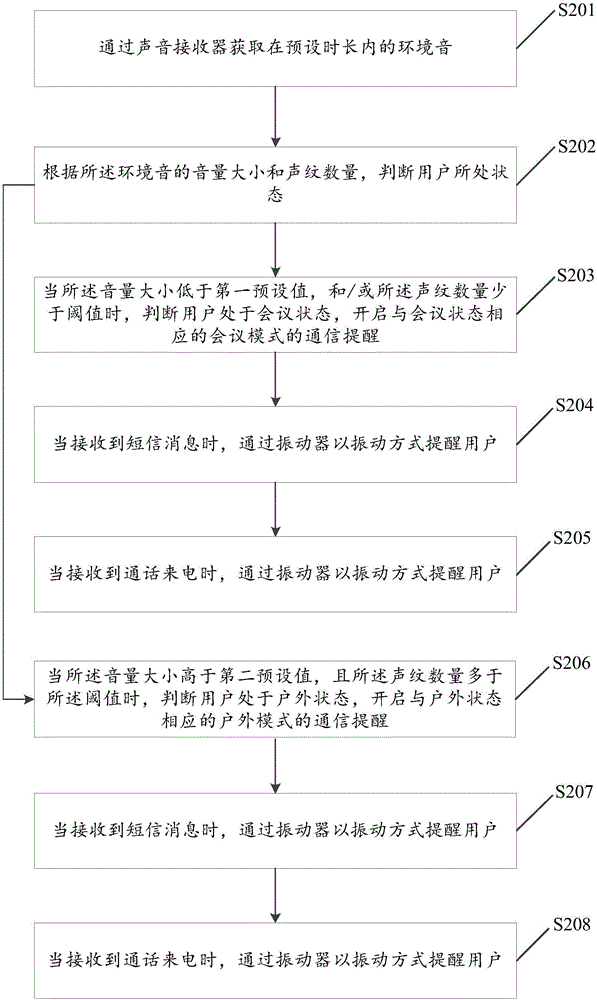
图2为本发明一种消息免打扰的权限控制方法的第一实施例流程图。与图1相比,图2的第一实施例还可以实现户外模式的切换。
S201:通过声音接收器获取在预设时长内的环境音;
S202:根据所述环境音的音量大小和声纹数量,判断用户所处状态;
S203:当所述音量大小低于第一预设值,和/或所述声纹数量少于阈值时,判断用户处于会议状态,开启与会议状态相应的会议模式的通信提醒。
S204:当接收到短信消息时,通过振动器以振动方式提醒用户。
S205:当接收到通话来电时,通过振动器以振动方式提醒用户。
S206:当所述音量大小高于第二预设值,且所述声纹数量多于所述阈值时,判断用户处于户外状态,开启与户外状态相应的户外模式的通信提醒。
S207:当接收到短信消息时,通过振动器和扬声器以振动和响铃方式提醒用户。
S208:当接收到通话来电时,通过振动器和扬声器以振动和响铃方式提醒用户。
户外模式与会议模式,功能相反。例如,孩子在玩耍的时候,身边的游戏机声音,同伴嬉戏声音等等,都会干扰孩子接听家长来电来信的通知声。故此,当所述音量大小高于第二预设值,且所述声纹数量多于所述阈值时,判断用户处于户外状态,开启与户外状态相应的户外模式的通信提醒。在户外模式下,当接收到短信消息时,通过振动器和扬声器以振动和响铃方式提醒用户。当接收到通话来电时,通过振动器和扬声器以振动和响铃方式提醒用户。而相反,在会议模式下,当接收到短信消息时,通过振动器以振动方式提醒用户。当接收到通话来电时,通过振动器以振动方式提醒用户。
需要补充说明的是,除了户外模式与会议模式,还有普通模式,在普通模式下,按照用户默认的来电铃声和/或来电振动告知用户。
图3为本发明一种消息免打扰的权限控制方法的第二实施例流程图。图3的第二实施例与图1、2相比,第二实施例还构建了声纹的模型库,通过检测环境音中是否存在与模型库内的特征声纹相匹配的声纹,判断用户是否正在与重要的目标人物进行交谈,如果是,则开启忙碌状态,避免外界的打扰。
S301:采集预设说话人的声纹,作为特征声纹录入模型库。
S302:通过声音接收器获取在预设时长内的环境音;
S303:根据所述环境音的音量大小和声纹数量,判断用户所处状态;
S304:分析所述环境音中的声纹,当辨别其中一个声纹与模型库中的特征声纹相符时,判断用户处于忙碌状态;
S305:将用户处于忙碌状态时接收到的短信消息或通话来电,在所述忙碌状态解除后再以通知方式提醒用户。
S306:当所述音量大小低于第一预设值,和/或所述声纹数量少于阈值时,判断用户处于会议状态,开启与会议状态相应的会议模式的通信提醒。
在第二实施例当中,首先,采集预设说话人的声纹,作为特征声纹录入模型库。例如,可以采集爸爸、妈妈、老师的声纹,存储到模型库之内。通过声音接收器获取在预设时长内的环境音,根据所述环境音的音量大小和声纹数量,判断用户所处状态。以上课环境为例,环境音当中,主要是老师的声音,分析所述环境音中的声纹,当辨别其中一个声纹与模型库中的特征声纹相符时,判断用户处于忙碌状态。通过与模型库中的特征声纹进行比对,能够准确的分析出用户所述状态,相比于第二实施例通过声纹数量来判断,更为准确。在忙碌状态下,将用户处于忙碌状态时接收到的短信消息或通话来电,在所述忙碌状态解除后再以通知方式提醒用户。例如,下课了,老师离开,环境音之中只有同学们的声音,此时解除忙碌状态,短信消息以通知方式提醒用户,上课期间的来电也是以通知方式通知用户,以便用户回电。当所述音量大小低于第一预设值,和/或所述声纹数量少于阈值时,判断用户处于会议状态,开启与会议状态相应的会议模式的通信提醒。
优选地,识别其中一个声纹与模型库中的特征声纹相符的步骤,具体包括:
Sp1,在所述环境音的声纹集合中选取一个测试声纹;
Sp2,对该测试声纹采用预设算法在模型库的特征声纹码书中查找与其距离最近的M个码字;
Sp3,对M个码字分别查找其所对应的特征声纹码书ID并对其所对应的说话人Scores[i]进行加分,Scores[i]=Scores[i]+1;
重复所述Sp1至所述Sp3直到所述环境音的声纹集合为空;
在Scores[i]中选出得分高于阈值的目标说话人,辨别该目标说话人的声纹与模型库中的特征声纹相符。
具体地,初始化:T置为测试特征向量集合;VPT为对所有目标说话人码书中的码字进行索引所构成的VPT树;Scores[i]为第i个码书所对应的目标说话人得分,对所有目标说话人的得分置0。
在识别的阶段首先对环境音的声纹进行特征提取,提取出所述环境音的声纹集合。在所述环境音的声纹集合中选取一个测试声纹;对该测试声纹采用预设算法在模型库的特征声纹码书中查找与其距离最近的M个码字,并找到每一节点所对应的码书以及该码书所对应的目标说话人,然后给该目标说话人的评分增加一分。当所述环境音的声纹集合中的所有测试声纹都测试完毕后,选取得分最高的K个目标说话人,辨别该目标说话人的声纹与模型库中的特征声纹相符。
优选地,所述预设算法包括:VPT树搜索算法;
针对模型库中N个目标说话人的特征声纹码书,以及每个码书中存在L个码字,构建N*L个码字的VPT树;
采用VPT树进行码字索引,查找与所述测试声纹距离最近的M个码字。
VPT树(Vantage Point Tree)是一种度量空间上的索引结构,只能采用静态的方式进行创建,不能进行动态的插入和删除元素。同时VPT树是采用连续距离的方式进行构建的,是一种基于距离的二叉平衡树,因而VPT的搜索时间复杂度为O(log n)。由于VPT是度量空间中的索引结构,因而只能利用其距离信息,VPT树的构建的思想也在于如何在高维空间中有效的利用距离信息来构建二叉搜索树。VPT树的构建算法以及搜索算法类似于二叉搜索树,均较为简单。假设系统中已经存在N个目标说话人的码书,每个码书中存在L个码字,那么则针对N*L个码字构建VPT树。在构建好的VPT树中,所有的码字均为节点,每个节点存储着码字所对应的码书信息。即针对每一个VPT树中的节点,该节点一定为某一码书的码字,且该节点记录了该节点属于哪一码书。这样就建立了每一节点与其码书,以及每一码书与相应说话人之间的对应关系。
在采用VPT树的方式进行码字索引,每个节点均为码书中的码字,每个节点分别记录着该码字的编号、该码字属于哪一个码书以及指向该节点左孩子和右孩子的指针。
除了VPT树搜索算法之外,还可以采用传统的红黑树及B+树搜索算法,两者之间的区别主要在于采用VPT树的方式可以对高维的特征向量进行搜索。而采用红黑树和B+树的形式,只能对标量形式的数值进行搜索。由于在语音信息中抽取的特征参数为高维的向量,因而选取了VPT树的方式进行搜索,从而降低搜索的时间复杂度。
与传统的矢量量化方式相比,采用矢量量化需要采用全搜索的方式计算测试特征向量与所有码书的每一个码字之间的距离,系统的计算复杂度正比于码书的个数以及每个码书中码字的个数的乘积,即为O(NL),其中N为目标说话人的个数,L为矢量量化的级数。而采用VPT方式,系统的计算复杂度对数正比于码书的个数与每个码书中码字的个数的乘积,即为O(log NL),因而采用该种方式可以大大的提高系统的识别速度。
图4为本发明一种消息免打扰的权限控制装置的示意图,包括:
声音接收单元,用于通过声音接收器获取在预设时长内的环境音;
状态判断单元,用于根据所述环境音的音量大小和声纹数量,判断用户所处状态;
模式切换单元,用于当所述音量大小低于第一预设值,和/或所述声纹数量少于阈值时,判断用户处于会议状态,开启与会议状态相应的会议模式的通信提醒。
图4与图1相对应,图中各个单元的运行方式与方法中的相同。
图5为本发明一种消息免打扰的权限控制装置的第一实施例示意图。
如图5所示,所述模式切换单元,包括:
第一短信提醒单元,用于当接收到短信消息时,通过振动器以振动方式提醒用户。
第一来电提醒单元,用于当接收到通话来电时,通过振动器以振动方式提醒用户。
如图5所示,模式切换单元,还用于当所述音量大小高于第二预设值,且所述声纹数量多于所述阈值时,判断用户处于户外状态,开启与户外状态相应的户外模式的通信提醒。
如图5所示,所述模式切换单元,包括:
第二短信提醒单元,用于当接收到短信消息时,通过振动器和扬声器以振动和响铃方式提醒用户。
第二来电提醒单元,用于当接收到通话来电时,通过振动器和扬声器以振动和响铃方式提醒用户。
图5与图2相对应,图中各个单元的运行方式与方法中的相同。
图6为本发明一种消息免打扰的权限控制装置的第二实施例示意图。
如图6所示,所述状态判断单元,包括:
声纹辨别单元,用于分析所述环境音中的声纹,当辨别其中一个声纹与模型库中的特征声纹相符时,判断用户处于忙碌状态;
延迟通知单元,用于将用户处于忙碌状态时接收到的短信消息或通话来电,在所述忙碌状态解除后再以通知方式提醒用户。
如图6所示,包括:
声纹录入单元,用于采集预设说话人的声纹,作为特征声纹录入模型库。
图6与图3相对应,图中各个单元的运行方式与方法中的相同。
优选地,所述声纹辨别单元,具体用于执行以下步骤,
Sp1,在所述环境音的声纹集合中选取一个测试声纹;
Sp2,对该测试声纹采用预设算法在模型库的特征声纹码书中查找与其距离最近的M个码字;
Sp3,对M个码字分别查找其所对应的特征声纹码书ID并对其所对应的说话人Scores[i]进行加分,Scores[i]=Scores[i]+1;
重复所述Sp1至所述Sp3直到所述环境音的声纹集合为空;
在Scores[i]中选出得分高于阈值的目标说话人,辨别该目标说话人的声纹与模型库中的特征声纹相符。
优选地,所述声纹辨别单元,包括:VPT算法单元;
所述VPT算法单元,用于针对模型库中N个目标说话人的特征声纹码书,以及每个码书中存在L个码字,构建N*L个码字的VPT树;采用VPT树进行码字索引,查找与所述测试声纹距离最近的M个码字。
所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,上述描述的系统,装置和单元的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!