基于双层模型体系的无线传感器网络的二次分簇算法的制作方法
本发明属于无线传感器网络技术领域,涉及一种基于双层模型体系的无线传感器网络的二次分簇算法。
背景技术:
最近几年,随着大量基于时空相关性的分层路由协议的提出,层次性数据采集方法得到了快速地发展,但是仍然存在许多不足。簇内成员节点之间采用轮值的方式进行数据采集,有效的均衡了簇内成员节点的能量消耗,但对簇所覆盖区域的信息提取不够充分;建立预测模型,并基于局部时间段的数据相关性,进行二次分簇,对簇所覆盖区域的信息提取相对充分,但簇内节点能量消耗不够均衡。
技术实现要素:
针对现有技术存在的问题,本发明提供一种基于双层模型体系的无线传感器网络的二次分簇算法。该方法能够全面、高效的收集簇内信息,此外,还延长了整个网网络的生命周期。
本发明的技术方案为:
基于双层模型体系的无线传感器网络的二次分簇算法,包括以下步骤:
第一步,利用采集到的样本构建双预测模型;
第二步,基于双预测模型的相关性,对簇内节点进行二次分簇。
本发明的有益效果为:相比较基于轮值的数据采集方案,基于双模型数据相关性的二次分簇算法,能够更全面且精确的反应簇内节点所覆盖区域的信息;与已有的基于轮值的数据采集方法相比,本发明对簇所覆盖区域的信息提取更充分;与已有的基于局部数据相关性的二次分簇方法相比,基于双模型的数据相关性的二次分簇算法,在不降低采集精度的前提下,能够有效延长整个网络的生命周期。
附图说明
图1为一次趋势模型的构建流程图;
图2为一次调整模型的构建流程图;
图3为二次分簇的算法流程图;
图4为节点实际观测值与模型预测值的对比图,图4(a)为18号节点采用Cor算法预测的效果图;图4(b)为18号节点采用DMC算法预测的效果图;4(c)为20号节点采用Cor算法预测的效果图;图4(d)为20号节点采用DMC算法预测的效果图;
图5为半数节点死亡时系统运行周期数的统计图。
具体实施方式
以下对本发明做进一步说明。
基于双层模型体系的无线传感器网络的二次分簇算法,具体步骤如下:
第一步,利用采集到的样本构建双预测模型
双预测模型的构造思想是:首先通过确定性因素分解方法提取序列的确定性信息,即利用线性函数表示采集数据的变化趋势,此过程称为趋势模型yt的构建,;然后再检测残差序列的自相关性并建模,即利用自回归模型来预测残差序列的扰动,此过程称为调整模型vt的构建。双预测模型具体如下:
其中,xt′为趋势模型自变量;yt为观测向量;α为趋势模型参数,通过卡尔曼滤波迭代计算出α的最优解,通过残差三阶累积量实时检测趋势模型的有效性;vt为趋势模型和观测值的残差,利用调整模型拟合,{vt}为残差序列;为调整模型参数,确定样本自相关性后,通过最小二乘法计算出的最优解,最后利用AIC定阶法确定回归模型阶数p;{εt}是白噪声序列,每个元素均服从均数为零、方差为δ2的正态分布,且相互之间独立。
以下详细介绍两个模型的构建过程。
1.1)构建趋势模型
趋势模型,用于描述采集量的分段线性变化趋势,表达式见公式(1)。趋势模型的构建流程图见说明图1,解释如下:
a)将公式(1)中的趋势模型写成状态空间的形式,即
量测方程:yt=x′tαt+ut (2)
状态方程:
其中,趋势模型的自变量为单变量,表示为x′t=[1 t]′;参数αt=[bt kt],bt、kt分别对应线性函数的截距和斜率;扰动项ut和εt相互独立;T为用于构建趋势模型的样本数量。
b)结合公式(2)和(3),进行卡尔曼滤波迭代:
其中,系统矩阵Zt,Tt,Rt,Qt,H是已知的;卡尔曼滤波的初值可以按a0和P0或a1|0和P1|0指定。对于t=1,2,…,T,每当得到一个观测值时,卡尔曼滤波提供了状态向量参数的最优估计。
当所有的T个观测值都已处理,卡尔曼滤波基于样本序列{yt},产生当前趋势模型参数α的最优估计,趋势模型构建成功。
c)利用残差三阶累积量,检测趋势模型有效性
{d(k)}是ith时间点最近的N个残差数据。假设{d(k)}满足遍历性,残差三阶累积量计算方法如下:
残差三阶累积量的标准化:
进行阈值检测:
当残差数据更新到ith,进行残差三阶累积量的检测。如果检测结论为模型有效,直接进入(i+1)th;否则,进行趋势模型更新。
1.2)构建调整模型
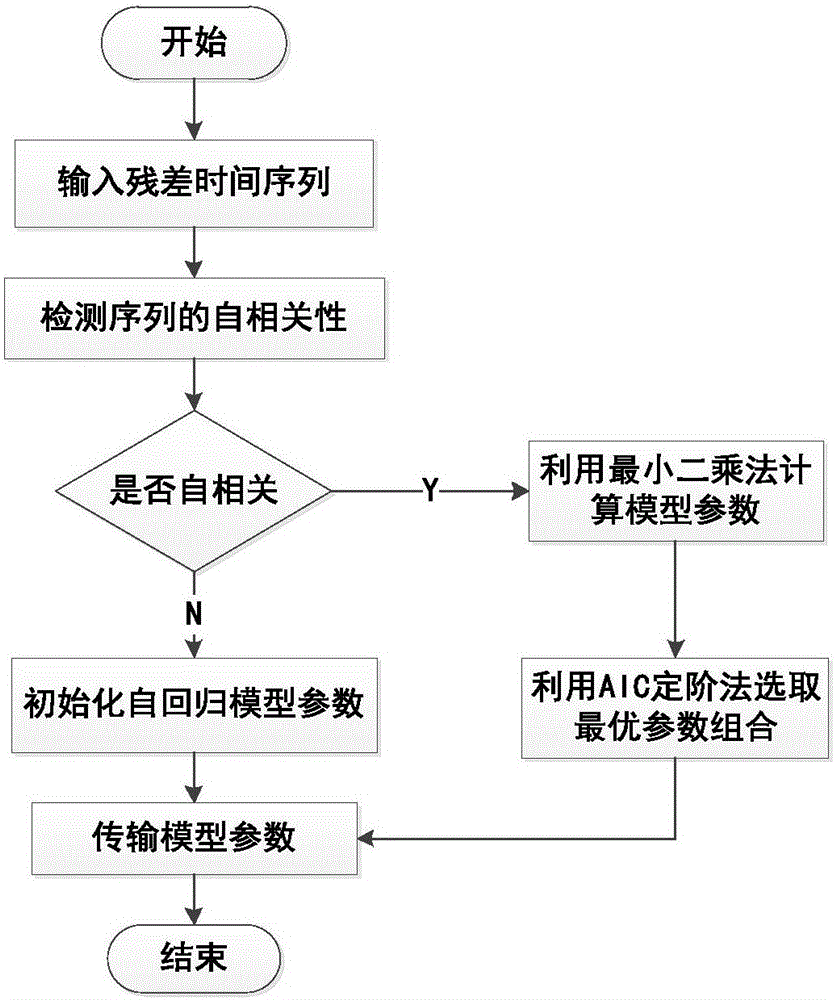
调整模型,用于描述采集量在趋势模型基础上的自然扰动,表达式见公式(8)。调整模型的构建流程图见说明图2,解释如下:
a)采用p阶自回归模型作为调整模型,表达式如下:
其中,为模型参数;∈t为独立同分布的随机变量,且满足:以及E(∈t)=0。
b)检测残差时间序列的自相关性
其中,{Y(i)}为残差序列,N,P已知,且根据样本量设定。如果自相关序列{R(i)/R(0)}最终收敛于零或者截尾,则残差序列具有很强的自相关性。
c)利用最小二乘法分别计算P=1,2…,5时,AR模型的参数:
其中Y=[xn+1 xn+2 … xN]T,ε=[εn+1 εn+2 … εN]T,则的最小二乘估计为:
d)利用AIC准则函数定阶:
AIC(n)=N lnδ2ε+2n (12)
其中,n=1,2…,5,代表调整模型阶数,δ2ε为对应残差序列的方差,N为残差序列的样本量。
选择AIC值最小的阶数P及其对应的参数组,做为调整模型参数的最优解,至此,调整模型构建成功。
第二步,基于双模型的相关性,对簇内节点进行二次分簇
第一部分已经完成了双模型的构建,这一部分将利用得到的双模型对簇内成员节点进行二次分簇,流程图见说明图3,步骤如下:
2.1)采用hausdorff距离,计算当前节点与每个邻近节点趋势模型的相关性,所述的hausdorff距离为:
h(A,B)=max{min{d(a,b)}} (13)
a∈A b∈B
其中,集合A={M1(y1,t1),M2(y2,t2)…,Mn(yn,tn)},元素a=Mi(yi,ti),代表分段线性函数第i段的起始点,将每个点连接起来即为当前节点的趋势模型;集合B、元素b的定义同上,代表当前节点的某个邻近节点的趋势模型;d(a,b)表示元素a和b的欧几里得距离。
通过计算,最终得到当前节点与其所有邻近节点趋势模型的相关系数集合HA={h(A,B1),h(A,B2)…,h(A,Bn)}。
2.2)计算当前节点与每个邻近节点调整模型的相关系数,这里通过对比自回归模型的随机扰动量ε~N(0,δ2)实现,最终得到调整模型相关系数集合G={δ21/δ2,δ22/δ2…,δ2n/δ2},其中δ2为当前节点调整模型随机扰动量的方差,δ2i为邻居节点调整模型的随机扰动量。
2.3)按照一定的权重,如公式(14)所示,综合双模型的相关系数,得到当前节点与其邻近节点数据的相关系数,即集合C={c1,c2…,cn},公式(14)具体为:
ci=αhi+βgi (14)
其中,α,β分别为分配给趋势模型、调整模型相关系数的权重;hi为趋势模型相关系数;gi为调整模型相关系数。
2.4)根据当前节点与其邻居节点的相关性,选出代表节点
这里设定两个相关系数阈值cmax和cmin,分别代表极度不相关和极度相关的临界值;分别计算集合中cmax≤c和cmin≥c所占的比例,并用puc,pc表示;再次设定百分比阈值p,按照以下三种情况,将簇内节点进行分类:
①当p≤pc时,代表当前节点采集到的数据和其大部分邻居节点采集到的数据具有很高的相关性,因而被选为代表节点(代表自己和其他相邻节点),处于工作状态,实时的将更新后的模型传送给簇头节点;
②当p≤puc时,代表当前节点采集到的数据和其大部分邻居节点采集到的数据具有很低的相关性,因而被选为代表节点(仅代表自己),处于工作状态,实时的将更新后的模型传送给簇头节点;
③当p≥pc且p≥puc时,当前节点可以被其他节点所代表,成为普通节点,处于休眠状态
以下从两个方面对算法性能进行对比分析。
首先是算法的数据预测精度。Cor算法采用簇内节点轮值的方式进行数据采集,本专利算法(DMC)选取代表节点代表整个簇进行数据采集,图4为随机选取的两个簇内节点(18号和20号),在同一时间段,分别采用以上两种算法,对节点观测值进行预测的效果图。分别对比图4(a)和图4(b)、图4(c)和图4(d),观察可发现,DMC算法表现出了更高的预测效果。针对500个数据,分别统计两种算法的单步预测平均绝对误差和单步预测平均绝对误差百分比两项性能指标,如表一所示。表中DMC算法在两项指标上均低于Cor算法,再一次验证了DMC算法具有更高的预测精度。
表一 预测模型性能分析
其次是在应用算法之后,网络的生命周期。2TC-cor算法采用基于局部数据相关性的二次分簇算法,本专利算法(DMC)通过对比每个节点双模型的相关性来进行二次分簇,如图5所示,当系统节点死亡率达到50%时,随着总结点数的增加,采用DMC算法的系统,其已运行周期数,明显高于采用2TC-cor算法的系统。由此可以证明:本专利算法在提升网络生命周期方面具有更优越的性能。
- 还没有人留言评论。精彩留言会获得点赞!