一种基于深度学习的视频增强与传输方法与流程
本发明涉及计算机人工智能技术,并应用在视频增强与传输领域,尤其涉及一种基于深度学习的视频增强与传输方法。
背景技术:
根据互联网行业报告调查显示,到2020年,互联网上80%的数据将是视频数据。虽然移动终端的计算能力大幅提高,4G网络也日益完善,但是视频数据的爆发式增长给在移动互联网上视频存储和传输带来了新的挑战。以视频直播平台为例,目前中国在线直播平台数量接近300家,有几十家投资机构参与了投资,其中网络直播的市场规模约为150亿,用户观看数量也已突破2亿人次。根据方正证券的预测,到2020年中国的网络直播市场规模将超过1000亿元。虽然视频直播改变了人与人之间的连接方式,但是视频数据的大量传输意味着巨大的带宽成本。如果视频直播平台同时在线用户达到100万,每个月带宽成本就会超过3000万元。根据财报数据显示,虎牙直播2015年仅第四季度就支出1.611亿元的带宽成本,平均每月超5000万元,占了公司总开支的30%-40%。因此,如何有效地减少视频传输所需的带宽成本成为一个急需解决的关键问题。
目前,为了减少带宽成本,主流的技术主要有两种:高效的视频编解码技术和优化的视频传输方案。由于视频当中有很多空间和时间冗余信息,使用不同的视频编码技术能够有效的压缩视频大小,从而减少传输所需流量。目前主流的视频编码技术是H.264,占有互联网上90%的视频市场。另外,我国即将推出第二代视频编码标准AVS2,比H.264的压缩效率有更大的提升。然而,高效的视频压缩技术包括AVS2、VP9和H.265等目前没有能够在市场上广泛应用。这些高效的视频编解码技术在提供高压缩率的同时也带来高计算复杂度,它们的编解码过程性能消耗太严重,对硬件要求过高。在手机移动端,目前的手机芯片还不能支持用H.265和VP9的编解码。内容分发网络(CDN)技术和点对点技术(P2P)是为了减少视频传输的带宽成本而被广泛采用的视频传输方案,他们主要工作原理是优化视频传输路径,从而有效管理和分配带宽。这些技术可根据各个时间不同的流量,对带宽进行有效的管理和分配。也就是说,可以根据流量大小,相应地放大缩小带宽,从而提高带宽的有效使用率。在本发明中,我们提出另外一种基于图像超分辨率的视频传输方法,可以跟主流的两种技术方案有效结合,并能够在主流技术的基础上进一步减少带宽成本至少50%以上。此外,在视频直播中,由于播主或者观众的网络限制,在移动终端的播放视频质量和清晰度不高,用户在录制和观看方面的体验较差。因此,如何有效增强直播视频的清晰度也成为另一个需要解决的问题。
经对现有技术的文献检索发现,中国专利公开号CN102726044B,公开日为2016.08.10,专利名称为“使用基于示例的超分辨率的用于视频压缩的数据剪切”。该专利从接收的视频信号提取视频拼块或视频部分,将这些拼块聚类成组,并将代表性拼块装入拼块帧中,形成拼块库并传送到解码器。在解码的时候,利用低分辨率视频部分作为关键字从拼块库中搜索到的拼块来替换这些低分辨率视频部分,并对得到的视频执行后处理。其不足之处是:在视频解码时,降分辨率的视频帧与代表性高分辨率的拼块帧需要一起被发送到接收器,额外增加视频传输的带宽消耗。另外,由于任意低分辨率拼块并不一定能在库中精确地匹配对应的高分辨率拼块,仅仅通过提高恢复的视频的时空平滑度无法达到较好的超分辨效果。专利“一种基于学习的超分辨文档图像复原处理方法”(公开号:CN102750686A,公开日:2012.10.24)也使用了类似的块状匹配技术来实现文档图像的超分辨率复原过程。对比之下,本发明所用的最新深度学习技术能够提供更好的超分辨率重建效果。此外,中国专利公开号CN103167284A,公开日为2013.06.19,专利名称为:一种基于画面超分辨率的视频流传输方法及系统。该专利使用字典学习的方法,传输低分辨率和学习字典,并重建超分辨率图像。其不足之处是:需要传播超完备的字典和低分辨率视频,占用传输的带宽消耗。另外,字典学习是一种线性表示过程,它的超分辨率重建效果比使用基于非线性的深度学习的重建效果会差很多。专利“一种图像超分辨方法”(公开号:CN104992407A,公开日:2015.06.17)也是利用了线性的字典学习实施图像超分辨率重建,与我们的非线性深度学习在技术上完全不同。
另一相关专利是中国专利公开号CN201610303886.6,公开日为2016.09.21,专利名称是:一种面向可穿戴设备的视频直播方法。该专利公开了一种基于视频超分辨率的面向可穿戴设备的视频直播方法,在基本不额外损伤高清视频品质的前提下极大地提升了可穿戴设备的移动视频直播效率。而本发明不仅可以增强视频品质,并且能够有效减少传输带宽。另外,本发明是基于深度学习的视频超分辨重建,能够达到目前最好重建效果,目前以上专利都没有采用这种技术。专利“一种图像超分辨率重建方法”(公开号:CN105976318A,公开日:2016.09.28)使用了深度学习的方法来进行超分辨率重建。此专利的不足之处是深度学习只采用了3层的网络结构,无法充分表达和重建低分辨率图像与高分辨率图像之间的非线性映射关系,得到的重建效果还有待提高。
技术实现要素:
本发明的目的在于克服现有技术的不足,提供一种基于深度学习的视频增强与传输方法。
本发明采用的技术方案是:
一种基于深度学习的视频增强与传输方法,其包括以下步骤:
a)视频源端将采集的高分辨率视频经降采样得到低分辨率的视频,
b)采用编码技术将低分辨率的视频压缩;
c)采用视频传输技术将压缩后的低分辨率的视频传输至用户终端;
d)用户终端接收压缩后的低分辨率的视频并进行解码获得低分辨率的视频;
e)采用基于深度学习的单帧图像超分辨重建技术将低分辨率视频重建并增强成高分辨率视频;
f)用户终端输出并显示高分辨率视频。
进一步地,步骤a)中采用双三线性插值的方法进行降采样。
进一步地,步骤b)中现有的编码技术包括H.264、H.265、AVS2。
进一步地,步骤c)中视频传输技术为CDN传输技术或者P2P传输技术。
进一步地,步骤e)中基于深度学习的单帧图像超分辨重建技术,其包括以下步骤:
1、训练神经网络模型:
1-1,给定低分辨率视频单帧RGB图像和对应的高分辨率视频单帧RGB图像,分别转换到YCbCr空间,利用Y通道进行算法训练,并对Cb和Cr通道采用双三线性插值;将低分辨率的Y通道图像x插值得到高分辨率图像y,并计算残差图像r;所述残差图像r的计算公式为:r=y-x;
1-2,设定神经网络模型为卷积神经网络模型,卷积神经网络模型的卷积层和激活函数均为20层,采用规整化线性单元函数作为激活函数;
1-3,选用图像对(x,r)作为训练集,将图像对(x,r)输入卷积神经网络模型,得到目标函数:
其中,f(w,b,x)为神经网络模型的预测结果,w和b为网络模型参数;
1-4,采用随机梯度下降法求解神经网络模型的参数w和b,在每次迭代过程中,计算预测结果误差并反向传播到卷积神经网络模型,计算梯度并更新卷积神经网络模型的参数;
1-5,基于卷积神经网络模型中各卷积层的模型参数生成低分辨率图像到高分辨率图像的映射关系并完成神经网络模型的训练;
2、基于训练完的神经网络模型将低分辨输入图像重建成高分辨率图像:
2-1,将低分辨图像xtest卷积神经网络模型输入低分辨图像xtest;
2-2,经神经网络模型的20层的卷积层和非线性激活函数的计算获得残差图像rtest,
2-3,重建的高分辨率图像ytest,高分辨率图像ytest的计算公式为:
ytest=xtest+rtest (2)。
进一步地,所述残差图像r表示丢失的高频图像信息,残差图像r包括图像边缘信息和纹理信息。
进一步地,步骤1-4中随机梯度下降法计算梯度时采用学习率为0.01,并用梯度剪切的方法限制计算梯度。
本发明采用以上技术方案,在视频源端把高清视频经过降采样,得到低清视频,然后使用现有的视频编码方式压缩低清视频,再传输压缩后的低清视频。由于降采样和视频编码都会极大地减小视频数据的大小,所需传输的视频流量也会相应减小,从而达到减少带宽成本的作用。在用户接收端,用户只能接受到低清视频,使用深度学习的超分辨图像重建方法把低清视频重建并还原成高分辨率视频,供用户观看。从而有效减少视频传输的带宽成本。本发明进一步公开了基于深度学习的图像超分辨重建方法,该重建方法先训练一个具有20层卷积层和激活函数的神经网络模型,使得学习的深度加深,能够更好的提高超分辨率重建效果。利用低分辨率图像和残差图像来训练该神经网络模型,由于残差图像的稀疏属性,不仅极大的提高了网络模型的训练速度,同时也增强了图像和视频的超分辨率重建效果。本发明提出基于深度学习的单帧图像超分辨重建技术的视频传输方法,能够减少视频传输的带宽成本至少50%,并能够增强直播视频清晰度,提高用户观看体验。
附图说明
以下结合附图和具体实施方式对本发明做进一步详细说明;
图1为现有的视频传输方法的原理示意图;
图2为本发明的一种基于深度学习的视频增强与传输方法的原理示意图;
图3为本发明的一种基于深度学习的视频增强与传输方法的工作流程图;
图4为本发明的一种基于深度学习的视频增强与传输方法的流程图;
图5为本发明所采用的基于深度学习的单帧图像超分辨重建技术的深度学习模型示意图;
图6为本发明所采用的基于深度学习的单帧图像超分辨重建技术的深度学习的流程图;
图7为本发明所采用的基于深度学习的单帧图像超分辨重建技术的重建前的低分辨率图像示意图;
图8为本发明所采用的基于深度学习的单帧图像超分辨重建技术的重建后的高分辨率图像示意图。
具体实施方式
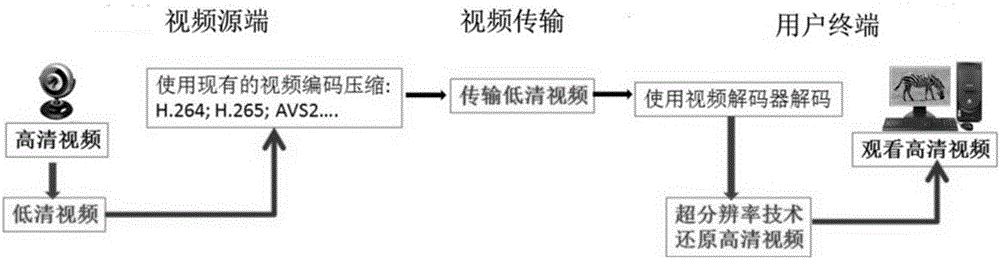
如图1所示,传统的视频传输技术中为了用户高清视频体验,通常采用在视频源端采集高清视频,并在视频传输过程中直接传输高清视频,用户终端使用视频解码器解码接收到高清视频并在终端上显示以供用户观看。
如图2-8之一所示,本发明还公开一种基于深度学习的视频增强与传输方法,视频传输过程中使用低清视频进行传输,用户终端再将低清视频采用基于深度学习的超分辨图像重建技术重建为高清视频并播放,从而能够有效的减少带宽成本,视频传输方法包括以下步骤:
a)视频源端将采集的高分辨率视频经降采样得到低分辨率的视频,进一步地,采用双三线性插值的方法进行降采样。
例如,针对网络直播平台,我们把采集到的高分辨率视频(如1080p),经过降采样降低到低分辨率(如480p),这样需要传输的视频数据是原始视频大小的一半以下。高分辨率(如1080p)的视频会占用直播平台很多的带宽,对主播和观众端的网速要求也特别高。而传输低分辨率(480p)的视频不仅能够有效的减少直播平台的带宽成本,而且对主播和观众的网速要求也会相应降低,这样可以允许观众在网速不好的时候仍然能流畅的观看视频。
b)采用编码技术将低分辨率的视频压缩,进一步减少传输的视频大小;现有的编码技术包括H.264、H.265、AVS2等。
c)采用视频传输技术将压缩后的低分辨率的视频传输至用户终端;
利用现有的视频传输技术(如CDN或者P2P等),合理管理和分配带宽资源,高效地传输压缩后的低分辨率视频至用户终端。
d)用户终端接收压缩后的低分辨率的视频并进行解密获得低分辨率的视频;
e)采用所述一种基于深度学习的单帧图像超分辨重建技术将低分辨率视频重建并增强成高分辨率视频;把接收到的低分辨率视频(如480p)还原成原始的高分辨率视频(如1080p)。
f)用户终端输出并显示高分辨率视频。
进一步地,步骤a)中采用双三线性插值的方法进行降采样。
进一步地,步骤b)中现有的编码技术包括H.264、H.265、AVS2。
进一步地,步骤c)中视频传输技术为CDN传输技术或者P2P传输技术。
进一步地,如图5-8之一所示,步骤e)中基于深度学习的单帧图像超分辨重建技术,其包括以下步骤:
1、训练神经网络模型:利用对应的低分辨率和高分辨率图像,采用图3所示的神经网络模型,训练从低分辨率图像到高分辨率图像的映射,并通过梯度下降法迭代寻找最优的网络模型参数,获得优化的神经网络模型,具体方法如下。
1-1,给定低分辨率视频单帧RGB图像和对应的高分辨率视频单帧RGB图像,分别转换到YCbCr空间,利用Y通道进行算法训练,并对Cb和Cr通道采用双三线性插值,这是由于人眼对Y通道的变化很敏感,而对其他两个通道的变化不太敏感;将低分辨率的Y通道图像x插值得到高分辨率图像y,并计算残差图像r;所述残差图像r的计算公式为:r=y-x;所述残差图像r表示丢失的高频图像信息,残差图像r包括图像边缘信息和纹理信息。残差图像r一般是很稀疏的,也就是说残差图像r中的值有很多接近于零。
1-2,如图5所示,设定神经网络模型为卷积神经网络模型,卷积神经网络模型的卷积层和激活函数均为20层,采用规整化线性单元函数作为激活函数;
1-3,选用图像对(x,r)作为训练集,残差图像r中的值有很多接近于零,选用图像对(x,r)会比(x,y)作为训练集收敛速度要快很多。
将图像对(x,r)输入卷积神经网络模型,得到目标函数:
其中,f(w,b,x)为神经网络模型的预测结果,w和b为网络模型参数;
1-4,采用随机梯度下降法求解神经网络模型的参数w和b,在每次迭代过程中,计算预测结果误差并反向传播到卷积神经网络模型,计算梯度并更新卷积神经网络模型的参数,由于网络结构一共有20层,为了加快训练的收敛速度,我们采用了比较高的学习率0.01,并用梯度剪切的方法防止计算的梯度过大;
1-5,基于卷积神经网络模型中各卷积层的模型参数生成低分辨率图像到高分辨率图像的映射关系并完成神经网络模型的训练;可以获得神经网络模型中各卷积层的参数(wi,bi),i=1,2..,20,即能够得到低分辨率图像到高分辨率图像的映射关系。
2、基于训练完的神经网络模型将低分辨输入图像重建成高分辨率图像:
2-1,将低分辨图像xtest卷积神经网络模型输入低分辨图像xtest;
2-2,经神经网络模型的20层的卷积层和非线性激活函数的计算获得残差图像rtest,
2-3,重建的高分辨率图像ytest,高分辨率图像ytest的计算公式为:
ytest=xtest+rtest (2)。
如图7或图8所示,把图7的低分辨图像经过我们的神经网络模型重建成图8的高分辨率图像,从图7中可以看到重建的高分辨率图像包含了更多的边缘信息和纹理信息,能让观众看到更加清晰的图像,从而获得更好的体验。
本发明采用以上技术方案,在视频源端把高清视频经过降采样,得到低清视频,然后使用现有的视频编码方式压缩低清视频,再传输压缩后的低清视频。由于降采样和视频编码都会极大地减小视频数据的大小,所需传输的视频流量也会相应减小,从而达到减少带宽成本的作用。在用户接收端,用户只能接受到低清视频,使用深度学习的超分辨图像重建方法把低清视频重建并还原成高分辨率视频供用户观看,从而有效减少视频传输的带宽成本。该深度学习的超分辨图像重建方法训练一个具有20层卷积层和激活函数的神经网络模型,使得学习的深度加深,能够更好的提高超分辨率重建效果。利用低分辨率图像和残差图像来训练该神经网络模型,由于残差图像的稀疏属性,不仅极大的提高了网络模型的训练速度,同时也增强了图像和视频的超分辨率重建效果。
本发明所提出的视频传输方法可以很好整合直播平台现有的视频编解码技术(H.264、H.265、AVS2等)和优化的视频传输技术(CDN或者P2P等),而所传输的视频数据量却能够减少至少一半以上,进而能够在现有技术基础上进一步减少视频直播平台的带宽成本至少一半以上。同时,我们的技术不仅帮助直播平台缩减成本,而且对主播和观众的网速要求也至少下降一半以上。这就意味着主播可以更加流畅的上传视频,而观众可以更加流畅的观看高清视频。本发明提出基于深度学习的单帧图像超分辨重建技术的视频传输方法,能够减少视频传输的带宽成本至少50%,并能够增强直播视频清晰度,提高用户观看体验。
- 还没有人留言评论。精彩留言会获得点赞!