一种基于CUDA架构的DNxHDVLC编码方法与流程
本发明涉及一种基于CUDA架构的DNxHD VLC编码方法。
背景技术:
在VC-3/DNxHD标准中,输入视频数据格式为YUV 4:2:2,每个块(block)大小固定为8x8,每个宏块(macroblock,简称MB)分为两部分:由亮度分量的四个块组成的16x16部分和由相应色差分量的四个块组成的16x16部分,也就是每个宏块包含8个8x8的block。
对于分辨率为1920x1080的视频序列的帧编码,每帧有120x68个宏块。虽然标准中没有明确提出Slice的概念,但实际编码中以每行120个宏块构成一个Slice。本发明中所称VLC编码主要指对于8x8块的DCT系数进行编码。
通常情况下用CPU编码实现时会采用slice并行的方式(每个slice中分别对每个宏块中的每个block的8x8个DCT系数依次进行编码,如图1所示),而如果以同样的方式进行CUDA实现,每个CUDA线程处理一个slice,那么这样的方式并行度会非常低。
对于分辨率1920x1080的视频序列,采用slice并行方式,也就是只能使用68个线程并行,而对于一块Tesla K10显卡,每个GPU上最多可并行16384个线程,这样GPU利用率只有0.42%。并且每个线程的运算量非常大,最多需要编码8x8x8x120=61440个系数。
技术实现要素:
本发明的目的在于克服现有技术中的不足而提供一种基于CUDA架构的DNxHD VLC编码方法。
为实现上述目的,一方面,本发明提供的一种基于CUDA架构的DNxHD VLC编码方法,包括如下步骤:
将8x8block的DCT系数进行量化后,加载到共享存储器;
64个线程同步处理一个宏块;
当threadIdx=0,则第0个线程用差分脉冲编码调制对直流系数进行编码;
当threadIdx>0,则第threadIdx个线程计算第threadIdx个交流系数进行VLC编码;
64个线程同步处理一个经编码宏块;
当一个经编码宏块中的8个block计算完成后,保存编码结果,并开始编码下一个宏块。
优选地,第0个线程用差分脉冲编码调制对直流系数进行编码的步骤中,具体为计算当前block与前一个block的直流系数之差,并根据预定义直流系数码表进行编码。
优选地,第threadIdx个线程计算第threadIdx个交流系数进行VLC编码的步骤中,具体为,
当当前交流系数为0,则不计算;
当当前交流系数非零,则检索该交流系数与前一个非零交流系数之间的0的个数,并根据预定义交流系数码表进行编码。
根据本发明提供的一种基于CUDA架构的DNxHD VLC编码方法,对原有算法进行分解优化,细化并行计算的粒度,采用系数级并行方式进行编码,每64个线程编码一个宏块,每个线程每次编码一个直流系数,对于分辨率为1920x1080视频序列而言,需要120x68x64=522240个线程并行,对于一块Tesla K10显卡,这远大于其GPU能够并行的线程数,使得GPU可以满负荷运行,提升了GPU使用效率,从而提高VLC编码速度。
附图说明
图1是Slice级并行编码原理流程示意图;
图2为本发明一实施例的一种基于CUDA架构的DNxHD VLC编码方法的原理示意图。
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
下面详细描述本发明的实施例。
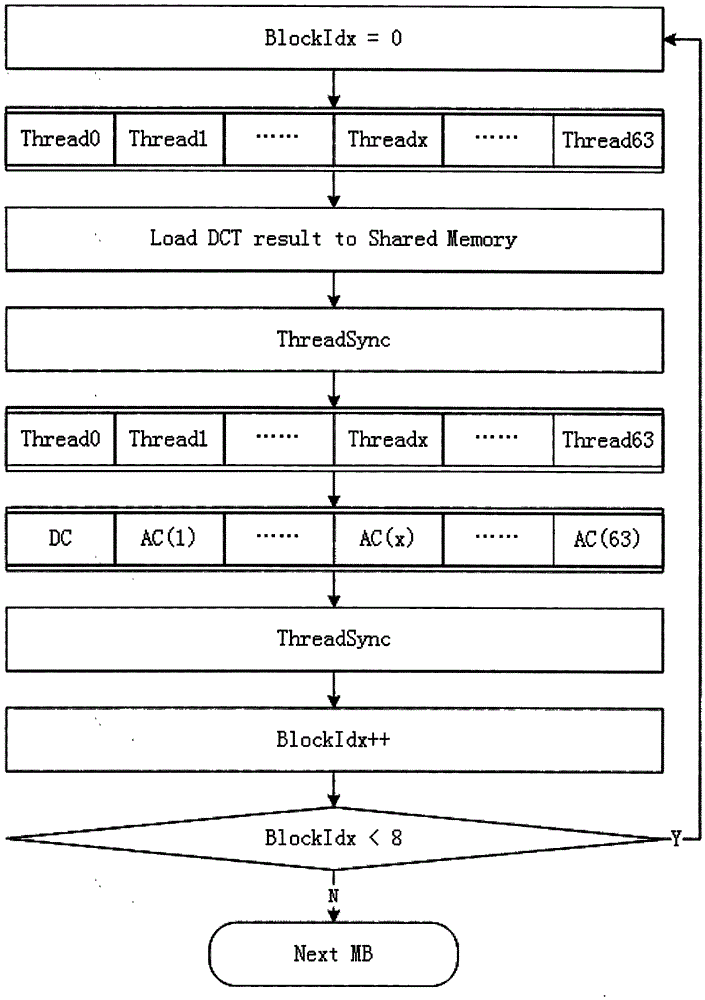
本发明一实施例提供了一种基于CUDA架构的DNxHD VLC编码方法,请参阅图2,具体地,包括如下步骤:
将8x8block的DCT系数进行量化后,加载到共享存储器;
64个线程同步处理一个宏块;
当threadIdx=0,则第0个线程用差分脉冲编码调制(DPCM)对直流系数(DC系数)进行编码;
当threadIdx>0,则第threadIdx个线程计算第threadIdx个交流系数(AC系数)进行VLC编码;
64个线程同步处理一个经编码宏块;
当一个经编码宏块中的8个block计算完成后,保存编码结果,并开始编码下一个宏块。
优选地,第0个线程用差分脉冲编码调制对直流系数进行编码的步骤中,具体为计算当前block与前一个block的直流系数之差,并根据预定义直流系数码表进行编码。
优选地,第threadIdx个线程计算第threadIdx个交流系数进行VLC编码的步骤中,具体为,
当当前交流系数为0,则不计算;
当当前交流系数非零,则检索该交流系数与前一个非零交流系数之间的0的个数,并根据预定义交流系数码表进行编码。
本发明方法充分考虑了CUDA存储器的限制,采用细粒度并行计算,能够充分利用CUDA架构的大规模并行性和高度可扩展性。使用本发明的方法,每64个线程处理一个宏块,每个线程每次编码一个DCT系数,对于分辨率为1920x1080视频序列而言,需要120x68x64=522240个线程并行。这对于一块Tesla K10显卡,已经远远大于其GPU能够并行的线程数,使得GPU可以满负荷运行。以编码DNxHD 1080p 185Mbps文件为例,传统方法只有0.9倍速,而本发明方法能够达到6.3倍速。
综上,根据本发明提供的一种基于CUDA架构的DNxHD VLC编码方法,对原有算法进行分解优化,细化并行计算的粒度,采用系数级并行方式进行编码,提升了GPU使用效率,从而提高VLC编码速度。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在不脱离本发明的原理和宗旨的情况下在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。
- 还没有人留言评论。精彩留言会获得点赞!