一种用于超密集网络系统遍历和速率的近似方法与流程
本发明属于无线通信领域中超密集网络领域,具体涉及一种用于超密集网络系统遍历和速率的近似方法。
背景技术:
:
随着移动互联网以及物联网的快速发展,当前的蜂窝网络已不足以满足人们日益增长的数据流量需求。为了满足人们日益增长的流量需求,第五代移动通信系统(5G)的研发被提上了日程。5G的目标之一是实现系统容量的千倍增长,为实现这一目标,超密集网络的概念被提了出来。超密集网络通过在给定区域大量部署低功率节点大大增加了系统容量,被认为是实现千倍容量增长的关键技术。
不同于传统网络,超密集网络中存在着大量的基站,其中基站的密度达到甚至超过了用户的密度。尽管低功率基站的密集部署可以提升区域吞吐量,但是它也将带来一些挑战。例如:在超密集网络环境中由于网络规模的扩大、基站的不规则部署以及基站用户比的改变,网络优化将变得异常复杂。这就使得基于瞬时信道状态信息的传统方案不再适用。因此,基于统计信道状态信息的解决方案引起了人们的极大关注。在这种情况下,遍历速率就成为了超密集网络的一个重要指标。不幸的是,超密集网络遍历和速率的表达式也很复杂,这就限制了它的应用。现有的近似方法有的忽略了噪声,有的得到了近似的上下界,但是他们都不是在超密集网络的环境中进行的。
在超密集网络中,网络规模的扩大和基站的不规则部署使得网络优化变得异常困难。这就使得基于统计信道状态信息的遍历速率引起了人们的关注,但是其复杂的表达式限制的它的应用。另外,在超密集网络的研究中还没人针对这个问题进行详细的研究。
综上所述,在超密集网络中,遍历和速率近似的研究是很有必要的。
技术实现要素:
:
本发明的目的在于针对上述缺陷和不足,提出了一种用于超密集网络系统遍历和速率的近似方法,该近似方法能够有效的降低遍历速率计算的复杂度。
为达到上述目的,本发明采用如下技术方案来实现:
一种用于超密集网络系统遍历和速率的近似方法,包括以下步骤:
1)根据超密集网络系统模型得到超密集网络的遍历和速率表达式;
2)根据随机几何等数学知识得到超密集网络和速率的近似表达式。
本发明进一步的改进在于,步骤1)包括如下实现步骤:
101)建立系统模型
考虑一个下行的超密集网络,包括N个基站和K个用户,其中基站间全频复用,分别用和表示基站和用户的集合,用k和n表示基站和用户,并假设网络中存在包括基站与用户一对一,一对多和多对一对多种连接方式,假设信道路径损耗因子α>2,小尺度衰落服从均值为1的瑞利分布;
102)计算用户端信干噪比
用户k连接基站n时的信干噪比为:
其中,Pkn和dkn分别是基站n为用户k服务时的发射功率与距离,hkn是基站n与用户k之间的信道系数,同理,Pij是基站j为用户i服务时的发射功率,hkj和dkj是基站j与用户k之间的信道系数和距离,α是路径损耗因子,是接收端高斯白噪声的方差;
103)计算用户端速率
用户k连接基站n时的速率为:
Rkn=log2(1+SINRkn) (2)
104)计算系统和速率为:
105)计算系统遍历和速率为:
本发明进一步的改进在于,步骤2)包括如下实现步骤:
201)等式变换
其中,
202)利用Lyapunov中心极限定理将Xkn和Ykn近似为正态分布
其中,代表正态分布;
203)利用正态分布和Gamma分布的关系,将和近似为Gamma分布
其中
其中,Γ代表Gamma分布,kx,ky和θx,θy分别是EYkn和DYkn的形状参数和尺度参数,EXkn和DXkn分别为Xkn的均值和方差,EYkn和DYkn分别为Ykn的均值和方差,且
204)利用Gamma的特性EXlnX=ψ(k)+ln(θ),得到:
其中ψ(·)是digamma函数;
205)根据digamma的近似表达式得到
其中a∈[0,1]。
本发明具有如下的优点:
与现有技术相比,本发明利用了超密集网络中基站数目众多,干扰严重的特性,因此可以根据Lyapunov中心极限定理将干扰项近似为正态分布,这就使得本发明更适用于超密集网络的环境。其次,本发明根据正态分布和Gamma分布的关系,得出了系统遍历和速率的近似表达式,这大大降低了仿真的复杂度。最后,与其他技术方案不同,本发明的近似方法中考虑了噪声的影响,这就使得本发明在保证高信噪比下良好近似精度的同时,在低信噪比的环境下具有比其他方案更好的近似精度。
附图说明:
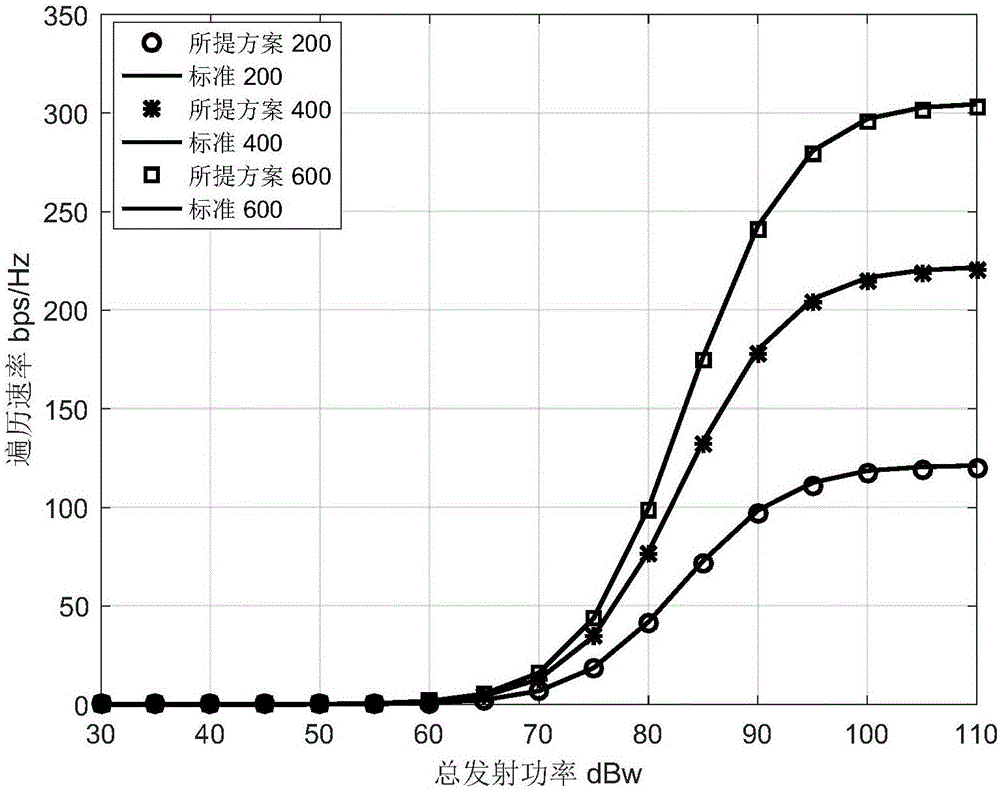
图1是在用户密度分别为200、400、600UE/km3时,本发明与蒙特卡洛仿真的系统遍历速率的性能对比图。
图2给出了用户密度600UE/km3时,本发明与蒙特卡洛仿真的单用户遍历速率的性能对比图。
具体实施方式:
下面结合附图对本发明作进一步详细描述:
本发明提出的用于超密集网络系统遍历和速率的近似方法,包括以下步骤:
第一步,根据系统模型,得到超密集网络的遍历和速率表达式。
考虑一个下行的超密集网络,包括N个基站和K个用户,其中基站间全频复用。为了方便分别用和表示基站和用户的集合,用k和n表示基站和用户。假设网络中存在包括基站与用户一对一,一对多和多对一等多种连接方式。
假设信道路径损耗因子α>2,小尺度衰落服从均值为1的瑞利分布,则用户k连接基站n时的信干噪比为:
其中,Pkn和dkn分别是基站n为用户k服务时的发射功率与距离,hkn是基站n与用户k之间的信道系数。同理,Pij是基站j为用户i服务时的发射功率,hkj和dkj是基站j与用户k之间的信道系数和距离,α是路径损耗因子,是接收端高斯白噪声的方差;从公式(1)可以得到用户k连接基站n时的速率为:
Rkn=log2(1+SINRkn) (2)
从公式(2)可以知道,系统和速率为:
因此,系统遍历和速率为:
第二步,根据随机几何等数学知识得到超密集网络和速率的近似表达式。
为了简便,首先将1+SINRkn表示为
其中,
当基站和用户的位置确定后是一个常数,如果假设Pij也是常数的话,那么Ykn可以被看作是均值和方差都不相同的Gamma随机变量和的形式。虽然它的方差和均值很难得到,但是考虑到超密集网络中庞大的基站和用户的数目,可以采用Lyapunov中心极限定理来处理这个问题。
引理1(Lyapunov中心极限定理):假设是X1,X2,…是一列均值和方差分别为μi和的独立随机变量。定义
如果存在某一δ>0使得Lyapunov条件成立,即满足
那么,当d趋于无穷大时,(Xi-ui)/sn的和将收敛为标准正态分布。
根据引理1,就可以将Xkn和Ykn近似为正态分布,证明如下。
证明:
当δ=1时,公式(7)就可以写成
因此,若此时公式(7)成立,就可以将Xkn和Ykn近似为正态分布。首先,
根据Gamma分布方差和均值的关系,公式(7)就可以变为:
其中,xi=|Xi-ui|。
为了计算首先需要计算出的xi概率密度函数
接着可以计算出
将(13)插入公式(11)中有
综上,问题得证。
因此,可以Ykn将近似为
其中,代表正态分布。
根据正态分布的特性,可以得到
同理,Xkn也可以近似为正态分布,即
此时,可以将遍历和速率写为
其中,Xkn和Ykn都是正态分布随机变量。
在随机几何中,只有Gamma分布可以顺利求解对数期望,因此考虑将正态分布近似为Gamma分布来继续求解。
引理2:当k足够大时,Gamma分布将收敛为均值和方差分别为μ=kθ和σ2=kθ2的正态分布,其中k和θ分别是Gamma分布的形状参数和尺度参数。
根据引理2,可以知道当满足条件:
其中,k足够大,Xkn和都可以近似为Gamma分布,即
其中
其中,Γ代表Gamma分布,kx,ky和θx,θy分别是EYkn和DYkn的形状参数和尺度参数,EXkn和DXkn分别为Xkn的均值和方差,EYkn和DYkn分别为Ykn的均值和方差,且
证明如下。
证明:
考虑到超密集网络的网络规模,可以用极限来计算的形状参数,即:
其中,Amid和Amax分别是Aij的平均值和最大值。
因此,可以近似为Gamma分布,同理也可以近似为Gamma分布。
根据Gamma分布的性质EXlnX=ψ(k)+ln(θ),可以得到:
其中ψ(·)是digamma函数。
由于是函数的形式,为了简化需要对它做进一步的近似,即
其中a∈[0,1]。
综上,可以将遍历和速率近似为:
考虑路径损耗因子α=4,基站高度为20米。假设衰落信道服从均值为1的瑞利衰落。每条曲线仿真10000次信道实现取平均。基站与用户随机部署,它们的密度分别是1000SBS/km3和600UE/km3。最后,取a为0.5。图1给出了用户密度分别为200、400、600UE/km3时,本发明与蒙特卡洛仿真的系统遍历速率的性能对比。可以看出,对于整个系统,本发明提出方法无论在低信噪比还是高信噪比的情况下性能都很接近标准曲线。
图2给出了用户密度600UE/km3时,本发明与蒙特卡洛仿真的单用户遍历速率的性能对比。三个用户随机选出。可以看出,对于单用户,本发明提出方法无论在低信噪比还是高信噪比的情况下性能都很接近标准曲线。
总上,可以看出,本发明中提出的遍历速率近似方法在保证准确性的前提下,大大降低了遍历速率计算的复杂度。
- 还没有人留言评论。精彩留言会获得点赞!