一种Spark数据分析服务发布系统的制作方法
本发明涉及数据分析挖掘技术领域,更具体地,涉及一种Spark数据分析服务发布系统。
背景技术:
随着信息时代的到来,数据的积累成几何倍增长。为了从已有的海量数据中挖掘有效信息,出现了各种不同的数据分析算法。在数据分析的实际操作过程中,无法立即确定最合适的算法,需要通过不断的尝试不同的算法,或者算法组合来获得不同的计算结果。根据对不同的计算结果进行对比,从而获得最佳的算法方案、以及最优的分析结果,以获得最效的数据反馈信息。
数据分析人员需要既懂算法的原理,又要懂算法的具体代码实现。对技术人员要求较高,同时实现不同的算法组合分析数据时候,需要不断调整编码,较为繁琐。当前的互联网已经进入信息数据时代,随着数据的快速增长,公司、科研机构越来越重视从已有的数据中挖掘有效信息,出现了各种不同的数据挖掘体系架构。
在传统业务系统中很少涉及数据挖掘,为了适应大数据的发展,传统的软件公司需要花费很大的时间和代价去构建分析挖掘平台。
技术实现要素:
本发明提供一种克服上述问题或者至少部分地解决上述问题的数据分析服务分配系统,将服务形式统一,合理利用集群资源,通过Spark分布式架构设计,构建便宜使用的大数据分析服务。
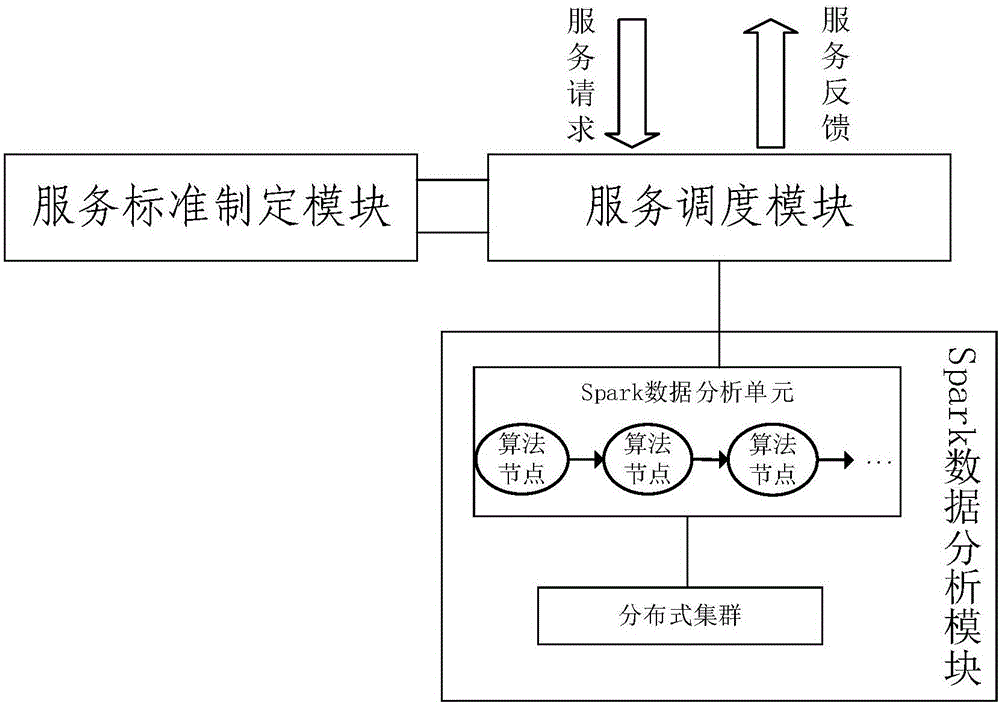
根据本发明的一个方面,提供包括Spark数据分析模块、服务调度模块、服务标准制定模块;所述服务标准制定模块用于制定统一的服务发布标准;所述服务调度模块用于接收服务请求并将服务请求发送到空闲服务;所述Spark数据分析模块用于构建服务容器,根据服务发布标准对服务请求进行分析处理。
作为优选的,用户采用B/S架构通过浏览器查看服务信息、调整服务状态,并设置服务执行形式、服务规模。
作为优选的,所述服务标准制定模块将不同的算法指定统一的服务标准,具体包括服务参数、服务结果组合方式、服务调用模式。
作为优选的,所述服务调度模块还用于将数据分析功能制成开放API的HTTP接口。
作为优选的,所述Spark数据分析模块包括Spark数据分析单元和分布式集群;
所述Spark数据分析单元用于通过Spark分布式计算系统,对分配的服务请求进行分析计算;
所述分布式集群用于为Spark数据分析单元提供分布式计算的运行环境。
作为优选的,所述分布式集群包括Spark集群和Hadoop集群。
作为优选的,所述Spark数据分析单元包括业务子单元和流程发布子单元;
所述业务子单元用于根据服务发布标准,将实现服务请求的算法随机组合绘制成流程图;
所述流程发布子单元用于将流程图的各个节点进行组合,生成任务,并将任务制作成服务,对服务请求进行分析处理。
作为优选的,所述服务调度模块用于通过分布式集群提供的集群资料数据,根据负载均衡-随机算法将服务请求发送到空闲的服务。
作为优选的,所述服务调度模块通过socket与服务进行通信,通信内容包括服务请求数据、服务结果数据、服务状态数据、服务计算进程数据。
本发明提供的一种数据分析服务分配系统,通过制定统一的服务标准,第三方客户或者业务系统通过调用数据分析服务进行大数据分析,能够有效的隔离业务系统与大数据分析,降低业务系统的开发成本;服务的运行环境采用Spark分布式计算系统,大幅度提高数据分析的速度与效率。
附图说明
图1为本发明实施例的数据分析服务分配系统结构框图。
具体实施方式
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
图1示出了一种数据分析服务分配系统,包括Spark数据分析模块、服务调度模块、服务标准制定模块;所述服务标准制定模块用于制定统一的服务发布标准,具体的包括服务生产标准、参数传递标准、结果返回标准,通过这个标准,能够保证服务的统一性,方便用户使用;所述服务调度模块用于接收服务请求将服务请求发送到空闲服务,分配数据分析任务、均衡集群资源、任务周期执行、服务启动与关闭;所述Spark数据分析模块用于构建服务容器,根据服务发布标准对服务请求进行分析处理。服务的运行环境采用Spark分布式计算系统。Spark分布式计算系统是主流的云计算框架之一。采用云计算的方式,大幅度提高数据分析的速度与效率。服务的运行环境采用Spark分布式计算系统,能够实现对算法的不同顺序组合来分析处理数据,分析流程多样化。
在本实施例中,用户采用B/S架构通过浏览器查看服务信息,如服务参数、服务返回值组合形式、服务状态、流程图、服务调用日志等;调整服务状态,并设置服务执行形式,如定时执行、周期执行等;服务规模,如并发数目等。
作为优选的,所述服务标准制定模块将不同的算法指定统一的服务标准,具体包括服务参数、服务结果组合方式、服务调用模式;通过这个标准,能够保证服务的统一性,能够降低用户使用难度,方便用户使用,提高服务的可用性和业务系统代码重用性。
作为优选的,所述Spark数据分析模块包括Spark数据分析单元和分布式集群;
所述Spark数据分析单元用于通过Spark分布式计算系统,对分配的服务请求进行分析计算;
所述分布式集群用于为Spark数据分析单元提供分布式计算的运行环境。
作为优选的,所述分布式集群包括Spark集群和Hadoop集群。
作为优选的,所述Spark数据分析单元还包括业务子单元和流程发布子单元;
所述业务子单元用于根据服务标准,将实现服务请求的算法随机组合绘制成流程图;流程图中包含算法实例节点、以及算法实例节点的关系,算法实例节点的关系通过算法之间的连线来确定。
所述流程发布子单元用于将流程图的各个节点进行组合,生成任务,并将任务制作成服务。
当有服务请求时,服务调度模块通过分布式数据集提供的集群资源数据,根据负载均衡-随机算法将服务请求发送到空闲的服务;服务调度模块记录每一个服务的当前状态,采用随机算法,随机调用后台空闲服务。因为在执行环境相同的情况下,从概率学上面讲,随着请求的增多,每个服务被调用次数大体相同。
作为优选的,所述服务调度模块通过socket与服务进行通信,通信内容包括服务请求数据、服务结果数据、服务状态数据、服务计算进程数据。
本发明提供了一种Spark数据分析服务发布系统,通过将指定统一的服务发布标准,增加服务的广泛应用,减少错误的产生以及服务使用的复杂度,并通过Spark数据分析架构构建数据分析平台以实现分析计算和分析流程,采用云计算的方式,大幅度的提高数据分析的速度与效率;有效隔离业务系统与大数据分析,降低业务系统的开发成本,将数据分析功能制作成开放API的HTTP接口,方便第三方调用。
最后,本申请的方法仅为较佳的实施方案,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!