适用于非对称时延精确时间同步的时钟偏移最优估计算法的制作方法
本发明属于网络测量和控制系统的精密时钟同步领域,涉及时钟偏移估计,具体涉及非对称时延精确时间同步的时钟偏移最优估计算法。
背景技术:
精确时间同步机制以硬件时间戳为基础,使得单跳环境下其精度可达纳秒级,从而实现对从时钟源计时误差的精确补偿,使分布式通信网络能够具有严格的定时同步,并且应用于工业自动化系统。
不同于有线链路,无线链路的传播时延通常具有非对称性,即数据在节点间上下行通信链路中的传播时延差具有不确定性,基于主从节点间的时间偏差主要包括:无线链路的非对称传播时延、中间节点转发的随机队列时延以及从时钟偏移产生的时延,链路非对称传播时延使得主从时钟源间的时间偏差变得更加难以预测。
从时钟本身的偏移主要为其时钟频率及相位影响产生的时间延迟,可基于ieee1588协议双向信息交互机制的非对称时延传输,建立相应含参数的时延向量方程,将时钟偏移的估计问题转化为统计学问题,但目前传统的最小二乘法,极大似然估计等参数估计方法并不适用于该模型下对向量位置参数的估计。
技术实现要素:
有鉴于此,本发明的目的在于提供一种适用于非对称时延精确时间同步的时钟偏移最优估计算法。
为达到上述目的,本发明提供如下技术方案:
适用于非对称时延精确时间同步的时钟偏移最优估计算法,包括以下两个步骤:
(1)通过主从时钟方向及反方向的固定传输时延、传输过程中的随机队列等待时延以及时钟频率偏移产生的时延和时钟相位偏移产生的时延之间的对应关系,建立时延向量方程;
(2)引入高斯分布,并利用pitman估计方法进行估计。
优选的,步骤(1)中是以前p次非对称双向传输为观测样本,从而建立时延向量方程,向量方程建立后,判断向量方程是否是y=aθ+t形式,是则结束,否则需转化为y=aθ+t形式,结束;其中,p为非对称双向传输的次数,为不小于1的正整数。
优选的,步骤(1)具体包括:
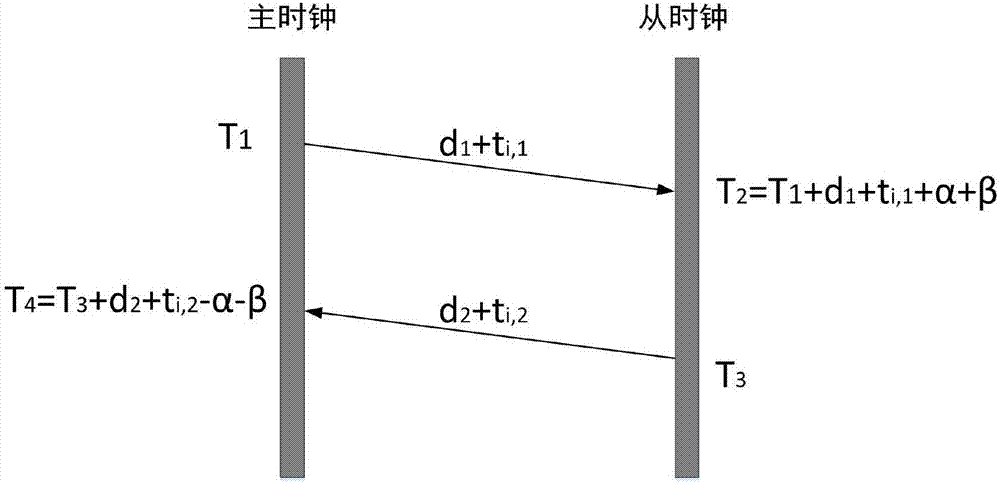
步骤(11):建立以第i次主从时钟方向及其反方向的固定传输时延d1和d2,随机队列时延ti,1和ti,2,以及时钟频率偏移时延α和时钟相位偏移产生时延β所组成的时延关系方程组:
步骤(12):由步骤(11)及反馈补偿,令d=d1,得到时延关系方程组:
步骤(13):令y=[y1t,y2t]t,yk=[y1,k···yp,k]、t=[t1t,t2t]t,tk=[t1,k···tp,k],k=1,2,将步骤(12)中的时延关系方程组转化为以向量y、向量e、向量t及未知参数α、β组成的向量方程:y=d·12p+(α+β)e+t,其中y为非固定传输总时延对应的向量,p为非对称双向传输的次数,为不小于1的正整数,k=1和k=2分别表示第i次的主从时钟及其反方向的传输,y1,k…yp,k分别表示第1次到第p次双向传输过程中主从时钟及其反方向的固定时延、时钟偏移造成时延以及随机队列时延的关系,α、β为未知参数分别代表时钟频率偏移及时钟相位偏移产生的时延,t为随机队列时延对应的向量,12p表示元素为1的2p维列向量,e为所推出向量方程中的一个矩阵,与(α+β)相乘表示一个向量。
进一步优选的,步骤(1)还包括步骤(14),具体方法是:将步骤(13)中的向量方程y=d·12p+(α+β)e+t,进一步转化为向量方程y=aθ+t,其中a表示矩阵
优选的,步骤(2)具体包括:
步骤(21):判断向量方程是否符合向量坐标位置问题模型(vectorlocationparameterproblem),是则进入步骤(21),否则结束;
步骤(22):求出向量方程中未知参数的pitman估计量,进入步骤(23);
步骤(23):转化为对ciθk的pitman最优估计,进入步骤(24);
步骤(24):引入高斯随机队列时延条件,进入步骤(25);vectorlocationparameterproblem):
步骤(25):求得最优估计量g*(y)关于ti,k的表达式,结束;其中,ti,k表示第i次双向传输的随机队列时延,k=1,2。
进一步优选的,步骤(22)的具体方法是:针对时延向量方程y=aθ+t,利用函数g(y)(对线性组合ctθ=α+β进行估计,其中
进一步优选的,步骤(23)的具体方法是:由pitman估计算法,对时延向量方程y=aθ+t中的向量θ所含未知参数进行估计,可得未知参数α与未知参数β之和α+β的最优估计量为:
进一步优选的,步骤(24)的具体方法是:已知第i次传输,主从时钟方向及其反方向随机队列时延ti,1及ti,2均服从均值为μ,方差为σ2的高斯分布,即:
进一步优选的,步骤(25)的具体方法是:已知
其中,步骤(2)包括以下要素:
(2-1)第i次主从方向及其反方向随机队列时延ti,1、ti,2,均服从高斯分布,即:f1(ti,1)、f1(ti,2)~n(μ,σ2);
(2-2)向量方程y=aθ+t,其中y为转移不变量,满足g(y+gh)=g(y)+cth,g为n×m矩阵(g表示一个n乘以m维的矩阵);
(2-3)延迟向量方程y=aθ+t,y服从概率密度函数f(y|θ)=f0(y-aθ),θ含未知参数,且仅改变概率密度函数的位置,而不改变其形状和大小;
(2-4)对向量方程y=aθ+t中向量θ所含未知参数的估计,即对未知参数表示的时钟频率偏移产生的时延α和时钟相位偏移产生的时延β之和α+β的估计;
(2-5)用观测量y对应的函数g(y)对向量θ中的未知参数ctθ进行pitman估计,其最优估计量g*(y)等于对其各分向量ciθk进行估计所得估计量之和,即:
(2-6)随机队列时延向量服从高斯分布的条件及概率密度函数关系
本发明的有益效果在于:
本发明参考统计学中的向量位置参数问题,将pitman估计算法引入向量参数估计范围,从而对基于精确时间同步非对称时延向量方程中的参数进行估计,得到时钟偏移的最优估计量应用于对从时钟计时误差的补偿,从而实现高精度的时间同步。具体的说,本发明将pitman估计算法引入到了向量范畴,同时结合向量位置参数问题及已建立的向量方程,提出一种新的算法;本发明加入了时钟频率偏移时延的考虑,且在通用模型上引入随机时延服从高斯分布的条件进一步进行了推导,实现了对多跳无线网络非对称时延传输过程中的时钟偏移进行了最优估计。
本发明的算法基于精确时间同步的双向信息交互机制,建立了以时钟频率偏移和相位偏移所产生的时间延迟作为未知参数的非对称时延向量方程,并在此基础上引入向量位置参数问题模型,进而基于随机队列时延所服从的高斯分布概率密度函数,运用pitman估计算法对方程中向量所含未知参数进行估计,从而得到时钟偏移的最优估计量。本发明通过对精确时间同步非对称时延向量方程的建立,引入向量位置参数问题模型及pitman估计算法,对高斯随机队列时延下的时钟偏移进行了最优估计,使得估计量的最大均方差值最小化。
附图说明
为了使本发明的目的、技术方案和有益效果更加清楚,本发明提供如下附图进行说明:
图1为本发明的整体框架图;
图2为基于精确时间同步的时延关系图;
图3为时延向量方程实现的流程图;
图4为pitman时钟偏移最优估计算法实现流程图。
具体实施方式
下面将结合附图,对本发明的优选实施例进行详细的描述。
适用于非对称时延精确时间同步的时钟偏移最优估计算法,整体框架图见图1,包括以下两个步骤:
(1)通过主从时钟方向及反方向的固定传输时延、传输过程中的随机队列等待时延以及时钟频率偏移产生的时延和时钟相位偏移产生的时延之间的对应关系,建立时延向量方程;
如图2和图3所示,具体包括:
步骤(11):建立以第i次主从时钟方向及其反方向的固定传输时延d1和d2,随机队列时延ti,1和ti,2,以及时钟频率偏移时延α和时钟相位偏移产生时延β所组成的时延关系方程组:
步骤(12):由步骤(11)及反馈补偿,令d=d1,得到时延关系方程组:
步骤(13):令y=[y1t,y2t]t,yk=[y1,k···yp,k]、t=[t1t,t2t]t,tk=[t1,k···tp,k],k=1,2,将步骤(12)中的时延关系方程组转化为以向量y、向量e、向量t及未知参数α、β组成的向量方程:y=d·12p+(α+β)e+t,其中y为非固定传输总时延对应的向量,p为非对称双向传输的次数,为不小于1的正整数,k=1和k=2分别表示第i次的主从时钟及其反方向的传输,y1,k…yp,k分别表示第1次到第p次双向传输过程中主从时钟及其反方向的固定时延、时钟偏移造成时延以及随机队列时延的关系,α、β为未知参数分别代表时钟频率偏移及时钟相位偏移产生的时延,t为随机队列时延对应的向量,12p表示元素为1的2p维列向量,e为所推出向量方程中的一个矩阵,与(α+β)相乘表示一个向量;
步骤(14):将步骤(13)中的向量方程y=d·12p+(α+β)e+t,进一步转化为向量方程y=aθ+t,其中a表示矩阵
(2)引入高斯分布,并利用pitman估计方法进行估计。
如图4所示,具体包括:
步骤(21):判断向量方程是否符合向量坐标位置问题模型,是则进入步骤(21),否则结束;
步骤(22):针对时延向量方程y=aθ+t,利用函数g(y)(对线性组合ctθ=α+β进行估计,其中
步骤(23):由pitman估计算法,对时延向量方程y=aθ+t中的向量θ所含未知参数进行估计,可得未知参数α与未知参数β之和α+β的最优估计量为:
步骤(24):已知第i次传输,主从时钟方向及其反方向随机队列时延ti,1及ti,2均服从均值为μ,方差为σ2的高斯分布,即:
进一步优选的,步骤(25)的具体方法是:已知
最后说明的是,以上优选实施例仅用以说明本发明的技术方案而非限制,尽管通过上述优选实施例已经对本发明进行了详细的描述,但本领域技术人员应当理解,可以在形式上和细节上对其作出各种各样的改变,而不偏离本发明权利要求书所限定的范围。
- 还没有人留言评论。精彩留言会获得点赞!