一种基于双自适应正则化在线极限学习机的网络入侵检测方法与流程
本发明属于机器学习领域,涉及一种基于双自适应正则化在线极限学习机的网络入侵检测方法。
背景技术:
随着网络技术和网络规模的不断发展,互联网在军事、金融、电子商务等领域得到大规模的应用。越来越多的主机和网络正受到各种网络入侵攻击的威胁,信息安全提升到一个非常重要的地位。网络入侵是指网络攻击者通过非法的手段(如破译口令、电子欺骗等)获得非法的权限,并通过使用这些非法的权限使网络攻击者能对被攻击的主机进行非授权的操作,例如窃取用户的网上银行账号信息等等。网络入侵的主要途径有:破译口令、IP欺骗和DNS欺骗。网络入侵检测技术属于动态安全技术,是信息安全的一个重要研究方向。它被认为是防火墙之后的第二道安全闸门,主动检测内部和外部攻击,保护自己免受网络入侵。随着网络入侵方式的更新换代,网络入侵技术也面临一系列新的挑战。第一点,由于新的网络入侵方式不断产生,网络数据样本集越来越大(即训练数据集不断变大),增大了安全分析的开销,降低了效率,很难满足入侵检测实时性的要求。第二点,网络攻击呈现智能化、复杂化的趋势,检测恶意入侵更加困难。
为了应对这些挑战,基于支持向量机(SVM)、人工神经网络、免疫原理以及聚类分析等人工智能的方法也被用于网络入侵检测技术中。这些算法在一定程度上提高了检测性能,但仍有一些缺点亟待解决,比如:属于批量学习算法,实时性不强、容易陷入局部最优解、训练速度慢等等。在实际的网络环境中,网络数据连续不断的产生,需要一种能实时连续学习且快速训练的方法来进行入侵检测,很多学者对此展开了大量研究。在线惯序极限学习机(OS-ELM)(参考文献:N.Liang,G.Huang,et al.(2006).A fast and accurate online sequential learning algorithm for feedforward networks.Neural Networks IEEE Transactions on,17(6),1411-1423.)属于在线学习算法,继承了传统极限学习机(ELM)训练速度快、检测精度高、泛化性能优等特点,并且能根据连续到达的数据实时的修正和优化训练模型,非常适合网络入侵检测等实时性强的应用。然而OS-ELM同ELM一样基于经验风险最小化,容易发生过拟合以及病态问题。在初始化阶段,其初始训练集大小必须大于或等于隐层单元数,不利于实时的检测网络入侵。因此,要将OS-ELM应用于复杂多变的网络环境,还需要进行更深的研究。
技术实现要素:
本发明是为了解决现有的技术所存在的上述技术问题,提供一种能高效、高速、实时的检测网络入侵的基于双自适应正则化在线极限学习机的网络入侵检测方法。
一种基于双自适应正则化在线极限学习机的网络入侵检测方法,包括以下步骤:
步骤1:利用标准NSL-KDD网络数据训练在线极限学习机分类器;
步骤2:基于已训练好的在线极限学习机分类器,计算待检测的网络数据的隐含层输出矩阵H;
步骤3:按照以下公式对待检测的网络数据进行入侵检测判断,得到入侵检测判断结果
其中,β为已训练好的在线极限学习机分类器中的隐含层和输出层之间的输出权重;
在训练在线极限学习机分类器时,首先对在线极限学习机分类器进行初始化设置:
激励函数设置为hardlim,隐层单元数L至少为1000,初始数据集大小n0至少为50,从训练数据集中随机选取,输入权重Wi和隐层偏置bi为[-1.1]范围内的随机值;
训练数据集为从标准NSL-KDD网络数据随机选取的至少10000个样本;
在线极限学习机分类器中的隐含层和输出层之间的初始输出权重β0按以下公式确定:
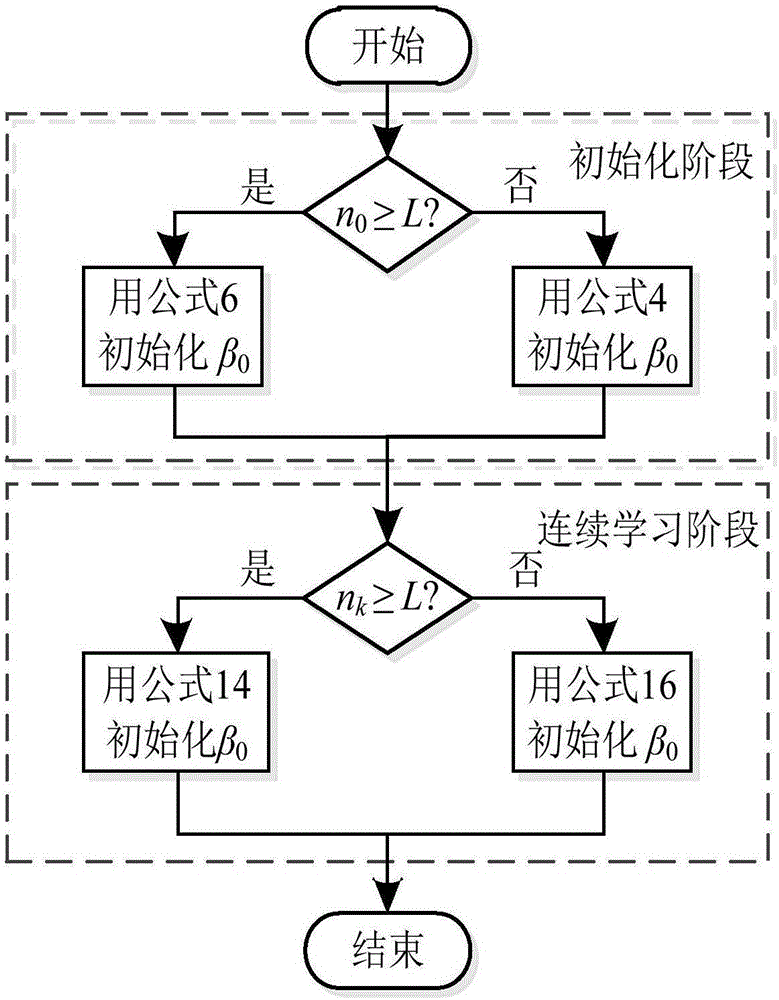
若n0<L,则否则,
其中,
C为脊回归因子,初始值为1e-8,I表示大小为L×L的单位矩阵,大小为,H0表示初始隐层输出矩阵,T0表示训练集n0对应的目标集,U0和K0表示中间变量矩阵。
在线极限学习机分类器在不断的学习过程中,每次用于训练的数据集是从除去已被随机选取后的样本的训练数据集中随机选取获得;
进一步地,在训练在线极限学习机分类器过程中,脊回归因子C按照以下设置进行更新;
首先,设置脊回归因子C的更新间隔时间△P;
其次,按照从第一次训练在线极限学习机分类器开始,每间隔△P次训练,更新一次脊回归因子C。
进一步地,所述脊回归因子C的更新过程如下:
把当前已经训练过的所有训练数据集合并成一个训练集,并依照当前的在线极限学习机分类器计算出合并后的训练集对应的输出矩阵H,采用基于SVD和PRESS的LOO-CV方法计算脊回归因子C的最优值,并自适应更新参数C,具体包括以下几个步骤:
对待检测的网络数据进行入侵检测时,由于网络中的数据为实时增加的,检测过程,同样如同训练过程一样,当产生新的网络数据时,将之前已检测的数据和新产生的数据一起合并后再利用已训练的在线极限学习机分类器进行检测;
步骤A:设置脊回归因子C的候选值[1e-10,1e-8,1e-6,1e-4,1e-2,0,1e,2,1e4,1e6,1e8,1e10];
步骤B:用奇异值分解将输出矩阵H分解为H=UΣVT;
其中,U、Σ及V均表示通过对H进行奇异值分解得到的中间变量矩阵,ΣT表示Σ的转置矩阵;
步骤C:依次计算脊回归因子C每个候选值的对应的预测残差平方和ELOO;
其中,ti和分别表示合并后的训练集中第i个样本的目标值和对应的预测值;hatii表示中间变量矩阵HAT的第i个对角元素值,N表示合并后的训练集中的样本数量;
中间变量矩阵HAT是通过对预测集矩阵进行分解获得:
T表示训练集的入侵检测目标集对应的矩阵;
对角矩阵S:
其中,σii为矩阵Σ的第i个对角元素,当i大于L时σii取值为0;
步骤D:选出最小预测残差平方和ELOO对应的脊回归因子C的候选值作为脊回归因子的当前最优值,更新脊回归因子C。
把合并的训练集的入侵检测预测集的矩阵做如下分解:
HAT表示中间变量矩阵,T表示训练集的入侵检测目标集对应的矩阵;VT、UT、HT分别表示V、U、H的转置矩阵;
进一步地,在训练在线极限学习机分类器过程中,隐含层和输出层之间的初始输出权重按照以下公式计算:
当nk≥L,用中间变量Kk来更新输出权重βk,其中Kk为L×L的矩阵:
其中,K′k-1=Kk-1-Ck-1+Ck;
当nk<L,用中间变量Uk来初始化输出权重βk,其中Uk为nk×nk的矩阵:
其中,U′k-1=(Uk-1-1-Ck-1+Ck)-1;
其中,nk、βk、Kk及Uk分别表示利用第k个合并训练集对在线极限学习机分类器进行第k次训练时所需的隐含层和输出层之间的初始输出权重以及两个中间变量矩阵;
nk表示利用第k个合并训练集的样本大小,k为大于或等于1的整数;
Ck-1和Ck分别表示利用第k-1个和第k个合并训练集对在线极限学习机分类器进行训练时的脊回归因子。
有益效果
本发明公开了一种基于双自适应正则化在线极限学习机的网络入侵检测方法,该方法用带标签的网络数据集训练极限学习机网络,并用该网络进行网络入侵检测。在极限学习机网络初始化阶段,从NSL-KDD网络数据集中随机抽取样本作为初始训练集,随机分配网络输入权重和隐层偏置,并根据初始训练集的大小自适应的初始化输出权重β,在连续学习阶段,根据当前已获取的全部数据集,采用基于奇异值分解(SVD)和预测平方和(PRESS)的留一交叉验证法(LOO-CV)自适应获取C的最优值并更新,然后根据新到达的数据集自适应更新β。在输出权重β的计算过程中,充分权衡经验风险和结构风险,引入基于吉洪诺夫正则化的脊回归因子C。训练好极限学习机网络后,再利用该网络分类待检测的网络数据,即进行网络入侵检测。本发明提出的方法能高效、高速的检测网络入侵,显著的提高网络入侵检测算法的泛化性能和实时性能。
附图说明
图1为极限学习机网络结构示意图;
图2为输出权重β的自适应机制流程图;
图3为本发明带和不带输出权重β的自适应机制的实验结果对比图;
图4为本发明带和不带脊回归因子C的自适应机制的实验结果对比图。
具体实施方式
下面将结合实施例对本发明做进一步的说明。
实施例1:
本实施例分为训练和检测两个部分,训练即用带标签的网络数据集训练极限学习机分类器,检测即用训练好的分类器来检测待检测数据中的网络入侵数据。
通过在NSL-KDD数据集上模拟训练和检测过程来说明本发明的有效性。NSL-KDD数据集是著名的KDD网络数据集的改进版本,该数据集删除了KDD数据集中的冗余数据,因此分类器不会偏向更频繁的数据,并且训练集和测试集的数据比较合理,使得数据集可以被充分利用。而KDD数据集是用于1999年举行的KDDCUP竞赛的网络数据集,虽然年代有些久远,但KDD数据集仍然是网络入侵检测领域的事实基准,为基于计算智能的网络入侵检测研究奠定基础。为了评估本发明的性能,用到的评估参数有:检测精度(ACC)、训练时间(Train Time)、漏检率(FPR)、误检率(FNR)。检测精度越高、训练时间越短、漏检率和误检率越低表示分类器性能越优。
一种基于双自适应正则化在线极限学习机的网络入侵检测方法,包括以下步骤:
步骤1:极限学习机分类器的初始化阶段。极限学习机是目前比较新颖的一种神经网络数学模型,初始化即初始化极限学习机网络的各个参数,为接下来的连续学习阶段做准备。
1.1把原始NSL-KDD数据集中的字符型数据转换为数字型,然后进行规范化和标准化处理。
1.2从处理过的NSL-KDD数据集中选取16000个样本作为训练数据集N,4000个样本作为测试数据集D,一般训练数据集应该选择10000个样本以上,测试数据集大小不作要求,根据实际网络待测数据的多少来决定。
NSL-KDD数据集包含五种类别的数据(NORMAL、PROBING、DOS、R2L、U2R),从该数据集中抽取的训练集N和测试集D中五种类别的数据都是等量的。
1.3选择激励函数‘hardlim’、设置隐层单元数L为1000、脊回归因子C初始值为‘1e-8’、初始数据集大小n0为50。
1.4从训练集N中随机的选择50个样本作为初始训练集N0,其中:
N0={(xi,ti)|i=1,…,50} (1)
xi和ti分别代表n×1的输入向量和m×1的目标向量。
其中n表示的是样本的特征数,比如连接持续类型、协议类型等等,NSL-KDD数据集中每个样本用41个特征表示,即n为41。m表示的是分类器把样本分成的类别,本实施例中样本分为正常和异常两类,即m为2,异常即表示该数据表示的网络连接异常。50个样本为随机选取,不考虑各类数据的比例,因为影响整个分类器性能的是整体训练集,只要整体训练集中各类数据比例相等即可。
1.4在[-1,1]范围内随机分配输入权重Wi和隐层偏置bi,极限学习机的特色就在于这两个参数是随机分配并且不需要迭代调整的,一旦这两个参数设置好,隐层输出矩阵就会被唯一确定。
1.5依据如下公式计算初始隐层输出矩阵H0,其中g(x)为激励函数‘hardlim’,Xi代表n×1的输入向量:
1.6根据no和隐层单元数L的大小关系50<1000,用中间向量U0来初始化输出权重β0,β0是连接隐层和输出层的输出权重,U0是50×50的矩阵:
若no设置为1000及以上,则用中间变量K0来初始化β0,其中:
步骤2:极限学习机分类器的连续学习阶段。
2.2设置需要更新脊回归因子C的步骤的集合P={1,100,200,…}(用户可以自由选择需要更新脊回归因子C的步骤,如果精度要求不是太高,用户可以把更新的步骤间隔设大一些,以此来降低计算复杂度,加快训练速度,更新步骤间隔一般设置为[100,1000]范围内。
2.1将训练数据集N剩下的数据进行分块处理,每块数据集大小均为chunk(本实施例中chunk设为50,实际网络环境中是过一段时间训练一次极限学习机网络,相等的时间段内产生的网络数据集大小不等,因此chunk是不断变化的),然后用分块后的训练数据集依次训练极限学习机网络。当用第k个训练集Nk训练时,用下式计算其对应的隐层输出矩阵Hk:
2.2当k∈P时(k代表当前训练极限学习机网络使用的训练数据集序号,k∈P即代表该训练步骤需要更新脊回归因子C),把当前已经训练过的所有训练数据集合并成一个训练集,并依照公式2计算出其对应的输出矩阵H,采用基于SVD和PRESS的LOO-CV方法计算脊回归因子C的最优值,并自适应更新参数C。
其中,自适应的更新脊回归因子C的具体过程如下:
1)设置参数C的候选值[1e-10,1e-8,1e-6,1e-4,1e-2,0,1e,2,1e4,1e6,1e8,1e10]。
2)用奇异值分解将输出矩阵H分解为H=UΣVT,把预测集的计算过程做如下分解:
3)对C的每个候选值,做如下计算:
a.用如下公式计算中间变量W,其中σii是Σ的第i个对角元素,当i>L时σii=0。
b.用如下公式计算HATi和
c.用如下公式计算预测残差平方和,其中ti代表目标值,代表预测值,hatii代表HAT矩阵的第i个对角元素值:
4)选取k个ELOOi值中的最小值作为参数C的最优值;
2.3类似初始化阶段中β0的计算过程,根据nk(nk为第k个训练集Nk的大小)和L的大小关系自适应的更新输出权重βk,输出权重β的自适应初始化和更新过程如图1所示。
当nk≥L,用中间变量Kk来更新输出权重βk,其中Kk为L×L的矩阵:
其中,K′k-1=Kk-1-Ck-1+Ck;
当nk<L,用中间变量Uk来初始化输出权重βk,其中Uk为nk×nk的矩阵:
其中,U′k-1=(Uk-1-1-Ck-1+Ck)-1;
Ck-1和Ck分别表示利用第k-1个和第k个合并训练集对在线极限学习机分类器进行训练时的脊回归因子。
在线极限学习机是用实时网络环境中不断生成的网络数据去更新极限学习机网络中的输出权重β,从以上的输出权重β更新公式可以看出,β的更新仅仅依赖于新生成的训练集,与之前的训练数据集无关,这样使得该方法能够更加适应实时性很强的网络环境。当极限学习机网络分类器训练好后,只需把待检测的网络数据集放入该极限学习机网络中进行分类,即可判断是否为网络入侵数据。
步骤3:网络入侵检测阶段
步骤1和步骤2训练好了极限学习机网络分类器后,就可以用来检查网络入侵。用测试数据集D来模拟待检测的网络数据集。
3.1对于测试数据集D,用公式2计算其对应的隐层输出矩阵H;
3.2按以下公式计算其对应的预测集进行分类判决,其中β为训练好的极限学习机网络中的输出权重;
3.3比较目标集T和预测集统计检测精度、误检率和漏检率。
步骤4:重新对数据集N进行分块处理,重复步骤1到步骤3,比较数据分块大小(chunk)在范围[20,3000]内时,本发明实施例的网络入侵检测方法的性能,如表1所示。由表知chunk对精度的影响不大,但chunk越小,训练时间越长。因此证明在实际的网络入侵检测中,不同时间段网络数据生成不均匀(即chunk大小不一)不会影响本发明的检测精度,进一步的证明了本发明的实时性良好。
表1不同chunk下本发明方法的性能比较。
步骤5:当chunk在范围[0,1000]内时,重复步骤1到步骤3,但此次初始化和更新输出权重β时不采用自适应机制(β自适应机制即在初始化和在线学习过程中自适应的选择初始化和更新的方式,是我的创新点),仅仅按nk>L情况下的方式进行β的初始化和更新。将此步骤的实验结果与步骤4的实验结果进行比较,如图2所示。本发明的β自适应机制能有效降低计算复杂度,缩短训练时间,提升检测性能。
步骤6:重新获取不同大小的训练集N,重复步骤1到步骤3,模拟现实的网络环境中网络数据集大小不同的情况。当训练集范围为[0,1000]时,比较自适应更新脊回归因子C和不更新C时,本发明网络入侵检测方法的性能,如图3所示。本发明的C自适应更新机制能有效提高检测精度,提升检测性能,更加符合实际网络环境的实时性要求。
步骤7:重新设置隐层单元数L,重复步骤1到步骤3,将本发明方法与基于OS-ELM的网络入侵检测方法性能进行详细比较,如表2所示。本发明相较基于OS-ELM的网络入侵检测方法,有更高的检测精度,更好的泛化性能。另外从表2中也可看出,当训练数据集只有2万左右时,隐层单元数应该设置到[500,1000]之间,训练速度快的同时精度也高。当训练数据集更大或者要求更高的精度的时候,就要设置更多的隐层数,牺牲训练时间来换取精度。
表2本发明与基于OS-ELM的网络入侵检测方法的性能比较
步骤8:将本发明实施例与以下四个方法进行实验比较:BP、SVM、ANN、K-means,实验结果如表3。可以看出,本发明的网络入侵检测方法在训练速度和训练精度方面均大大优于其他方法。同时,本发明属于连续学习方法,其双自适应机制满足了实际网络环境的实时性要求,降低了计算复杂度,提高了泛化性能。
表3本发明与其余四个方法的性能比较
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!