一种基于NetFPGA的VoIP流量实时识别方法与流程
技术领域
本发明涉及网络安全及流量管理领域,具体地,涉及一种基于NetFPGA的VoIP流量实时识别方法。
背景技术:
VoIP由于成本低,应用灵活,易于扩展等特点,自出现以来,发展迅速。目前它的流量已成为互联网流量中不可忽略的一部分,其流量的迅速增长使得传统的网络流量模型受到影响,给网络管理和监控带来了新的挑战。使网络流量的分析、监控和管理变得更加复杂和困难。对其流量进行准确识别,已经成为一个很有价值的研究课题。
其次,任何一种网络业务的准确识别都将为入侵检测提供便利。将网络中大量的合法业务准确的识别出来,有助于入侵检测制定更可靠的合法流量规则集。
最后,VoIP流媒体为信息隐藏提供了更为安全的存在环境,流媒体的瞬时性使得攻击者在流媒体即时传输的过程中难以有足够的时间来检测隐蔽通信的存在。
所以 VoIP 语音流识别具有很强的现实意义,而传统的流量识别方法在准确性、实时性和通用性方面越来越难以到达要求。当前对VoIP 语音流作出准确,可靠的识别是一个富有挑战而亟待解决的问题。在传统的流量识别技术中,数据包提取速度总是受到PCI传输速度的限制,丢包的现象时有发生。主要是因为这种数据包的获取方式是通过LibPcap或者WinPcap中的数据包提取函数实现,所以要实现快速的网络流量识别分类不仅仅是软件技术的问题,也与硬件技术相关。
技术实现要素:
本发明的目的在于,针对上述问题,提出一种基于NetFPGA的VoIP流量实时识别方法,以解决现有技术存在的技术问题。
为实现上述目的,本发明采用的技术方案是:一种基于NetFPGA的VoIP流量实时识别方法,主要包括:
步骤1:配置Net FPGA,然后将Net FPGA构建为网卡模型,基于该网卡模型的框架,扩展VoIP流捕获模块、快速准确识别模块以及流重现和缓存模块,用户数据通过DMA数据传输控制器和PCI控制功能模块与用户主机进行数据交换;
步骤2:利用Libpcap的数据包捕获BPF,实现VoIP的捕获;
步骤3:利用包相似规则并结合DFI技术,实现VoIP流的快速准确识别;
步骤4:采用Hash方式实现VoIP数据表的重现和缓存,适应 Net FPGA 硬件速度。
进一步地,步骤1中,配置Net FPGA包括安装Cent OS操作系统,配置驱动程序,安装工具软件。
进一步地,步骤2 具体包括,数据包到达硬件层的网络适配器后,通过修改网卡驱动,使网卡驱动与内核共享缓冲区,降低对内存数据的拷贝次数;然后Libpcap中的网络分流器将数据拷贝后分配给过滤器,过滤器按照用户设定的过滤规则对报文进行匹配,若匹配成功则放入缓冲区,否则丢弃该报文,最后交付给用户态的应用程序以作进一步分析。
进一步地,步骤3具体包括,将网络探针捕获的UDP流,按照UDP和RTP协议规则匹配,并根据其游程特性进行判断,即连续观察数个RTP包,识别出RTP包流量;结合高速DFI技术,即结合包的长度,上下行流量特征,包时间间隔特征快速确认RTP流。
进一步地,步骤4具体包括,将经过确认的VoIP流按五元组建立哈希索引,即分配一个流ID,放入基于生成的静态哈希表,以流ID对应其哈希表的键值,为每一个流建立一个唯一的表项,每个表项含有流标识、下一表项指针、状态、数据包计数、流队列指针和活动时间,流标识利用五元组用于指明一个唯一的流,下一表项指针指向同一键值的下一个流的表项,每一个流分配一组队列缓存和数据包计数,活动时间用于标识该流最后一个数据包到达的时间,若某个流某个timeout时间后没有新数据到达,则认为该流已经终止,从而释放该表项。
进一步地,所述五元组包括源IP地址、目的IP地址、源端口、目的端口和协议。
进一步地,所述按照UDP和RTP协议规则匹配,包括按照UDP端口号,UDP包的长度域,RTP包的Version规则匹配;
所述UDP端口号用于指明用于双向通信的端口;
所述UDP包的长度域,是负载数据加上UDP包头域的总长度,UDP包头长度为8字节,RTP固定包长度为12字节,RTP包的贡献源标识符,长度为4字节,所述UDP包长度域值大于CC*4+12+8;
所述RTP包的Version域,用于指明当前RTP协议的版本,此域值为2;
进一步地,所述根据包的长度,上下行流量特征,包时间间隔特征快速确认RTP流,具体为根据VoIP数据包的大小是否相同,VoIP的上下行流量分配差距是否很大,包时间间隔是否相对其他网络应用的间隔相对要小。
本发明各实施例的一种基于NetFPGA的VoIP流量实时识别方法,包括:基于NetFPGA的软硬件协同设计,首先构建NetFPGA的网卡模型,在此基础上扩展NetFPGA的硬件设计,使其具有服务于网络流量捕获识别的功能;软件部分以网络数据包捕获函数库libpcap为基础,将软硬件结合,实现对VoIP通信流的实时捕获,快速识别,重现和缓存。
本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
图1为本发明实施例所述的基于NetFPGA的VoIP流量实时识别方法的系统硬件扩展图;
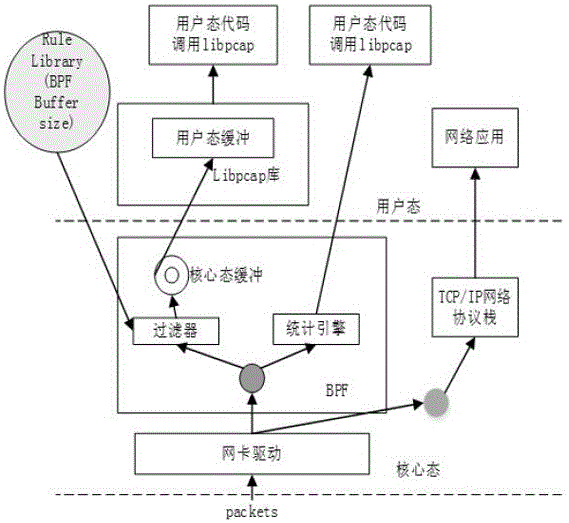
图2为本发明实施例所述的基于NetFPGA的VoIP流量实时识别方法的流量捕获结构图;
图3为本发明实施例所述的基于NetFPGA的VoIP流量实时识别方法的网络截包流程图;
图4为发明实施例所述的基于NetFPGA的VoIP流量实时识别方法的VoIP流快速准确识别流程图。
具体实施方式
以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
具体地,一种基于NetFPGA的VoIP流量实时识别方法,结合附图1-附图4,包括以下步骤:
S1:首先配置 Net FPGA ,即安装Cent OS操作系统,配置驱动程序,安装工具软件。其次将NetFPGA构建为网卡模型,基于此框架,扩展VoIP流捕获模块,快速准确识别模块,流重现和缓存模块,用户数据通过DMA数据传输控制器和PCI控制功能模块与主机交换。其系统硬件扩展如图1所示。
S2:VoIP流捕获实现:采用Libpcap的数据包捕获BPF技术,其系统架构如图2所示。数据包到达硬件层的网络适配器后,通过修改网卡驱动,使网卡驱动与内核共享缓冲区,降低了对内存数据的拷贝次数。然后Libpcap中的网络分流器将数据拷贝后分配给过滤器,过滤器按照用户设定的过滤规则对报文进行匹配,若匹配成功则放入缓冲区,否则丢弃该报文,最后交付给用户态的应用程序以作进一步分析。
进一步:首先开启所要监听的网卡适配器,并检查链路状态和获取网络掩码,其流程如图3所示。然后配置内核过滤器为“ip and udp”,从而,只提交UDP数据包。因为VoIP流主要被封装在 RTP 信息包的 UDP 消息段中。随后,过滤器被植入内核,直接与网络接口通信,不必通过用户层解析数据包,从而高效地过滤掉其他无关的数据包。内核通过一系列回调函数为用户层提供I/O操作,通过这种回调方式,应用层程序便可以访问UDP包的整个以太帧,执行诸如包解析、过滤、分类和缓存等功能。
S3:VoIP流的快速准确识别。将网络探针捕获的UDP流,按照UDP和RTP协议(如UDP端口号,UDP包的长度域,RTP包的Version域等)规则匹配,并根据其游程特性进行判断,即连续观察数个RTP包,识别出RTP包流量;特结合高速DFI技术,即包的长度,上下行流量特征,包时间间隔特征快速确认RTP流。
具体过程是:主要的协议规则匹配依据如下所示。
UDP端口号。UDP端口号用于指明用于双向通信的端口,通常的UDP端口都是偶数端口,其加1的奇数端口通常用于其配套使用的RTCP协议端口。
UDP包的长度域。是负载数据加上UDP包头域的总长度。UDP包头长度为8字节,RTP固定包长度为12字节,RTP包的贡献源标识符(Contributing Source Identifiers, CSRC)长度为4字节。因此,UDP包长度域值必须大于CC*4+12+8。
RTP包的Version域。此域用于指明当前RTP协议的版本,此域值应当为2。
采用包相似性分析规则,即通过对连续多个包的观察,依据多个包的相似性进一步确认RTP包,设置为5个连续数据包,如果都满足所述的匹配和检测,可以判定其为VoIP流。
包相似性分析规则具体是:将通过匹配判断的流按五元组(源IP地址、目的IP地址、源端口、目的端口和协议)进行建立哈希索引,并缓存起来,已确认后续多个包属于同一个VoIP 流。
PT域。载荷类型域(Payload Type)用于指明当前通信的压缩语音编码格式。对于VoIP流,PT域必须是一个定值。
SSRC域。同步源标识符(Synchronization Source Identifier, SSRC)域用于标识此RTP流的来源。每个RTP流都有一个唯一的SSRC,是一个定值。
序列号和时间戳域。在RTP包中,序列号(Sequence Number)被用于标识语音帧的发送顺序。时间戳(Timestamp)用于写入当前包的发送时间。
游程长度。试验后设置为5个连续数据包,如果都满足之前的匹配和游程检测,可以判定其为VoIP流。
利用DFI技术的流量识别方法,更准确的判别VoIP流。
包的长度:
VoIP数据包的大小基本相同。(此处数据包的大小基本相同指的是大小误差在0-100字节围内)
上下行流量特征:
VoIP的上下行流量差异不大,而其他流上下行流量分配差距很大(此处的上下行流量差异不大,没有严格的量化数据,现有中上下流量的判断是根据人为根据整体数据判断)。
包时间间隔特征:
由于网络电话要求实时性较高,其包的间隔相对其他网络应用的间隔相对要小,有着较为明显的分布特征。
S4:将经过确认的VoIP流按五元组(源IP地址、目的IP地址、源端口、目的端口和协议)进行建立哈希索引,即分配一个流ID,放入基于生成的静态哈希表,以流ID对应其哈希表的键值,为每一个流建立一个唯一的表项。每个表项含有流标识、下一表项指针、状态、数据包计数、流队列指针和活动时间。流标识利用五元组用于指明一个唯一的流。下一表项指针指向同一键值的下一个流的表项。每一个流分配一组队列缓存和数据包计数。活动时间用于标识该流最后一个数据包到达的时间,若某个流某个timeout时间后没有新数据到达,便可认为该流已经终止,从而释放该表项。采用 Hash 方式解决VoIP数据表的重现和缓存,适应 Net FPGA 硬件速度的要求
发明基于NetFPGA的软硬件协同设计,首先构建NetFPGA的网卡模型,在此基础上扩展NetFPGA的硬件设计,使其具有服务于网络流量捕获识别的功能;软件部分以网络数据包捕获函数库libpcap为基础,将软硬件结合,实现对VoIP通信流的实时捕获,快速识别,重现和缓存。
软硬件协同,提高效率,不丢包。基于NetFPGA的VoIP流量识别,利用NetFPGA可编程的硬件实现数据包流量信息的提取和搜集,能够保证不丢包,软件部分只处理识别分类工作,保证较高的识别效率。
采用将包相似性分析与流量行为(DFI)特征相结合的方法,不但解决了传统基于主机行为方法无法应对的加密流和基于随机端口号建立的动态会话的识别,同时由于不必访问流量的应用层数据,从而保护了用户数据的隐私性。特别是该算法对VoIP的应用升级或者新的VoIP应用,仍然可以有效地识别其流量。
最后应说明的是:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!