一种联系人数据管理方法及其系统与流程
本发明涉及通信录
技术领域:
,尤其涉及一种联系人数据管理方法及其系统。
背景技术:
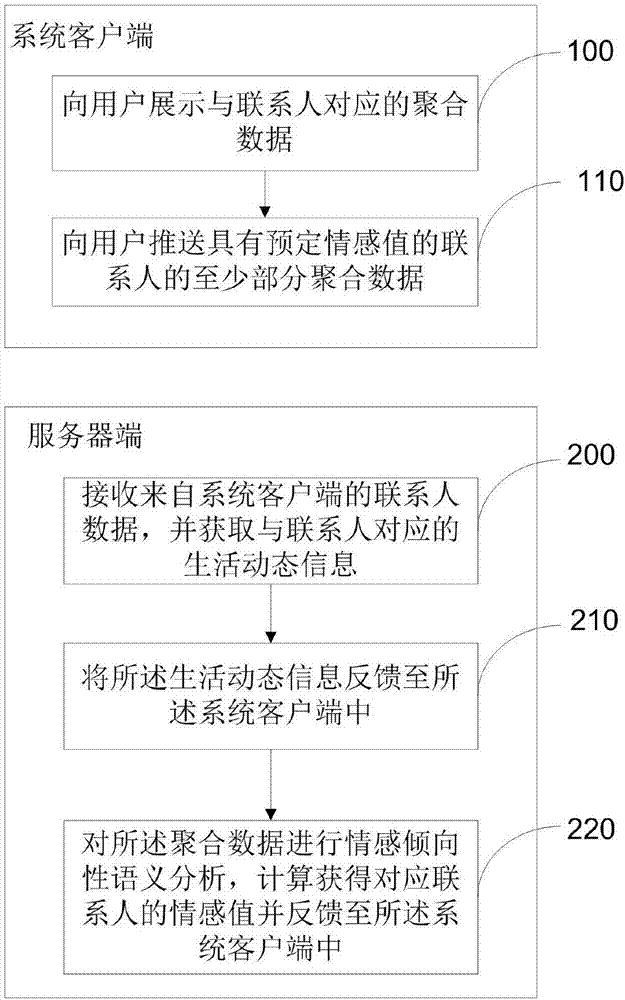
:在现有的移动应用市场中提供的通讯录类应用大多都只是作为一个联系人联系方式的存储工具,只停留在维护和挖掘本地数据阶段。在智能移动终端上安装以后,用户通常能够进行的操作就是对联系人的一些数据进行增加、删除、修改或者检索等简单的操作,例如搜索联系人,查看通话记录,发短信和拨打电话。这样的联系人数据的管理方式较为单一,也无法提供更多可能的信息以满足用户的要求。例如在浏览联系人和拨打电话之前,我们完全无法通过手机通讯录app知悉该联系人的其他细节信息和近期状态。随着机器学习技术的不断发展,应用相关的技术实现的各类型智能化功能,例如推荐引擎等越来越广泛,用户也越来越希望能够获得这样的一些智能功能,提高使用的便捷性。但是,现有的通讯录都只是被动的被用户所使用,智能化程度较低,无法满足用户的使用需求,提高用户的粘合度。因此,现有技术还有待发展。技术实现要素:鉴于上述现有技术的不足之处,本发明的目的在于提供一种联系人数据管理方法及其系统,旨在解决现有技术中通信录应用的智能化程度低,无法满足用户需求的问题。为了达到上述目的,本发明采取了以下技术方案:一种联系人数据管理方法,其中,包括:在系统客户端:a1、向用户展示与联系人对应的聚合数据,所述聚合数据包括:与联系人对应的生活动态信息以及联系人数据;所述联系人数据至少包括联系人,联系人对应的联系方式;a2、向用户推送具有预定情感值的联系人的至少部分聚合数据;在服务器端:b1、接收来自系统客户端的联系人数据,并获取与联系人对应的生活动态信息;b2、将所述生活动态信息反馈至所述系统客户端中;b3、对所述聚合数据进行情感倾向性语义分析,计算获得对应联系人的情感值并反馈至所述系统客户端中。所述的联系人数据管理方法,其中,所述步骤b1具体包括:b11、使用预定的网络爬虫及其页面过滤规则,根据与联系人对应的url数据获取原始数据;b12、将过滤后的原始数据按字段存储在数据库中;b13、每间隔预定的时间,更新所述数据库中的原始数据。所述的联系人数据管理方法,其中,所述方法还包括:在系统客户端:a01、获取用户输入的联系人数据;a02、检查所述联系人数据是否满足预定标准;a03、若否,提醒用户输入完整的联系人数据。所述的联系人数据管理方法,其中,所述步骤a2具体包括:a21、判断联系人的情感值是否在预定范围内;a22、将情感值属于预定范围内的异常联系人以弹窗或者列表置顶显示的方式,向用户展示;a23、向用户推送所述异常联系人的部分聚合数据。所述的联系人数据管理方法,其中,所述方法还包括:在系统客户端,根据联系人的社会关系,相关通话数据,计算所述联系人对应的亲密度;所述步骤b3具体包括:b31、根据所述生活动态信息,分别计算文本情感总值和情绪稳定值;所述文本情感总值用于表示联系人的情感倾向,所述情绪稳定值用于表示所述文本情感总值的变化波动程度b32、将所述亲密度、文本情感总值和情绪稳定值反馈至所述系统客户端中。一种联系人数据管理系统,其中,所述系统包括:系统客户端和服务器端;所述系统客户端包括:展示模块,用于向用户展示与联系人对应的聚合数据,所述聚合数据包括:与联系人对应的生活动态信息以及联系人数据;所述联系人数据至少包括联系人,联系人对应的联系方式;以及推送模块,用于向用户推送具有预定情感值的联系人的至少部分聚合数据;所述服务器端包括:生活动态信息获取模块,用于接收来自系统客户端的联系人数据,并获取与联系人对应的生活动态信息;信息反馈模块,用于将所述生活动态信息反馈至所述系统客户端中;以及情感值计算模块,用于对所述聚合数据进行情感倾向性语义分析,计算获得对应联系人的情感值并反馈至所述系统客户端中。所述的系统,其中,所述生活动态信息获取模块具体用于:使用预定的网络爬虫及其页面过滤规则,根据与联系人对应的url数据获取原始数据;将过滤后的原始数据按字段存储在数据库中;以及每间隔预定的时间,更新所述数据库中的原始数据。所述的系统,其中,所述系统客户端还包括:输入模块,所述输入模块具体用于:获取用户输入的联系人数据;检查所述联系人数据是否满足预定标准;若否,提醒用户输入完整的联系人数据。所述的系统,其中,所述推送模块具体用于:判断联系人的情感值是否在预定范围内;将情感值属于预定范围内的异常联系人以弹窗或者列表置顶显示的方式,向用户展示;向用户推送所述异常联系人的部分聚合数据。所述的系统,其中,所述推送模块具体用于:根据联系人的社会关系,相关通话数据,计算所述联系人对应的亲密度;所述情感值计算模块具体用于:根据所述生活动态信息,分别计算文本情感总值和情绪稳定值;所述文本情感总值用于表示联系人的情感倾向,所述情绪稳定值用于表示所述文本情感总值的变化波动程度。将所述文本情感总值和情绪稳定值反馈至所述系统客户端中。有益效果:本发明提供的联系人数据管理方法及其系统,能够向用户同时展示与联系人相关的生活动态信息,能够提供更多的信息。并且采用特定的计算算法,充分挖掘并利用了网络和本地数据,将联系人的状态进行量化和具象化为情感值,并根据情感值提供相应推荐结果,使得通信录更具智能化特点,提高用户的粘合度。附图说明图1为本发明实施例提供的联系人数据管理方法的方法流程图;图2为本发明实施例提供的通信录移动应用的示意图;图3为本发明实施例提供的联系人数据备份和同步的方法流程图;图4为本发明实施例提供的生活动态信息获取方法的方法流图;图5为本发明实施例提供的通信录移动应用的使用流程图;图6为本发明实施例提供的联系人数据管理系统的功能框图。具体实施方式本发明提供一种联系人数据管理方法及其系统。为使本发明的目的、技术方案及效果更加清楚、明确,以下参照附图并举实施例对本发明进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。如图1所示,为本发明实施例提供的一种联系人数据管理方法。所述联系人数据管理方法基于c/s架构建立,其包括了系统客户端(client)和服务器端(server),在两端分别分配执行一定的功能,并具有各自的数据库,进行维护和数据更新。其中,在系统客户端,可以执行如下步骤:100、向用户展示与联系人对应的聚合数据。所述聚合数据包括:与联系人对应的生活动态信息以及联系人数据;所述联系人数据至少包括联系人,联系人对应的联系方式。所述联系人数据是指现有通信录中通常包含的一些数据项目,例如,联系人名称、联系人的电话、联系人住址,联系人的社交账号等。所述生活动态信息是指与某个联系人相关的,在社交平台或者其他网络平台上发布的,与自己生活动态相关的信息,例如在微博上发布的微博、朋友圈动态等。上述聚合数据具体可以以任何合适的方式在智能终端上展示,例如如图2所示,为本发明实施例提供的一种展示方式,在点击进入通信录的某个联系人名片时,同时显示其在一些社交平台上发布的消息。110、向用户推送具有预定情感值的联系人的至少部分聚合数据。该联系人的情感值由服务器端计算得出。系统客户端根据一些预定的规则,筛选联系人并将一些存在异常情况(例如突然联系频率下降)的联系人向用户提示,保持用户与联系人之间的联系。相对应地,在服务器端可以执行如下方法步骤:200、接收来自系统客户端的联系人数据,并获取与联系人对应的生活动态信息。服务器端接收获得的联系人数据可以存放在服务器端的数据库中,这样可以使通信录具备一定备份功能。根据联系人数据,在用户授权的情况下,服务器端可以通过合适的方式自动的获取到联系人的生活动态信息。210、将所述生活动态信息反馈至所述系统客户端中。反馈信息可以采用合适的数据格式完成,由系统客户端对消息进行解析,然后形成聚合数据向用户展示。220、对所述聚合数据进行情感倾向性语义分析,计算获得对应联系人的情感值并反馈至所述系统客户端中。情感倾向性语义分析是一种机器学习方式,对生活动态信息进行量化,用以判断联系人的情感状态并以情感值的数据来体现。具体可以使用任何合适的方式来完成这样的计算。例如,可以简单的利用由第三方提供api服务,将文本上传后完成情感值计算,也可以使用自定义的情感词典,通过特定的算法来进行情感值计算,评判文本所表达的倾向。当然,上述计算方式是基于文本信息的信息类型完成的。因此,在一些实施例中,还可以对生活动态信息中的图像信息、语音信息等进行转换,转换为文本信息。在本发明实施例中,使用了c/s架构并且进行了合理分配的情况下,有效的减缓了系统客户端网络和计算压力,提高了目标数据的获取速率。并且使用两级数据获取存储策略,降低了对客户端网络的要求和消耗,减少用户智能终端的流量消耗。服务器数据库还可以实现用户群联系人数据的备份和同步,一定程度上保证了联系人数据的完整性和安全性。以下结合实例具体阐述系统客户端和服务器端各自的数据库维护和更新过程:首先,对于服务器端的数据库需要存储所有已上传的联系人基本信息和他们各自对应的三个社交平台的文本动态数据及用户与其联系人之间的映射关系。而系统客户端的数据库需要存储本地联系人的基本信息和他们各自对应的三个平台的文本动态数据。1)用户在系统客户端除了需要存储自己和本地联系人的姓名、电话等基本信息,还可以填写自己和本地联系人已知的社交平台账号信息,具体信息存储表如下表所示:该表中包含了本地联系人的姓名(name)、贴吧id(tiebaid)、贴吧主页url(tiebaurl)、微博id(weiboid)、微博个人主页url(weibourl)、人人网id(renrenid)、人人网个人主页url(renrenurl)、个人近期情感值(emotion_value)、该联系人与用户的亲密度(degree_of_intimacy)等项目。用户在第一次使用客户端应用时,就会生成该联系人信息表,用于记录本地联系人的相关信息。当用户在填写自己的信息时,信息记录会保存至sharepreference文件中。2)在服务器端,数据库记录存储用户们上传的本地联系人和个人相关信息,数据表结构如下表所示:idnametelsourceidtiebaurlweibourlrenrenurlemotion_valueisuser1张三1234567xxxwww.x.comwww.x.comwww.x.com3212李四1245678xxxwww.x.comwww.x.comwww.x.com7703王五7654321xxxwww.x.comwww.x.comwww.x.com870该表中包含了客户端用户上传的本地联系人和自己的相关信息。包括联系人姓名(name)、电话(tel)、唯一识别码(source_id)、贴吧个人主页url(tiebaurl)、微博个人主页url(weibourl)、人人网个人主页url(renrenurl)、情感值(emotion_value)、是否为客户端用户的标识(isuser)。source_id是系统为每个联系人生成的唯一识别码,该识别码是当用户将该联系人首次信息上传时,服务器端根据当前的系统信息生成的uuid。emotion_value是服务器通过对该联系人的社交平台动态进行语义情感分析后得出数据经过相应算法转化后得出的情感值。isuser是用来标识该联系人是否为客户端的使用者,即用户。服务器端数据库还包含一类联系人社交平台动态记录表,该表结构如下表所示:idsourceidtimeaddresstitlecontentimg_urlsocila_platform1xxx2016/10/27www.x.com321tieba2xxx2016/10/27www.x.com770weibo3xxx2016/10/26www.x.com870renren该表用于记录服务器在三个社交平台获取到的各联系人的发言、动态情况,字段包含联系人唯一识别码(source_id)、发表时间(time)、发表地址或设备(address)、发表的主题(title)、发表的文字内容(content)、内容图片的url(img_url)、社交平台的类别(socila_platform)。在一些实施例中,为了保证用户数据的安全和简化用户的操作,还可以利用服务器端的数据库支持用户备份本地联系人数据和联系人数剧同步,其具体方式如图3所示:首先,当用户第一次打开使用系统客户端时,客户端会要求用户先填写自己的个人数据信息,其中电话号码为必填项(s10)。这是为了保证将来用户上传数据到服务器时,服务器能确定用户的唯一身份并能够建立每个用户与其本地联系人的关系映射表。同时应用会将手机中原有的联系人数据进行导入。用户进行联系人添加时,电话信息为必填项。当用户需要对本地数据进行备份时,可以点击主界面的备份按钮。随后客户端会将本地数据以xml文件流的形式通过socket通信上传给服务器端,服务器端接收到数据后,在将每个联系人添加到数据库时,会先检测该联系人信息中是否包含source_id(s20),如果包含,则说明该联系人信息已经在数据库中,如果该联系人是用户(s30),则不修改数据,否则修改(s50)。如果不包含source_id,则服务器为其生成一个source_id,并将该联系人数据保存进数据库(s40)。对于用户自身数据,和上面操作相同。然后服务器会为上传用户建立一个与本地联系人的关系映射表,该表即用户数据备份索引,用户每次上传数据,服务器都会去更新该表信息。对于数据同步:这里的数据同步不仅包含用户的本地联系人的基本信息,还包含每个联系人的社交平台动态信息。同步包括自动同步和手动同步。自动同步是应用会在后台保持一个服务,在网络保持正常连接的情况下,它会定时发送数据同步指令给服务器,服务器接收到指令后,会在数据库中搜索到该用户,根据之前提到的关系映射表获取到所有相关联系人的所有最新信息,并将数据以xml数据流的格式返回给相应客户端,客户端进行格式解析并将数据保存至客户端数据库,手动同步是用户点击主界面上的数据同步按钮,实现和上面一样的功能。在一些实施例中,所述步骤200具体包括:首先,使用预定的网络爬虫及其页面过滤规则,根据与联系人对应的url数据获取原始数据;然后,将过滤后的原始数据按字段存储在数据库中;最后每间隔预定的时间,更新所述数据库中的原始数据。上述数据每次都只保留一个周期的并且每次爬虫抓取完毕后都会检测是否有新动态,每次都只将新动态添加进数据库。所以在每次存放新的周期的数据前,都会将旧数据进行清空,从而避免产生数据冗余。在本实施例中,使用的是网络爬虫来实现对于生活状态信息的获取。如图4所示,为所述网络爬虫的工作流程:首先,提供初始url作为信息抓取的入口网页(步骤310)。然后,该url会被加入到具有特定爬取原则的待抓取url队列中(步骤320),根据所述爬取原则下载相应的url对应的页面(步骤330),并将已抓取页面加入到已抓取队列中(步骤340)。最后,根据爬取策略将已抓取的页面上的新url加入待抓取url队列中(步骤350)。网络爬虫爬行策略包含多种,常使用的有深度优先遍历策略、广度优先遍历策略和反向链接数策略。在本实施例中,使用了深度和广度优先遍历策略。在本实施例中,使用了开源爬虫框架webcollector。在具体项目中导入相关jar包即可,开发者因此只需要提供url和相应的页面过滤规则。当然,由于社交平台的数据私密性,需要提供测试账号进行模拟登陆来到达指定网页,然后根据相应的dom树和标签来爬取指定的页面数据。对于url的选择方式,当用户在系统客户端点击进入一位联系人的信息主页面时,客户端会提取本地数据库中的该联系人的社交账号信息传输到服务器端用于爬虫的初始url。若本地没有该联系人的社交账号信息,服务器端会根据该联系人的source_id或电话号码对服务器数据库进行搜索,查找是否有该联系人的社交账号信息,如果有,则使用服务器数据库中账号信息,否则不进行页面爬取。当爬虫根据过滤规则对页面解析完毕后,服务器端获得数据,并将其按社交平台分类存放。在一些具体实施例中,所述社交平台具体可以包括:百度贴吧、新浪微博以及人人网等。其中,对于百度贴吧,其生活状态信息可以包括:发帖时间、贴吧名、帖子主题、帖子内容、回复对象、回复内容,由于百度贴吧的特殊性,从用户操作频率来看,发帖和回帖都占了很大比例,可以记录联系人发帖和回帖的动态数据。对于新浪微博,其生活状态信息可以包括:发表时间、动态文字内容、动态包含的图片url、该动态的关注度,这里的关注度指的是该动态获得的评论数、获赞数、分享数等等,可以用来衡量该动态对联系人的重要程度。如图5所示,为本发明实施例提供的联系人数据管理方法在通信录移动应用中的使用流程。在初次使用系统客户端的过程中,系统客户端会提示用户输入相关信息,获取用户输入的联系人数据。然后,检查所述联系人数据是否满足预定标准(例如某些必填项目是否完整)。若否,提醒用户输入完整的联系人数据。当然,在后续的新增联系人的过程中,也可以执行上述检查和提醒步骤。当用户需要对本地信息进行备份和同步时,可以通过点击客户端主界面上的功能按钮来下达指令,客户端根据指令,会将其上传数据到服务器,服务器进行解析并进行查找和存储,然后将特定数据返回给客户端,实现了备份和数据同步。当用户需要查看某联系人的具体信息时,点击该联系人项目,即可进入该联系人的具体信息显示界面,例如图2所示,该界面可以包含该联系人的基本信息和三个社交平台的动态信息。当用户进入该界面时,客户端会上传该联系人的社交主页url,当传输到服务器后,该url会作为该联系人的首选url进行数据爬取,如果本地没有该联系人的社交账号信息,服务器会根据该联系人的唯一识别码在数据库中进行查找,如果存在该联系人的账号信息,则使用数据库中该数据。如果数据库中也没有,则不进行数据爬取。当社交平台动态数据获取成功后,服务器会将数据进行存储,并同时以xml字符流的形式返回给客户端,客户端接收到数据后解析,即可在界面上正确显示。另外,服务器会定时提取数据库中所有联系人数据,并进行社交平台数据爬取,获取到数据后,将数据进行格式处理后,利用文本语义情感倾向性分析方法对获取到的文本数据进行情感分析,随后将数据存储并同时返回给客户端,客户端会结合本地数据计算所得的亲密值和返回数据中的情感值来综合分析本地联系人的最新状态,并对数值超过预定范围的联系人以弹窗或者列表置顶显示的方式提醒用户关注。并且会向用户推送联系人中的热门动态(即生活动态信息)。在本发明实施例中,还包括了由服务器端进行的联系人情感度计算以及由系统客户端进行的,向用户推送特定联系人的步骤。现结合具体例子陈述如下:在服务器端,根据生活动态消息计算联系人情感值的方法具体包括:根据所述生活动态信息,分别计算文本情感总值和情绪稳定值;所述文本情感总值用于表示联系人的情感倾向,所述情绪稳定值用于表示所述文本情感总值的变化波动程度。该计算的基础是对于文本的情感倾向性分析。在一些实施例中,为了提高文本分析的准确性,可以使用第三方提供的语义api服务(例如波森中文语义api服务)。其主要是将本地数据转化为json数据格式,通过发送post请求到sentiment_url表示的网址,即完成了数据的上传,随后第三方在线api会自动对上传数据进行语义分析,然后本地通过jsonresponse.getbody().tostring将计算所得结果以字符串形式返回,形式如下:[[0.8297396961046672,0.1702603038953328]]其中第一个值表示该文本是表达正面情绪的概率,第二个值表示该文本是表达负面情绪的概率。两个值的和为1,在此可以使用(正向概率-负向概率)作为该段文本的情感值。这样的情感值波动范围在[-1,1]之间。在另一些实施例中,也可以自行构建情感词典,如使用大连理工大学情感词汇本体作为情感词典构建的模板。将情感分为7大类:“乐”、“好”、“怒”、“哀”、“惧”、“恶”、“惊”。确定七大类情感后,根据词语的情感强度和复杂度在每个大类中继续细分,且每个词在每一类情感下都对应一个用数值标注的极性。在确定了每个词的基本属性值后,对文本进行语法划分。文本语句的划分没有限制,根据语法、意群或者标点符号都可以,差别就在于能否精确划分到词汇,然后将每个词结合构造的情感词典来进行分数计算,在得出每个词的评分后,需要根据词性来确定每个词的分数占语句情感值的权重,最终进行加权运算来得出情感值。在本实施例中,对于每个联系人的最理想情况而言,会有三个社交平台数据。其中,每个平台都有一定量的数据量。因此,一个人的近期情感值时需要综合考虑数据来源的平台属性、动态受关注度、动态发表时间和动态发表频率等多方面因素,其具体的运算过程如下:1)需要使用到的参数如下表所示:2)根据上述表格中的参数,通过如下算式计算最终的情感文本总值w:w=σx=(t,w,r)(p(x)·∑t=(1,2,3)c*(xt)·d(t))对于所述情绪稳定值,其用于表示所述文本情感总值的变化波动程度。可以通过联系人单位周期内在三个社交平台发布的所有文本动态数据的情感分析值计算标准差。考虑到方差在描述一组数据的波动情况具有显著的优势。因此,在选择计算联系人的文本动态情感分析值的标准差来描述联系人的单位周期内的情感波动情况:最后,将所述亲密度、文本情感总值和情绪稳定值作为联系人的情感值反馈至所述系统客户端中。在系统客户端,会根据通话记录等信息计算用户与各个联系人之间的亲密度,然后结合服务器端返回的各联系人的情感值综合判断哪些联系人是用户近期需要去关注的,并主动推送给用户。其中,计算所述联系人对应的亲密度具体可以采用如下方式完成:为了衡量用户与联系人的亲密度,确定用户与联系人之间的社会关系必不可少。因此我们需要用户在添加联系人时,需要为该联系人指定与其的社会关系。在本实施中,设定了五种大类的社会关系,分别是:家人、朋友、同事、普通关系、黑名单。为了体现它们在亲密度值计算上的差别,为之设定在计算上所代表的不同系数值。这里称之为社会属性系数值q1,比如家人(*1)、朋友(*0.95)、同事(*0.9)、普通社会关系(*0.85)、黑名单(*-1)。其中,q1占亲密度总值计算的60%。然后参考客户端本地的通话数据(通话次数和通话时长),对于通话次数,可以设定系数值q2,称之为通话频率系数值。该值的计算方式为:q2=(与特定联系人的单位时间内的通话次数)/(单位时间内的通话总次数),q2占亲密度总值计算的20%。本实施例中,设定的单位时间为一周,通话指的是拨出和接入。对于通话时长,设定系数值q3,称之为通话质量系数值。该值的计算方式为q3=(与特定联系人的单位时间内的通话总时长)/(单位时间内的通话总时长),q3占亲密度总值计算的20%。最后是亲密度w可以通过如下算式计算获得:w=(0.6*10)*q1+(0.2*10)*q2+(0.2*10)*q3其推送方法可以为:首先,判断联系人的情感值是否在预定范围内;然后将情感值属于预定范围内的异常联系人以弹窗或者列表置顶显示的方式,向用户展示;并且向用户推送所述异常联系人的部分聚合数据。在本实施例中,联系人包含了三种不同的数值用以衡量情感。用户可以自由选择按这三种值进行指定排序方式来生成排序列表,比如选择按亲密度从高到低排序,系统会根据数据库中联系人的亲密度值从高到低排序,并且无论选择哪种顺序排序,都会将亲密度超过预定值的联系人进行置顶显示。这种方式自由度较高,当用户有目的的需要查看这方面情况时,可以快速提供给用户所需的结果,让用户做出相应的选择,对有需要进行沟通的联系人做出动作。另外,系统内部对这三个值都设有正常范围界限,可以对这三个值进行综合判断,选择出最需要用户关注的若干联系人。例如,首先需要确定三类数据的参考优先级(情绪稳定值最高,情感值次之,亲密度最后)。然后,系统会先把情绪稳定值超过正常范围的一类人找出,在这类人中找出情感值超过界限较低的一类人,最后在这类人中选择亲密度较低的前若干位来向用户推送。通过这样的方式,既能保证推送内容的有效性,又不至于产生过多数据交给用户处理,让用户反感。在系统客户端分析出最终结果后会立即在系统提示栏或者当用户打开应用时以弹窗的方式向用户推送这些可能出现了状态异常的联系人,用户便可以点击进入他们的个人信息主页进行详细的查看,然后确定是否需要进行电话或短信沟通。本发明实施例还提供了一种联系人数据管理系统。所述系统包括:系统客户端和服务器端。如图6所示,所述系统客户端包括:展示模块100,用于向用户展示与联系人对应的聚合数据,所述聚合数据包括:与联系人对应的生活动态信息以及联系人数据;所述联系人数据至少包括联系人,联系人对应的联系方式;以及推送模块200,用于向用户推送具有预定情感值的联系人的至少部分聚合数据;所述服务器端包括:生活动态信息获取模块300,用于接收来自系统客户端的联系人数据,并获取与联系人对应的生活动态信息;信息反馈模块400,用于将所述生活动态信息反馈至所述系统客户端中;以及情感值计算模块500,用于对所述聚合数据进行情感倾向性语义分析,计算获得对应联系人的情感值并反馈至所述系统客户端中。具体的,所述生活动态信息获取模块具体用于:使用预定的网络爬虫及其页面过滤规则,根据与联系人对应的url数据获取原始数据;将过滤后的原始数据按字段存储在数据库中;以及每间隔预定的时间,更新所述数据库中的原始数据。更具体的,如图6所示,所述系统客户端还包括:输入模块600,所述输入模块具体用于:获取用户输入的联系人数据;检查所述联系人数据是否满足预定标准;若否,提醒用户输入完整的联系人数据。在一些实施例中,所述推送模块具体用于:判断联系人的情感值是否在预定范围内;将情感值属于预定范围内的异常联系人以弹窗或者列表置顶显示的方式,向用户展示;向用户推送所述异常联系人的部分聚合数据。在另一些实施例中,所述推送模块具体用于:根据联系人的社会关系,相关通话数据,计算所述联系人对应的亲密度;所述情感值计算模块具体用于:根据所述生活动态信息,分别计算文本情感总值和情绪稳定值;所述文本情感总值用于表示联系人的情感倾向,所述情绪稳定值用于表示所述文本情感总值的变化波动程度。将所述文本情感总值和情绪稳定值反馈至所述系统客户端中。可以理解的是,对本领域普通技术人员来说,可以根据本发明的技术方案及本发明构思加以等同替换或改变,而所有这些改变或替换都应属于本发明所附的权利要求的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1