一种视频数据的处理方法和装置与流程
本申请涉及多媒体视频信息处理技术领域,尤其涉及一种视频数据的处理方法和装置。
背景技术:
随着网络通讯技术和互联网技术的飞速发展,越来越多的多媒体视频数据应运而生,这些海量的视频数据以丰富的内容给人们的生活带来了巨大的便利。其中有较大部分的视频数据用于在线教育和在线培训,这部分视频数据本身就包含非常丰富的信息量,如视频中存在培训教师演讲的PPT投影内容、用于演示的实验器材、培训教师演讲的语音描述等,这些内容的信息量包含用户所关心的焦点,但是却以复杂编码的方式存在于视频站点之中,目前并没有很精确有效的方法和应用,能让用户快速触达到其所关心的视频内容焦点上。
目前而言,对于多媒体视频的描述信息,主要还是由人工定义的标题、标签、以及视频文件格式、播放时长、分辨率、音频视频码率等视频元数据组成,拥有语义的部分仅限于人工定义的标题、标签、内容简介等。这些描述信息是无法满足用户更精准触达内容的需求。而且,当面对海量视频文件时,人工定义标题、标签等会有标准较为主观和处理效率低下的缺点。
因此,目前急需一种视频数据的处理方法,能够快速和精准地提取海量视频数据,并能够对海量的视频数据进行场景切分和语义化定义,从而提高在各种视频应用场景中用户触达的精准度和效率。
技术实现要素:
有鉴于此,本申请提供一种视频数据的处理方法和装置,能够快速和精准地提取海量视频数据,并能够对海量的视频数据进行场景切分和语义化定义,从而提高在各种视频应用场景中用户触达的精准度和效率。技术方案如下:
基于本申请的一方面,本申请提供一种视频数据的处理方法,包括:
获取待处理的视频元数据;
根据预设的视频转码规则和视频转码参数,对所述视频元数据进行转码处理,获得视频转换信息;所述视频转换信息包括转码后的目标视频文件;
根据预设的提取参数,对所述目标视频文件进行图像采样获得采样图像集合信息,对所述目标视频文件进行音频数据提取、切分,获得音频片段集合信息;
对所述采样图像集合信息进行处理,获得图像文本信息和物品信息;
对所述音频片段集合信息进行处理,获得语音文本信息;
依据所述采样图像集合信息和所述图像文本信息,按照图像相似度计算方法,对所述采样图像集合信息进行聚类分组,获得多个视频场景;
根据所述多个视频场景、物品信息和语音文本信息,生成语义标签和上下文特征信息。
优选地,所述视频元数据包括:视频名称、用户标签和源文件。
优选地,预设的视频转码参数包括:视频解码和编码参数、音频解码和编码参数、转码分辨率参数、存储路径以及文件系统相关参数。
优选地,预设的提取参数包括:图像采样率参数、图像采样分辨率参数、音频提取参数、音频切分率参数、存储路径以及文件系统相关参数。
优选地,所述采样图像集合信息包括:采样图片文件、采样图片对应的视频帧目、采样图片对应的视频播放时间;
所述音频片段集合信息包括:切分音频文件、切分音频对应的视频起始帧目、切分音频对应的视频播放起始时间。
优选地,所述对所述采样图像集合信息进行处理,获得图像文本信息和物品信息包括:
使用光学识别技术逐一对所述采样图像集合信息中,图像所包含的文本信息进行识别、提取,获得图像文本信息;
使用深度学习图像识别技术逐一对所述采样图像集合信息中,图像所包含的特型物品进行识别、提取,获得物品信息。
优选地,所述对所述音频片段集合信息进行处理,获得语音文本信息包括:
使用语音识别技术逐一对所述音频片段集合信息中的人类语音信息进行识别、提取,获得语音文本信息。
优选地,所述依据所述采样图像集合信息和所述图像文本信息,按照图像相似度计算方法,对所述采样图像集合信息进行聚类分组,获得多个视频场景包括:
对所述采样图像集合信息中的图像按固定比率进行缩放,并计算相邻两张图片的汉明距离,获得所述采样图像集合信息进行聚类分组的第一信息参数;
对所述图像文本信息统一编码,并计算相邻图像文本信息的编辑距离,获得所述采样图像集合信息进行聚类分组的第二信息参数;
对所述第一信息参数、所述第二信息参数进行加权合并,并采用线性函数进行拟合,按照斜率的变化规律进行分段,获得多个视频场景。
优选地,所述物品信息包括:特型物品名称、特型物品标签。
优选地,所述根据所述多个视频场景、物品信息和语音文本信息,生成语义标签和上下文特征信息包括:
将特型物品名称和特型物品标签依次进行过滤、聚类和编码,获得包含所述特型物品的图像所在帧目的第一语义标签信息和第一上下文特征信息;
根据所述多个视频场景,逐一合并所述视频场景下所有图像所在帧目的第一语义标签信息和第一上下文特征信息,获得所述视频场景的第一语义信息参数;
对所述语音文本信息进行分词处理,获得多个词组;
依据弃用词库和/或停用词库,对所述词组进行过滤,获得多个拥有语义的词组;
对所述多个拥有语义的词组进行聚类和编码,并从中提取第二语义标签信息和第二上下文特征信息,获得所述视频场景的第二语义信息参数;
逐一融合所述视频场景的第一语义信息参数、第二语义信息参数,获得所述视频场景的语义标签信息和上下文特征信息。
基于本申请的另一方面,本申请提供一种视频数据的处理装置,包括:
视频元数据获取单元,用于获取待处理的视频元数据;
转码处理单元,用于根据预设的视频转码规则和视频转码参数,对所述视频元数据进行转码处理,获得视频转换信息;所述视频转换信息包括转码后的目标视频文件;
图像采样单元,用于根据预设的提取参数,对所述目标视频文件进行图像采样获得采样图像集合信息;
音频数据处理单元,用于根据预设的提取参数,对所述目标视频文件进行音频数据提取、切分,获得音频片段集合信息;
第一信息处理单元,用于对所述采样图像集合信息进行处理,获得图像文本信息和物品信息;
第二信息处理单元,用于对所述音频片段集合信息进行处理,获得语音文本信息;
视频场景确定单元,用于依据所述采样图像集合信息和所述图像文本信息,按照图像相似度计算方法,对所述采样图像集合信息进行聚类分组,获得多个视频场景;
关联单元,用于根据所述多个视频场景、物品信息和语音文本信息,生成语义标签和上下文特征信息。
优选地,所述视频元数据包括:视频名称、用户标签和源文件。
优选地,预设的视频转码参数包括:视频解码和编码参数、音频解码和编码参数、转码分辨率参数、存储路径以及文件系统相关参数。
优选地,预设的提取参数包括:图像采样率参数、图像采样分辨率参数、音频提取参数、音频切分率参数、存储路径以及文件系统相关参数。
优选地,所述采样图像集合信息包括:采样图片文件、采样图片对应的视频帧目、采样图片对应的视频播放时间;
所述音频片段集合信息包括:切分音频文件、切分音频对应的视频起始帧目、切分音频对应的视频播放起始时间。
优选地,所述第一信息处理单元包括:
光学识别处理子单元,用于使用光学识别技术逐一对所述采样图像集合信息中,图像所包含的文本信息进行识别、提取,获得图像文本信息;
深度学习处理子单元,用于使用深度学习图像识别技术逐一对所述采样图像集合信息中,图像所包含的特型物品进行识别、提取,获得物品信息。
优选地,所述第二信息处理单元包括:
语音识别处理子单元,用于使用语音识别技术逐一对所述音频片段集合信息中的人类语音信息进行识别、提取,获得语音文本信息。
优选地,所述视频场景确定单元包括:
第一信息参数确定单元,用于对所述采样图像集合信息中的图像按固定比率进行缩放,并计算相邻两张图片的汉明距离,获得所述采样图像集合信息进行聚类分组的第一信息参数;
第二信息参数确定单元,用于对所述图像文本信息统一编码,并计算相邻图像文本信息的编辑距离,获得所述采样图像集合信息进行聚类分组的第二信息参数;
视频场景确定单元,用于对所述第一信息参数、所述第二信息参数进行加权合并,并采用线性函数进行拟合,按照斜率的变化规律进行分段,获得多个视频场景。
优选地,所述物品信息包括:特型物品名称、特型物品标签。
优选地,所述关联单元包括:
第一处理子单元,用于将特型物品名称和特型物品标签依次进行过滤、聚类和编码,获得包含所述特型物品的图像所在帧目的第一语义标签信息和第一上下文特征信息;
第二处理子单元,用于根据所述多个视频场景,逐一合并所述视频场景下所有图像所在帧目的第一语义标签信息和第一上下文特征信息,获得所述视频场景的第一语义信息参数;
分词处理子单元,用于对所述语音文本信息进行分词处理,获得多个词组;
过滤子单元,用于依据弃用词库和/或停用词库,对所述词组进行过滤,获得多个拥有语义的词组;
第三处理子单元,用于对所述多个拥有语义的词组进行聚类和编码,并从中提取第二语义标签信息和第二上下文特征信息,获得所述视频场景的第二语义信息参数;
第四处理子单元,用于逐一融合所述视频场景的第一语义信息参数、第二语义信息参数,获得所述视频场景的语义标签信息和上下文特征信息。
本申请提供的视频数据的处理方法,获取待处理的视频元数据后,根据预设的视频转码规则和视频转码参数,对所述视频元数据进行转码处理,获得视频转换信息;所述视频转换信息包括转码后的目标视频文件;并根据预设的提取参数,对所述目标视频文件进行图像采样获得采样图像集合信息,对所述目标视频文件进行音频数据提取、切分,获得音频片段集合信息;对所述采样图像集合信息进行处理,获得图像文本信息和物品信息;对所述音频片段集合信息进行处理,获得语音文本信息;依据所述采样图像集合信息和所述图像文本信息,按照图像相似度计算方法,对所述采样图像集合信息进行聚类分组,获得多个视频场景;最后根据所述多个视频场景、物品信息和语音文本信息,生成语义标签和上下文特征信息。本申请可以自动有效地实现对海量视频数据的场景切分,并对视频数据场景关联上语义的功能,弥补了现有技术中需要对视频数据采用人工标注的方式或只适用于单一场景等模式识别方式的处理过程主观、处理效率低下、无法涵盖整个视频过程等众多缺陷。采用本申请提供的技术方案,可以自动且高效而精准地对海量视频数据进行场景切分和语义关联,提高了用户触达视频数据的精准度和效率。
附图说明
为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
图1为本申请提供的一种视频数据的处理方法的流程图;
图2为本申请提供的一种视频数据的处理装置的结构示意图。
具体实施方式
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
请参阅图1,其示出了本申请提供的一种视频数据的处理方法的流程图,包括:
步骤101,获取待处理的视频元数据。
本实施例中,视频元数据包括视频名称uname、用户标签utag、源文件src_file等,具体例如,教学视频的名称、用户主动填充的关联知识点标签、以及源文件MD5值和存储路径。在本申请实际应用过程中,视频元数据信息还可以包括其他参数,例如语言种类、视频种类等类型参数,由用户主动填充的关于视频内容的简单语义标签等。
进一步可选的,本申请中的视频元数据可以用于视频后续的处理流程,视频元数据中用户UGC(User Generated Content,指用户原创内容)的语义标签可以在机器自动生成语义标签的过程中构建机器学习的样本集合。
步骤102,根据预设的视频转码规则和视频转码参数,对所述视频元数据进行转码处理,获得视频转换信息;所述视频转换信息包括转码后的目标视频文件。
可选的,所述视频转换信息还可以包括转码后的目标视频信息。
其中,转码后的目标视频文件可用于直接点播播放,也会应用于后文涉及的提取关键帧、提取音频段等流程上。转码后的目标视频信息是指,在转码过程中产生的中间信息,如转码后的目标视频文件的大小、时长、码率(影响播放参数、影响提取关键帧、音频段的参数)等。
预设的视频转码参数可以包括:视频解码和编码参数、音频解码和编码参数、转码分辨率参数、存储路径以及文件系统相关参数。
具体在本实施例中,根据预设的视频转码规则和视频转码参数,对教学视频的名称uname、用户标签utag、源文件src_file进行转码处理,获取教学视频的视频转换信息trans_info。在转码处理完成之后,还可以获得目标视频MD5值和存储路径、文件大小、播放时长、封面截图等参数。
步骤103,根据预设的提取参数,对所述目标视频文件进行图像采样获得采样图像集合信息,对所述目标视频文件进行音频数据提取、切分,获得音频片段集合信息。
其中,预设的提取参数包括:图像采样率参数、图像采样分辨率参数、音频提取参数、音频切分率参数、存储路径以及文件系统相关参数;采样图像集合信息包括:采样图片文件、采样图片对应的视频帧目、采样图片对应的视频播放时间;音频片段集合信息包括:切分音频文件、切分音频对应的视频起始帧目、切分音频对应的视频播放起始时间。
本实施例中,根据预设的提取参数,对教学视频的视频转换信息trans_info进行图像采样,获得采样图像集合信息image_set,对教学视频的视频转换信息trans_info进行音频数据提取和切分,获得音频片段集合信息audio_set。本实施例中,预设的提取参数包括图像采样率参数、图像采样分辨率参数、图像存储模式、音频提取参数、音频切分率参数、音频存储模式等。在进行图像采样和音频数据提取、切分之后,本申请还可以获得附带采样帧目、当前播放时间、图像分辨率的多张图像集合,以及特定码率、声道数目的多个音频集合。
具体的,本申请中进行图像采样可以表示为:Y=DownSample(X,n),n为采用时间。具体例如本实施例中,教学视频按照每秒5张240x240分辨率的图像进行采样,上述表达式中n=0.2。
本申请中进行音频数据提取、切分可以表示为:Y=FullSplit(X,m),m为分段时间。具体例如本实施例中,音频以单声道、8k码率的amr格式标准进行提取,提取完成之后按照每60s切分分离的amr音频,上述表达式中m=60。
如此,本申请可以获得待处理的采样图像集合信息image_set和音频片段集合信息audio_set。
步骤104,对所述采样图像集合信息进行处理,获得图像文本信息和物品信息。
其中,所述物品信息包括:特型物品名称、特型物品标签,还可以包括特型物品位置。
具体的,本申请步骤104包括:
步骤1041,使用光学识别技术逐一对所述采样图像集合信息中,图像所包含的文本信息进行识别、提取,获得图像文本信息。
步骤1042,使用深度学习图像识别技术逐一对所述采样图像集合信息中,图像所包含的特型物品进行识别、提取,获得物品信息。
需要说明的是,本申请对于步骤1041和步骤1042的执行顺序不做限定,本申请还可以为先执行步骤1042,再执行步骤1041,也可以为步骤1041和步骤1042同时执行。
本实施例中,对于采样图像集合信息中包含文本信息的图像,逐一使用光学识别技术(Optical Character Recognition,OCR)实现其图像上的文本信息的识别、提取,获得图像文本信息。对于采样图像集合信息中包含特型物品的图像,逐一使用深度学习图像识别技术实现其图像上的特型物品的识别、提取,获得物品信息。
步骤105,对所述音频片段集合信息进行处理,获得语音文本信息。
具体地在本实施例中,使用语音识别技术逐一对所述音频片段集合信息中的人类语音信息进行识别、提取,获得语音文本信息。
本申请上述步骤104和步骤105可以表示为:Y=RecogniztionService(X),其中,输入X为请求对象,输出Y为响应对象。
对于OCR识别技术,请求对象包括待识别图像、图像相关参数、召回参数,响应对象包括提取的光学文本信息ocr_content(即图像文本信息);对于深度学习图像识别技术,请求对象包括待识别图像、图像相关参数、召回参数,响应对象包括提取的特型物品文本信息vgg_content(即物品信息);对于语音识别技术,请求对象包括待识别音频片段、音频相关参数、召回参数,响应对象包括提取的语音对应文本信息hmm_content(即语音文本信息)。
本申请将采样图像集合信息image_set中的所有采样图像逐一进行OCR识别技术和深度学习图像识别技术处理,获得每张采样图像对应的光学文本信息ocr_content和特型物品文本信息vgg_content,依据获得的每张采样图像对应的ocr_content和vgg_content,最终获得采样图像集合信息image_set对应的ocr_content_set和vgg_content_set。
步骤106,依据所述采样图像集合信息和所述图像文本信息,按照图像相似度计算方法,对所述采样图像集合信息进行聚类分组,获得多个视频场景。
本申请根据所述采样图像集合信息及其对应的图像文本信息,按照图像相似度计算,辅助以文本相似度计算,对所述采样图像集合信息进行聚类分组,将视频切分为多个包含起始帧和结束帧的视频场景。具体的,本申请步骤106可以采用如下方法实现:
步骤1061,对所述采样图像集合信息中的图像按固定比率进行缩放,并计算相邻两张图片的汉明距离(haming_distance),获得所述采样图像集合信息进行聚类分组的第一信息参数。
步骤1062,对所述图像文本信息统一编码,并计算相邻图像文本信息的编辑距离(levenshtein_distance),获得所述采样图像集合信息进行聚类分组的第二信息参数。
本申请中的第一信息参数和第二信息参数均为一维相同列数矩阵。
步骤1063,对所述第一信息参数、所述第二信息参数进行加权合并,并采用线性函数进行拟合,按照斜率的变化规律进行分段,获得多个视频场景。
本实施例中,第一信息参数由采样图像集合信息image_set计算得到,第二信息参数由采样图像集合信息对应的光学文本信息ocr_content_set计算得到。
具体在本申请实际应用过程中,对采样图像集合信息image_set中的采样图像压缩成8x8分辨率,进而按照采样顺序,逐一比较相邻两张图片的汉明距离,同时提取相邻两张图片的光学文本信息,比较其编辑距离。如果相邻两张图片的汉明距离和编辑距离加权求和之后不大于预设阈值T,则将对应的两张图片进行聚合,如此迭代至完成整个采样图像集合的比较,获取采样图像集合的若干图像分组image_group。
本申请中涉及的计算规则可以表示为:
(1)Hi=hamin g(Xi,Xi+1),Li=levenshtein(Xi,Xi+1),Di=AHi+BLi;
(2)Group(Xi,Xi+1)={1,当Di≤T|0,当Di〉T};
(3)VGi=[i,j],当Di-1〉T﹠Dj〉T;
其中,Hi为第i张图和相邻第i+1张图的汉明距离,Li为第i张图和相邻第i+1张图的OCR编辑距离,Di为第i张图和相邻第i+1张图的加权距离。当Di不大于预设阈值T时,第i张图和相邻第i+1张图可以聚合成一组,反之则重新分配新组。
本申请获得视频场景分组的具体信息如下:
(4)from_frame(VGi)=i,to_frame(VGi)=j,当Di-1〉T﹠Dj〉T;
(5)from_time(VGi)=i*n,to_time(VGi)=j*n,n为采样时间,当Di-1〉T﹠Dj〉T。
步骤107,根据所述多个视频场景、物品信息和语音文本信息,生成语义标签和上下文特征信息。
具体的,本申请步骤107可以采样如下方法实现:
步骤1071,将特型物品名称和特型物品标签依次进行过滤、聚类和编码,获得包含所述特型物品的图像所在帧目的第一语义标签信息和第一上下文特征信息。
步骤1072,根据所述多个视频场景,逐一合并所述视频场景下所有图像所在帧目的第一语义标签信息和第一上下文特征信息,获得所述视频场景的第一语义信息参数。
步骤1073,对所述语音文本信息进行分词处理,获得多个词组。
步骤1074,依据弃用词库和/或停用词库,对所述词组进行过滤,获得多个拥有语义的词组。
步骤1075,对所述多个拥有语义的词组进行聚类和编码,并从中提取第二语义标签信息和第二上下文特征信息,获得所述视频场景的第二语义信息参数。
步骤1076,逐一融合所述视频场景的第一语义信息参数、第二语义信息参数,获得所述视频场景的语义标签信息和上下文特征信息。
本申请通过获得所述视频场景的语义标签信息和上下文特征信息,从而实现所述视频场景和语义的关联,获得所述视频有语义关联的各个视频场景。
需要说明的是,本申请上述实现获取视频场景的第一语义信息参数的步骤1071-步骤1072与实现获取视频场景的第二语义信息参数的步骤1073-步骤1075间的执行顺序不做限定,本申请也可先执行步骤1073-步骤1075,再执行步骤1071-步骤1072,或步骤1071-步骤1072与步骤1073-步骤1075同时执行。
在本申请实施例中,根据多个视频场景、特型物品信息vgg_content和语音文本信息hmm_content提取场景语义信息。
(6)Tag(VGi)=Category(i,j)。
具体的,本申请中特型物品信息vgg_content包括物品具体类别名称、物品在图像中位置等参数,语义标签可以简单的由物品类别名称指代;如果包含多个特型物品,则根据位置,面积以及物品出现频率加权获得最有代表性的物品名称。语音文本信息hmm_content则通过分词和词性过滤,获取指代的语义标签,具体实施规则如下:
(7)Wall=WordSegment(hmm_content);
(8)Wreal=TagFilter(Wall,S,D),S、D分别为停用词和弃用词集合;
(9)
获得视频场景和语义的关联:
(10))
应用本申请提供的视频数据的处理方法,可以准确地对视频数据中的视频场景进行切分,并提取视频场景中光学文本信息、特型物品信息、视频场景对应的语音文本信息,进而对提取的信息进行处理,得到和视频场景关联的语音信息。处理过程可以采用流水线式作业方式,从而保证处理过程的快速高效和可控制性;提取的视频场景和场景语义,能在视频应用场合下提供用户更精确的信息。因此,采用本申请提供的视频数据处理方法,可以自动且高效精准地对海量视频数据进行场景切分和语义关联,从而增加用户触达视频内容的精准度和效率。
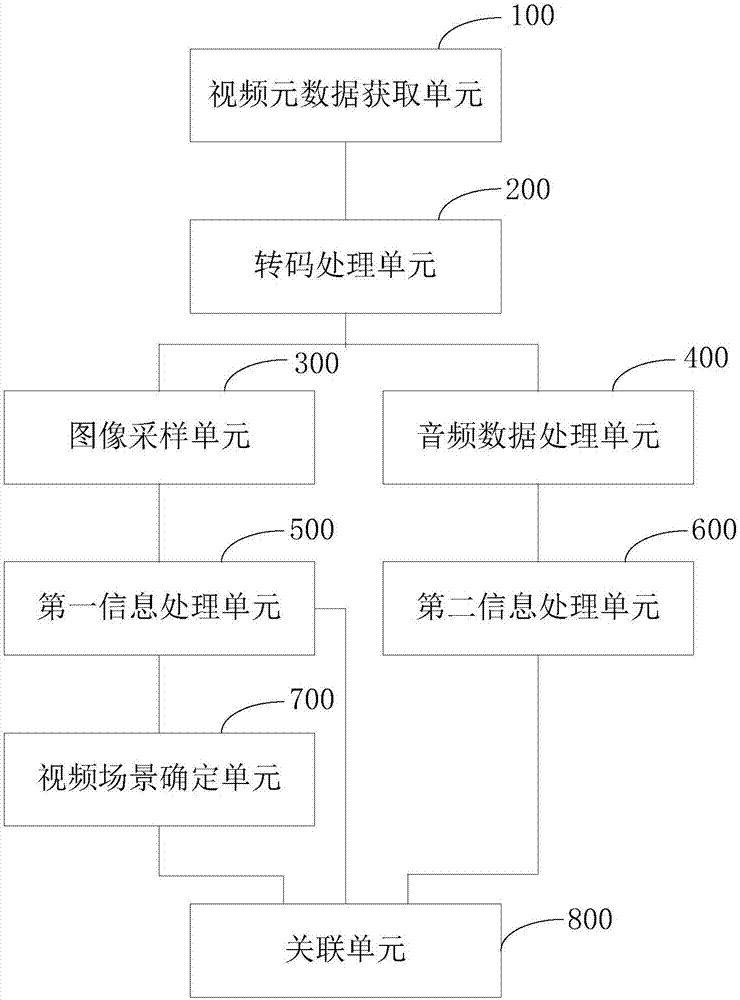
基于前文本申请提供的一种视频数据的处理方法,本申请还提供一种视频数据的处理装置,如图2所示,包括:
视频元数据获取单元100,用于获取待处理的视频元数据;
转码处理单元200,用于根据预设的视频转码规则和视频转码参数,对所述视频元数据进行转码处理,获得视频转换信息;所述视频转换信息包括转码后的目标视频文件;
图像采样单元300,用于根据预设的提取参数,对所述目标视频文件进行图像采样获得采样图像集合信息;
音频数据处理单元400,用于根据预设的提取参数,对所述目标视频文件进行音频数据提取、切分,获得音频片段集合信息;
第一信息处理单元500,用于对所述采样图像集合信息进行处理,获得图像文本信息和物品信息;
第二信息处理单元600,用于对所述音频片段集合信息进行处理,获得语音文本信息;
视频场景确定单元700,用于依据所述采样图像集合信息和所述图像文本信息,按照图像相似度计算方法,对所述采样图像集合信息进行聚类分组,获得多个视频场景;
关联单元800,用于根据所述多个视频场景、物品信息和语音文本信息,生成语义标签和上下文特征信息。
其中,所述视频元数据包括:视频名称、用户标签和源文件。
预设的视频转码参数包括:视频解码和编码参数、音频解码和编码参数、转码分辨率参数、存储路径以及文件系统相关参数。
预设的提取参数包括:图像采样率参数、图像采样分辨率参数、音频提取参数、音频切分率参数、存储路径以及文件系统相关参数。
采样图像集合信息包括:采样图片文件、采样图片对应的视频帧目、采样图片对应的视频播放时间;
音频片段集合信息包括:切分音频文件、切分音频对应的视频起始帧目、切分音频对应的视频播放起始时间。
具体的,第一信息处理单元500包括:
光学识别处理子单元501,用于使用光学识别技术逐一对所述采样图像集合信息中,图像所包含的文本信息进行识别、提取,获得图像文本信息;
深度学习处理子单元502,用于使用深度学习图像识别技术逐一对所述采样图像集合信息中,图像所包含的特型物品进行识别、提取,获得物品信息。
第二信息处理单元600包括:
语音识别处理子单元601,用于使用语音识别技术逐一对所述音频片段集合信息中的人类语音信息进行识别、提取,获得语音文本信息。
视频场景确定单元700包括:
第一信息参数确定单元701,用于对所述采样图像集合信息中的图像按固定比率进行缩放,并计算相邻两张图片的汉明距离,获得所述采样图像集合信息进行聚类分组的第一信息参数;
第二信息参数确定单元702,用于对所述图像文本信息统一编码,并计算相邻图像文本信息的编辑距离,获得所述采样图像集合信息进行聚类分组的第二信息参数;
视频场景确定单元703,用于对所述第一信息参数、所述第二信息参数进行加权合并,并采用线性函数进行拟合,按照斜率的变化规律进行分段,获得多个视频场景。
本申请中,物品信息包括:特型物品名称、特型物品标签。
所述关联单元800包括:
第一处理子单元801,用于将特型物品名称和特型物品标签依次进行过滤、聚类和编码,获得包含所述特型物品的图像所在帧目的第一语义标签信息和第一上下文特征信息;
第二处理子单元802,用于根据所述多个视频场景,逐一合并所述视频场景下所有图像所在帧目的第一语义标签信息和第一上下文特征信息,获得所述视频场景的第一语义信息参数;
分词处理子单元803,用于对所述语音文本信息进行分词处理,获得多个词组;
过滤子单元804,用于依据弃用词库和/或停用词库,对所述词组进行过滤,获得多个拥有语义的词组;
第三处理子单元805,用于对所述多个拥有语义的词组进行聚类和编码,并从中提取第二语义标签信息和第二上下文特征信息,获得所述视频场景的第二语义信息参数;
第四处理子单元806,用于逐一融合所述视频场景的第一语义信息参数、第二语义信息参数,获得所述视频场景的语义标签信息和上下文特征信息。
需要说明的是,本说明书中的各个实施例均采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似的部分互相参见即可。对于装置类实施例而言,由于其与方法实施例基本相似,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
最后,还需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
以上对本申请所提供的一种视频数据的处理方法和装置进行了详细介绍,本文中应用了具体个例对本申请的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本申请的方法及其核心思想;同时,对于本领域的一般技术人员,依据本申请的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本申请的限制。
- 还没有人留言评论。精彩留言会获得点赞!