在可交换图中基于博弈的链接预测方法及系统与流程
本发明涉及机器学习领域,具体为一种在可交换图中基于博弈的链接预测方法及系统。
背景技术:
在实际生活中,许多系统可以用网络来建模,网络的数据结构即图。图中节点表示系统中的实体,边表示实体间的相互关系。可交换图(exchangeable graph)是指在图中,边出现的顺序对其分布并不产生影响,即边的顺序是可交换的。链接预测(link prediction)是指在网络中,利用已知的点和边结构来预测未知的边,也就是利用已知的实体之间的关系来预测任意两实体之间是否可能存在某种关系。链接预测广泛应用于推荐系统、风险评估和系统规划等方面。在可交换图中,链接预测问题和时序没有很强的关系,使得问题更加明确和简化。博弈论是一种运筹学方法,被广泛应用于存在竞争的场景。近年来,有一些研究利用博弈论来分析网络演化,提出了一些基于博弈论的网络演化模型(NFG,Network Formation Game)。
链接预测问题由来已久,已经有较多的研究。现在大多数基于机器学习的方法会对所有已经存在的正样本边和不存在的负样本边进行训练。但由于这些网络大多都是很稀疏的,所以会有大量的不存在的边(即负样本),这就对模型训练效率和准确性造成了影响。同时,有些负样本边,有时候并不是不存在的边,而可能是由于某些原因没有观测到,例如观测时被遗漏等等,这些负样本有可能在下一时刻会立即建立边转化成正样本,所以将这些作为负样本并不合适。另一方面,在可交换图中,使用隐高斯过程(latent Gaussian process)的推断一般复杂度较高,训练效率较低,并且并行化程度低。
技术实现要素:
为了解决现有技术的不足,本发明提供了一种在可交换图中基于博弈的链接预测方法,可应用在推荐系统、风险评估、系统规划或社交网络中,实体和实体之间的关系满足可交换图的要求,对实体之间的关系预测(也就是链接预测)的速度快,准确度高。
具体的,本发明的技术方案为:
一种在可交换图中基于博弈的链接预测方法,采用以下步骤:
(1)获取数据集,将数据集中的元素通过图表示,图由节点集和边集组成;所述节点代表待预测的实体,边代表待预测实体之间的关系,所述数据集的节点和边满足可交换图的要求;
(2)采用基于博弈的网络演化模型,过滤所述图中的不符合设定要求的边,以过滤后的图作为训练集;
(3)采用训练集对概率图模型进行迭代训练,得到具有最优模型参数的概率图模型;
(4)采用(3)中具有最优模型参数的概率图模型进行链接预测。
进一步的,步骤(2)中选择至少两种基于博弈的网络演化模型,采用各网络演化模型的效用函数,计算所述边对两个实体的效用值改变量,若所述边对两个实体的效用值改变量均呈下降趋势,则过滤所述边,否则,保留所述边。
进一步的,当采用两种网络演化模型时,选择链接模型和联合作者模型。
进一步的,步骤(3)中采用变分推断对概率图模型进行迭代训练。
进一步的,将步骤(2)中的训练集分为各个子训练集,子训练集是按照块(Block)划分的,每一个块大小相同;在步骤(3)中同时采用多个所述子训练集对概率图模型进行迭代训练。
进一步的,在步骤(1)中,若所述数据集的边数目大于设定值,则对所述数据集进行采样,用于使数据集的边数目减少,提高模型迭代训练速度。
进一步的,所述采样方法使用统一采样、加权采样或网格采样。
进一步的,所述概率图模型的模型参数包括隐变量U的维度和学习速率。
进一步的,提取步骤(1)中的数据集中的部分数据构成测试集,采用上述测试集对所述具有最优模型参数的概率图模型进行预测测试。
进一步的,采用5叠交叉验证方法将步骤(1)中的数据分为若干份,取其中至少一份作为测试集,采用上述测试集对所述具有最优模型参数的概率图模型进行预测测试。
本发明还提出了一种基于上述方法的在可交换图中基于博弈的链接预测系统,其特征在于包括:
获取模块,用于获取数据集,将数据集中的元素通过图表示,图由节点集和边集组成;所述节点代表待预测的实体,边代表待预测实体之间的关系,所述数据集的节点和边满足可交换图的要求;
过滤模块,用于采用基于博弈的网络演化模型,过滤所述图中的不符合设定要求的边,以过滤后的图作为训练集;
训练模块,用于采用训练集对概率图模型进行迭代训练,得到具有最优模型参数的概率图模型;
预测模块,用于采用所述具有最优模型参数的概率图模型进行链接预测。
进一步的,本系统还包括采样模块,用于当所述数据集的边数目大于设定值时,对所述数据集进行采样,用于使数据集的边数目减少,提高模型迭代训练速度。
进一步的,本系统还包括分块模块,用于将所述训练集分为各个子训练集,子训练集是按照块划分的,每一个块大小相同。
与现有技术相比,本发明的有益效果是:
(1)本发明提供一种在可交换图中基于博弈的链接预测方法及系统,它利用基于博弈论的网络演化模型将不合适的负样本边过滤出去,从而简化了训练集,在一定程度上提高了训练效果。
(2)利用联机变分推断(onlinevariational inference)来对概率图模型进行训练,可以提高可交换图的隐高斯过程的学习速率;
(3)通过对初始数据进行分块,可同时对其中的多块数据进行训练,进一步提高了训练速率;
(4)通过对数据集进行采样,可进一步去除数据集中的负样本,从而提高训练速度。
(5)本发明可适用于推荐系统、风险评估、系统规划或社交网络中,实体和实体之间的关系满足可交换图的要求,对实体之间的关系预测(也就是链接预测)的速度快,准确度高
附图说明
构成本申请的一部分的说明书附图用来提供对本申请的进一步理解,本申请的示意性实施例及其说明用于解释本申请,并不构成对本申请的不当限定。
图1为本发明链接预测模型的概率图模型。
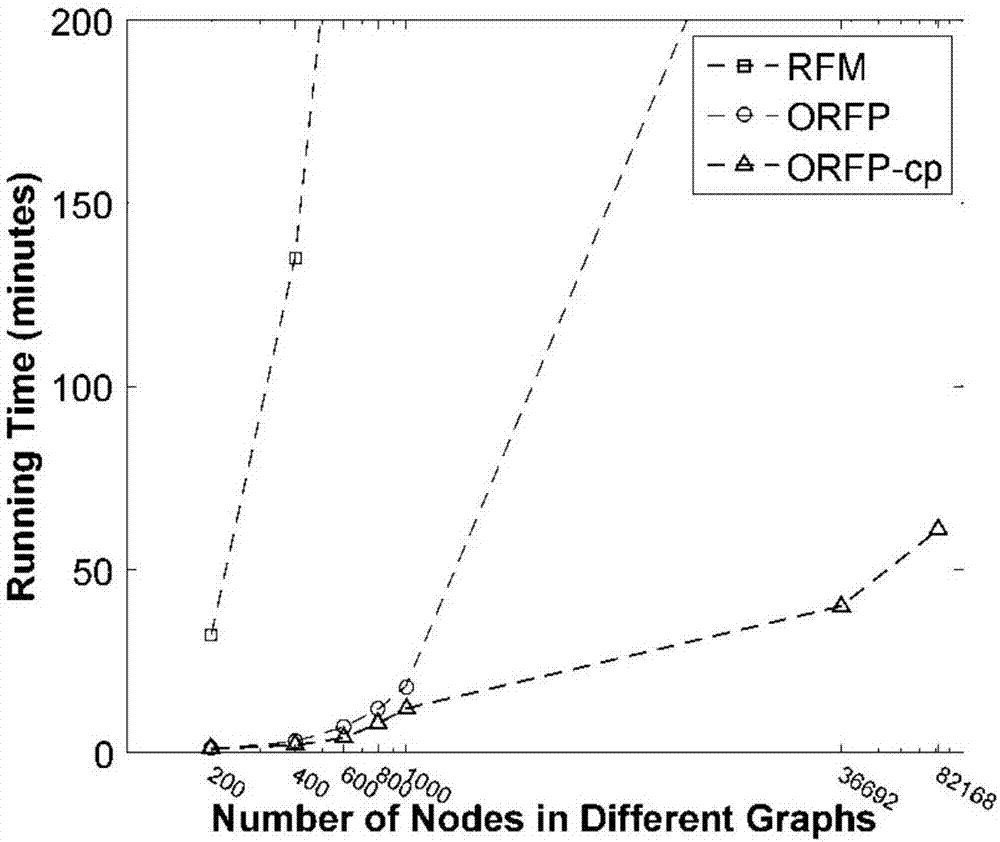
图2为不同对比方法的运行时间。
具体实施方式
应该指出,以下详细说明都是例示性的,旨在对本申请提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本申请所属技术领域的普通技术人员通常理解的相同含义。
需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本申请的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合。
实施例1:
一种在可交换图中基于博弈的链接预测方法,采用以下步骤:
(1)获取数据集,将数据集中的元素通过图表示,图由节点集和边集组成;所述节点代表待预测的实体,边代表待预测实体之间的关系,所述数据集的节点和边满足可交换图的要求;
(2)采用基于博弈的网络演化模型,过滤所述图中的不符合设定要求的边,以过滤后的图作为训练集;
(3)采用训练集对概率图模型进行迭代训练,得到具有最优模型参数的概率图模型;
(4)采用(3)中具有最优模型参数的概率图模型进行链接预测。
基于博弈的网络演化模型NFG,采用各网络演化模型的效用函数,计算所述边对两个实体的效用值改变量,若所述边对两个实体的效用值改变量均呈下降趋势,则过滤所述边,否则,保留所述边。
具体的:不同的NFG模型有着不同的效用函数,从而会对边的过滤效果产生不同的影响。这里我们主要用到了两种不同的NFG模型:链接模型(Connections Model)和联合作者模型(Co-author Model)。在链接模型中,用户通常从直接边和2-跳边获得收益,但仅仅对维护直接边产生花费。联合作者模型主要用来描述学者之间共同协作的关系。每个学者的精力是有限的,在跟其他学者的合作中获得收益,并且耗费一定的精力。NFG模型的基本思想是每个人的精力和资源是有限的,跟其他人产生合作等关系会获得一定的收益并产生花费,这是一个博弈的过程,如果收益大于花费,那么这个关系就是极有可能建立的。
每个NFG模型都有其效用函数,用来衡量每个博弈的用户的收益变化情况。这里我们确认链接模型和联合作者模型的效用函数。
链接模型:
ui(G)表示用户i在图G中所拥有的效用值。Ni(G)表示i在图G中的邻居。表示在图G中用户i经过两跳所能达到用户。dij(G)表示在图G中i和j的距离,这里是1或者2。b(dij(G))表示i从与j的关系中获得的收益。cij表示i对维护和j的关系付出的花费,这里i对其他每个人的花费都是一样的,所以用ci表示。δ表示收益基数,这个参数可以根据如下规则来确定。将所有用户按花费c从小到大排列,c1<c2<…<cn,取前20%作为核心用户,其余的作为普通用户,确定交界处的ck-1和ck,用以下公式计算δ的范围,调节这个参数可以过滤不同数量的边。
δ-δ2>0.5(ck-1+ck)
联合作者模型:
效用函数中ni表示用户i的度,即邻居数。可以按照如下公式计算效用值
1.针对每条边计算效用值变化量Δ。
通过NFG模型的效用函数,可以计算每条边lij给用户带来的收益。所以可以分别推导出不同模型的效用变化函数。
链接模型:
Δi=ui(G∪{l})-ui(G)
=δ+δ2|Nj(G)|-ci
联合作者模型:
这样就可以计算出每条边lij对用户效用值造成的改变Δi。
将Δ不符合要求的边过滤掉,和正样本边组合成训练集。
对于一条边lij分别计算Δi和Δj,如果两个都变小,即用户i和j建立关系是对双方都无益的,即建立关系的可能性很小,可以作为负样本。反之,只要有一方的Δ值增大,即表示此关系建立至少对一方是有利的,是可能建立关系的,这种边就不适合做负样本,可以过滤掉。
具体算法参照Algorithm 1如下:
步骤(3)中采用变分推断对概率图模型进行迭代训练。
具体的:如图1所示,图模型的输入为观测到的用户Ui和Uj形成的边以及过滤之后的负样本组成V,输出即为对一条边的预测,0为将来不会建立边,1为会建立边。上标m表示将整个图分成的第m块。X和Z为引入的隐变量(latent variable)。
下面我们对模型进行公式推导:
(1)确定Ui的维度为r,假设U服从如下正态分布:
Ui,Uj~N(0,Ir),1≤i,j≤n
那么,边集vk服从如下正态分布:
(2)因为y是离散的,而输入是连续的,所以一如probit函数和x变量,概率方程如下:
并且给出一个高斯先验:
为了简化计算,引入变量z,那么概率方程和先验如下:
(3)最终我们得到联合概率分布如下:
加入分块的联合概率分布如下:
(4)变分EM推断
E-step:
为简化,假定p(zm,xm|ym,vm)的近似后验方程如下:
q(zm,xm)=q(zm)q(xm)
那么通过让KL分歧最小,
可以得到x的期望:
<x>m=Km(Km+I)-1<zm>
通过<x>和z的概率分布,
可以得到z的期望如下:
M-step:
整理最大对数似然方程,
得到如下最大化目标方程,const为常数项:
进而推到得出梯度如下:
(5)预测方程
给出要预测的集合和标号预测分布如下:
以观测到的中的序列坐标,那么:
1.对整个图进行分块
对整个图按照坐标从大到小排列,每隔一段分为一块,共可以分成M块,对其中的每一块m进行训练,同时可以训练多块。
2.模型训练
θ即为上一步中推导出来的最大化目标方程,根据如下学习算法进行迭代训练:
将步骤(2)中的训练集分为各个子训练集,子训练集是按照块划分的,每一个块大小相同;在步骤(3)中同时采用多个所述子训练集对概率图模型进行迭代训练。
对整个图,也就是训练集,按照坐标从大到小排列,每隔一段分为一块,共可以分成M块,对其中的每一块m进行训练,同时可以训练多块。坐标是识别每一子训练集,即每一块的标识。
在步骤(1)中,若所述数据集的边数目大于设定值,则对所述数据集进行采样,用于使数据集的边数目减少,提高模型迭代训练速度。
具体的:可以采用的采样策略有三种:
统一采样(uniform sampling),即对每个实体采固定数量的样本。
加权采样(weighted sampling),即对每个实体,根据其度的大小采不同数量的样本。用户度越大,采样的数量就越大。
网格采样(grid sampling),将整个图(即训练集)分成不同的网格,在每个格子中进行随机采样。
最后经过迭代训练,模型已经训练好,即得到了U中的隐变量和确定的最优的模型参数,这时可以使用上述推导好的预测方程进行预测,从而得到最终结果。
实施例2:一种在可交换图中基于博弈的链接预测系统:其特征在于:包括:
获取模块,用于获取数据集,将数据集中的元素通过图表示,图由节点集和边集组成;所述节点代表待预测的实体,边代表待预测实体之间的关系,所述数据集的节点和边满足可交换图的要求;
过滤模块,用于采用基于博弈的网络演化模型,过滤所述图中的不符合设定要求的边,以过滤后的图作为训练集;
训练模块,用于采用训练集对概率图模型进行迭代训练,得到具有最优模型参数的概率图模型;
预测模块,用于采用所述具有最优模型参数的概率图模型进行链接预测。
本系统还包括采样模块,用于当所述数据集的边数目大于设定值时,对所述数据集进行采样,用于使数据集的边数目减少,提高模型迭代训练速度。
本系统还包括分块模块,用于将所述训练集分为各个子训练集,子训练集是按照块划分的,每一个块大小相同。
实施例3:本发明获取网络公开的数据集,包括Highschool、NIPS、Protein等,如表1所示。
其中Highschool是学生之间的一个网络,用来描述学生之间的相互认识情况。通过这个数据集可以预测哪些学生之间会相互认识,哪些学生在一起会更容易形成一个小集体。
NIPS包括了在NIPS 1-17会议上的作者和论文发表情况。其中我们选择了一个包括234个作者以及他们之间共同合作论文关系的子集进行示例分析。通过这个数据集,我们的预测方法可以应用在判断两个学者之间是否容易形成合作,从而能够更好的将学者团体进行聚类。
Protein数据描述了蛋白质之间的链接关系,在这个的数据集上,我们的方法可以用来预测未知的蛋白质间的关联关系,从而帮助发现和设计新的蛋白结构。
Ciao是产品评价网站www.ciao.co.uk上的用户之间的信任关系,如果一个用户信任另外一个用户,那么这两个用户之间就存在一条边。通过这个数据集,我们的方法可以用来推断两个用户之间的信任关系,从而进一步的帮助判断两个用户的评价的可靠性,用户的产品喜好等。
HEP-PH是高能物理现象日志项目的合作网络。同样是一个学者学术合作关系的网络。
Enron是一个邮件联系网络,如果两个用户之间有邮件往来就存在一条边。通过这个数据集,我们的方法可以用来预测两个用户间有没有可能形成邮件往来,从而进一步的帮助挖掘用户团体。
Slashdot是一个科技新闻分享网站,这个数据集包含了用户之间的标记关系,其中用户可以将对方标记成朋友或者是敌人。通过这个数据集,我们的方法可以用来帮助分析用户团体、喜好以及新闻的质量等等,从而能进行合适的推荐。
基于这些数据集,我们进行其中实体与实体之间的链接关系预测:
首先第一步,数据规范化处理:
将原数据进行规范化处理,转换成模型能够处理的数据格式。对图中的实体从0开始进行编号,构造图矩阵G,其中,实体i和j有边则Gij为1,否则为0。如表1所示,这里我们以表中的小中大三种数据集作为示例。
然后利用NFG进行边过滤:
选择NFG模型,这里提供的两种选择为链接模型和联合作者模型。两模型的效用函数在实施例1中已经给出,其中链接模型需要确定δ参数,这里通过前文中提供的方法计算出δ的范围,在此范围内调节δ可以获得不同过滤边的数量,可以进行多次实验,最终确定最优δ。
根据Algorithm 1,对每个NFG模型,针对每一条边lij计算效用值的改变Δi和Δj,从而过滤掉其中有一方效用值增大的边,从而将正样本和负样本一起组合成最终的训练集。
接下来进行模型训练,根据前文中提供的模型推导,在具体实施的时候需要对模型的各项参数进行设置。这里我们对参数进行如下说明。首先需要确定隐变量U的维度,这里针对小数据集我们选择维度为{1,2,3},中大型数据集为{3,5,7}。采用梯度下降法(SGD),学习率(learning rate)选定为{10-5,10-4,10-3}。为了计算协方差矩阵,我们采用RBF核(radial basis function kernel),其参数γ需要交叉验证进行最优化。对整个图进行切块处理时,对小数据集采用10*10的块大小,对中大型数据集采用100*100的块大小。
确定好参数之后,根据Algorithm 2进行训练,使用5叠交叉验证(5-fold cross validation),即将数据集分为五份,四份做训练,一份做测试。最终经过多次训练,取预测AUC(area under the curve)最好时的模型参数,这样模型就训练好了。
未知边预测:
使用训练好的模型进行预测。预测时不是一条一条边的进行预测,而是将所有未知边一起进行预测,使得预测集的分布跟训练集的分布一致。根据前文中的预测方程进行预测,最终得到每条未知边的预测结果及可信度。
表2为各种对比方法在小型数据集上的AUC结果。ORFP为本发明的方法,ORFP-ca指NFG选用的联合作者模型,而ORFP-cp指选用的是链接模型。从表中可以看出本发明的方法在小数据集的性能表现上是优秀的。表3为对比方法在中型数据集上的AUC结果,可以看出本发明方法同样性能较好。表4为在大数据集上的AUC结果,-u、-w,-g分别表示采用了统一采样、加权采样和网格采样。
本发明在预测效果上保持相似和更好的性能,并且大大缩短了模型训练时间。如图2中所示,本发明的方法与其他方法相比,运行时间大大降低。
表1示例数据集描述
表2不同对比方法在小型数据集上的AUC结果
表3不同对比方法在中型数据集上的AUC结果
表4不同对比方法在大型数据集上的AUC结果
以上所述仅为本申请的优选实施例而已,并不用于限制本申请,对于本领域的技术人员来说,本申请可以有各种更改和变化。凡在本申请的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本申请的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!