多视点信号编解码器的制作方法
本申请是进入中国国家阶段日为2013年4月10日、国际申请号为pct/ep2011/063852、发明名称为“多视点信号编解码器”的pct申请的中国国家阶段申请的分案申请,该中国国家阶段申请的申请日为2011年8月11日、申请号为201180049014.7。
本发明涉及多视点信号的编码(coding)。
背景技术:
在许多应用领域中涉及到多视点信号,比如3d视频应用,包括立体和多视点显示,自由视点视频应用等。对于立体、多视点视频内容,已制定出mvc标准[1,2]。该标准对来自多台相邻照相机的视频序列进行压缩处理。mvc解码处理仅在原始的照相机位置再现这些照相机视点。然而,对于不同的多视点显示来说,要求具有不同空间位置的不同数量的视点,从而需要另外的视点,例如在原始的照相机位置之间的视点。
处理多视点信号的难度在于需要大量的数据来传送包含在多视点信号中的关于多视点的信息。在以上提及的使能够进行中间视点提取/合成的要求而言,情况变得甚至更糟,因为在这种情况下,与各个视点相关联的视频可能伴随有诸如使得能够将各个视点重投影到另一个视点,比如中间视点的深度/视差图数据的补充数据。由于数据量巨大,因此尽可能最大化多视点信号编解码的压缩率是非常重要的。
因此,本发明的目的在于提供一种使压缩率更高或率/失真比更好的多视点信号编解码。
技术实现要素:
本目的通过未决的独立权利要求的主题实现。
本申请提供了利用发现的实施方式,根据此发现,可通过根据用于编码多视点信号的第一视点的第一编码参数采用或预测用于编码多视点信号的第二视点的第二编码参数来实现更高的压缩率或更好的比率/失真比。换句话说,发明人发现多视点信号之间的冗余不限于视点本身,比如视频信息,而使在并行编码这些视点的过程中的编码参数具有可利用的相似度,以进一步提高编码率。
本申请的一些实施方式还利用了一种发现,根据此发现,可利用视频帧中检测到的边缘作为提示,即,通过确定wedgelet分隔线以在视频帧中沿该边缘延伸,来确定或预测与用于编码深度/视差图的某个视点的视频的某个帧相关联的深度/视差图的分割。尽管边缘检测增加了解码器侧的复杂度,但在可接受质量下的低传输率比起复杂性问题更重要的应用情况下,这点缺陷还是可接受的。这样的情况可以涉及解码器被实现为固定器件的广播应用。
进一步地,本申请的一些实施方式还利用了一种发现,根据此发现,如果编码参数的采用/预测包括根据空间分辨率之间的比率定标这些编码参数,则可以以较低的空间分辨率编码,即,预测并残余校正其编码参数从另一个视点的编码信息中采用/预测的视点,从而节省编码位。
根据本发明的一个方面,提供了一种解码器,被配置为:根据从数据流获得的第一编码参数,通过从多视点信号的第一事先重建部分预测第一视点的当前部分,并利用包含在数据流中的第一校正数据校正第一视点的当前部分的预测的预测误差,来从数据流重建多视点信号的第一视点,多视点信号的第一事先重建部分在第一视点的当前部分的重建之前由解码器从数据流重建;至少部分根据第一编码参数采用或预测第二编码参数;以及根据第二编码参数,通过从多视点信号的第二事先重建部分预测第二视点的当前部分,并利用包含在数据流中的第二校正数据校正第二视点的当前部分的预测的预测误差,来从数据流重建多视点信号的第二视点,多视点信号的第二事先重建部分在第二视点的当前部分的重建之前由解码器从数据流重建。
其中,解码器被配置为:至少部分根据第一编码参数采用或预测第二编码参数的第一部分,根据第二编码参数的第一部分,通过从多视点信号的第五事先重建部分预测第二视点的视频的当前部分,并利用包含在数据流中的第二校正数据的第一子集校正第二视点的所述视频的当前部分的预测的预测误差,来从数据流重建第二视点的视频,多视点信号的第五事先重建部分在第二视点的视频的当前部分的重建之前由解码器从数据流重建,至少部分根据第一编码参数和/或第二编码参数的第一部分采用或预测第二编码参数的第二部分;以及根据第二编码参数的第二部分,通过从多视点信号的第六事先重建部分预测第二视点的深度/视差图数据的当前部分,并利用第二校正数据的第二子集校正第二视点的深度/视差图数据的当前部分的预测的预测误差,来从数据流重建第二视点的深度/视差图数据,多视点信号的第六事先重建部分在第二视点的深度/视差图数据的当前部分的重建之前由解码器从数据流重建。
其中,解码器被配置为:从第二视点的视频的事先重建部分,或从第一视点的视频的第二事先重建部分预测第二视点的视频的当前部分,第二视点的视频的事先重建部分在第二视点的视频的当前部分的重建之前由解码器从数据流重建,第一视点的视频的第二事先重建部分在第二视点的视频的当前部分的重建之前由解码器从数据流重建,以及从第二视点的深度/视差图数据的事先重建部分,或从第一视点的深度/视差图数据的第二事先重建部分预测第二视点的深度/视差图数据的当前部分,第二视点的深度/视差图数据的事先重建部分在第二视点的深度/视差图数据的当前部分的重建之前由解码器从数据流重建,第一视点的深度/视差图数据的第二事先重建部分在第二视点的深度/视差图数据的当前部分的重建之前由解码器从数据流重建。
其中,解码器被配置为:检测第二视点的视频的当前帧中的边缘并确定楔形波分隔线以沿边缘延伸,以及在从数据流重建第二视点的深度/视差图数据的过程中,设定与第二视点的视频的当前帧相关联的第二视点的深度/视差图数据的深度/视差图的当前部分的边界,以与楔形波分隔线一致。
其中,解码器被配置为在从数据流重建所述第二视点的深度/视差图数据的过程中,以当前部分所属的区段为单位利用区段的不同组的预测参数分段执行预测。
其中,解码器被配置为使得楔形波分隔线为直线并且解码器被配置为沿楔形波分隔线划分第二视点的深度/视差图数据的预分割的区块,从而使得两个相邻区段为一起形成预分割的区块的楔形波形区段。
其中,解码器被配置为使得第一编码参数和第二编码参数分别为分别控制第一视点的当前部分的预测和第二视点的当前部分的预测的第一预测参数和第二预测参数。
其中,当前部分分别为第一视点和第二视点的视频的帧分割的区段。
其中,解码器被配置为通过以第一空间分辨率对多视点信号(10)的第一视点(121)的当前部分进行预测和校正来从数据流重建多视点信号(10)的第一视点(121),并被配置为通过以低于第一空间分辨率的第二空间分辨率对多视点信号(10)的第二视点(122)的当前部分进行预测和校正来从数据流重建多视点信号(10)的第二视点(122),然后将第二视点的重建的当前部分从第二空间分辨率上采样至第一空间分辨率。
其中,解码器被配置为,至少部分从第一编码参数采用或预测第二编码参数,根据第一空间分辨率与第二空间分辨率之比定标第一编码参数。
附图说明
上文列出的各方面的实施方式的有利实现是所附从属权利要求的主题。具体地,下面相对于附图对本申请的优选实施方式进行描述,其中
图1示出了根据实施方式的编码器的框图;
图2示出了用于说明视点之间的信息重用及深度/视差边界的多视点信号的一部分的示意图;
图3示出了根据实施方式的解码器的框图;
图4是两个视点和两个时间实例的示例的多视点编码中的预测结构和运动/视差矢量;
图5是通过相邻视点之间的视差矢量进行的点对应;
图6是使用定标视差矢量通过视点1和2的场景内容投影进行的中间视点合成;
图7是用于在任意观察位置生成中间视点的分别解码颜色和补充数据的n视点提取;以及
图8是9视点显示的两视点比特流的n视点提取实例。
具体实施方式
图1示出了根据实施方式的用于编码多视点信号的编码器。图1的多视点信号在10处示例性地表示为包括两个视点121及122,尽管图1的实施方式对更多数量的视点同样是可行的。此外,根据图1的实施方式,每个视点121及122都包括视频14和深度/视差图数据16,尽管如果结合具有不包括任何深度/视差图数据的视点的多视点信号使用,则相对于图1描述的本实施方式的许多有利原理同样是有利的。本发明的这样的广义性下面进一步在图1至图3的描述之后进行描述。
各个视点121及122的视频14表示公共场景在不同投影/查看方向上的投影的时空采样(spatio-temporalsampling)。优选地,视点121及122的视频14的时间采样率彼此相等,尽管不必必须满足该约束。如图1所示,优选每个视频14包括一系列帧,每个帧与各个时间戳t,t-1,t-2,……相关联。在图1中,视频帧由vviewnumber,timestampnumber表示。每个帧vi,t表示在各个时间戳t处场景i在各个查看方向上的空间采样,并因此包括一个或多个样本阵列,比如,亮度样本的一个样本阵列以及具有色度样本的两个样本阵列,或仅亮度样本或其他颜色分量(比如rgb颜色空间的颜色分量等)的样本阵列。一个或多个样本阵列的空间分辨率在一个视频14内以及在不同视点121及122的多个视频14内可以是不同的。
类似地,深度/视差图数据16表示沿视点121及122的各个查看方向测量的公共场景的场景目标的深度的时空采样。深度/视差图数据16的时间采样率可以等于如图1中描述的相同视点的相关视频的时间采样率,或与其不同。在图1的情况下,每个视频帧v已经将各个视点121及122的深度/视差图数据16的各个深度/视差图d与此相关联。换句话说,在图1的实例中,视点i和时间戳t的每个视频帧vi,t具有与此相关联的深度/视差图di,t。关于深度/视差图d的空间分辨率,这对上文针对视频帧所示的情况同样适用。也就是说,空间分辨率在不同视点的深度/视差图之间可能会有所不同。
为了有效地压缩多视点信号10,图1的编码器并行地将视点121及122编码为数据流18。然而,用于编码第一视点121的编码参数被重新使用,以采用所述编码参数作为或预测要用于编码第二视点122的第二编码参数。通过这种措施,图1的编码器利用了本发明人发现的事实,据此,视点121及12的并行编码使编码器类似地确定用于这些视点的编码参数,从而这些编码参数之间的冗余可以被有效利用,以提高压缩率或比率/失真比(例如,以所测量的失真作为两个视点的平均失真,并以所测量的比率作为整个数据流18的编码率)。
具体地,图1的编码器一般用参考标号20表示,并包括用于接收多视点信号10的输入端以及用于输出数据流18的输出端。如在图2中所看到的,图1的编码器20的每个视点121及122包括两个编码支路,即,一个用于视频数据,另一个用于深度/视差图数据。相应地,编码器20包括用于视点1的视频数据的编码支路2v,1,用于视点1的深度视差图数据的编码支路22d,1,用于第二视点的视频数据的编码支路22v,2以及用于第二视点的深度/视差图数据的编码支路22d,2。这些编码支路22中的每一个被类似地构造。为了描述编码器20的构造和功能,以下描述开始于编码支路22v,1的构造和功能。该功能对于所有支路22是共用的。之后,讨论支路22的各个特征。
编码支路22v,1用于编码多视点信号12的第一视点121的视频141,支路22v,1相应地具有用于接收视频141的输入端。除此之外,支路22v,1包括按照所提及的顺序彼此串联的减法器24、量化/变换模块26、重量化(requantization)/逆变换(inverse-transform)模块28、加法器30、进一步的处理模块32、解码图像缓冲器34、相互并联的两个预测模块36及38以及一方面连接在预测模块36及38的输出端之间,另一方面连接在减法器24的反相输入端之间的组合器或选择器40。组合器40的输出端还与加法器30的另一个输入端连接。减法器24的非反相输入端接收视频141。
编码支路22v,1的元件24-40协作以编码视频141。编码操作以某些部分的单位对视频141进行编码。例如,在编码视频141的过程中,将帧v1,k分割成区段比如区块或其他采样组。分割可以随时间保持不变或在时间上变化。进一步地,分割操作在默认情况下对编码器和解码器来说可以是已知的或可以在数据流18内信号告知。该分割可以是被分割成区块的帧的规则分割,诸如以行和列的区块的非重叠排列,或可以为被分割成不同尺寸的区块的基于四叉树(quad-tree)的分割。输入减法器24的非反相输入端的视频141的当前编码区段在以下描述中被称为视频141的当前部分。
预测模块36及38用于预测当前部分,为此,预测模块36及38具有连接至解码图像缓冲器34的输入端。实际上,这两个预测模块36及38都使用位于解码图像缓冲器34中的视频141的事先重建部分,以预测输入减法器24的非反相输入端的当前部分/区段。因此,预测模块36用作从视频141的同一帧的空间上相邻的已经重建的部分空间预测视频141的当前部分的帧内预测子(intrapredictor),而预测模块38用作从视频141的事先重建帧时间上预测所述当前部分的帧内预测子(interpredictor)。这两个预测模块36及38根据某些预测参数执行它们的预测或执行由某些预测参数描述的它们预测。更确切地说,在一些约束(诸如最大比特率)或没有限制的情况下用于优化一些优化目标(诸如优化比率/失真比)的一些优化帧结构中,后者参数由编码器20确定。
例如,帧内预测模块36可以确定当前部分的空间预测参数,比如预测方向,视频141的同一帧的相邻的已重建的部分的内容沿该预测方向扩展到/复制到当前部分,以预测所述当前部分。帧间预测模块38可以使用运动补偿来从事先重建帧预测当前部分,并且所涉及的帧间预测参数可以包括运动矢量、参考帧指数(index)、有关当前部分的运动预测细分信息、假设数量或其任意组合。组合器40可以对模块36及38提供的一个或多个预测进行组合或仅选择其中之一。组合器或选择器40将当前部分所得的预测分别转发给减法器24的插入输入端以及加法器30的另一输入端。
在减法器24的输出端,输出当前部分的预测的残余,量化/变换模块36配置为通过量化变换系数来变换该残余信号。该变换可以是任意频谱分解变换,比如dct。由于该量化,量化/变换模块36的处理结果是不可逆转。也就是说,会发生编码损耗。模块26的输出端是在数据流内传输的残余信号421。在模块28中对残余信号421进行去量化和反相变换处理以尽可能重建残余信号,即,以对应于由减法器24输出的残余信号,尽管存在量化噪声。加法器30通过求和将重建残余信号和当前部分的预测组合在一起。其他组合也是可行的。例如,减法器24可以实施为按比例测量残余的除法器,根据可选的实施方式,加法器可以实施为重建当前部分的乘法器。加法器30的输出端由此表示当前部分的初步重建。然而,模块32中的进一步处理可以任选以用于增强重建。这样的进一步处理例如可包括解块、自适应滤波等。在解码图像缓冲器34中对目前可用的所有重建进行缓冲处理。因此,解码图像缓冲器34缓冲视频141的事先重建帧以及当前部分所属的当前帧的事先重建部分。
为了使解码器能够从数据流18重建多视点信号,量化/变换模块26将残余信号421转发至编码器20的多路复用器44。同时,预测模块36将帧内预测参数461转发至多路复用器44,帧间预测模块38将帧间预测参数481转发至多路复用器44,进一步处理模块32将进一步处理参数501转发至多路复用器44,该多路复用器44从而使所有信息多路复用或将其插入数据流18。
从以上讨论清楚可见,根据图1的实施方式,通过编码支路22v,1的视频141的编码是独立的,在于编码操作独立于深度/视差图数据161和其他视点122中的任何一个的数据。从总体上来看,编码支路22v,1可看成是通过确定编码参数,根据第一编码参数从视频141的事先编码部分预测视频141的当前部分,并确定当前部分的预测误差以获得误差数据(即,上述残余信号421)来将视频141编码成数据流18,其中,视频141的事先编码部分在所述当前部分的编码之前由编码器20编码成数据流18。将编码参数和校正数据插入数据流18中。
刚才提及的通过编码支路22v,1插入数据流18的编码参数可以包含以下项中的一个、组合或全部:
-首先,视频141的编码参数可以限定/信号告知如前面简述的视频141的帧的分割。
-另外,编码参数可以包括指示每个区段或当前部分的编码模式信息,哪个编码模式用于预测各个区段,比如帧内预测、帧间预测或其组合。
-编码参数还可以包括刚才提及的预测参数,比如用于通过帧内预测所预测的部分/区段的帧内预测参数,以及用于帧间预测部分/区段的帧间预测参数。
-然而,编码参数还可以包括进一步处理参数501,所述参数向解码侧信号告知如何在使用同一处理来处理视频141的当前或随后部分进行预测之前来对视频141的已经重建的部分进行进一步的处理。这些进一步处理参数501可包括指示各个滤波器、滤波器系数等的指数。
-预测参数461,481及进一步处理参数501甚至还可以包括子分割数据,以相对于限定模式选择的粒度或限定完全独立分割的前述分割限定进一步子分割,例如,在进一步处理中应用帧的不同部分的不同自适应滤波器。
-编码参数还可能会影响残余信号的确定,由此是残余信号421的一部分。例如,由量化/变换模块26输出的频谱变换系数等级可以看作是校正数据,而量化步长在数据流18中可以被信号告知,从以下提出的描述的意义上讲,量化步长参数可以看作是编码参数。
-编码参数还可限定预测参数,所述预测参数限定上文讨论的第一预测阶段的预测残差的第二阶段预测。因此,可以使用帧内/帧间预测。
为了提高编码效率,编码器20包括编码信息交换模块52,该编码信息交换模块接收所有编码参数以及影响或受模块36、38、32内的处理影响的进一步的信息,例如,如由从各个模块向下指向编码信息交换模块52的垂直延伸的箭头所示例性指示的。编码信息交换模块52用于共享编码参数并可选地共享编码支路22之间的进一步的编码信息,以所述分支可以预测或采用彼此的编码参数。在图1的实施方式中,为了实现这个目的,在数据实体之间定义顺序,即,多视点信号10的视点121及122的视频和深度/视差图数据。具体地,第一视点121的视频141在第一视点的深度/视差图数据161之前,随后是第二视点122的视频142,再后是第二视点122的深度/视差图数据162,以此类推。此处应注意的是,多视点信号10的数据实体之间的严格顺序不需要严格适用于整个多视点信号10的编码,但为了更便于讨论,假设在下文中该顺序是不变的。数据实体之间的顺序自然定义了与此相关联的支路22的顺序。
如上所述,另外的编码支路22比如编码支路22d,1,22v,2及22d,2操作的方式类似于编码支路22v,1,以分别编码各个输入161,142及162。然而,由于刚才提到的视点121及122的视频和深度/视差图数据之间的顺序,以及在编码支路22之间定义的相应顺序,编码支路22d,1在预测将被用于编码第一视点121的深度/视差图数据161的当前部分的方面具有另外的自由度。这是由于不同视点的视频和深度/视差图数据之间的前述顺序造成的。例如,允许这些实体中的每一个利用自身的重建部分以及按照这些数据实体之间的前述顺序居先的实体进行编码。相应地,在编码深度/视差图数据161的过程中,允许编码支路22d,1使用从对应视频141的事先重建部分已知的信息。下面将更详细地描述支路22d,1如何利用视频141的重建部分来预测深度/视差图数据161的某些属性,所述属性使深度/视差图数据161的压缩具有更好的压缩率。然而,除此之外,编码支路22d,1能够预测/采用上述编码视频141的过程中所涉及的编码参数,以便获得用于编码深度/视差图数据161的编码参数。在采用的情况下,可以抑制有关数据流18中的深度/视差图数据161的任何编码参数的信号告知。在预测的情况下,只有有关这些编码参数的预测残差/校正数据才可能需要在数据流18中信号告知。下面将对编码参数的这样的预测/采用的实例进行进一步描述。
对后续数据实体(即,第二视点122的视频142和深度/视差图数据161)而言存在另外的预测性能。就这些编码支路而言,帧间预测模块自身不但能够执行时间预测,而且还能执行视点间预测。对应的帧间预测参数包括与时间预测相比来说相似的信息,即,每视点间预测区段、视差矢量、视点指数、参考帧指数和/或多个假设的指示,即,通过求和方式参与形成视点间预测的多个帧间预测的指示。这样的视点间预测不但对于有关视频142的支路22v,2是可用的,而且对于有关深度/视差图数据162的支路22d,2的帧间预测模块38也是可用的。当然,这些视点间预测参数也表示可作为用于可能的第三视点(然而,图1中未示出)的随后的视点数据的采用/预测基础的编码参数。
由于上述措施,进一步减少了通过多路复用器44插入数据流18的数据量。具体地,通过采用前面的编码支路的编码参数或仅经由多路复用器44将与此相关的预测残差插入数据流18,可以大大减少编码支路22d,1,22v,2及22d,2的编码参数的量。由于能够在时间预测和视点间预测之间选择,因此也可减少编码支路22v,2及22d,2的残余数据423及424的量。残余数据量的减少以区分时间和视点间预测模式的方式过度补偿了另外的编码工作。
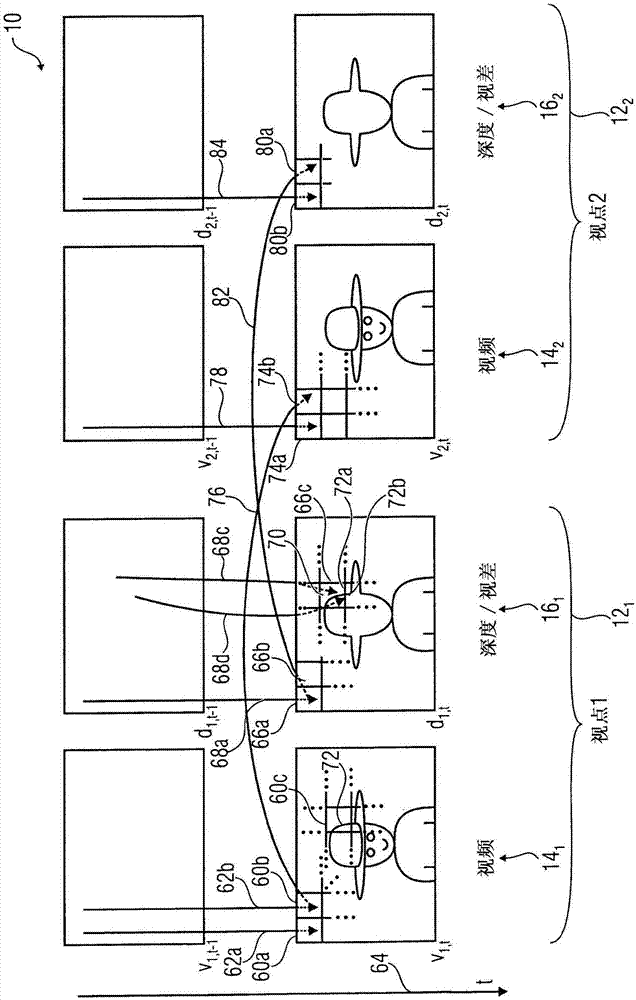
参照图2以更详细说明编码参数采用/预测的原理。图2示出了多视点信号10的示例性部分。图2示出了被分割成区段或部分60a,60b及60c的视频帧v1,t。为了简化,只示出了帧v1,t的三个部分,尽管分割可以无缝且无间隙地将帧划分为多个区段/部分。如前所述,视频帧v1,t的分割可以是固定的,也可以随时间变化,并且分割可以在数据流中信号告知或不告知。图2示出了使用来自视频141的任何参考帧(在本情况下为示例性帧v1,t-1)的重建版本的运动矢量62a及62b时间地预测部分60a及60b。如在本领域中已知的那样,视频141的帧之间的编码顺序可能与这些帧之间的呈现顺序不一致,因此,参考帧可以按呈现时间顺序接替当前帧v1,t。部分60c例如是将帧内预测参数插入数据流18的帧内预测部分。
在编码深度/视差图d1,t的过程中,编码支路22d,1可以通过在下文中相对于图2举例说明的一种或多种方式利用上述可能性。
-例如,在编码深度/视差图d1,t的过程中,编码支路22d,1可以采用由编码支路22v,1所使用的视频帧v1,t的分割。相应地,如果视频帧v1,t的编码参数内存在分割参数,则可避免重发深度/视差图数据d1,t。可选地,通过经由数据流18信号告知相对于视频帧v1,t的分割偏差,编码支路22d,1可以使用视频帧v1,t的分割作为用于深度/视差图d1,t的分割的基础/预测。图2示出了编码支路22d,1使用视频帧v1的分割作为深度/视差图d1,t的预分割。也就是说,编码支路22d,1采用来自视频v1,t的分割的预分割或从其预测所述预分割。
-此外,编码支路22d,1可以从分配给视频帧v1,t中的各个部分60a,60b及60c的编码模式采用或预测深度/视差图d1,t的部分66a,66b及66c的编码模式。在视频帧v1,t和深度/视差图d1,t之间的分割不同的情况下,可以对从视频帧v1,t采用/预测编码模式进行控制,从而使得从视频帧v1,t分割的协同定位部分获得采用/预测。协同定位的适当定义如下。深度/视差图d1,t中的当前部分的视频帧v1,t中的协同定位部分例如可以是包括深度/视差图d1,t中的当前帧的左上角处的协同位置的部分。在预测编码模式的情况下,编码支路22d,1可以信号告知深度/视差图d1,t的部分66a-66c的编码模式相对于数据流18中明确地信号告知的视频帧v1,t中的编码模式的偏差。
-只要涉及预测参数,编码支路22d,1可自由地空间采用或预测用来对在同一深度/视差图d1,t中的相邻部分进行编码的预测参数,或者从用来对视频帧v1,t的协同定位部分66a-66c进行编码的预测参数采用/预测所述预测参数。例如,图2示出了深度/视差图d1,t的部分66a是帧间预测部分,并且可以从视频帧v1,t的协同定位部分60a的运动矢量62a来采用或预测对应的运动矢量68a。在预测的情况下,只将运动矢量差插入数据流18,作为帧间预测参数482的一部分。
-就编码效率而言,使得编码支路22d,1能够利用所谓的楔形波分隔线(wedgeletseparationline)70将深度/视差图d1,t的预分割区段进行细分,并将该楔形波分割线70的位置信号告知数据流18中的解码侧,这对于编码支路22d,1来说是有利的。通过这种措施,在图2的实例中,深度/视差图d1,t的部分66c被细分为两个楔形波形部分72a及72b。编码支路22d,1可以被配置为分别编码子区段72a及72b。就图2而言,这两个子区段72a及72b都示例性地利用各自的运动矢量68c及68d进行帧间预测。在对这两个子区段72a及72b进行帧内预测(intraprediction)的情况下,通过外推相邻因果区段的dc值来导算出每个区段的dc值,通过将相应细化的dc值发送给解码器作为帧内预测参数来选择细化这些导出dc值中的每一个。存在使解码器能够确定由编码器所用来细分深度/视差图的预分割的楔形波分隔线的若干可能性。编码支路22d,1可以被配置为专用这些可能性中的任一个。可选地,编码支路22d,1可以自由地选择以下编码选项,且将所述选择作为数据流18中的边信息(sideinformation)信号告知解码器。
楔形波分隔线70例如可以是直线。将该线70的位置信号告知解码侧可以包括信号告知沿区段66c的边界的交叉点以及倾斜或梯度信息或楔形波分隔线70与区段66c的边界的两个交叉点的指示。在实施方式中,楔形波分隔线70可利用楔形波分隔线70与区段66c的边界的两个交叉点的指示在数据流中明确信号告知,其中表示可能的交叉点的网格的粒度,即,交叉点指示的粒度或分辨率,可以取决于区段66c的尺寸或编码参数,比如量化参数等。
在利用二进方块通过基于四叉树的区块划分给出预分割的可选实施方式中,可以以查找表(lut)的形式给出每个区块大小的交叉点的容许集,从而使得每个交叉点的信号告知涉及对应的lut索引的信号告知。
然而,根据另一种可能性,编码支路22d,1使用解码图像缓冲器34中的视频帧v1,t的重建部分60c,以便预测楔形波分隔线70的位置,并在数据流中将实际用于编码区段66c的楔形波分隔线70的偏差(如果有的话)信号告知解码器。具体地,模块52可以在与深度/视差图d1,t的部分66c的位置对应的位置处对视频v1,t执行边缘检测。例如,该检测对视频帧v1,t中的一些定标特征比如亮度、亮度分量或色度分量或色度等的空间梯度超过某一最小阈值的边缘是敏感。模块52可基于该边缘72的位置确定楔形波分隔线70,以便该线沿边缘72延伸。因为解码器也访问了重建视频帧v1,t,解码器能够确定楔形波分隔线70以便将部分66c细分为楔形波形子部分72a及72b。从而节省了用来信号告知楔形波分隔线70的信令容量。具有表示楔形波分隔线位置的部分66c大小相关的分辨率的方面也适用于通过边缘检测确定线70的位置的方面并根据预测位置传送可选偏离。
在编码视频142的过程中,编码支路22v,2除了可用于编码支路22v,1的编码模式选项之外,还具有帧间视点预测(inter-viewprediction)选项。
例如,图2示出了视频帧v2,t的分割的部分64b是从第一视点视频141的时间相应视频帧v1,t利用视差矢量76预测得到的帧间视点。
尽管存在差异,编码支路22v,2还可以利用从视频帧v1,t和深度/视差图d1,t编码为可用的所有信息,比如,特别是,这些编码中所使用的编码参数。因此,编码支路22v,2可以从时间对准视频帧v1,t和深度/视差图d1,t的协同定位部分60a及66a的运动矢量62a及68a的任意一个或组合采用或预测包括视频帧v2,t的时间帧内预测部分74a的运动矢量78的运动参数。如果有的话,可以相对于部分74a的帧间预测参数信号告知预测残差。因此,应该指出,运动矢量68a可能已经根据运动矢量62a自身进行了预测/采用。
相对于深度/视差图d1,t的编码的如上所述的采用/预测用于编码视频帧v2,t的编码参数的其他可能性可用于通过编码支路22v,2对视频帧v2,t进行的编码,然而,由模块52分布的可用的共用数据会增加,因为视频帧v1,t和相应深度/视差图d1,t的编码参数都可用。
然后,与编码支路22d,1编码深度/视差图d1,t类似,编码支路22d,2编码深度/视差图d2,t。对于从相同视点122的视频帧v2,t的所有编码参数采用/预测情况来说,这是真的。然而,另外,编码支路22d,2有机会从已用于编码前面的视点121的深度/视差图d1,t的编码参数采用/预测编码参数。另外,编码支路22d,2可以使用相对于编码支路22v,2所说明的帧间视点预测。
就编码参数采用/预测而言,需要将编码支路22d,2从多视点信号10的事先编码实体的编码参数采用/预测其编码参数的可能性限制至同一视点122的视频142及相邻的事先编码视点121的深度/视差图数据161,以降低信令开销,所述信令开销源自信号告知数据流18中的编码侧用于度/视差图d2,t的各个部分的采用/预测来源的必要性。例如,编码支路22d,2可以从视频帧v2,t的协同定位部分74b的视差矢量76预测包括视差矢量82的深度/视差图d2,t的帧间视点预测部分80a的预测参数。在这种情况下,根据其进行了采用/预测的数据实体的指示,即,图2的视频142,可以被省略,因为视频142只有可能是深度/视差图d2,t的视差矢量采用/预测的来源。然而,在采用/预测时间帧间预测部分80b的帧间预测参数的过程中,编码支路22d,2可以从运动矢量78,68a及62a中的任何一个采用/预测对应的运动矢量84,因此,编码支路22d,2可以被配置为在数据流18中信号告知运动矢量84的采用/预测来源。因此,将可能的来源限制到视频142和深度/视差图161减少了开销。
就分隔线而言,编码支路22d,2除了上文已讨论的选项之外还具有以下选项:
为了利用楔形波分隔线编码视点122的深度/视差图d2,t,可以比如通过边缘检测并隐含地推导出相应的楔形波分隔线来使用信号d1,t的对应的视差补偿部分。视差补偿然后用于将深度/视差图d1,t中的检测线传递给深度/视差图d2,t。对于视差补偿来说,可以使用沿深度/视差图d1,t中的各个检测边缘的前景深度/视差值。
可选地,为了利用楔形波分隔线编码视点122的深度/视差图d2,t,可以通过使用d1,t的视差补偿部分中的楔形波分隔线,即,使用用于编码信号d1,t的协同定位部分的楔形波分隔线作为预测子(predictor)或采用该分隔线,来使用信号d1,t的相应视差补偿部分。
在描述图1的编码器20之后,应注意的是,该编码器可以软件、硬件或固件,即,可编程硬件实现。尽管图1的框图提出了编码器20在结构上包括并行编码支路,即,多视点信号10一个编码支路和深度/视差数据一个编码支路,但这并不一定如此。例如,分别被配置为执行元件24-40的任务的软件程序、电路部分或可编程逻辑部分可以被顺序用于完成每个编码支路的任务。在并行处理过程中,可以对并行处理器核或并行运行电路执行并行编码支路的处理。
图3示出了解码器的实例,该解码器能够解码数据流18以便从数据流18重建与由多视点信号表示的场景对应的一个或几个视点视频。在很大程度上,图3的解码器的结构和功能类似于图2的编码器,从而尽可能重新使用图1的参考标号来表示上文相对于图1提供的功能描述同样适用于图3。
图3的解码器一般用参考标号100表示,并包括用于数据流18的输入端以及用于输出前述一个或几个视点102的重建的输出端。解码器100包括解多路复用器104和用于由数据流18表示的多视点信号10(图1)的每个数据实体的一对解码支路106以及视点提取器108和编码参数交换器110。如与图1的编码器的情况一样,解码支路106在相同互连中包括相同解码元件,相应地,相对于负责解码第一视点121的视频141的解码支路106v,1代表性地描述所述解码分支。具体地,每个编码支路106包括与多路复用器104的各个输出端连接的输入端以及与视点提取器108的各个输入端连接以便向视点提取器108输出多视点信号10的各个数据实体即,解码支路106v,1情况下的视频141的输出端。其中,每个编码支路106都包括串联连接在多路复用器104和视点提取器108之间的去量化/反相变换模块28、加法器30、进一步处理模块32以及解码图像缓冲器34。加法器30、进一步处理模块32以及解码图像缓冲器34和跟随在组合器/选择器40之后的预测模块36及38(以上述顺序)的并联(连接在解码图像缓冲器34和加法器30的另一输入端之间)构成一个回路。正如利用图1的相同参考标号所表示的那样,解码支路106的元件28至40的结构和功能与图1中的编码支路的相应元件的相似之处在于,解码支路106的元件利用数据流18中传递的信息模拟编码过程的处理。自然,解码支路106仅相对于由解码器20最终选择的编码参数反转编码程序,而图1的编码器20从优化程度来说必须找出一组最优的编码参数,比如优化比率/失真成本函数的编码参数,任选要受一定限制,比如最大比特率等。
解多路复用器104用于向各个解码支路106分配数据流18。例如,解多路复用器104为去量化/反相变换模块28提供残余数据421,为进一步处理模块32提供进一步处理参数501,为帧内预测模块36提供帧内预测参数461,为帧间预测模块38提供帧间预测参数481。编码参数交换器110的作用与图1中的相应模块52一样,以便在各个解码支路106中分配共用编码参数和其他共用数据。
视点提取器108接收由并行解码支路106重建的多视点信号并从中提取与外部提供的中间视点提取控制数据112规定的视角或视向(viewdirection)对应的一个或多个视点102。
由于解码器100与编码器20的相应部分的构造类似,因此可与以上描述类似地简单说明视点提取器108的接口的功能。
实际上,解码支路106v,1和106d,1一起操作以根据数据流18中包含的第一编码参数(比如,421中的定标参数、参数461,481,501、相应的未采用的参数以及第二支路16d,1的编码参数的预测残差,即参数462,482,502),通过从多视点信号10的事先重建部分预测第一视点121的当前部分并利用例如421和422中的,同样包含在数据流18中的第一校正数据校正第一视点121的当前部分预测的预测误差,来重建数据流18的多视点信号10的第一视点121,其中,所述多视点信号10的事先重建部分在第一视点121的重建之前从数据流18被重建。当解码支路106v,1负责解码视频141时,编码支路106d,1假设负责重建深度/视差图数据161。例如,参见图2:根据从数据流18读取的相应编码参数,即,421中的定标参数、参数461,481,501,解码支路106v,1通过从多视点信号10的事先重建部分预测视频141的当前部分(诸如,60a,60b或60c)并使用从数据流18,即从421中的变换系数等级获得的相应校正数据校正该预测的预测误差,来从数据流18重建第一视点121的视频141。例如,解码支路106v,1以区段/部分为单位利用视频帧之间的编码顺序对视频141进行处理,为了编码帧内的区段,这些帧的区段之间的编码顺序就像编码器的相应编码支路所做的那样。相应地,视频141的所有的事先重建部分都可用于预测当前部分。用于当前部分的编码参数可以包括帧内预测参数501、帧间预测参数481、用于进一步处理模块32的滤波参数等中的一个或多个。用于校正预测误差的校正数据可以由残余数据421中的频谱变换系数等级表示。并非所有这些编码参数都需要全部传送。它们中的一部分可能已经从视频141的相邻区段的编码参数进行了空间预测处理。视频141的运动矢量例如可以在比特流内作为视频141的相邻部分/区段的运动矢量之间的运动矢量差而传送。
只要涉及第二解码支路106d,1,该第二解码支路不但对在数据流18中信号告知的并通过解多路复用器104分配给各个解码支路106d,1的残余数据422和相应的预测和滤波参数,即,不是通过帧间视点边界预测的编码参数,进行访问,而且可以间接地对经由解多路复用器104提供给解码支路106v,1的编码参数和校正数据,或由此产生的、经由编码信息交换模块110分配的任何信息进行访问。因此,解码支路106d,1从经由解多路复用器104转发至第一视点121的一对解码支路106v,1及106d,1的编码参数的一部分(其与尤其专用于并转发至解码支路106v,1的这些编码参数的一部分部分重叠)确定用来重建深度/视差图数据161的编码参数。例如,解码支路106d,1从在481中明确传送的运动矢量62a确定运动矢量68a,在一方面作为与帧v1,t的另一个相邻部分的运动矢量差,另一方面作为在482中明确传送的运动矢量差。另外地或可选地,解码支路106d,1可以使用上文相对于楔形波分隔线的预测而描述的视频141的重构部分来预测用来解码深度/视差图数据161的编码参数。
更确切地说,解码支路106d,1通过使用至少部分地从由解码支路106v,1所使用的编码参数预测的和/或从解码支路106v,1的解码图像缓冲器34中的视频141的重建部分预测的编码参数来从数据流重建第一视点121的深度/视差图数据141。编码参数的预测残差可以经由解多路复用器104从数据流18中获得。用于解码支路106d,1的其他编码参数可以全部在数据流108中传送或相对于另一个依据,即,参照已用于编码深度/视差图数据161自身的任意事先重建部分的编码参数进行传送。基于这些编码参数,解码支路106d,1从深度/视差图数据161的事先重建部分预测深度/视差图数据141的当前部分,并利用各个校正数据422校正预测深度/视差图数据161的当前部分的预测误差,其中,所述深度/视差图数据161的事先重建部分在重建深度/视差图数据161的当前部分之前由解码支路106d,1从数据流18重建。
因此,数据流18可以包括一个部分,比如深度/视差图数据161的部分66a,如下:
-指示用于当前部分的编码参数是否或哪一部分从例如视频141的协同定位和时间校准部分的(或从其他视频141的特定数据,比如重建版本以便预测楔形波分隔线)对应的编码参数采用或预测,
-若是,在预测的情况下,则是编码参数残差,
-若否,则是当前部分的所有编码参数,其中,与深度/视差图数据161的事先重建部分的编码参数相比,当前部分的所有编码参数都可以被信号告知为预测残差,
-如果并非如上所述的所有编码参数都要被预测/采用,则是当前部分的编码参数的剩余部分,其中与深度/视差图数据161的事先重建部分的编码参数相比,当前部分的编码参数的剩余部分可以被信号告知为预测残差。
例如,如果当前部分是帧间预测部分,比如部分66a,则运动矢量68a可以在数据流18中被信号告知为从运动矢量62a被采用或预测。此外,解码支路106d,1可以根据如上所述视频141的重建部分中的检测边缘72预测楔形波分隔线70的位置并在数据流18中无信号告知的情况下或根据数据流18中的各个应用信号告知应用该楔形波分隔线70。换句话说,用于当前帧的楔形波分割线的应用可以通过数据流18中的信号告知的方式被抑制或允许。甚至换言之,解码支路106d,1可以有效预测深度/视差图数据的当前重建部分的外周(circumference)。
与如上文相对于编码描述的那样,第二视点122的一对解码支路106v,2及106d,2的功能与第一视点121类似。这两个支路协作以利用自身的编码参数从数据流18重建多视点信号10的第二视点122。仅是这些编码参数的一部分需要经由解多路复用器104传输并分配给这两个解码支路106v,2及106d,2中的任一个,其没有在视点141及142之间的边界被采用/预测,可选地,为视点间预测部分的残差。第二视点122的当前部分从多视点信号10的事先重建部分进行预测,并由此利用由解多路复用器104转发给这对解码支路106v,2及106d,2的校正数据,即423及424校正预测误差,其中,所述多视点信号10的事先重建部分在第二视点122的各个当前部分的重建之前通过解码支路106中的任一个从数据流18中重建。
解码支路106v,2被配置为至少部分地从由解码支路106v,1及106d,1中的任意一个使用的编码参数采用或预测其编码参数。可以对视频142的当前部分呈现以下有关编码参数的信息:
-指示当前部分的编码参数是否或哪一部分从例如视频141或深度/视差数据161的协同定位和时间校准部分的对应的编码参数被采用或被预测,
-若是,在预测的情况下,则是编码参数残差,
-若否,则是当前部分的所有编码参数,其中,与视频142的事先重建部分的编码参数相比,当前部分的所有编码参数可以被信号告知为预测残差,
-如果并非如上所述的所有编码参数都要被预测/采用,则是当前部分的编码参数的剩余部分,其中,与视频142的事先重建部分的编码参数相比,当前部分的编码参数的剩余部分可以被信号告知为预测残差,
-数据流18中的信号告知可以用信号告知当前部分74a是否要从全新的数据流中读取此部分的相应编码参数,比如运动矢量78,相应编码参数是否进行空间预测或是否根据第一视点121的视频141或深度/视差图数据161的协同定位部分的运动矢量进行预测,并且解码支路106v,2是否可以相应起作用,即,通过全部从数据流18中提取运动矢量78,采用或预测该运动矢量,在后一种情况下,从数据流18中提取有关当前部分74a的编码参数的预测误差数据。
解码支路106d,2可以进行类似的操作。也就是说,解码支路106d,2可以至少部分地通过采用/预测而从由解码支路106v,1、106d,1及106v,2中的任一个所使用的编码参数,从第一视点121的重建视频142和/或重建深度/视差图数据161确定其编码参数。例如,数据流18可以信号告知深度/视差图数据162的当前部分80b,当前部分80b的编码参数是否或者哪一部分从视频141、深度/视差数据161以及视频142或其适当子集中的任一个的协同定位被采用或被预测。这些编码参数所关注的部分可以涉及运动矢量比如84,或视差矢量比如视差矢量82。此外,其他编码参数,比如有关楔形波分隔线的编码参数,可以由解码支路106d,2利用视频142中的边缘检测推导出来。可选地,边缘检测甚至可以通过应用预定再投影而用于重建深度/视差图数据161,以便将检测边缘在深度/视差图d1,t中的位置传递给深度/视差图d2,t,从而作为预测楔形波分隔线的位置的基础。
多视点数据10的重建部分在任何情况都可到达视点提取器108,其中包含的视点是新视点(即,与这些新视点相关联的视频等)的视点提取基础。该视点提取可以包括或涉及利用与此相关联的深度/视差图数据再投影所述视频141及142。坦率地说,在将视频再投影到另一个中间视点的过程中,视频的与位于接近观察者的场景部分对应的部分沿视差方向,即查看方向差矢量的方向的移动超过视频的与位于远离观察者位置的场景部分对应的部分。下面相对于图4至图6及图8概述由视点提取器108执行的视点提取的实例。去遮挡处理也可以由视点提取器执行。
然而,在描述下文的另外的实施方式之前,应注意的是,可以对上面列出的实施方式进行几处修改。例如,多视点信号10不一定要包括每个视点的深度/视差图数据。甚至可以是,多视点信号10中没有任何视点具有与此相关联的深度/视差图数据。然而,编码参数重新使用或在上面列出的多个视点之间共享会使编码效率得到提高。此外,对于某些视点来说,可以限制深度/视差图数据在数据流中传送至去遮挡区域(disocclusionarea),即,根据设定为不确定图的剩余区域中的值的多视点信号的其他视点填充再投影视点中的去遮挡区域的区域。
如上所述,多视点信号10的视点121及122可以具有不同的空间分辨率。也就是说,它们可以使用不同的分辨率在数据流18中传输。甚至换言之,编码支路22v,1及22d,1执行预测编码的空间分辨率可能高于编码支路22v,2及22d,2按照视点之间的上述顺序对继视点121之后的后续视点122执行预测编码的空间分辨率。本发明的发明人发现,在考虑到合成视点102的质量时,该措施还提高了比率/失真比。例如,图1的编码器首先以相同的空间分辨率接收视点121和视点122,然而,然后在使第二视点122的视频142和深度/视差图数据162进行由模块24-40实现的预测编码程序之前,将第二视点122的视频142和深度/视差图数据162下采样为较低的空间分辨率。然而,仍然可通过根据源视点和目标视点的不同分辨率之间的比来定标形成采用或预测基础的编码参数,从而执行采用并预测视点边界上的编码参数的上述措施。例如,参见图2。如果编码支路22v,2意在从运动矢量62a及68a中的任意一个采用或预测运动矢量78,则编码支路22v,2通过与视点121(即,源视点)的高空间分辨率与视点22(即,目标视点)的低空间分辨率之比对应的值向下定标该运动矢量。自然,这对于解码器和解码支路106都适用。解码支路106v,2及106d,2可以相对于解码支路106v,1及106d,1以低的空间分辨率执行预测解码。在重建之后,可使用上采样方式,以便在深度/视差图到达视点提取器108之前将由解码支路106v,2及106d,2的解码图像缓冲器34输出的重建图像和深度/视差图从低空间分辨率转变为高空间分辨率。各个上采样器可以位于各个解码图像缓冲器和视点提取器108的各个输入端之间。如上所述,在一个视点121或122内,视频及相关深度/视差图数据可以具有相同的空间分辨率。然而,另外地或可选地,这些对具有不同的空间分辨率,并在空间分辨率边界,即深度/视差图数据和视频之间执行上面刚刚描述的措施。此外,根据另一个实施方式,存在包括视点123的三个视点,为了便于进行说明在图1至图3中未示出,第一视点和第二视点具有相同的空间分辨率,而第三视点123具有较低的空间分辨率。因此,根据刚才描述的实施方式,部分后续视点,比如视点122,在编码之前进行下采样处理,在解码之后进行上采样处理。该子采样或上采样分别表示解码/编码支路的预处理或后处理,其中用于采用/预测任何后续(目标)视点的编码参数的编码参数根据源视点和目标视点的空间分辨率的比进行定标。如上所述,以较低的质量传输这些后续视点(诸如视点122)并没有显著影响中间视点提取器108的中间视点输出102的质量,原因是在中间视点提取器108中进行处理。由于再投影到中间视点并且必须对再投影到中间视点的采样网格的视频采样值进行再采样,因此视点提取器108无论如何都会对视频141及142执行插值/低通滤波。为了探讨第一视点121以相对于相邻视点122增加的空间分辨率进行传送的事实,其间的中间视点可以主要从视点121获得,仅利用低空间分辨率视点122和其视频142作为辅视点,比如仅用于填充视频141的再投影版本的去遮挡区域,或当对视点121和视点122的视频的再投影版本进行平均处理时仅以减少的加权因子参与。通过这一措施,尽管第二视点122的编码率因以较低空间分辨率传送而明显降低,但同样对视点122的较低空间分辨率进行补偿。
还应提及的是,就编码/解码支路的内部结构而言,可以修改所述实施方式。例如,可能不存在帧内预测模式,即,无空间预测模式可用。类似地,可以忽略任意帧间视点和时间预测模式。此外,所有进一步处理选项都是可选的。另一方面,在解码支路106的输出端上可以存在越环后处理模块(out-of-looppost-processingmodule),以便执行自适应滤波或其他质量提高措施和/或上述上采样。此外,可以不执行残差变换。而是,残差可以在空间域中而不是在频域中传送。就一般意义而言,图1及图3中所示的混合编码/解码设计可以用其他编码/解码构思,比如基于小波变换的构思替换。
还应提及的是,解码器没必要包括视点提取器108。而是,可能不存在视点提取器108。在这种情况下,解码器100仅用于重建视点121及122中的任意一个,比如其中一个、几个或全部。如果对各个视点121及122来说不存在深度/视差数据,则视点提取器108可以通过利用使相邻视点的相应部分彼此相关的视差矢量来执行中间视点。这些视差矢量作为与相邻视点的视频相关联的视差矢量场的支持视差矢量,视点提取器108可以通过应用该视差矢量场从相邻视点121及122的这样的视频来构建中间视点视频。试想视频帧v2,t具有视点间预测的部分/区段的50%。也就是说,对于50%的部分/区段来说,可能存在视差矢量。对于剩余部分来说,视差矢量可以由视点提取器108通过内插/外推法从空间方面确定。还可以使用将视差矢量用于视频142的事先重建帧的部分/区段的时间插值。然后根据这些视差矢量使视频帧v2,t和/或基准视频帧v1,t失真,从而产生中间视点。为此,根据中间视点在第一视点121和第二视点122的视点位置之间的中间视点位置定标视差矢量。下面将更详细地概述有关该程序的细节。
通过使用确定楔形波分割线以在视频的重建的当前帧中沿着检测的边缘延伸的上述选项,来获得编码效率增益。因此,如上所述,上述楔形波分隔线位置预测可以用于每个视点,即,全部或仅用于其适当的子集。
迄今为止,图3的上述讨论还揭示了一种解码器,其具有解码支路106c,1和解码支路106d,1,解码支路106c,1被配置为从数据流18重建视频141的当前帧v1,t,解码支路106d,1被配置为检测重建当前帧v1,t中的边缘72,确定楔形波分隔线70以便沿边缘72延伸,并从数据流18以深度/视差图d1,t的分割的区段66a,66b,72a,72b为单位重建与当前帧v1,t相关联的深度/视差图d1,t,其中,分割的两个相邻区段72a,72b通过楔形波分隔线70相互分开。解码器可以被配置为利用区段的不同组的预测参数,从与当前帧v1,t相关联的深度/视差图d1,t或与视频的任意事先解码帧v1,t-1相关联的深度/视差图d1,t-1的事先重建区段来分段预测深度/视差图d1,t。解码器可以被配置使得楔形波分隔线70是直线,解码器被配置为根据深度/视差图d1,t的基于区块的预分割,通过沿楔形波分隔线70划分预分割的区块66c来确定分割,以便两个相邻的区段72a,72b为一起形成预分割的区块66c的楔形波形区段。
总结上述一些实施方式,这些实施方式使得能够从共同解码多视点视频和补充数据进行视点提取。术语“补充数据”在下文中用于表示深度/视差图数据。根据这些实施方式,多视点视频和补充数据被嵌入在一个压缩表示中。补充数据可以由逐像素深度图、视差数据或3d线框组成。所提取的视点102与压缩表示或比特流18中包含的视点121,122的不同之处在于视点数量和空间位置。之前已经通过编码器20生成了压缩表示18,其可以使用补充数据来改善视频数据的编码。
与当前现有技术的方法相比,执行联合解码,其中,通过共用信息支持并控制视频和补充数据解码。实例为一组共用的运动矢量或视差矢量,用于解码视频和补充数据。最后,从解码视频数据、补充数据和可能组合数据中提取视点,其中,在接收设备处通过提取控制对所提取视点的数量和位置进行控制。
进一步地,上文描述的多视点压缩概念可结合基于视差的视点合成一起使用。基于视差的视点合成的含义如下。如果由多台照相机捕获场景内容,比如视频141及142,则可以向观察者呈现该内容的三维感知。为此,立体对必须为左眼和右眼设置稍微不同的查看方向。由视差矢量表示相等时间实例的两个视点中的同一内容的切换。类似于此,在不同时间实例之间的序列中的内容切换是运动矢量,如图4所示,用于不同时间实例的两个视点。
通常,直接估计或以场景深度形式估计视差,该视差由外部提供或利用专用传感器或照相机进行记录。运动估计已由标准编码器执行。如果多个视点被一起编码,则对时间和视点间方向进行类似处理,以便在编码过程中沿时间和视点间方向执行运动估计。这已经相对于图1和图2进行了描述。在视点间方向上的估计的运动矢量是视差矢量。这样视差矢量在图2中用82和76示例性地示出。因此,编码器20还隐式地执行视差估计并且编码比特流18中包括有视差矢量。这些矢量可以用于在解码器上,即,在视点提取器108中进行额外的中间视点合成。
考虑位置(x1,y1)处的视点1的像素p1(x1,y1)以及位置(x2,y2)处的视点2的像素p2(x2,y2),它们具有相同亮度值。则,
p1(x1,y1)=p2(x2,y2)(1)
通过2d视差矢量连接位置(x1,y1)和(x2,y2),例如从视点2至视点1,其是具有分量dx,21(x2,y2)和dy,21(x2,y2)的d21(x2,y2)。因此,下面的等式适用:
(x1,y1)=(x2+dx,21(x2,y2),y2+dy,21(x2,y2))(2)
组合(1)和(2),
p1(x2+dx,21(x2,y2),y2+dy,21(x2,y2))=p2(x2,y2)(3)
如图5所示,右下角的具有相同内容的两个点可以由视差矢量连接。将该矢量添加到p2的坐标得出图像坐标中p1的位置。如果视差矢量d21(x2,y2)现在由因子κ=[0…1]定标,则(x1,y1)和(x2,y2)之间的任何中间位置可以被求出。因此,可以通过由定标视差矢量使视点1和/或视点2的图像内容偏移来生成中间视点。图6中示出了中间视点的实例。
因此,可以利用视点1和视点2之间的任意位置来生成新的中间视点。
除此之外,还可以利用视差的定标因子κ<0和κ>1来实现视点外推。
这些定标方法还可以应用于时间方向,以便可通过定标运动矢量来提取新帧,从而生成更高帧率的视频序列。
现在,返回上文相对于图1和图3所描述的实施方式,这些实施方式尤其描述了具有视频和补充数据比如深度图的解码器的并行解码结构,所述解码器包含公共信息模块,即,模块110。该模块利用来自信号的由编码器生成的空间信息。常见的例子为在视频数据编码过程中提取的例如还用于深度数据的一组运动或视差矢量。在解码器处,该公共信息用于操纵解码视频和深度数据并向每个解码器支路提供所需的信息,任选用于提取新视点。利用该信息,可以从视频数据中并行提取所有所需视点,例如用于n-视点显示的视点。要在各个编码/解码支路之间共享的公共信息或编码参数的实例如下:
-例如,来自同样用于补充数据的视频数据的公共运动和视差矢量
-例如,来自同样用于补充数据的视频数据划分的公共区块划分结构
-预测模式
-亮度和/或色度信息中的边缘和轮廓数据,例如,亮度区块中的直线。其被用于补充数据非矩形区块划分。该划分被称为楔形波,并以一定角度和位置由直线将区块分为两个区域。
公共信息还可以用作一个解码支路的预测子(例如,视频用预测子)以便在其他支路中细化(例如,补充数据),反之亦然。这可以包括运动矢量或视差矢量的细化,通过视频数据的区块结构初始化补充数据中的区块结构,从来自视频区块的亮度或色度边缘或轮廓信息中提取直线并利用该直线进行楔形波分隔线预测(以相同的角度但在保持所述角度的对应的深度区块中可能不同的位置)。公共信息模块还将部分重建数据从一个解码支路转移至另一个。最后,来自该模块的数据也可以被传递给视点提取模块,其中,提取用于显示的所有必要的视点(显示可以是2d显示、具有两个视点的立体显示、具有n个视点的自动立体显示)。
一个重要方面在于,如果利用上述编码/解码结构来编码/解码一个以上的单对视点和/深度/补充信号,则可以考虑必须在每个时间点t传输一对彩色视点vcolor_1(t)、vcolor_2(t)以及对应的深度数据vdepth_1(t)和vdepth_2(t)的应用场景。上述实施方式建议首先利用传统的运动补偿预测来编码/解码信号vcolor_1(t)。然后,在第二步骤中,对于对应深度信号vdepth_1(t)的编码/解码,可以重新使用来自编码/解码信号vcolor_1(t)的信息,如上所述。随后,来自vcolor_1(t)和vdepth_1(t)的累积信息也可以用于编码/解码vcolor_2(t)和/或vdepth_2(t)。因此,通过共享和重新使用不同视点和/或深度之间的公共信息,可以最大程度地利用冗余。
图3的解码和视点提取结构可选地如图7所示。
如图所示,图7的解码器的结构基于用于颜色和补充数据的两个并行经典视频解码结构。另外,其包括公共信息模块。该模块可以发送,处理并接收两个解码结构中的任何模块的任何共享信息。解码视频和补充数据最终在视点提取模块中进行组合以便提取所需数量的视点。这里,还可以使用来自新模块的公共信息。通过图7的灰框突出显示了新提出的解码和视点提取方法的新模块。
解码过程开始于接收共用的压缩表示或比特流,其包含来自一个或多个视点的视频数据,补充数据以及运动矢量或视差矢量共用的信息,控制信息,区块划分信息,预测模式,轮廓数据等。
首先,对比特流应用熵解码以提取视频和补充数据的量化变换系数,所述系数被馈送至两个独立的编码支路,在图7中的由虚线灰框突出显示,标记为“视频数据处理”和“补充数据处理”。此外,熵解码还提取共享或共用数据并将其馈送至新的公共信息模块。
两个解码支路在熵解码之后类似地操作。对收到的量化变换系数进行定标处理并应用逆变换来获得差分信号(differencesignal)。为此,添加来自时间或相邻视点的事先解码数据。待添加的信息的类型由专用控制数据进行控制。在帧内编码视频或补充数据的情况下,没有先前或相邻信息可用,从而使得应用帧内重建。对于帧间编码视频或补充数据来说,来自时间上在前面或相邻的视点的事先解码数据是可用的(图7中的当前切换设定)。事先解码数据在运动补偿区块中偏移相关的运动矢量并被添加至差分信号以生成初始帧。如果事先解码数据属于相邻视点,则运动数据表示视差数据。通过区块滤波器和可能的增强方法(例如,边缘平滑处理等)对这些初始帧或视点进行进一步处理,以便提高视觉质量。
在改进阶段之后,重建数据被传递给解码图像缓冲器。该缓冲区对解码数据排序并且每次都按照正确的时间顺序输出解码图像。所存储的数据还用于下一处理周期以便作为可定标运动/视差补偿的输入。
除了该单独的视频和补充解码之外,还可使用公共信息模块,其可以处理任何数据,且对于视频和补充数据是共用的。公共信息的实例包括共享运动/视差矢量,区块划分信息,预测模式,轮廓数据,控制数据,以及公共变换系数或模式,视点增强数据等。在各个视频和补充模块中处理的任何数据也可以是公共模块的一部分。因此,存在至公共模块连接和从公共模块至各个解码支路的所有部分的连接。同样,公共信息模块可以包含足够数据,只有一个独立的解码支路和公共模块是必需的以解码所有视频和补充数据。此实例为压缩表示,其中,某些部分仅包含视频数据,其他所有部分包含共用视频和补充数据。这里,视频数据在视频解码支路中被解码,而所有补充数据在公共模块中被处理并被输出至视点合成。因此,在该实例中,没有使用独立的补充支路。同样,来自独立的解码支路的模块的各个数据可以例如以部分解码数据的形式将信息发回公共信息处理模块,以在那里使用或被传输至其他解码支路。一个实例为解码视频数据,如传递给适当的补充解码模块的变换系数,运动矢量,模式或设定。
在解码之后,重构视频和补充数据从独立的解码支路或从公共信息模块被传递至视点提取模块。在例如图3中的110的视点提取模块中,提取用于接收设备,例如多视点显示所需的视点。通过中间视点提取控制来控制该过程,所述中间视点提取控制设定视点序列的所需数量和位置。视点提取的实例是视点合成。如果要在两个原始视点1和2之间合成新的视点,如图6所示,来自视点1的数据可以先移至新的位置。然而,该视差偏移对前景物体和背景物体来说是不同的,因为该偏移与原来的场景深度(照相机的前距离)成反比。因此,在视点1中不可见的新的背景区域在合成视点中变得可见。这里,视点2可以用于填补该信息。此外,可以使用空间相邻数据,例如相邻的背景信息。
作为一个实例,考虑图8中的设定。这里,解码数据由具有颜色数据vcolor1和vcolor2和深度数据vdepth1和vdepth2的两个视点序列组成。应从该数据中提取具有视点vd1,vd2,……,vd9的9视点显示的视点。该显示器经由中间视点提取控制信号告知视点的数量和空间位置。这里,要求9个视点具有0.25的空间距离,从而使得相邻显示视点(例如,vd2和vd3)就空间位置和立体感知而言比比特流中的视点近4倍。因此,这组视点提取因子{κ1,κ2,…,κ9}被设定为{-0.5,-0.25,0,0.25,0.5,0.75,1,1.25,1.5}。这表明解码颜色视点vcolor1和vcolor2的空间位置与显示视点vd3和vd7一致(因为κ3=0和κ7=1)。此外,vd3,vd4及vd5内插在vcolor1和vcolor2之间。最后,vd1和vd2以及vd8和vd9外插在比特流对vcolor1,vcolor2的各侧。根据视点提取因子的设定,深度数据vdepth1和vdepth2被转换为逐像素位移信息并在视点提取阶段相应地被定标以便获得解码颜色数据的9个不同改变版本。
尽管以装置的上下文描述了某些方面,但显然,这些方面也表示相应方法的描述,其中,区块或设备对应于方法步骤或方法步骤的特征。类似地,以方法步骤上下文描述的方面也表示相应区块或相应装置的项目或特征。一部分或所有方法步骤可以通过(或利用)硬件装置,比如微处理器、可编程计算机或电子电路等来执行。在某些实施方式中,最重要的方法步骤中的一个或多个可以利用此装置来执行。
本发明解码多视点信号可以存储在数字存储介质上或可以在传输介质比如无线传输介质或有线传输介质比如因特网上进行传送。
根据某些实现要求,本发明的实施方式可以以硬件或软件来实施。所述实施可以利用其上存储有电子可读控制信号的数字存储介质,例如,软盘、dvd、蓝光光盘、cd、rom、prom、eprom、eeprom或闪存来执行,所述电子可读控制信号与可编程计算机系统协作(或能够与此协作),从而执行各种方法。因此,数字存储介质可以是计算机可读介质。
根据本发明的某些实施方式包括具有电子可读控制信号的数据载体,所述电子可读控制信号能够与可编程计算机系统协作,以便执行本文描述的方法之一。
通常,本发明的实施方式可以被实施为具有程序代码的计算机程序产品,当计算机程序产品在计算机上运行时,程序代码可操作为执行方法之一。程序代码例如可以存储在机器可读载体上。
其他实施方式包括存储在机器可读载体上的用于执行本文描述的方法之一的计算机程序。
换句话说,本发明方法的实施方式由此为一种计算机程序,该计算机程序具有在该计算机程序在计算机上运行时用于执行本文描述的方法之一的程序代码。
因此,本发明方法的另一个实施方式是一种包括记录在其上的用于执行本文描述的方法之一的计算机程序的数据载体(或数字存储介质或计算机可读介质)。数据载体、数字存储介质或记录介质通常是实体的和/或非瞬态的。
因此,本发明方法的另一个实施方式为表示用于执行本文描述的方法之一的计算机程序的数据流或一系列信号。数据流或一系列信号例如可以被配置为经由数据通信连接,例如经由因特网进行传输。
另一个实施方式包括处理装置,例如计算机或可编程逻辑器件,被配置为或适于执行本文描述的方法之一。
另一个实施方式包括其上安装有用于执行本文描述的方法之一的计算机程序的计算机。
根据本发明的另一个实施方式包括装置或系统,被配置为将用于执行本文描述的方法之一的计算机程序传输至(例如,电学地或光学地)接收器。所述接收器例如可以是计算机、移动设备、存储设备等。装置或系统例如可以包括用于将计算机程序传输至接收器的文件服务器。
在某些实施方式中,可编程逻辑器件(例如,现场可编程门阵列)可以用于执行本文描述的方法的一部分或全部功能。在某些实施方式中,现场可编程门阵列可以与微处理器协作以便执行本文描述的方法之一。通常,所述方法优选由任意硬件装置执行。
上述实施方式仅仅用于说明本发明的原理。应理解的是,本文描述的配置及细节的修改和变形对本领域技术人员来说是显而易见的。因此,旨在仅由即将实现的专利权利要求的范围的限定,而不受本文的实施方式的描述和说明的方式表示的具体细节的限定。
- 还没有人留言评论。精彩留言会获得点赞!