基于异步模式的HEVC运动搜索并行方法与流程
本发明属于视频压缩编码领域,特别涉及一种运动搜索并行方法,可用于对视频编码标准hevc的优化。
背景技术:
随着视频应用的多样性和视频高清化趋势,对视频压缩效率的要求越来越高。2010年4月itu-tvceg和iso/iecmpeg联合成立jct-vc联合协作小组,着手开始制定了新一代的视频编码标准h.265/hevc。并确定了hevc的其核心目标是在h.264/avchighprofile的基础上,将压缩效率提高一倍,即在保证相同的视频图像质量的前提下,视频流的码率减少50%。随之带来的是编码复杂度的大幅度提升,普遍认为hevc的编码复杂度是h.264/avc的8倍以上。hevc编码标准的高复杂度使得其编码时间大大提升,远不能达到实时编码,给其应用推广带来了巨大的挑战。为此,如何在不影响图像质量和码率的前提下实现快速编码成为亟待解决的问题。
大连理工大学张维龙在2016年发表的硕士论文“hevc关键模块并行算法的设计与基于gpu的实现”中,针对16x16的预测单元实现了hevc运动搜索算法的cuda优化,该方法在对tzsearch算法做并行优化的过程中,每次只对一个预测单元中的搜索点进行并行计算,而且在优化过程中存在很多分支判断,导致cuda的并行计算量并不是很高。对于1080p的图像平均加速比只有11倍左右。
北京邮电大学徐荣飞在2013年发表的硕士论文“hevc编解码算法的cuda优化”中,对运动估计模块进行了优化,论文在搜索点起始点的选取前一帧lcu中所有分块的运动矢量的平均值,对不同的视频序列采取相同的搜索模板,导致搜索精度有所下降,特别是对运动较为剧烈的视频序列进行编码时,会对图像质量和码率带来较大的影响。
南京邮电大学仝明亮在2014年发表的硕士论文“基于gpu的h.265视频并行编码设计与实现”中,对全搜索算法进行了cuda优化,由于全搜索算法本身搜索点数比快速算法多很多,故在此基础上做并行优化,编码时间并没有得到很好的改善。
技术实现要素:
本发明针对以上问题,提供了一种基于异步模式的hevc运动搜索的并行方法,在对图像压缩效率和图像质量影响较小的情况下,大幅度降低编码时间。
为达到上述目的,本发明技术方案包括如下:
1.一种基于异步模式的hevc运动搜索并行方法,其特征在于包括:
(1)将cpu划分两个线程,即第一线程和第二线程;
(2)第一线程对gpu进行调度,完成最大编码单元lcu内各个预测单元匹配块的并行计算:
2a)获取第二线程在前一帧编码过程中计算的第i-1帧的第n个lcu块的所有预测单元运动矢量的平均值mvi-1(n)与第i-2帧的第n个lcu块的所有预测单元运动矢量的平均值mvi-2(n)的差值△(mvi-1(n)),其中i表示当前帧图像,i-1表示前一帧图像,i-2表示当前帧之前的第二帧图像;
2b)根据差值△(mvi-1(n))的模长d(△(mvi-1(n))),将lcu划分为运动平缓,运动中等和运动剧烈的a,b,c三类,并为不同类别的lcu选择不同的搜索模板,根据lcu的搜索模板再划分gpu线程;
2c)计算lcu搜索点的起始位置:
2d)计算每个搜索位置的lcu块中每个4x4像素块的绝对误差和sad4×4(x,y),其中,x、y分别是运动矢量的水平分量和垂直分量;
2e)通过4x4像素块的绝对误差和sad4×4(x,y)值,计算lcu中各个预测单元pu的绝对误差和sadm×n(x,y)值,其中m、n表示像素块的大小,m、n的取值范围从4到64变化;
2f)将2e)的结果数据从gpu显存中拷贝到cpu内存,并存放到缓存队列中;
(3)第二线程通过缓存队列调用第一线程的结果数据,完成编码器的编码。
本发明与现有技术相比具有以下优点:
1、本发明通过增加起始搜索点的计算和搜索模板的自适应选择,去除运动搜索过程中lcu内各个预测单元的数据依赖关系,实现了lcu内各个预测单元的并行计算,并通过设计cpu多线程实现cpu与gpu计算的异步模式,大幅度降低了编码时间。
2、本发明根据前两帧运动矢量的平均值的差值将lcu划分为运动平缓,运动中等和运动剧烈的a,b,c三类,并根据lcu的运动状态动态为不同类别的lcu选择不同的搜索模板,提高了运动搜索的准确性。
3、本发明根据前两帧对应位置的lcu内的各个pu的运动矢量的平均值确定每个lcu的运动搜索点的起始位置,提高了搜索精度。
附图说明
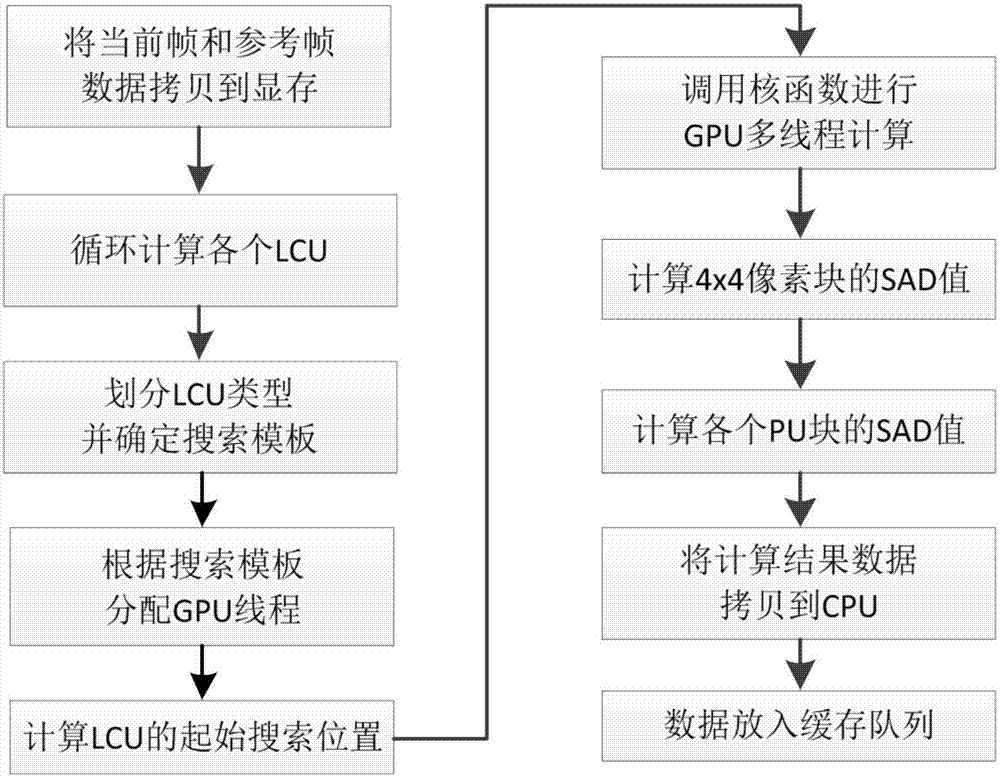
图1是本发明的实现总流程;
图2是本发明中第一线程对gpu进行调度的子流程图;
图3是本发明中运动搜索中对四种基本搜索模板的搜索位置示意图;
图4是本发明中计算各个预测单元绝对误差和的示意图。
具体实施方式
以下参照附图对本发明的实例及效果进行详细的描述:
参照图1,发明的实现步骤如下:
步骤1:将cpu划分为两个线程。
在视频编码过程中,通过c运行时库的_beginthreadex在cpu端开辟两个线程对数据进行处理,即将cpu划分为第一线程和第二线程,其中:
第一线程首先获取当前帧和参考帧信息,并将参考帧信息拷贝到gpu显存,然后将每帧图像划分为互不重叠的最大编码单元lcu,对每个lcu的预测单元进行处理,即计算最大编码单元lcu内各个预测单元的匹配值,执行步骤2;
第二线程作为主线程,通过第一线程调用gpu对运动搜索匹配块进行计算,然后在运动搜索模块调用第一线程的结果数据,进行视频序列的编码,执行步骤3。
步骤2:第一线程计算最大编码单元lcu内各个预测单元的匹配值。
参照图2,本步骤的具体实现如下:
2a)初始化并行计算所需要的运动矢量信息:
首先,获取第i-1帧的第n个lcu块的所有预测单元运动矢量的平均值mvi-1(n);
接着,获取第i-2帧的第n个lcu块的所有预测单元运动矢量的平均值mvi-2(n);
然后,计算mvi-1(n)和mvi-2(n)的差值△(mvi-1(n)):
△(mvi-1(n))=mvi-1(n)-mvi-2(n);
其中i表示当前帧图像,i-1表示前一帧图像,i-2表示当前帧之前的第二帧图像,最后,计算△(mvi-1(n))的模长d(△(mvi-1(n))):
d(△(mvi-1(n)))=|△(mvi-1(n)))|=|mvi-1(n)-mvi-2(n)|;
2b)为不同类别的lcu确定不同的搜索模板,并确定gpu的线程划分:
2b1)根据差值△(mvi-1(n))的模长d(△(mvi-1(n))),将lcu划分为运动平缓,运动中等和运动剧烈的a,b,c三类,并按照如下标准对lcu进行划分:
若d(△(mvi-1(n)))≥0且d(△(mvi-1(n)))<2,则将lcu划分为运动平缓类a;
若d(△(mvi-1(n)))≥2且d(△(mvi-1(n)))<5,则将lcu划分为运动平缓类b;
若d(△(mvi-1(n)))≥5,则将lcu划分为运动平缓类c;
2b2)根据lcu的类别选择搜索模板:
若lcu为a类,则选择a类搜索模板,该a类模板的搜索点集中在搜索起始点附近,搜索点数为λa=100;
若lcu为b类,则选择b类搜索模板,该b类模板的搜索点分布处于a类和c类两种模板之间,搜索点数λb=128;
若lcu为c类,则选择c类搜索模板,该c类模板的搜索点的分布较为分散,搜索点数λc=128。
根据不同类别的lcu搜索模板的搜索点的分布特征,参照图3的四种基本搜索模板的搜索位置示意图,描述a、b、c三类不同的lcu搜索模板的组成,得到搜索模板的搜索点位置分布,如表1所示,其中,图3(a)是4点搜索模板,图3(b)是8点搜索模板,图3(c)是12点搜索模板,图3(d)是16点搜索模板。
表1不同类型的lcu搜索模板中搜索点的分布
2b3)根据搜索模板划分gpu线程:
根据搜索模板的搜索点的个数对gpu线程进行划分,gpu的线程划分包括对线程网格grid的划分和对线程块block的划分,即首先将每个线程网格划分为多个线程块,再将每个线程块划分为多个线程,其中:
对线程网格grid的划分,是将每个线程网格划分为λi*n个线程块,其中λi为lcu搜索点的个数,n为当前帧的参考帧的个数;
对线程块block的划分,是每个线程块划分为16*16个线程,其中每个线程计算一个4x4的像素块的绝对误差和,一个64x64大小的lcu有
2c)计算lcu块的在不同情况下的起始搜索位置mvstart:
若当前帧的前一帧者不存在,即不存在mvi-1(n)的值时,则mvstart=(0,0);
若当前帧之前的第二帧不存在,即不存在δ(mvi-1(n))的值,则mvstart=mvi-1(n);
在其他情况下,
2d)按照如下公式计算lcu中每个4x4像素块的绝对误差和sad4×4(x,y):
其中,m、n均表示像素块的大小,m=4,n=4,fi和fi-1分别代表当前图像和参考图像的像素值,x、y分别是运动矢量的水平分量和垂直分量;
2e)计算lcu中各个预测单元的绝对误差和:
参照图4,本步骤是根据4x4像素块的绝对误差和sad4×4(x,y)值,计算lcu中各个预测单元的绝对误差和sadm×n(x,y)值,其中m、n表示像素块的大小,m、n的取值范围从4到64变化,具体步骤如下:
首先,根据两个相邻的4x4像素块的绝对误差和sad4×4(x,y)值,计算4x8,8x4像素块的绝对误差和,再根据两个相邻4x8像素块的绝对误差和计算8x8像素块的绝对误差和;
接着,根据8x8像素块绝对误差和分别计算8x16像素块和16x8像素块绝对误差和,再根据两个8x16像素块的绝对误差和计算16x16像素块的绝对误差和;
以此类推,计算16x16,16x32,32x16,32x32,32x64,64x32,64x64各个不同尺寸的像素块的绝对误差和sadm×n(x,y)值,得到并行计算的结果数据;
2f)将并行计算的结果数据,即2e)的结果数据从gpu显存中拷贝到cpu内存,并将结果数据存放到缓存队列中。
步骤3:第二线程利用第一线程的结果数据,进行编码。
第二线程作为主线程,首先将运动搜索模块的匹配值的计算交由第一线程进行计算,接着在编码过程中运行到运动估计时,调用第一线程的结果数据,进行编码。
本发明的效果可以通过以下实验进行进一步说明:
1.实验条件和对象:
硬件仿真平台cpu处理器是intel(r)core(tm)i3-3220@3.30ghz,操作系统是64位的windows10,gpu型号是nvidiageforcegtx960,开发工具是microsoftvisualstudio2013和cuda7.5;
本实验采用hevc测试模型hm16.6,选用配置文件encoder_lowdelay_p_main.cfg,其中,令fen=0、amp=0,对运动搜索并行方法和原始算法进行测试。
2.实验内容和结果:
用本发明方法和现有的原始算法分别对四种不同分辨率的多组视频序列进行测试,测试结果如表2。
表2基于异步模式的hevc运动搜索并行方法实验结果
表2中,y-psnr表示本发明的y分量的峰值信噪比与原始算法的差值,码率(%)表示本发明方法的码率与原始方法的差值与原始方法比值,加速比表示本发明方法与原始方法的比值;
从表2可以看出,本发明与原始算法进行比较,峰值信噪比y-psnr平均降低了0.029db,码率平均提高1.627%,平均速度提高了18.465倍。
实验结果表明,本发明在对图像质量和码率影响很小的情况下,取得了很好的模块加速比。
- 还没有人留言评论。精彩留言会获得点赞!