可容错的专用片上网络拓扑生成方法与流程
本发明属于soc领域,具体涉及一种可容错的专用片上网络拓扑生成方法。
背景技术:
随着半导体工艺的提高和晶体管尺寸的不断减小,未来单个芯片可集成的晶体管个数越来越多。这就意味着,在一个芯片上可以集成成千上万个ip核,并且这些ip核可以是cpu或者dsp核,io端口,内存等等。但是随着单个芯片中包含的ip核数量的不断增加,基于总线架构的片上系统设计(system-on-chip,soc)面临着存储带宽,互连延迟,功耗和可靠性等方面的巨大挑战。因此,随着片上网络(network-on-chip,noc)的出现有效的解决了soc的困境,为ip核之间提供高效,高吞吐量,低功耗的通信。
noc的结构中有规则的和非规则的,规则的结构具有容易构造,可重构等优势,但是对于一些具体的应用时不能够得到最优的设计成本,造成了资源的大量的浪费。对于非规则的拓扑结构在对于专用的片上网络的设计时,能够使得功耗和面积大幅度的少于规则的拓扑结构,现在大量的研究者对于noc的研究都集中在规则的情况下去优化功耗和容错方式,所以在遇到具体的应用时可能造成资源的大量的浪费。
对于专用片上网络的专用拓扑结构的产生,大量的研究者仅仅考虑的是在相应的功耗模型下的怎么样使功耗模型最小的情况下生成专用的拓扑结构,但是他们所生成的专用拓扑结构仅仅都只有一条交流路径,如果结构中一个路由节点或者链路的错误会使得整块芯片无法正常的工作,而随着一块芯片上面所集成的处理器的不断增加,节点和路由错误的可能性大幅度的增加,所以怎么样在添加最小成本的情况下生成可容错的专用片上网络拓扑结构是本发明研究的重点。
技术实现要素:
本发明的目的在于提出一种可容错的专用片上网络拓扑生成方法,通过可容错拓扑生成算法生成可容错拓扑结构集,然后根据生成的可容错拓扑结构集对任务流程图tg(n,v)进行分簇,最后根据分簇的结果将任务图tg(n,v)中的任务节点ni∈n映射到可容错拓扑结果中去,并选择功耗最小的可容错的专用片上网络拓扑结构。本发明的目的在于设计一个可容错的专用片上网络拓扑生成方法,该方法不仅可以容忍专用片上网络的路由链路错误,还可以降低功耗和面积的减少,同时利用分簇的方式来对专用片上网络的映射进行预处理还可以降低映射算法的时间和空间复杂度减少开发周期和成本。
本发明通过如下技术方案实现。
一种可容错的专用片上网络拓扑生成方法,包含步骤:
(1)根据任务图中的任务节点个数和周围路由端口数,通过添加链路和路由的容错拓扑生成算法生成可容错的专用片上网络拓扑结构集;
(2)根据(1)中所述的可容错的专用片上网络拓扑集对任务图tg(n,v)中的任务节点进行分簇;
(3)根据(2)中分簇结果,将任务图中的各个节点映射到(1)中生成的可容错拓扑结构集中去并通过功耗分析模型对可容错拓扑结构集进行分析,得到最优功耗的可容错拓扑结构;
上述方法中,所述步骤(1)中包括:
(1.1):根据任务图tg(n,v)(为一个非循环有向图,ni∈n表示一个任务节点,vi,j∈v表示任务节点i,j之间的通信量大小)中的任务节点总数n和周围路由的端口数量p确定周围路由数量范围[rmin,rmax];
(1.2):根据(1.1)中的周围路由的端口数量范围,在周围路由个数为rmin的情况下生成不能容错的专用片上网络拓扑结构;
(1.3):在周围路由的个数小于等于rmax的情况下,通过增加周围路由的个数和链路数使得(1.2)中的不能容错的专用片上网络拓扑结构变为可以容错的专用片上网络拓扑结构集;
(1.4):根据网络中的最小路径定理计算(1.3)中生成的所述可容错的专用片上网络拓扑结构集中的每个拓扑结构的平均最小路径值并统计每个拓扑结构的路由数量,得到平均最小路径值和路由数量最小的两个可容错拓扑结构。
上述方法中,所述步骤(2)中包括:
(2.1):根据周围路由的端口数p和(1.4)中所述的可容错拓扑结构,得出需要簇的数量和每个簇中任务节点的数量;
(2.2):根据任务图tg(n,v),将任务图中的每个任务节点ni∈n与它相邻的节点组成一个簇,得到k个簇(c1,c2,c3,……,ck);
(2.3):对(2.2)中得到的k个簇,计算所述k个簇中任务节点之间的通信量总和w,并将k个簇按照w进行降序排序,得到从大到小排列的w集合w;
(2.4):根据(2.3)中所述的集合w,选取w中的第一个w对应的簇ci(其中i<k),删除剩下的k-1个簇中与簇ci中有相同任务节点的那些任务节点,以此类推直到每个簇中的任务节点数都不相同;
(2.5):将(2.4)中的结果进行处理,重新计算各个簇内部的各个节点的通信量总和并根据降序方式进行排序,直到处理后的结果满足(2.1)中的簇个数和每个簇中的任务节点数量。
上述方法中,所述步骤(3)中包括:
(3.1)根据步骤(1.4)得到的可容错拓扑结构,将任务图tg(n,v)中的任务节点按照步骤2的分簇结果映射到可容错拓扑结构中去;
(3.2)对(3.1)中的结果进行功耗分析,得到功耗最小的可容错的专用片上网络拓扑结构。
与现有技术相比,本发明的优点和积极效果在于:
1.本发明提供的可容错的专用片上网络拓扑生成方法,当某个路由链路出现错误时,可以选择其它的传输路径来进行通信,提升了芯片的可容错性。
2.相对规则拓扑结构,本发明下生成的拓扑结构路由开光的数量明显减少,从而使得该结构具有更少的芯片面积和延迟的减少。
3.本发明根据生成的可容错拓扑结构进行分簇处理后进行任务节点的映射,使得映射算法的复杂度降低。
附图说明
图1为本发明实施方式中的设计流程框图。
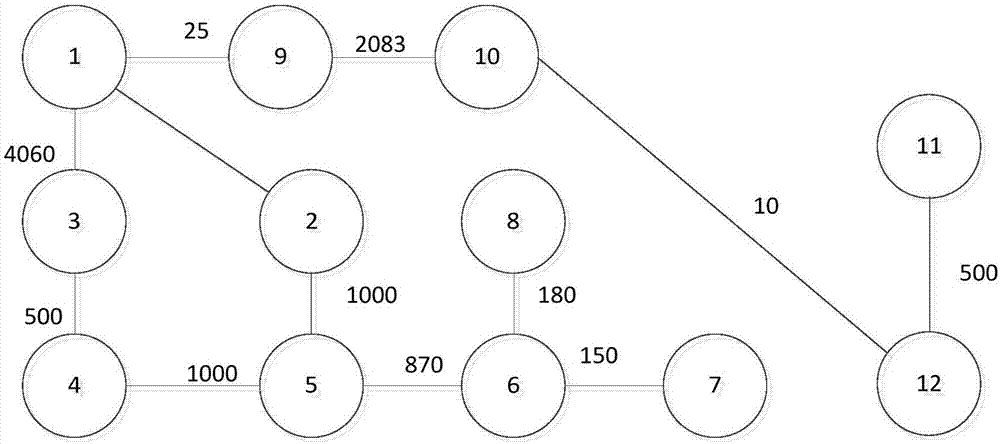
图2a为本发明实施方式中的任务图;
图2b为图2a分簇后的任务图。
图3a为本发明实施方式中的非容错拓扑结构图;
图3b为图3a的可容错拓扑结构图。
图4为本发明实施方式中的最终映射图。
具体实施方式
下面结合附图对本发明的具体实施方式作进一步说明,但本发明的实施和保护不限于此。如图1,本发明的具体实施步骤如下:
步骤一,生成不可容错的拓扑结构;
步骤二,通过可容错拓扑生成算法将不可容错的拓扑结构生成为可容错拓扑集;
步骤三,根据所述的可容错拓扑结构集对任务图tg(n,v)进行分簇;
步骤四,根据分簇情况把任务图tg(n,v)中的任务节点映射到可容错拓扑集中去,选出功耗最低的可容错的专用片上网络拓扑结构。
其中步骤一的具体实施为:
1.生成不可容错的拓扑结构图。
根据周围路由的端口数量p和如图2a所示的任务图tg(n,v)中的任务节点的数量n=12和路由端口数量p=4我们可以根据公式(1)得出无容错情况下的最小周围路由数量为rmin=4,
得到无容错的拓扑结构如3a所示,其中如果任何一个周围的链路或者路由出现错误,都会导致芯片不能正常的工作。
其中步骤二的具体实施方式:
1.生成可容错的拓扑结构
增加周围路由的数量和链路的数量使不能容错的拓扑变为可以容错的拓扑结构,其中增加路由之后,总的周围路由数量为r,增加的链路数为l分别为:
通过最短平均路径定理计算拓扑结构集中的每个生成的拓扑结构的平均路径值ap:
其中r为拓扑结构中所有路由数量总和,d(ri,rj)为拓扑结构中ri,rj路由之间的最短路径所经过的路由个数,从而根据公式(4)得到ap最小的可容错拓扑结构如图3b所示。
其中步骤三的具体实施方式:
1.根据所述的可容错拓扑结构对任务图进行分簇
(1.1)如图3b所示的可容错拓扑结构图,根据公式(5)可知所需簇的数量为6,每个簇中的任务节点数量为c=2;
|c|<=p-2(5)
(1.2)对图2a所示的任务图tg(n,v),根据公式(6)计算每个任务节点与它相邻的任务节点之间的通信量总和w,所以得到12个有不同大小w的簇,并将得到的12个簇按照w从大到小进行排序;
(1.3)从(1.2)中排好序的12簇中,选择w最大的簇,删除其它11个簇中与w最大的簇中相同的任务节点,以此类推,直到得到的簇的数量和每个簇中的任务节点数量分别为6和2,结果如图2b所示;
其中w为在节点ni≠nj(i,j为节点的编号且都小于等于n)的条件下,任务图tg中节点ni与自己相连节点nj的通信量之和wi,j。
其中步骤四的具体实施方式为:
1.设定映射过程中的功耗模型。
将erbit设定为周边单个路由功耗,elbit为链路的功耗,
所以整个可容错拓扑结构的总功耗为
2.将任务图映射到可容错拓扑中去。
根据步骤三种对任务图tg(n,v)分簇得到的6个簇,将每个簇映射到如图2.b所示的可容错拓扑结构中去,并通过模拟退火算法不断改变每个簇在所述拓扑结构中的位置,得到总功耗最小的映射结果图,如图4所示。
本发明应用在专用片上网络的设计中,可确保设计出来的专用片上网络不仅具有可容错功能,还具有更低的包延迟,丢包率,降低soc设计的面积和功耗。
- 还没有人留言评论。精彩留言会获得点赞!