假冒学术期刊网站的检测方法与流程
本发明涉及网站检测领域,特别是一种假冒学术期刊网站的检测方法。
背景技术:
计算机的出现以及计算机技术的快速发展,使人们的生活方式发生了翻天覆地的变化。尤其互联网(internet)的蓬勃兴起,已经成为当今世界推动经济发展和社会进步的重要信息基础设施,互联网这条高速信息公路能够清楚地把整个世界的面貌都呈现在我们眼前,给人们生活带来了极大的方便。与此同时,也给网络犯罪提供了平台。钓鱼者通过各种钓鱼手段,在各个领域都设计出来相关的假冒网页,而且钓鱼手段越来越成熟,越来越高明。
近年来,通过计算机来欺骗用户的事件相继出现,其中利用网络钓鱼(phishing)进行犯罪的现象迅速增加,给个人用户、企业乃至社会经济造成严重的损害,给社会信任带来了严重的挑战,使网络环境日益恶化。基本上各行各业都会遭受网络钓鱼的攻击,网络钓鱼是指欺诈者在网络上以授权机构的名义窃取用户隐私信息的行为。phishing攻击者将用户引诱到一个通过精心设计的,与目标组织非常相似的web页面,通过进入假冒网站的用户进行注册、登录等操作来获取个人重要信息。钓鱼网站已经渗透到了学术期刊投稿领域,在网上输入任何一本期刊的刊名,搜索结果便会出现三五个该刊的投稿网站,其搜索结果中只有一个为真实的学术期刊投稿网站,其余的都是假冒的投稿网站,然而目前在这一领域还没有有效的防钓鱼网站系统,所以积极研究学术期刊假冒网站攻击检测技术是非常有必要的,本发明根据这网络现象,结合研究人员在其它领域的反钓鱼研究,在学术期刊网站检测这一领域,提出一种假冒学术期刊网站检测技术,来有效保护用户隐私,维护学术社区的秩序。
现有的检测方法主要有以下几类:①基于黑名单或白名单技术,基于黑名单检测技术是在商业、各政府部门最常见的一种反钓鱼方法,也是使用时间最长的一种检测方法。黑名单技术是指通过手动的发现假冒网址,然后把这些假冒的url存入到一个黑名单库中。当用户访问网址时,访问网址的url就会和黑名单库中的url进行对比,如果找到一样的域名链接,就可以判断该链接为假冒网页,并向用户发出提醒。②基于视觉图像匹配的钓鱼识别。该方法通过对网页图像进行分割、提取和计算并获得可疑网页与受保护网页直接的视觉相似度,最终完成钓鱼页面的检测判定,但该方法主要针对风格布局等比较相近的网页。③基于链接分析的钓鱼检测技术,基于链接分析的钓鱼检测技术是一种实时在线的一种学习算法,一旦用户访问网页时,浏览器就会马上提取网页的特征值,然后与合法的网页特征值做一个比较,然后判断其真假性。
上述现有技术中:①基于黑名单或白名单技术,对所访问网址进行过滤。黑白名单检测技术的准确率较高,不容易出现误报等情况,但由于钓鱼网站的更新速度很快,存活时问较短,因此,黑白名单技术必须要实时更新名单库,但这样做的难度很高。②基于视觉图像匹配的钓鱼识别。该方法主要针对风格布局等比较相近的网页,对于布局差异较大的假冒网页检测,则显得力不从心。③链接分析的检测技术的优势在于,不需要去实时的去更新黑名单库,所以在访问网不需要消耗大量的网络带宽,但是缺陷在于,该方法的判断网页的真假性的准确率却大大降低。
技术实现要素:
本发明旨在提供一种假冒学术期刊网站的检测方法,提高对真假学术期刊网站的判别率。
为解决上述技术问题,本发明所采用的技术方案是:一种假冒学术期刊网站的检测方法,包括以下步骤:
1)筛选出所有真假学术期刊网站,区分真假学术期刊网站;
2)提取真假学术期刊网站的url、域名和网页内容特征,并统计和分析真假学术期刊网站的url、域名和网页内容特征,通过比较各特征值在真假学术网站中的差别,选择区分真假学术网站的特征值;
3)利用支持向量机算法对选取的学术期刊网站特征值进行处理,训练出svm分类器;
4)通过训练的分类器,提取测试样本的特征值,作为决策函数的输入量,根据函数结果,判断学术期刊网站的真假性。
步骤1)的具体实现过程包括:
a)以各期刊名为关键字,通过爬虫程序,获取排列前一千名的搜索结果,记录搜索结果的url地址、标题、摘要、名次排列和搜索结果总数;
b)对于任一搜索结果,分析比较url地址的标题与其期刊名,如果url的地址标题的字符长度与期刊名的字符长度差超过八个字符,直接去除该搜索结果;
c)在经步骤b)处理后剩下的搜索结果中,通过这些搜索结果的url地址来获取网页的内容,判断获取的网页内容中是否含有投稿指南和表单提交信息,如果都没有,直接删除该获取的网页内容对应的搜索结果;
d)点击经步骤b)和步骤c)处理后剩余的搜索结果的url地址链接,区分真假学术期刊网站。
步骤2)中,url特征包括url的长度、url中的域名、url中的特殊字符“@”、url中点的数目以及url地址的网络端口号。
步骤2)中,域名特征包括网站的所有者、网站所有者的邮箱、网站的注册日期和到期日期。
步骤2)中,网页内容特征包括网站中含有的空链接的数量、网站中含有链接总数量、网站指向外部域名链接的数量、网站指外部请求的数量、网站中所有请求数量和网站中的联系方式。
步骤4)的具体实现过程包括:输入测试样本的特征值,根据决策函数来判断网页的真假性,如果决策函数的输出结果为1,就为真实的学术期刊网站,决策函数的输出结果为-1,则为假冒的学术期刊网站。
与现有技术相比,本发明所具有的有益效果为:
(1)现有技术都是使用布尔型数据来对特征值进行赋值,而本发明主要利用给每个特征值赋予不同的权值,这样就可以提现每个特征值在真假学术网站中的重要程度。
(2)本发明使用支持向量机,而现有技术都是使用神经网络等方法进行分类,而对于二类分类来说,使用支持向量机比其它方式都具有突出的优势。
附图说明
图1为url特征量在真假网址中出现次数对比。
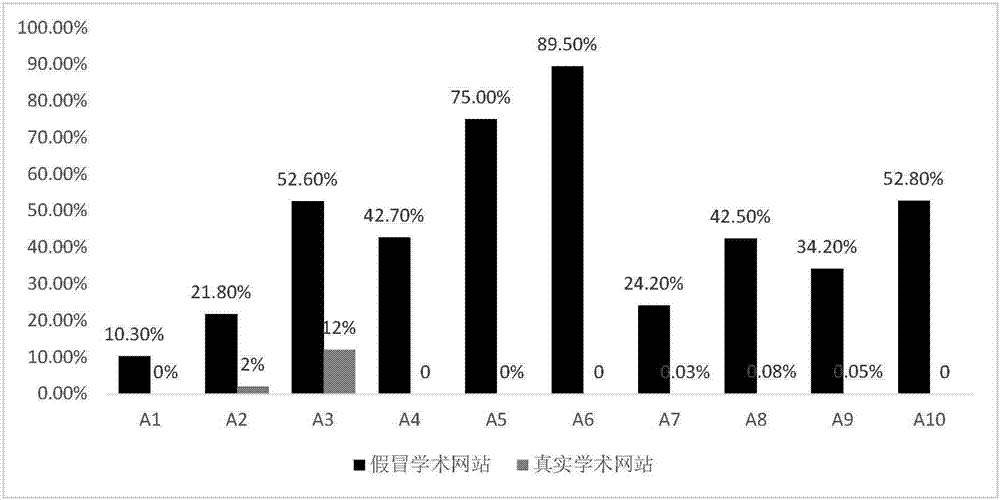
图2为网站中各特征值在真假学术期刊网站中出现的比例;
图3为半监督学习的分类器训练模型示意图;
图4为假冒学术期刊网站的检测流程图。
具体实施方式
本发明通过对国内外反钓鱼检测技术进行了研究与分析,结合学术期刊投稿网站的特征,提出了一种学术期刊假冒网站检测的方法。本发明首先通过使用期刊刊名为关键字,爬取到所有真假投稿网站的url,然后通过解析工具和whois查询获取网页内容特征和域名信息特征,并结合网站url特征,通过分析真假投稿网页各特征的区别,提取明显能区分真假网站的特征,再利用svm分类学习算法训练分类器,最后利用分类器对学术期刊投稿网站进行分类。
下面结合附图和实施例,进一步描述发明的具体实现过程:
(1)图1为url特征量在真假网址中出现次数对比。本发明主要提取真假学术期刊网址url中含点的个数、网络端口号和含特殊字符“@”等。在提取这些特征后,统计这些特征在真假网站中出现的次数。使用符号a1表示在真假学术期刊网址样本中使用ip地址作为网站url地址中的一部分的个数,使用符号a2表示在真假学术期刊网址样本url地址中包含点“.”的个数超过4个的个数,使用符号a3表示在真假学术期刊网站样本url地址中网络端口号不是80端口的个数,使用符号a4表示在真假学术期刊网站样本url地址中含有特殊字符“@”的个数。通过比较真假学术期刊网站各url特征值之间的区别,a1和a4这两个特征,只在假冒学术期刊网站中出现,而a2特征绝大多数在假冒网站中出现,小部分在真实学术期刊网站中出现,对于a3,在图中,可以看到,在真假学术网站中出现的次数差不多,所以该量对判断真假网站没有很大的作用,所以选择a1,a2和a4特征作为区分真假学术期刊网站的特征量。
(2)提取合适特征值,主要有以下特征值
4个url地址特征值:
2个域名信息特征值:
4个网页内容特征:
空链接数量的比例:
外部链接的比例:
指向外部请求比例:
其中,空链接的数量比例是指,网站中空链接的总数与网站所有链接数量的比例,如果比例小于0.5,则赋值为1,否则为零;外链接的比例是指网站的指向外部域名的链接数量与网站的链接数量的比值,如果比例小于0.5,则赋值为1,否则为零;外部请求比例是指网站中外部请求的数量与网站中所有请求数量的一个比值,如果比例小于0.5,则赋值为1,否则为零。
(3)图2为网站中各特征值在真假学术期刊网站中出现的比例,a1-a9表示各特征值在真假学术期刊网站中出现的比例,在图中可以看到,每个特征值在真假期刊网站中出现的比例都不相同,其中a6比例最大,表示为有效期的时间未超过12个月的网站所占的比例,所占a1比例最少,表示在使用ip地址作为网站url地址中的一部分在真假学术期刊网站所占的比例。为了区分这些特征值在真假网站中出现比例的不同,本发明通过计算各特征值的权值,来体现每个特征值在检测时的重要程度。
(4)图3为半监督学习的分类器训练模型示意图,要想设计一个分类器理想的分类器,就必须对分类器设定一个学习阈值,然后在人工监督下进行学习,如果样本的阈值不在分类器的学习阈值内,那么就要人工的去修改样本的一些特征量,最后达到高效的分类目标。利用支持向量机构造分类的算法如下:
①选择合适的核函数,本发明用的核函数为高斯核函数,并要给核函数参数初始化;
②遍历样本的所有记录;
③利用高斯函数,将选取合适样本的特征量映射到高维的空间中;
根据决策函数来进行计算,公式如下:
④如果分类效果非常好,就结束以上操作,如果分类产生的误差很大,就必须修改样本的特征量,重复③和④的步骤。
(5)图4为假冒学术期刊网站的检测流程图,通过构造合适的分类器,对学术期刊网站进行分类,步骤如流程图所示:
①访问学术期刊网站。本发明主要针对学术期刊网站这一领域,所以检测样本的都是学术期刊网站。
②提取网站的部分特征值。主要是提取网站是否有提交表单这个特征值,如果网站有提交表单这一项,这继续下一步检测,如果没有,则结束检测。对于没有提交表单的网站,检测其真假性无任何意义。
③提取学术期刊网站的特征值。主要包括url特征、域名特征和网页内容特征。
④计算各特征值的权值,统一表示成向量的形式。通过图1可以知道,通过计算各特征值的权值,来体现每个特征值在检测时的重要程度。
⑤判断学术期刊网站的真假性。根据图2中构造的分类器,来判断网站的真假性。
⑥返回结果。输入测试样本的特征值,根据决策函数来判断网页的真假性,如果决策函数的输出结果为1,就为真实的学术期刊网站,决策函数的输出结果为-1,则为假冒的学术期刊网站。
(6)本发明使用权值代替了传统使用布尔型数据对特征值进行赋值,提高了对网站的识别能力,降低了误判率。
对网页url、域名信息以及网页内容的特征值提取和分析做了详细的说明,这部分主要对这些特征值赋予一定的值,在支持向量机算法中,都会常使用布尔型值来表示,比如:
或者是
使用布尔型的值来表示特征值,这种方法的确很简单,也很理解,但是却忽略了一个重要的问题,即各个特征值的重要程度。在这些特征中,不是每个假冒学术期刊网站都会出现,也不是所有的真实学术期刊网站这些特征值都是符合要求,还有一些分类特征一确定就可以判断出来网页的真假,比如网页的有效期,如果有效期在2年以上,就可以完全判断该网址为真实网站,如果该网址的有效期在一年以内,就完全可以判断该网址为假冒网站,所以每个特征值的重要程度取决于它们在真假网站中存在的差异有多大,差异越大,重要程度越高,反之,重要程度就越低。
由于布尔型值的缺陷,本发明推出用权值来表示特征向量的值,这样就可以体现各个特征值在检测时的重要程度,例如,如果某个特征值只在假冒学术网站中出现,那么该特征值的权值就表示为1,这表示非常重要,如果某个特征值在真假学术网站中出现的概率一样,那么该特征值的权值为0,这一种特征值对区分真假网站的没有帮助,其余的情况,都是出现在真假网站的比例来确定。
用np表示假冒学术期刊网站样本的数量,用npi表示第i个特征向量在假冒学术期刊网站中的比例。
用pp表示真实学术期刊网站样本的数量,用ppi表示第i个特征向量在真实学术期刊网站中的比例。
通过上面的表示,就可以用下面的公式来表示第i个特征向量的权值,即:
由上面的表达式我们可以看出,当假冒网站的数量为0时,其权值都为1,同理,当真实的网站数量为0时,其权值为1,如果某个特征值只在真网站出现而不在假网站出现或者只在假网站出现不在真网站出现,其权值同样也为1,如果某个特征值在真假网站中出现的次数一样,那么其权值为0,由上面可以知道,要想得到权值,就必须知道真假网页的数量,以及每个特征值在真假网页中出现的次数。
(7)本发明使用支持向量机作为分类的方法,主要是因为本发明样本只有两种,要么为假冒学术网站,要么为真实的学术期刊网站,所以使用这种方法对分类具有很明显的优势。
支持向量机可以分为线性支持向量机和非线性支持向量机两种:
①线性向量机。主要是指能够把样本利用一条直线y=w.x+b完全分割开来,并且利用符号函数sgn(y)来判断样本为哪一类。
在两种不同的样本中,能够找到一条直线把不同的两种样本分割开来,然后往上移和下移这条直线,使得上移的那条直线使得样本的一些点第一次落在这条直线上w.x+b=1,往下移的直线同样要使得另一类样本中的某些点第一次落在这条直线上w.x+b=-1,由于这样的平行直线划分存在很多,为求最优的直线,就要使这两条直线的距离相差最大,这样就可以把样本高效率区分开来。
由直线w.x+b=1和w.x+b=-1可以知道,这两条直线的之间的分类间隔为
由上面可以知道把样本分成两类的函数表达式为:
设训练集
t={(x1,y1),(x2,y2),......,(xi,yi)}∈(x,y)
其中xi∈x∈r,yi∈y∈{1,-1},i=0,......l
可以把(2)式化为
yi(w.xi+b)≥1,yi={1,-1}i=1,…l(3)
同时(3)作为(1)的约束条件,其中l是指有l个约束条件。要想求(1)的最值问题,由于目标函数w是一个二次函数,而约束条件中的w是一次函数,这样的问题就是一个二次规划问题,对于一个二次规划问题,就一定有一个全局最优解,为求最优解,就要引入lagrange函数:
然后对(4)中的w和b求偏导并且令都等于零得到:
将式(5)、(6)代入式(4),就可以把上述最优分类问题转化成其对偶优化问题,通过化简后得:
约束条件为:
对原问题求最值,最终转化对对偶中的α求最小值,由式(4.7)和式(4.8)可以得到一个最优解α*,那么就可以得到最优解w*。
并选择α*的正分量,也就是指只有点在超平面上时αi才为正数,其余的时候αi为零,由此可以得出b*。
求解上述问题后,得到的最优分类函数为:
②非线性支持向量机。是指对样本不可以线性分开,也就是说在w.x+b=1上方的点可能还存在在直线w.x+b=-1下方的点,或者反过来,总而言之,就是线性不可分,为求解这种情况,就要引入松弛变量来“软化”约束条件,把上述的式(3)转化为:
最优化问题就可写成:
其中c为误差权重,起主要是控制松弛变量,当松弛变量大的时候,c就比较小,反之,c就比较大,把上述最优分类问题转化成其对偶优化问题,通过化简后得:
约束条件为:
对于非线性问题,可以通过非线性转化为某个高维特征空间中的线性问题,在变换空间中求最优分类面,对于这种方法,实现比较困难,因此就要原特征向量用映射的方式转成:
xi→φ(xi)
则式(11)中的xi·xj转换成:
xi·xj→φ(xi)·φ(xj)
由上可以知道,将输入空间的样本映射到高维的(也有可能是无穷维)的特征空间中,在高维的空间中构造最优平面时,训练算法仅用特征空间中的内积,因此如果能找到一个函数k使得:
k(xi·xj)=φ(xi)·φ(xj)
这样,在高维特征空间实际上只需进行内积运算,而这种内积运算可以输入空间中的函数实现,甚至没有必要知道变换φ的形式,根据泛函的相关理论,只要有一种核函数满足条件,它就对应某一变换空间中的内积,所以可以把式(11)转化为:
因此,总个问题就转化为把(12)这个求最优解。
- 还没有人留言评论。精彩留言会获得点赞!