基于强化学习的多路径传输协议拥塞控制方法与流程
本发明涉及拥塞控制领域,具体涉及一种多路径传输协议拥塞控制方法。
背景技术:
传输控制协议(transmissioncontrolprotocol,tcp)是一种面向连接的、可靠的、基于字节流的传输层通信协议。网络中有95%的流量来自于tcp连接,tcp连接的两端一般使用一条路径来传输数据。而随着多种接入技术的发展,现如今大多数的主机都配置有多个网络接口,也可以通过usb接口来扩展网络接口。而且智能移动终端越来越普及,它们也往往都同时具有蜂窝网络接口(如3g接口、4g接口)和wifi两种接口。传统tcp协议只能将每个连接绑定到单个接口,因此不能有效利用现今设备的多个接口,这将会造成大量的资源浪费。近年来,ietf工作组提出了对传统tcp协议的扩展协议,多路径tcp(multi-pathtcp,mptcp)。mptcp将单个tcp的数据分流到多个不同的子流,每一条子流会走不同的路径,从而形成多条链路。这样就可以充分利用设备的多个网络接口,实现最大的吞吐量和鲁棒性。
网络中的拥塞现象是由于通信子网中某一部分的分组数量过多,使得该部分的网络来不及处理,以致引起这部分乃至整个网络性能下降的现象,严重时甚至会导致网络瘫痪。拥塞控制就是防止过多的数据注入网络,这样可以使网络中的路由器或者链路不会过载。mptcp的拥塞控制机制决定在每个子流上发送多少数据,这样做的目的是将流量从比较拥挤的路径转移到不那么拥塞的路径上,从而提高吞吐量。链接增长算法(linkedincreasesalgorithm,lia)是mptcp的默认拥塞控制算法,在多路径速率分配时,综合考虑了丢包率和往返时间(roundtimetrip,rtt)。但是由于mptcp需要收到各个子流的数据并排序后才能上传到应用层,所以当mptcp的子流之间速率差异较大时,快子流需要“等待”慢子流的数据,如果慢子流的数据迟迟不来,而快子流的数据不停地到达,则容易造成接收端的缓冲区溢出,从而导致来自快子流的数据包也可能被丢弃,使得网络性能下降。
技术实现要素:
发明目的:正是基于以上的原因,本发明提出一种基于强化学习的多路径控制协议拥塞控制方法。通过在网络环境中进行反复学习,得到一组对应于该网络的从状态到动作的映射表,从而使得网络设备知道在不同网络状态下如何改变窗口大小以获得最好的性能。
技术方案:一种基于强化学习的多路径传输控制协议拥塞控制方法,应用于多路径传输控制协议中,包括以下步骤:
1)建立拥塞控制的马尔可夫模型,具体包括:
设置
设置{m,b,r}作为发送端的动作,m为对当前拥塞窗口的乘数,b为对当前拥塞窗口的加数,m和b都是用于调整当前拥塞窗口大小,r为发送子流的时间间隔,通过调节发送间隔以达到调节发送速率的目的;一般设置为m={0,0.1,0.5,1,2},b={0,+/-1,+/-4,+/-8},r={+/-0.01,+/-0.08,+/-0.64};
为了使平均吞吐量最大化并且使各个子流的平均时延最小化,设置
2)对网络环境采样,得到马尔可夫模型的状态参数;
3)根据状态参数对马尔可夫模型进行迭代训练,得到从状态到动作的映射表;
4)在网络中应用状态-动作映射表,具体为:从拥塞避免阶段开始,发送端每收到一个确认,就计算当前的状态,然后在状态-动作映射表中找到对应的动作并执行该动作。
其中,所述步骤3)具体包括以下步骤:
31)将状态空间划分为多个区域,并设置默认动作;
32)对所有状态区域应用默认动作,找出状态最常出现的区域,作为待优化状态区域;
33)对待优化状态区域应用所有动作,选择使目标方程值最大的动作,形成状态-动作映射规则,并添加到状态-动作映射表中;
34)按照以下原则继续寻找待优化状态区域:对未经优化的区域应用所有动作,对优化过的区域应用前次优化所得到的动作,然后找出状态最常出现的区域,作为待优化状态区域;如果找到的是已经优化过的区域,则将该区域进一步划分,然后再次按照上述原则选取待优化区域;
35)重复执行步骤33)-34),直到状态区域的数目达到指定阈值为止。
在以上过程中,本发明的方法选取状态最常出现的区域作为待优化状态区域,这样可以着重优化经常会用到的规则。这种策略更有针对性,能够提高效率,节省时间。并且在选取待优化状态区域时,利用了前一次优化的成果,可以更快地逼近最优解。这体现了强化学习的思想。
工作原理:强化学习是机器学习的一个分支,是指智能系统从环境到行为映射的学习,以使奖励信号函数值最大。强化学习通常用马尔可夫决策过程(markovdecisionprocess,mdp)来描述。如图1所示,机器处于环境e中,状态空间为x,其中每个状态x∈x是机器感知到的环境的描述,机器能够采取的动作构成了动作空间a,若某个动作a作用在当前状态x上,则转移函数p将环境从当前状态按某种概率转移到另一个状态,同时根据奖赏函数r反馈给机器一个奖赏。强化学习的目的就是求解马尔可夫决策过程mdp。简单地说,mdp就是一个机器采取行动从而改变自己的状态并获得奖励与环境发生交互的循环过程。mdp的策略完全取决于当前状态,这体现了它的马尔可夫性质。
本发明通过建立马尔可夫决策过程,将拥塞控制形式化表示。用发送端的各个子流的拥塞窗口大小以及各个子流的rtt来表示各个子流当前的网络状态,定义发送端调整拥塞窗口和发送间隔的动作,建立目标方程,以获得最大平均吞吐量和最小平均时延为目的。通过建立网络模型,模拟产生多种网络环境。在不同的网络环境中,通过不断地试错,对当前网络环境做所有的动作,然后从环境给出的反馈中学习并优化动作。经过大量的线下学习,使得发送端可以在某一个状态区域做出相应的调整拥塞窗口大小和发送间隔的动作,以使得目标方程的值最大。
有益效果:本发明利用马尔可夫决策过程实现多路径传输控制协议的拥塞控制,该方法以最大平均吞吐量和最小平均时延为目标,通过感知环境状态来学习动态系统的最优策略,不仅克服了现有技术中丢包的缺点,而且具有速度快,稳定性高,鲁棒性强等优点。并且对环境的先验知识要求低,非常适合于应用到实时网络环境中。
附图说明
图1为强化学习原理示意图;
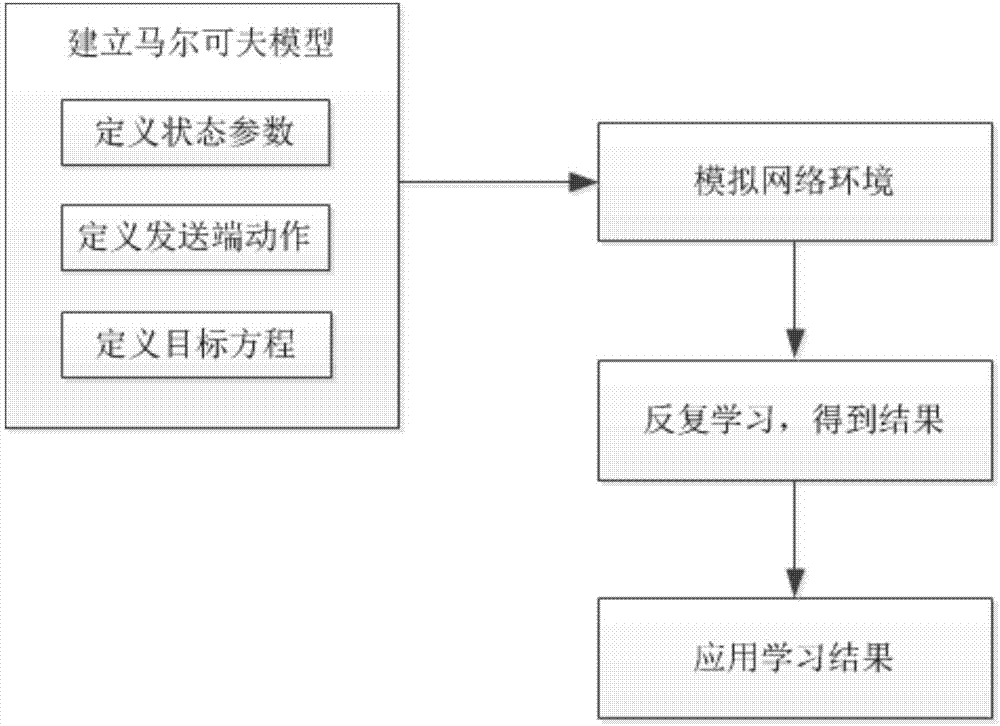
图2为本发明的拥塞控制总体流程图;
图3为本发明的学习过程流程图;
图4为本发明的拥塞控制方法与lia算法的应用效果对比图。
具体实施方式
下面结合附图对本发明的技术方案作进一步说明。
图2是基于强化学习的多路径传输协议拥塞控制的流程图,首先建立马尔可夫模型,然后在网络中反复学习,得到学习结果,最后在网络中应用该结果。在本实施例中,我们用模拟器模拟了一个网络环境,基于该模拟网络进行上述学习和应用过程。具体过程如下:
a)建立马尔可夫模型,包括:
a1)定义发送端的状态
a2)定义发送端的动作{m,b,r},m和b表示对当前拥塞窗口大小的调整,m为对当前拥塞窗口的乘数,b为对当前拥塞窗口的加数,r为发送子流的时间间隔。在本实施例中,分别设置为m={0.1,0.5,1,2},b={+/-1,+/-4,+/-8},r={+/-0.01,+/-0.08,+/-0.64}。
a3)定义目标方程
b)在模拟器中搭建网络环境,包括:
b1)模拟网络基本状况,包括设置瓶颈链路的速度、不同网络的传输时延、网络中竞争瓶颈链路的用户个数、网络中竞争瓶颈链路的子流个数。网络状况可以根据不同的环境设置不同的参数,目的是针对不同的网络环境学习到不同的规则,以期在不同的网络中都得到理想的结果。
b2)建立网络流量模型,包括模拟网络中的应用,建立连接时产生流量,终止连接时停止流量;此外,不同的用户可能会在不同的时间建立连接,连接也有可能是长连接或者是短连接。流量模型主要体现某个发送端是否产生流量,何时产生流量。在模拟器中,我们设置所有的发送端都随机的产生流量或者终止连接,开流量或者关流量的时间服从某一个分布模式(比如指数分布),目的是模拟真实环境下不同用户竞争瓶颈链路的场景。
在本实施例中,设置瓶颈链路的速度为15mbps,网络延迟为20ms。有4个mptcp用户竞争瓶颈链路,且每个用户都同时使用wifi网络和蜂窝网络,两条子流在带宽和rtt上有明显差异,蜂窝网络的rtt大约是wifi网络的25倍。在流量模型中,开流量和关流量的时间服从指数分布。
c)根据马尔可夫模型在网络环境中开始学习,图3示出了学习的具体过程,包括:
c1)采样:首先对网络环境进行采样,确定各个状态可能出现的范围。
c2)首次划分状态空间:从每一个状态范围的中点将此状态的范围划分为两部分,将由三个状态组成的状态空间划分为8个区域。这里选取从中点划分是考虑了平均分布情况,当然也可以根据其他划分标准来划分状态空间。
c3)应用默认动作:第一次为所有状态区域应用一个统一的默认动作,默认动作设置为m=1,b=1,r=0.01,表示将当前拥塞窗口的大小乘以1再加上1,并设置子流的发送间隔为0.01ms。
c4)选择待优化状态区域:在模拟器每个发送端的每一条子流中,每当收到一个ack,就对步骤c1)中的各个状态进行计算,然后更新当前状态。模拟器运行一分钟,找出状态最经常出现的状态区域,作为待优化状态区域。
c5)对待优化状态区域的动作进行优化:在模拟器中的所有发送端的每一条子流上穷举应用所有的动作,模拟器运行一分钟,使用抓包工具(如tcpdump)进行抓包,然后对包进行分析,计算平均吞吐量以及平均时延,如果有动作提高了目标方程的值,就用这个动作替换原来的动作。穷举完所有的动作之后,就得到了对应于这个区域的所有状态的最好的动作,从而形成一条状态区域到动作的映射规则,将该规则添加到状态-动作映射表中。得到的映射表,在系统中用带头结点的单链表的数据结构进行存储,使用该数据结构插入结点速度快。
c6)继续寻找待优化状态区域:为了利用上次学习的结果,此时对不同的状态区域应用不同的动作,其中,对尚未经过优化的区域应用所有动作,对优化过的区域应用前一次优化得到的结果动作,然后再找出状态最经常出现的区域,作为待优化状态区域。有两种情况,一种是找到了其他的区域,就按上述的优化策略进行优化。还有一种是找到的还是刚刚优化过的区域,则再沿着各个状态的中点划分此区域,再按上述的优化策略优化此区域对应的动作。
c7)重复执行步骤c5)-c6),理论上这种优化可以不停地进行下去,并且可以设置不同的状态参数和动作来达到不同的拥塞控制精度。在本实施例中,我们规定在状态区域的数目被划分到50时,停止学习,得到状态-动作映射表。
d)在网络中应用学习结果:在多路径传输控制协议运行至拥塞避免阶段时,每当发送端的一个子流收到一个ack时,就查找上述步骤c)中得到的状态-动作映射表,找到当前状态所对应的动作,使用该动作对这条子流的拥塞窗口和发送间隔进行调整。一个发送端的所有子流共用同一个状态-动作映射表表。
本发明提出的基于强化学习的多路径传输控制协议拥塞控制方法,从当前网络环境提取状态特征,以最大平均吞吐量和最小平均时延为目标,通过感知环境状态来学习网络连接发送端的最优策略,具有速度快、稳定性高的优点。通过模拟器的实验结果表明,在两条子流有明显差异的情况下,本发明的方法取得效果远远好于lia算法。如图4所示,s1为快子流,s2为慢子流,本发明的方法将慢子流的数据转移到了网络情况更好的子流上,虽然慢子流的吞吐量比lia算法略低,但是在快子流上却高了很多,这表明拥塞控制的效果更好。
以上详细描述了本发明的优选实施方式,但是,本发明并不限于上述实施方式中的具体细节,在本发明的技术构思范围内,可以对本发明的技术方案进行多种等同变换,这些等同变换均属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!