一种基于CUDA的H.264并行编码器的实现方法与流程
【技术领域】
本发明属于视频编码领域,尤其涉及一种基于cuda的h.264并行编码器的实现方法。
背景技术:
现在,h.264/avc作为当今最流行的视频编码标准,以其高图像质量和高压缩比的性能而受到广泛欢迎,但是提高了图像质量和编码效率,同时也大大增加了h.264的计算复杂度,而现有的基于通用处理器的串行结构编码器无法达到高清实时编码的性能,而专用硬件的开发成本高,周期长,通用性差,不适合大规模使用,所以亟需为h.264编码器寻找一种高效的实现方法。
技术实现要素:
为了解决现有技术中的上述问题,本发明提出了一种基于cuda的h.264并行编码器的实现方法。
本发明采用的技术方案具体如下:
一种基于cuda的h.264并行编码器的实现方法,该方法包括以下步骤:
(1)对h.264编码器结构进行调整,包括对编码器功能模块进行帧级分隔,以及对该编码器在cpu和gpu上的任务进行划分;
(2)所述编码器的各个功能模块在cuda上并行化运行,即在模块级对h.264编码器的功能模块分别进行帧间预测、帧内预测编码、熵编码、去块滤波4个过程。
进一步地,功能模块的帧级分隔包括如下步骤:
(1.1)按照编码器核心函数的功能,将核心函数中的各个功能函数分隔成独立的循环体,使每个功能函数在帧一级进行独立循环;
(1.2)将编码器中的大型数据结构按照其生命周期划分成多个简单数据结构,并且根据其实际的生命周期进行本地化。
进一步地,所述步骤1.2具体包括:
将所述大型数据结构分成局部变量、伪全局变量和真全局变量三种类型;
(a)如果所述大型数据结构是局部变量,则其不作变化;
(b)如果所述大型数据结构是伪全局变量,则通过重命名的方法,将该伪全局变量按照其实际生命周期划分成不同的变量;
(c)如果所述大型数据结构是真全局变量,则考察该真全局变量的数据结构中,是否有部分变量是伪全局变量或局部变量,如果有,则将这些变量从该真全局变量中分离出去,对分离出去的伪全局变量再进行如上述步骤b的处理。
进一步地,cpu和gpu的任务划分包括:
(2.1)由cpu完成视频文件的输入并对视频文件进行预处理;
(2.2)cpu将视频文件中的原始帧和参考帧传送给gpu,由gpu进行后续的编码操作;
(2.3)gpu进行帧间预测;
(2.4)gpu执行帧内预测编码;
(2.5)gpu进行并行化熵编码;
(2.6)gpu进行去块滤波。
进一步地,所述帧间预测采用多分辨率多窗口(mrmw)算法。
进一步地,在帧内预测编码过程中,采用一次读取多次处理的方式加载数据,即每个线程块向对应的共享存储器中加载处理多个宏块需要的数据,cuda的kernel函数内部通过一层循环对这些数据进行预测编码,当此次读取的数据处理结束之后将重建数据写回,然后再加载新的数据进行处理;相应的kernel的组织为两重循环结构,外层循环控制变量对应加载的次数,内存循环控制变量对应每次加载的数据需处理的次数。
进一步地,kernel内部以宏块为单位进行处理,所述宏块包括多个子宏块,帧内预测编码包括三个阶段:
第一阶段:每个子宏块交由帧内预测线程块中的一个线程进行帧内预测处理;
第二阶段:由dct线程块中的一个线程对一个子宏块中的一行或一列像素进行dct处理;
第三阶段:由量化线程块中的一个线程对一个像素进行量化处理。
进一步地,在并行化熵编码过程中,每个cuda线程块处理8个连续的宏块,每一个线程处理一个子宏块的熵编码。
进一步地,所述去块滤波以帧为单位,包括边界强度的计算和滤波。
进一步地,所述预处理包括对视频分量yuv的分离以及编码器基本参数设置。
本方法的有益效果为:提高了h.264编码器的执行效率,在不降低编码性能的前提下降低编码的计算复杂度,提高编码速度。
【附图说明】
此处所说明的附图是用来提供对本发明的进一步理解,构成本申请的一部分,但并不构成对本发明的不当限定,在附图中:
图1是本发明对核心函数的循环体分割示意图。
图2是本发明数据结构简单化和局部化的示意图。
图3是本发明cpu-gpu上的任务划分图。
图4是本发明帧间预测编码存储模型。
图5是本发明cavlc编码阶段cuda并行模型。
图6是去块滤波函数分离示意图。
【具体实施方式】
下面将结合附图以及具体实施例来详细说明本发明,其中的示意性实施例以及说明仅用来解释本发明,但并不作为对本发明的限定。
本发明基于h.264的串行程序x264,基于对此程序的分析,根据cuda架构提出了并行h.264编码器框架并且在cuda上实现并行h.264编码器的方法。该方法包括以下两个方面:
(1)总体结构优化
总体结构优化是对h.264编码器结构进行调整,对基于cuda的h.264并行编码器的框架进行设计,该调整和设计主要包括两个方面:对编码器功能模块进行帧级分隔;以及对cpu和gpu进行任务划分。
(2)各个功能模块在cuda上的并行化,即在模块级对h.264编码器的功能模块分别进行帧间预测、帧内预测编码、熵编码、去块滤波4个过程,从并行模型设计和存储模型等方面实现编码器在cuda上的并行化。
下面对该方法的这两个方面进行详细说明。
功能模块的帧级分隔:
功能模块的帧级分隔的具体步骤如下:
(1.1)松散函数耦合度
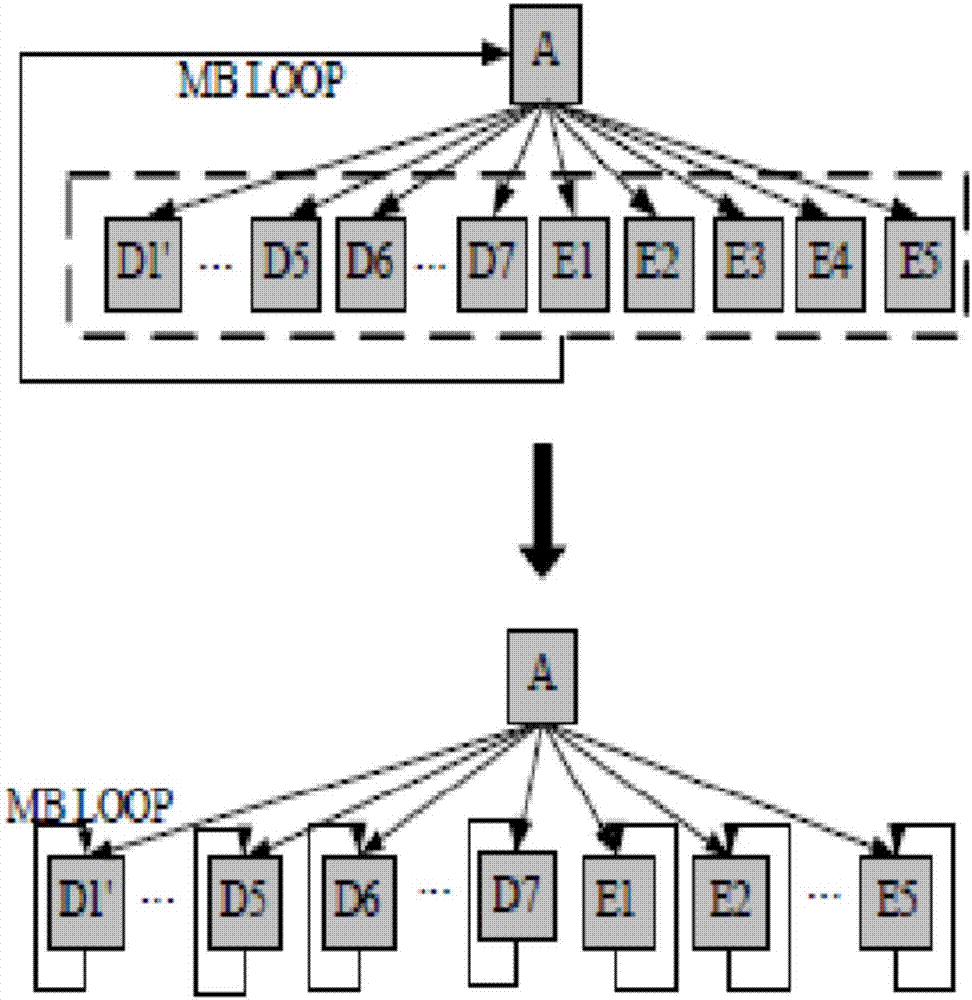
在h.264编码器中,其核心函数(main函数)是一个大的循环体,如图1上方所示,a为main函数,其包括下方的d1’,…,d5,d6,…,d7,e1,e2,e3,e4,e5所有的函数作为一个整个的大的循环体,main函数的每一次循环都执行一遍所有的函数,这种方式循环体路径长,如果直接进行并行程序的开发,函数负载太重。
因此本发明按照核心函数的功能,将核心函数的整个循环分割成多个相对独立的循环体,如图1下方所示,每个函数在帧一级进行独立循环,将d1’,…,d5,d6,…,d7,e1,e2,e3,e4,e5每个都分割成独立的循环体,例如d1’函数是个循环体,d5函数是个循环体,d7函数是个循环体,e1函数是个循环体等等。这样,每个函数独立集中处理一个任务,独立循环,在每个循环体执行的过程中,指令的局域性更好,失效次数低。
(1.2)将h.264编码器中的数据结构简单化和局部化
参见图2,为了减少数据传输的时间,本发明将编码器中的大型数据结构按照其生命周期划分成多个简单数据结构,并且根据其实际的生命周期进行本地化。具体地,所述大型数据结构可以分成局部变量、伪全局变量和真全局变量三种类型。
对于局部变量,例如图2中函数0中的本地变量a,不作变化。
对于伪全局变量b,即虽然是全局变量,但是该变量的作用范围可以拆分成多个实际生命周期,则通过重命名的方法,将该伪全局变量按照其实际生命周期分为不同的变量。如图2所示,对于伪全局变量b,其在函数0和函数1之间的变量值没有关系,可以拆分成2个生命周期,因此将函数1中的该伪全局变量重命名为b0,而函数2中没有使用到该变量b,则函数2中就可以不再定义该变量b。
对于真全局变量c,则需要考察该真全局变量的数据结构中,是否有部分变量是伪全局变量或局部变量,如果有,则将这些变量从c中分离出去,分离出去的伪全局变量再进行如上处理。如果图2所示,真全局变量c可以拆分成一个伪全局变量和一个局部变量,则限制该伪全局变量的作用范围在函数0和函数1,限制局部变量c0的作用范围只在函数2.
cpu和gpu的任务划分
参考图3,其示出了本发明h.264编码器各个功能模块在cpu和gpu上的任务划分以及cpu-gpu之间的数据流动情况。
(2.1)首先由cpu完成视频文件的输入并对视频文件进行预处理,包括对视频分量yuv的分离,以及编码器基本参数设置等。
(2.2)cpu将原始帧和参考帧传送给gpu,由gpu进行后续的编码操作。
gpu以帧为单位,通过执行四个模块对帧进行处理,基本流程是:对一帧的帧间预测结束之后,再进行相应的帧内预测编码,然后对得到的变量化系数进行熵编码,以此类推,直至整帧的熵编码和去块滤波结束之后再将结果数据传回cpu。
(2.3)gpu执行帧间预测。
帧间预测是h.264编码器中计算需求最大的部分,传统帧间预测所需的计算量约占整个编码器的70%,虽然图像质量较好但复杂。本发明采用现有技术中的多分辨率多窗口(mrmw)算法进行帧间预测。由于本发明对功能模块进行了帧级分隔,使用mrmw算法相对于现有技术可以大幅度减少帧间预测的时间。
(2.4)gpu执行帧内预测编码。
帧内预测并行度并不高,cuda每个线程块能够同时处理最大的数据量为1个宏块(256像素),对于共享存储器的压力并不大,而相邻宏块之间存在生产者-消费者之间的关系,为了减少为全局存储中相关数据的访问次数,本发明采用一次读取多次处理的方式加载数据。即每个线程块向对应的共享存储器中加载处理多个宏块需要的数据,cuda的kernel函数内部通过一层循环对这些数据进行预测编码,当此次读取的数据处理结束之后将重建数据写回,然后再加载新的数据进行处理。相应的kernel的组织为两重循环结构,外层循环控制变量对应加载的次数,内存循环控制变量对应每次加载的数据需处理的次数。
参见附图4,其示出了帧内预测编码的存储模型。图4左上部分由多个宏块(mb)组成的一个图像帧,每次读取帧数据时,都从原始图像帧中读取一个strip,并存储到共享存储器中(如图4右上所示),kernel内部以宏块为单位对该strip进行处理。
图4中部和下部示出了kernel对一个宏块的处理过程。图4的左中部分示出了一个4*4的宏块,其包括子宏块0到子宏块15,每个子宏块包括4*4个像素,其帧内预测编码包括三个阶段:
第一阶段:如图4左中和左下部分,每个子宏块交由帧内预测线程块(predictionthreadblock)中的一个线程进行帧内预测处理,共需要16个线程(线程0至线程15)。
第二阶段:如图4的正中和正下部分,由dct线程块中的一个线程对一个子宏块中的一行或一列像素进行dct处理,共需64个线程(线程0至线程63)。
第三阶段:如图4的右中和右下部分,由量化线程块(quantthreadblock)中的一个线程对一个像素进行量化处理(以行优先的方式),共需256个线程(线程0值线程255)。
(2.5)gpu进行并行化熵编码。
参考附图5,其为cavlc编码阶段cuda并行模型,示出了亮度交流分量熵编码阶段数据与线程的映射关系。其中每个cuda线程块处理8个连续的宏块,即线程块b0处理第0行中的mb0到mb7,线程块b14处理mb112到mb119,以此类推。线程块内连续的16个线程分别处理一个宏块中16个子宏块。图5中共有1200个线程块,每个线程块包含128个线程,线程数达到了130560个,每一个线程处理一个子宏块的熵编码,从而实现了130560个线程并行熵编码。虽然熵编码是一个分支密集型的组件,但是经过功能模块的帧级分隔,将各种分量分离,已经消除了一些分支路径,通过大量线程实现大规模的数据并行足以弥补分支操作带来的影响。
(2.6)gpu进行去块滤波,如图6所示,所述去块滤波以帧为单位,包括边界强度的计算和滤波。
通过上述过程,本发明从系统和模块级两个方面实现了h.264在cuda上的并行化过程,在不降低编码性能的前提下降低编码的计算复杂度,提高编码速度。
以上所述仅是本发明的较佳实施方式,故凡依本发明专利申请范围所述的构造、特征及原理所做的等效变化或修饰,均包括于本发明专利申请范围内。
- 还没有人留言评论。精彩留言会获得点赞!