基于双MIC的OpenCL并行帧率上转换方法与流程
本发明属于视频处理
技术领域:
,涉及一种opencl并行帧率上转换方法,具体涉及一种基于双mic的opencl并行帧率上转换方法,适用于视频帧率上转换等领域。
背景技术:
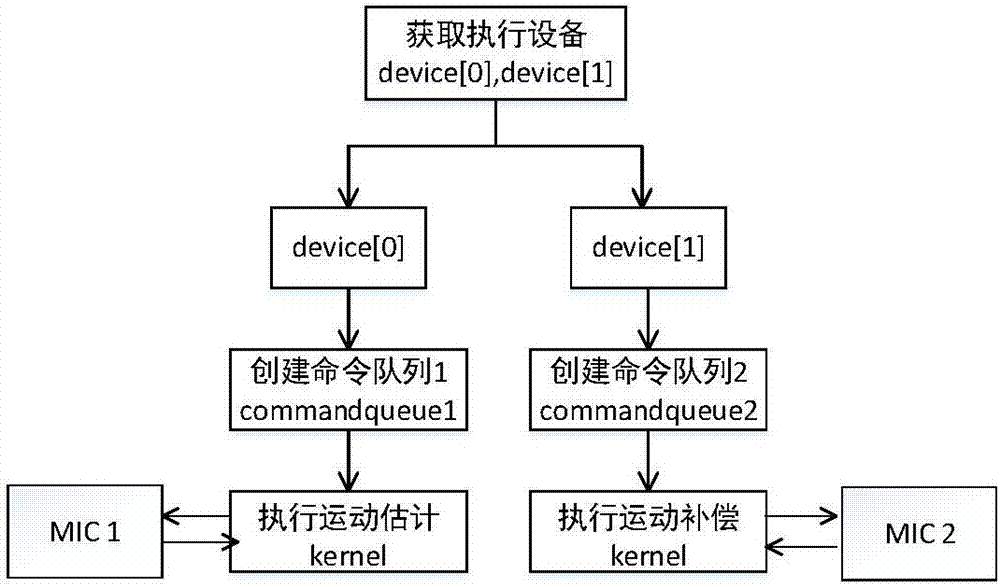
:近年来,视频领域的新技术不断涌现,通过增加视频的分辨率和提高视频的帧率等技术手段,已带给人们更清晰、更具冲击力的视觉感受。比如从原先的标清视频,到现在的高清视频,甚至超高清的4k视频。现如今4k视频源也越来越多,已经逐渐进入到人们的视野当中,预示着人们对于视频画面的清晰度要求也更高了。2016年11月李安导演的新作《比利·林恩的中场战事》,首次尝试了“120帧/4k/3d”(每秒播放120帧、4k分辨率、3d效果)的技术,以每秒120帧高帧率的播放方式开创了电影技术的新法则,引起了业界的广泛关注。视频帧率上转换技术(fruc),作为一种视频后处理手段,通过在原有视频帧中插入中间帧的方式,将低帧率视频转换成高帧率视频。最早在20世纪80年代在业界就出现了帧率转换的技术,线性内插帧被采用来执行帧率上转换算法,其中包括帧复制和帧平均,随后发展越来越成熟。90年代中期提出了基于运动补偿的视频帧率上转换技术,这种技术对运动的物体首先进行运动估计算法,尽可能获得接近真实运动的矢量场。它以块或者像素点为单位,不同的块得到的矢量很可能不一样,所以包含了运动物体的各个部分,得到的矢量是比较精确的。然后根据得到的运动矢量,进行运动补偿模块的计算,即根据原始的视频帧和上一步得到的运动矢量通过插值的方式获得待插帧。随着视频图像从高清到超高清的迈进,以及高帧率视频的出现,使得处理视频的图像大小和帧数都有了极大的增长。图像规模的增大,算法复杂度的提高,使得原先算法处理的时间大大增加,无法满足迅速处理甚至实时的要求。因此,研究如何加速帧率上转换算法已成为当今比较迫切的问题之一。intel在2012年发布了intelxeonphi协处理器,它是一款基于集成众核架构mic(manyintergratedcores)的至强融合产品。该协处理器集成了50个以上的计算核心,并且具备了512bit的向量处理单元(vpu)。intelmic众核架构的硬件既保留了cpu中的多级流水线,同时又配备了众多的计算核心,每个计算核心又可以并发执行4个线程,这就保证了mic具有同时处理多个任务的优势。2015年焦文在硕士论文中提出了在mic架构上的并行运动估计和并行运动补偿方法,该方法利用openmp的fork-join模型,将运动估计的每个块求解运动矢量的过程放在mic每个线程执行,运动补偿模块的每个像素点放在mic每个线程执行。该方法虽然获得了一定的加速效果,但是,并没有研究在双mic上如何实现视频帧率上转换。技术实现要素:本发明的目的在于针对上述已有技术的不足,提出了一种基于双mic的opencl并行帧率上转换方法,在保证图像质量的前提下,有效缩短帧率上转换的运行时间,提高帧率上转换的运行效率。为实现上述目的,本发明采取的技术方案包括有如下步骤:(1)主线程对opencl设备的mic1和mic2进行初始化,实现主机端对mic设备的控制;(2)主线程对读入的视频进行编号:主线程读入n帧视频,并对运动估计算法中视频当前帧的图像编号为i,初始化i=1,同时对运动补偿算法中视频当前帧的图像编号为j,初始化j=1,其中,i的取值范围是[1,n],j的取值范围是[1,n];(3)主线程定义信号量并初始化:主线程定义信号量1和信号量2,并将信号量1的值初始化为1,信号量2的值初始化为0;(4)主线程在主机上开辟内存并创建子线程:主线程在主机上开辟主机内存cpu_mem1、主机内存cpu_mem2和主机内存cpu_mem3,同时创建子线程1和子线程2;(5)子线程1控制mic1,执行运动估计算法:(5a)子线程1在mic1上开辟内存mic1_mem1和内存mic1_mem2;(5b)子线程1将第i帧和第i+1帧的图像数据传输到内存mic1_mem1;(5c)mic1计算运动估计算法中第i帧图像数据的运动矢量mvi,并将mvi存入内存mic1_mem2中;(5d)子线程1将mvi从内存mic1_mem2传入主机内存cpu_mem1;(5e)子线程1判断信号量1的值是否大于0,若是,将信号量1的值减1,同时将主机内存cpu_mem1中的mvi写入主机内存cpu_mem2中,将信号量2的值加1,并执行步骤(5g),否则,执行步骤(5f);(5f)子线程1等待子线程2修改信号量1的值,直到修改完成,并执行步骤(5e);(5g)令i=i+1,子线程1判断i≤n是否成立,若是,执行步骤(5b),否则,子线程1挂起;(6)子线程2控制mic2,执行运动补偿算法,实现视频帧率的上转换:(6a)子线程2在mic2上开辟内存mic2_mem1、内存mic2_mem2和内存mic2_mem3;(6b)子线程2将第j帧和第j+1帧的图像数据传入内存mic2_mem1;(6c)子线程2判断信号量2的值是否大于0,若是,将信号量2的值减1,同时将主机内存cpu_mem2中的mvi读到内存mic2_mem2,并执行步骤(6e),否则,执行步骤(6d);(6d)子线程2等待子线程1修改信号量2的值,直到修改完成,并执行步骤(6c);(6e)mic2计算待插帧中每个像素点的运动补偿插值,并将待插帧的插值结果存放在内存mic2_mem3中;(6f)子线程2将插值结果从内存mic2_mem3传入主机内存cpu_mem3,并将主机内存cpu_mem3中的插值结果写文件到硬盘中,同时将信号量1的值加1;(6g)令j=j+1,子线程2判断j≤n是否成立,若是,执行步骤(6b),否则,子线程2挂起;(7)主线程关闭子线程1和子线程2。本发明与现有技术相比,具有如下优点:1、本发明通过pthread在主机端创建子线程1和子线程2,子线程1控制mic1计算当前帧图像的运动矢量,同时子线程2控制mic2计算当前帧的上一帧图像的运动补偿插值,避免了现有技术通过单个计算设备串行计算运动矢量和运动补偿插值耗时大的缺陷,有效地提高了帧率上转换的运行效率。2、本发明中子线程1和子线程2都需要访问存放运动矢量的主机内存,其中子线程1利用信号量控制对这块主机内存进行写操作,子线程2利用信号量控制对这块主机内存进行读操作,避免了两个线程对这块内存的读写冲突,保证了帧率上转换的正确性。附图说明图1是本发明的实现流程图;图2是本发明对opencl设备初始化的实现流程图;图3是本发明子线程1控制mic1执行运动估计算法的实现流程图;图4是本发明子线程2控制mic2执行运动补偿算法的实现流程图;图5是本发明仿真实验输入的不同分辨率的单帧测试视频图;图6是本发明判别正确性的仿真实验结果图。具体实施方式下面结合附图和具体实施例,对本发明作进一步说明。参照图1,基于双mic的opencl并行帧率上转换方法,包括如下步骤:步骤1)主线程对opencl设备的mic1和mic2进行初始化,实现主机端对mic设备的控制:程序开始执行后,进入主线程。对opencl设备初始化的实现流程图参照图2,主线程在获取执行opencl设备阶段时,通过device[0]来获取mic1的设备信息,通过device[1]来获取mic2的设备信息。然后对mic1设备创建命令队列commandqueue1,对mic2设备创建命令队列commandqueue2,在运动估计算法中,利用commandqueue1控制对mic1的数据读写和执行运动估计kernel的操作。在运动补偿算法中,利用commandqueue2控制对mic2的数据读写和执行运动补偿kernel的操作。步骤2)主线程对读入的视频进行编号:主线程读入30帧视频,由于执行运动估计算法的子线程1和执行运动补偿算法的子线程2,并不是对同一帧图像并行处理,所以对运动估计算法中视频当前帧的图像编号为i,初始化i=1,同时对运动补偿算法中视频当前帧的图像编号为j,初始化j=1,其中,i的取值范围是[1,30],j的取值范围是[1,30]。步骤3)主线程定义信号量并初始化:为了防止两个线程对同一块内存的访问冲突,本发明采用信号量控制两个线程之间的通信,主线程定义信号量1和信号量2,将信号量1的值初始化为1,信号量2的值初始化为0。步骤4)主线程在主机上开辟内存并创建子线程:主线程在主机上开辟主机内存cpu_mem1、主机内存cpu_mem2和主机内存cpu_mem3,采用pthread函数pthread_create创建子线程1和子线程2。步骤5)子线程1控制mic1,执行运动估计算法,实现流程图参照图3:步骤5a)子线程1采用opencl函数clcreatebuffer在mic1上开辟内存mic1_mem1和内存mic1_mem2,mic1_mem1用来存储输入的图像数据,mic1_mem2用来存储计算出的运动矢量结果。步骤5b)子线程1采用opencl函数clenqueuewritebuffer将第i帧和第i+1帧的图像数据传输到内存mic1_mem1。步骤5c)mic1计算运动估计算法中第i帧图像数据的运动矢量mvi,并将mvi存入内存mic1_mem2中:将第i帧的图像划分为240×135个宏块,计算每个宏块的候选运动矢量集,根据sad计算公式,得出矢量集中每个候选运动矢量的sad值,选择sad值最小的候选运动矢量作为该宏块的运动矢量,依次计算完第i帧图像所有宏块的运动矢量。其中x代表第i帧当前宏块的宽,y代表第i帧当前宏块的高,xmn代表第i帧中当前块内位置为(m,n)点的像素值,ymn为第i+1帧中匹配块位置为(m,n)点的像素值。步骤5d)子线程1采用opencl函数clenqueuereadbuffer将mvi从内存mic1_mem2传入主机内存cpu_mem1。步骤5e)子线程1判断信号量1的值是否大于0,若是,表明子线程2已经计算完第j帧的运动补偿,可以给子线程2中存储输入数据的内存块拷贝数据,将信号量1的值减1,同时将主机内存cpu_mem1中的mvi写入主机内存cpu_mem2中,将信号量2的值加1,并执行步骤5g),否则,执行步骤5f)。步骤5f)子线程1等待子线程2修改信号量1的值,直到修改完成,并执行步骤5e)。步骤5g)令i=i+1,子线程1判断i≤30是否成立,若是,计算下一帧图像的运动矢量,执行步骤5b),否则,表明视频所有帧的运动矢量已经计算完成,子线程1挂起。步骤6)子线程2控制mic2,执行运动补偿算法,实现流程图参照图4:步骤6a)子线程2采用opencl函数clcreatebuffer在mic2上开辟内存mic2_mem1、内存mic2_mem2和内存mic2_mem3。步骤6b)子线程2采用opencl函数clenqueuewritebuffer将第j帧和第j+1帧的图像数据传入内存mic2_mem1。步骤6c)子线程2判断信号量2的值是否大于0,若是,表明子线程1已经将mvi从主机内存cpu_mem1写入主机内存cpu_mem2,将信号量2的值减1,同时将主机内存cpu_mem2中的mvi读到内存mic2_mem2,并执行步骤6e),否则,执行步骤6d)。步骤6d)子线程2等待子线程1修改信号量2的值,直到修改完成,并执行步骤6c)。步骤6e)mic2上计算待插帧中每个像素点的插值结果,并将待插帧的插值结果存放在内存mic2_mem3中。步骤6f)子线程2采用opencl函数clenqueuereadbuffer将插值结果从内存mic2_mem3传入主机内存cpu_mem3,并将主机内存cpu_mem3中的插值结果写文件到硬盘中,同时将信号量1的值加1,表明第j帧的运动补偿插值计算完成。步骤6g)令j=j+1,子线程2判断j≤n是否成立,若是,计算下一帧图像的运动补偿插值,执行步骤(6b),否则,表明视频所有的待插帧已经计算完成,子线程2挂起。步骤7)主线程关闭子线程1和子线程2。以下结合仿真实验,对本发明的技术效果进一步说明:1)仿真条件:仿真实验输入的不同分辨率的单帧测试视频图,参照图5,图5(a)是2k分辨率的单帧测试视频图parkscene_1920×1080,图5(b)是4k分辨率的单帧测试视频图sunset_3840×2160。仿真实验环境使用西安电子科技大学高性能计算中心集群设备,测试平台参数见表1所示。表12)仿真内容与结果分析:基于双mic的opencl并行帧率上转换方法,表2为串行算法和本发明并行算法的psnr值对比,表3为运动估计算法和运动补偿算法测试时间,表4为串行测试时间和本发明测试时间。表2视频序列串行算法本发明并行算法2k视频36.3936.374k视频38.4338.40表3测试序列运动估计算法(ms)运动补偿算法(ms)2k视频240.52187.924k视频249.37684.38表4测试序列串行算法(ms)本发明并行方法(ms)2k视频428.44261.304k视频933.75689.61图6为判别正确性的仿真实验结果图,图6(a)是2k分辨率视频的单帧仿真结果图,图6(b)是4k分辨率视频的单帧仿真结果图。为了更加准确判断本发明的并行方案的正确性,采用客观评价准则的峰值信噪比(psnr)用来评价算法的质量,本发明仿真结果的psnr值如表2所示,在本发明中提出的并行帧率上转换算法得到的psnr和串行算法的psnr接近,可以得到结论,并行帧率上转换算法的图像质量与串行算法的图像质量保持一致,因此验证了本次并行帧率上转换算法的正确性。表3为帧率上转换算法中运动估计算法和运动补偿算法的串行测试时间。表4为帧率上转换算法的串行测试时间和本发明的并行测试时间,其中串行测试时间为表3中运动估计算法时间和运动补偿算法时间的求和结果,本发明的测试时间约为表3中运动估计算法测试时间和运动补偿算法测试时间两者之间的较大者,再加上数据拷贝时间和信号量等待时间。从表4可以看出,本发明的测试时间有效地加速了帧率上转换算法的计算效率。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1