基于工控私有协议的模糊测试方法与流程
本发明属于工业网络安全技术领域和模糊测试技术领域的结合,涉及了一种工控私有协议的学习方法和基于工控私有协议的模糊测试方法。
背景技术:
工业控制系统(industrialcontrolsystems,ics)是指工业生产过程中的控制网络和系统,是国家关键基础设施的关键组成部分。目前,工业控制系统已广泛应用于石油石化,交通控制,电力设施,制造业以及核工业等各工业领域。随着我国信息化和工业化的深度融合,工业控制系统在工业生产过程中得到了越来越广泛的应用,越来越多的工业现场设备集成以太网通信功能,与erp甚至互联网相连,在提高数据共享效率,改进企业管理水平的同时也引入了黑客,病毒木马等安全风险。由于工业控制系统与石油化工等工业领域息息相关,一旦工业控制系统等国家安全基础设施受到网络攻击,将会造成财产损失、人员伤亡等严重后果,对社会稳定造成重大威胁。
近年来,针对工业控制网络的攻击屡见不鲜。2010年,网络超级武器“stuxnet”病毒通过针对性的入侵ics系统,严重威胁到伊朗布什尔核电站核反应堆的安全运营,这次被称为“震网”的攻击事件使人们对关键基础设施网络安全问题的关注度大大上升。权威工业安全事件信息库risi(repositoryofsecurityincidents)统计,截止2011年,全球已发生200余起针对工业控制系统的重大攻击事件,尤其在2000年以后,随着通用协议、通用硬件、通用软件在工业控制系统中的应用,对过程控制系统和数据采集监控系统的攻击增长了近10倍。工控系统之所以会成为攻击者的目标,根源之处还是在于系统软件,网络协议,设备在设计之初只专注于实用性和功能性,并未考虑安全性问题,在使用之中便暴露出安全漏洞。漏洞挖掘是探测系统软件漏洞的常见技术手段,是解决工控系统安全的根本,它可以在威胁未发生时就检测出系统存在的安全隐患。国内外安全领域对漏洞挖掘技术的研究已具有一定的成果,但传统网络的漏洞挖掘方法并不适用于工控网络,如何对工业控制系统进行漏洞挖掘的研究较少。面对日益严重的工控网络安全问题,基于工控网络的漏洞挖掘方法也在发展之中。
技术实现要素:
为解决上述问题,本发明考虑了工业网络的特殊性,针对工控网络设备经常使用私有协议的特点,提出了一种工控私有协议的学习方法和基于工控私有协议的模糊测试方法。通过工控主从通信链路获取的报文样本数据,学习私有协议的协议特征信息,将协议特征信息作为构建测试用例以及对测试用例变异的依据,从而以网络流量的方式,测试支持此私有协议的过程逻辑控制器(plc)的健壮性,同时对被测对象进行异常监控,记录被测对象发生的异常信息。
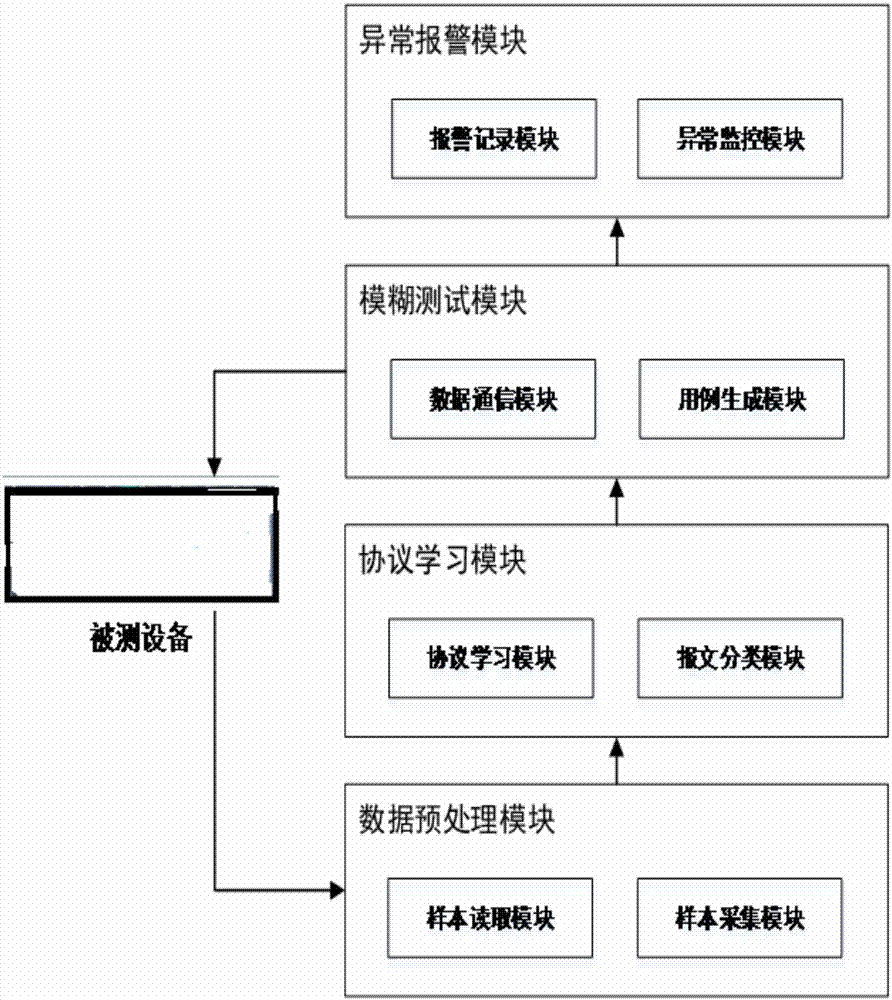
为了达到本发明的目的,本发明结合工控私有协议学习方法和工控私有协议模糊方法,提出了一种基于工控私有协议模糊测试方法,该方法由数据预处理模块、协议学习模块、模糊测试模块、异常报警模块共四部分构成。
数据预处理模块。此模块作用是采集样本数据包,将样本数据包读取到程序内存中。因此,此模块由两个功能子模块构成。功能一,样本采集模块,在程序运行阶段,在主从通信链路之间使用镜像端口的方式采集一个工业流程周期内的双向数据包,保存为pcap文件,作为样本集,放置在程序根目录下。功能二,样本读取模块,此功能通过利用对winpcap封装好的sharppcap,使用用于文件数据捕获的icapturedevice接口,使用tcpdump规则对样本集内的数据包进行过滤,如果不属于需要进行分析的数据报文,则将其丢弃。将需要分析的协议报文通过请求与响应对应的形式保存到程序内部的请求响应队列中,再将所有请求保存到请求队列中。两个缓存队列提交给协议学习模块使用。
协议学习模块。此模块的作用是根据数据预处理模块提供的缓存队列,利用学习算法,首先将请求队列中的协议报文进行分类,然后针对每类报文进行请求字段特征的学习,最后对请求与响应之间字段特征的关系进行学习,因此,此模块由两个功能子模块构成。功能一,报文分类模块,首先获取数据处理模块中的请求响应队列和请求队列,根据请求队列,学习统计出请求数据包样本的可变域和不可变域,最大报文长度,最小报文长度,可变域中该字节的变化率,称这些属性为基本属性,通过请求响应队列和请求队列以及统计学习到的上述基本属性,实例化一个节点作为根节点。通常,工控协议存在控制命令标识符,命令标识符往往在样本中属于可变域并且变化率低,并且在协议字段头部的位置,所以,通过可变域的变化率寻找变化率最小,并且前一个字节不为0x00的第一个字节索引为划分依据字节,根据此字节的不同将两个缓存队列进行划分,并且分别统计上述的基本属性,根据统计信息实例化多个节点作为根节点的叶子节点。在具有叶子节点的情况下,需要判断叶子节点是否需要继续划分,统计一个节点中的最小变化率索引的集合,由于,工控协议往往存在命令表示符和子命令标识符,同一层的兄弟节点的命令标识符位置应该接近,所以,判断叶子节点是否需要继续划分的依据为,一个节点的子节点集合中,如果子节点的最小变化率索引的集合有交集,则该子节点集合中所有的节点都应划分,否则停止划分。如果满足划分的条件,则应该确定使用哪一个字节进行划分,由于有些需要划分的节点的划分依据已经成为不可变域,为了使划分的更加精确,可以将划分的依据节点向后移,所以确定使用哪一个字节进行划分的依据为,根据一个节点,获取此节点中变化率最小,并且前一个字节不为0x00的字节,查看该字节是否存在于该节点的兄弟节点的不可变域中,如果存在,则该节点和其他兄弟节点各自按照其变化率最小且前一个字节不为0x00的字节进行划分,否则统计每个子节点其变化率最小且前一个字节不为0x00的字节,取出该字节在各个兄弟节点中索引最小的索引,每个子节点依据此字节进行划分。划分出来的子节点继续根据是否划分的条件和划分的节点进行操作,最多不超过4层,直到所有节点不可再划分为止。功能二,协议学习模块,分类完毕后,对每个叶子节点,首先划分该节点的可变域和不可变域,统计该节点可变域的样本频率,然后,收集属于不可变域且前一个字节为0x00,或属于可变域的节点作为长度域的初始化空间,以向量集的形式,统计长度域最小的可能范围。接着使用apriori算法学习协议字段间的关联规则,此关联规则的学习共有两个步骤,步骤一,寻找数据包间的单独项,统计出现的次数形成初始候选集,然后根据最小支持度进行裁剪,得到初始频繁集,通过频繁集的自连接生成下一轮的候选集,直到进行裁剪之后频繁集内个体为零为止,最后,可得到最终的频繁集。步骤二,根据频繁集,首先统计频繁集中所有出现的子集,统计每个子集出现的次数。然后,根据子集的支持度,使用条件概率的方法,计算不相交的两个子集间的关联概率,以最小置信度进行裁剪,最后得出该叶子节点的强关联规则。学习的最后,需要使用请求响应队列,学习请求与响应的对应的特征关系,该方法由三个步骤,步骤一,针对请求响应队列中的一对请求响应数据,以字节为单位,使用双序列比对算法中的needleman/wunsch算法,将请求的个数加一作为行数,响应的个数加一作为列数,构造比对矩阵,使用动态规划的思想和填充规则,将矩阵内部进行填充,步骤二,从矩阵的右下角开始,使用回溯规则进行规则,将相等的字节索引进行记录,获得一对请求与响应间的比对序列,步骤三,将该节点下的请求响应数据依次进行步骤一、二的操作,最后对所有数据所得的结果求交集,得出最终的请求响应特征比对结果。将学习到的可变域与不可变域,可变域的样本频率,长度域向量集,关联规则、请求响应特征比对结果依附于相关的叶子节点上。
模糊测试模块。此模块的作用是根据协议学习模块学习的协议特征,构造符合协议特征的应用报文并且在协议特征的基础上进行变异操作,生成模糊测试用例,之后通过数据通信模块将测试用例发生给被测对象(plc)。因此,此模块由两个功能子模块构成,功能一,用例生成模块,以叶子节点作为处理单元,以字节作为变化单位。首先,通过该节点的最后一个不可变域的索引、样本最大长度、样本最小长度,确定样本的data数据域,以随机的方式生成data数据域的长度,再进行随机填充。然后,统计该节点的不可变域和该节点的父节点的不可变域的差集,将该集合作为第一步变异的空间,随机选择字节进行随机填充,将所有不可变域存入一个记录队列。接着,以apriori关联规则的结果概率,选择关联规则的条件或结果,使用可变域的变异规则,进行随机变异,再次使用可变域的变异规则,将识别出的长度域进行随机变异,把关联规则中的条件结果和长度域均加入记录队列。最后,从第一个字节向后遍历非data数据域的部分,如果该字节不存在于记录队列意味着该字节还未生成,因此,使用可变域的变异规则,生成该可变域,最终将生成的各种域进行拼接,形成一个测试用例。功能二,数据通信模块,将生成的测试用例通过socket异步通信的方式,首先建立连接,然后send测试数据,接着监听响应数据,receive响应信息,将响应数据和对应的测试数据进行记录,最后断开连接,进行下一个测试用例的生成和发送。
异常报警模块,此模块的作用是在测试用例发送的同时,实时对接收到的响应以及被测对象的状态进行监控,如果发生异常,通过报警记录的功能对信息记录。因此该模块由两个功能子模块构成。功能一,异常监控模块,在发送测试用例,接收到测试用例的响应数据之后,通过学习的请求与响应之间的特征关系,对记录的请求与响应进行匹配,查看是否符合该叶子节点下的多序列比对特征,如果不匹配,则进行报警操作;在发送测试用例之前,检测socket的tcp是否连接成功,如果不成功,则进行报警操作。功能二,报警记录模块,该模块的作用是将报警的信息进行记录显示,需要将报警进行记录到数据库中。
本发明提出了一种工控私有协议的学习方法和基于工控私有协议的模糊测试方法,在支持私有协议的工控设备运行于工业现场之前,对设备的安全性和健壮性进行测试,发现工控设备异常情况,提前获知可能存在的危险。
附图说明
图1是本发明工控私有协议模糊测试方法的结构示意图。
图2是本发明私有协议树学习构建的流程示意图。
图3是本发明私有协议特征字段学习的流程示意图。
图4是本发明模糊测试的流程示意图。
具体实施方式
以下将结合附图所示的具体实施方式对本发明进行详细描述。
图1是本发明基于工控私有协议模糊测试方法的结构示意图,如图1所示,其步骤包括:
步骤11:在正常工控工艺环境中,采集私有协议的通信流量,使用wireshark保存为pcap文件。程序通过sharppcap的icapturedevice接口实例化虚拟的捕获设备,使用tcpdump规则对样本集进行过滤,将所有的请求数据保存在请求队列,将所有的请求响应数据保存在请求响应队列。
步骤12:通过两个缓存队列,使用协议树生成算法对私有协议报文进行分类,以实例化树节点方法和是否继续划分的判断条件以及划分依据条件,生成一个私有协议特征分类树。其中分类的过程和判断依据条件为:首先获取数据处理模块中的请求响应队列和请求队列,根据请求队列,学习统计出请求数据包样本的可变域和不可变域,最大报文长度,最小报文长度,可变域中该字节的变化率,称这些属性为基本属性,通过请求响应队列和请求队列以及统计学习到的上述基本属性,实例化一个节点作为根节点。通过可变域的变化率寻找变化率最小,并且前一个字节不为0x00的第一个字节索引为划分依据字节,根据此字节的不同将两个缓存队列进行划分,并且分别统计上述的基本属性,根据统计信息实例化多个节点作为根节点的叶子节点。在具有叶子节点的情况下,需要判断叶子节点是否需要继续划分,统计一个节点中的最小变化率索引的集合,判断叶子节点是否需要继续划分的依据为,一个节点的子节点集合中,如果子节点的最小变化率索引的集合有交集,则该子节点集合中所有的节点都应划分,否则停止划分。如果满足划分的条件,则应该确定使用哪一个字节进行划分,确定使用哪一个字节进行划分的依据为,根据一个节点,获取此节点中变化率最小,并且前一个字节不为0x00的字节,查看该字节是否存在于该节点的兄弟节点的不可变域中,如果存在,则该节点和其他兄弟节点各自按照其变化率最小且前一个字节不为0x00的字节进行划分,否则统计每个子节点其变化率最小且前一个字节不为0x00的字节,取出该字节在各个兄弟节点中索引最小的索引,每个子节点依据此字节进行划分。划分出来的子节点继续根据是否划分的条件和划分的节点进行操作,最多不超过4层,直到所有节点不可再划分为止。
对该树进行广度优先搜索遍历,遍历到每一个节点时,统计该节点内数据样本的最大长度和最小长度。以最小长度为遍历字节序列统计该节点的可变域和不可变域。根据统计出的可变域,统计序列组中相同域中出现的数据,计算相同域中不同数据在序列样本中出现的频率,例如,设索引1为序列组中第一个出现的可变域,长度为2个字节,1中出现的(0x81,0x02)概率为0.12,则可将此组信息表示为{1,(0x81,0x02),0.12}。最终得到该节点的可变域的样本频率。
对该节点中的每个数据包数据的序列,穷举所有可能出现的连续字节的组合,计算每种组合的字节长度值,从起始位遍历每一个可变域,查看该可变域中字节的值是否和出现在该字节索引之后的连续字节组合的长度相匹配,如果匹配,则形成一个长度域向量,例如,s表示起始域序号,e表示终止域序号,l表示长度域序号,p表示长度域在可变域之内的偏移,h表示长度域的长度,则匹配信息以{s,e,l,p,h}的向量形式记录下来,将一个数据包所有的匹配信息形成一系列的长度向量集,对所有数据包的长度向量集做相同的操作,然后求它们的交集。最后得出识别出的长度域集合,此长度域的数量可能不唯一,但都符合报文样本数据情况。
对该节点的可变域进行统计,生成样本数据集。统计样本数据集内部的所有可变域的频率,生成初始候选集。使用最小支持度进行裁剪,然后进行自连接操作,统计每个个体在初始样本集内出现的次数,生成第二轮的候选集,再次进行上述自连接并且统计候选集出现频率的操作,进行自连接操作和统计频繁集的时候需要满足两个条件:两个项集可以进行连接的条件是它们有k-1项是相同的,并且如果一个项集有一个子集不为频繁集中的项集则该项集也不为频繁集中的项集。在裁剪之后如果候选集为空则停止操作,上一轮的候选集成为频繁集。统计这个频繁集中的项集符合索引前后关系且不相交的两个子集,前者置信度的条件,后者为置信度的结论。x为置信度的条件,y为置信度的结论,其中x,y均表示每个报文序列特征域之中的数据,supp函数表示x与y同时在样本集中出现的概率其值表示x与y的支持度,conf函数表示在x出现的情况下,y出现的概率,其值表示x与y的置信度,则支持度和置信度的计算方法为:
对每一个条件结果进行计算之后,生成apriori关联规则列表,依附于该叶子节点上。
获取节点的请求响应列表,对每一对请求响应构建双序列比对矩阵x,矩阵的行为m+1,列为n+1,m为请求数据长度,n为响应数据长度,首先对矩阵的0行和第0列进行填充,填充的方法为:
x(i,0)=0;x(0,j)=0(0≤i≤m,0≤j≤n)
然后以从左上到右下的方向填充矩阵中的其他元素,
填充的方法为:
ai和bj代表第i个索引的请求字节值和第j个索引的响应字节值,max为取最大值的函数。接着通过矩阵,从矩阵的右下角开始进行回溯操作,若ai=bj,则回溯到左上角单元格,并且对请求与响应的索引进行对应记录,若ai≠bj,回溯到左上角、上边、左边中值最大的单元格,若有相同最大值的单元格,优先级按照左上角、上边、左边的顺序。回溯到矩阵左上角为止,生成该请求响应对的比对特征。对所有请求响应序列进行特征比对操作后,求所有比对特征的交集,生成最终的请求响应比对特征。最后将记录的协议请求响应比对特征依附于该节点上。
步骤13:随机选择一个叶子节点,该叶子节点的数据包最大长度为m,最后一个不可变域的索引为c,随机生成一个x,取值范围为0≤x≤2,则所生成测试用例数据域的长度l为:
random(min,max)函数表示取min到max-1之间的随机数,包含min和max-1,然后对生成的数据域进行随机填充。寻找该节点和该节点的父节点的不可变域的差,随机选择一个字节进行变异,以长度域,apriori关联规则域的,未处理可变域的顺序对每个域中的数据进行变异,维持原有样本空间内的数据的概率为pi,i为该可变字节中每个字节值出现的样本,n为该节点数据包的个数,qi为i样本的频率,则pi为:
最终构造了一个基于该叶子节点的私有协议的测试用例。
通过socket建立tcp连接,连接建立成功后,将测试用例数据发送给plc,等待响应数据,将请求与响应数据成对放入缓存队列中。通过请求与响应的特征,比对是否满足该节点的请求与响应的比对特征以及是否下一次tcp连接成功,如果满足且连接成功则继续发送下一个测试用例,如果不满足或连接不成功则由异常报警模块处理。
步骤14:对无法建立tcp连接情况和不符合请求响应比对特征的情况,记录其有关信息,存入报警数据库中,停止测试用例发送过程。
图2是本发明基于工控私有协议的协议树学习构建方法的流程示意图,如图2所示,其步骤包括:
步骤21:启动协议树的创建,开始创建一颗私有协议分类树。
步骤22:从读取的数据包样本内存中,获取请求队列和请求响应队列。
步骤23:以请求队列中数据最小长度为最大值,统计请求数据的可变域和不可变域。
步骤24:根据统计的可变域,统计每个可变域的变化次数,统计变化频率最低的可变域的索引序列。
步骤25:通过请求队列,统计请求队列的最大长度和最小长度。
步骤26:将上述统计信息和两个队列封装为一个树节点。
步骤27:判断该节点是否为根节点,如果是则跳转步骤28,否则跳转步骤210。
步骤28:通过变化频率最低的可变域的索引序列,寻找第一个,并且前一个字节不为0x00的字节的索引为划分依据字节。
步骤29:根据划分依据对请求队列和请求响应队列进行划分。
步骤210:如果该节点的最小变化率索引和其兄弟节点的最小变化率索引有交集,则该子节点集合中所有的节点都应划分,如果需要继续划分则跳转步骤211,否则跳转步骤216。
步骤211:获取此节点中变化率最小,并且前一个字节不为0x00的字节,查看该字节是否存在于其兄弟节点的不可变域中,如果存在,则该节点和其他兄弟节点各自按照其变化率最小且前一个字节不为0x00的字节进行划分,否则统计每个子节点其变化率最小且前一个字节不为0x00的字节,每个子节点依据此字节进行划分。根据此规则获取该节点的划分的依据。
步骤212:判读划分的依据是否为同一字节。如果是则跳转步骤213,否则跳转步骤214。
步骤213:使用获取的同一个字节,对请求与请求响应的队列进行划分。
步骤214:通过变化率最小,并且前一个字节不为0x00的字节的条件获取该节点的划分依据。
步骤215:对该节点自身的划分依据对请求队列与响应请求队列进行划分。
步骤216:判断是否所有的节点都通过划分操作。如果是则跳转步骤217,否则跳转步骤218。
步骤217:划分完毕,协议树构建完成,停止协议树的学习操作。
步骤218:获取下一个未划分的节点,进行学习操作。
图3是本发明基于工控私有协议的协议特征学习方法的流程示意图,如图3所示,其步骤包括:
步骤31:通过叶子节点开始协议特征的学习。
步骤32:获取一个分好类的叶子节点。
步骤33:开始学习该节点中可变域样本频率的学习。
步骤34:获取该节点中的数据包请求队列。
步骤35:使用该节点的最大长度为最大值遍历所有请求数据的索引。
步骤36:每遍历到一个索引之后查看该索引是否存在于该节点的不可变域中,如果存在则跳转到步骤35,否则跳转到步骤37。
步骤37:将该索引在请求队列出现的所有值进行统计。
步骤38:对所有统计出的值,统计它们各自在请求队列中出现的频率。
步骤39:判断该遍历的索引是否为最后一个可变域索引,如果是则跳转到步骤310,否则跳转到步骤35。
步骤310:统计所有可变域的样本频率之后,生成该节点的可变域样本频率特征。
步骤311:对该节点的长度域开始进行学习。
步骤312:通过该节点的可变域,找到所有可能成为长度域的索引,构成长度序列
步骤313:遍历一个请求队列的序列,统计该序列的子集,不包含自身序列。
步骤314:根据长度序列和该序列的子集,子集出现在长度域之后,长度域的值为子集的长度,以向量的形式表示一种长度域的可能性,一个序列统计出一个向量集表示来长度域的多种可能性。
步骤315:判读该数据序列是否为最后一个请求队列的序列,如果是,跳转到步骤316,否则跳转到步骤313。
步骤316:每个序列进行长度向量集的统计,生成该节点长度向量集的集合。
步骤317:对整个该节点长度向量集的集合求交集。
步骤318:生成最终的该节点的长度向量集特征。
步骤319:开始对该节点进行apriori关联规则的学习。
步骤320:定义该方法的最小支持度和最小置信度。
步骤321:对每个序列,以索引值的方式,生成一个序列的样本,再生成该节点的样本集。
步骤322:通过节点的样本集,统计每个样本中的个体在样本集中出现的次数,计算该样本个体的支持度。
步骤323:以样本个体作为项集,和它所对应的支持度生成初始样本频繁集,对初始样本频繁集进行裁剪生成初始频繁集。
步骤324:对频繁集中的项集,通过数据表中的自连接方法,进行自连接操作,除去相同项集的自连接结果。
步骤325:两个项集长度都为k,如果不是具有k-1个相同的个体索引值,则将该两个项集自连接的结果除去,如果自连接的结果项集有一个子集不存在于前一轮的频繁集中,则将该自连接的结果除去。进行项集的过滤操作。
步骤326:通过前一轮的频繁集,统计项集在样本集中出现的频率,得到的自连接的项集的支持度。
步骤327:使用最小支持度对自连接结果进行裁剪,生成该轮次的频繁集。
步骤328:判断经过裁剪之后该频繁集是否内部项集个数为零,如果是,则跳转步骤329,否则跳转步骤319。
步骤329:得出一个频繁集,对其项集进行置信度的学习,获取一个项集,统计其所有的子集,不包括其本身。
步骤330:生成该项集条件结果的对应列表,保证条件子集索引全在结果子集索引之前。
步骤331:生成该项集的条件结果集合。
步骤332:获取一个条件结果,通过上述置信度计算公式计算其置信度。
步骤333:判断是否为条件结果集合中最后一个条件结果,如果是,则跳转步骤334,否则跳转步骤332。
步骤334:对该项集学习到的条件结果、置信度集合通过最小置信度进行裁剪,生成该项集最终的关联规则集。
步骤335:判断是否为频繁集中最后一个项集,如果是,则跳转步骤336,否则跳转步骤329。
步骤336:对该频繁集中条件结果、置信度的所有情况进行统计,生成该节点的apriori关联规则特征集。
步骤337:开启对请求响应队列中的请求响应对的进行协议关系的学习。
步骤338:获取该节点的请求响应队列。
步骤339:对该获取的请求响应队列,遍历一个请求响应对。
步骤340:以请求序列的长度加一为行数,响应序列的长度加一为列数,形成比对矩阵,根据上述的填充规则,首先填充第一行和一列的值,然后再填充剩下的矩阵值,完成比对矩阵的创建。
步骤341:使用比对矩阵的回溯方法,从矩阵右下角开始回溯。若行列对应的索引值相等,则回溯到左上角单元格,并且对请求与响应的索引进行对应记录,若行列对应的索引值不相等,回溯到左上角、上边、左边中值最大的单元格,若有相同最大值的单元格,优先级按照左上角、上边、左边的顺序。回溯到矩阵左上角为止。
步骤342:对回溯过程中相等的索引,以成对的方式进行记录。
步骤343:回溯结束之后,生成一对请求响应的比对特征。
步骤344:判断是否为该请求响应队列的最后一个请求响应对,如果不是,则跳转步骤339,否则跳转步骤345。
步骤345:统计完该节点下的所有请求响应对之后,对所有请求响应对的比对特征求交集。
步骤346:所得的交集为该节点的请求响应协议比对特征。
步骤347:将学习的可变域的样本频率、长度域集合特征、apriori关联规则特征集,请求响应协议比对特征依附于该叶子节点上。
步骤348:判断该节点是否为此协议树最后一个叶子节点,如果是,则跳转步骤349,否则跳转步骤32。
步骤349:生成该协议树中叶子节点的协议特征,结束协议特征的学习。
图4是本发明基于工控私有协议的模糊测试方法的流程示意图,如图4所示,其步骤包括:
步骤41:开始模糊测试过程,向被测对象发送测试用例,监听响应数据。
步骤42:获取协议树中的所有叶子节点。
步骤43:根据协议树获取到的叶子节点,随机选择一个叶子节点。
步骤44:使用该节点的最大长度,最小长度,最后一个不可变域的索引,和随机数生成方法,确定数据域的长度。
步骤45:遍历数据域,对每个索引字节进行随机填充,生成该测试用例的数据域部分。
步骤46:根据该节点的不可变域和该节点父节点的不可变域,确定该节点的不可变域的差集。
步骤47:根据该节点的不可变域的差集,随机选择一个不可变域差集的索引字节进行变异。
步骤48:使用apriori关联规则的结果概率,随机选择关联规则的条件或结果,使用可变域的变异规则,随机选择一个索引字节进行变异操作。
步骤49:获取该节点的长度域集合,对所有长度域进行遍历,对每个长度域进行变异操作。
步骤410:将以进行处理变异的特征,apriori特征,长度域特征,不可变域加入到变异记录队列。
步骤411:获取该节点的可变域,遍历该节点的可变域。
步骤412:判断此可变域的索引是否在记录队列里。如果是,则跳转步骤411,否则,跳转步骤413。
步骤413:对变异到的索引字节进行随机变异。
步骤414:对进行了变异操作的索引加入到记录队列。
步骤415:判断该遍历的可变域是否是该节点最后一个可变域,如果是,则跳转步骤416,如果不是,则跳转步骤411。
步骤416:和之前生成的数据域进行合并,生成一个测试用例。
步骤417:通过socket技术,与被测对象进行tcp连接。
步骤418:判断tcp连接是否连接成功,如果连接成功,则跳转到步骤419,如果未连接成功,则认为是异常信息需要进行报警操作,则跳转步骤424。
步骤419:通过socket向被测对象send该生成的测试用例。
步骤420:判断发送的测试用例是否接受到了被测设备的响应,如果接受到了,则跳转步骤421,否则跳转步骤43。
步骤421:将发送的测试用例和该测试用例接受到的响应进行配对,保存到缓存队列中。
步骤422:使用学习的请求响应协议比对特征对该请求与响应数据进行比对。
步骤423:查看通过请求响应协议比对特征是否匹配成功,如果成功则跳转步骤425,否则,发生请求与响应信息不匹配,认为是异常信息,需要报警操作,跳转步骤424。
步骤424:将未成功建立tcp连接或请求响应未匹配成功的异常信息记录到报警信息数据库中。
步骤425:判读用户是否自行停止模糊测试过程,如果是,则跳转步骤426,否则跳转步骤43。
步骤426:完成一次模糊测试,停止该模糊测试过程。
本发明可以解决在面对工控私有网络协议的情况下进行漏洞挖掘的问题,相比较于传统模糊测试框架,具有更高的测试效率。
应当理解,虽然本说明书根据实施方式加以描述,但是并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为了清楚起见,本领域的技术人员应当将说明书作为一个整体,各个实施方式中的技术方案也可以适当组合,按照本领域技术人员的理解来实施。
上文所列出的一系列详细说明仅仅是针对本发明的可行性实施方式的具体说明,它们并非用于限制本发明的保护范围,凡是未脱离发明技艺精神所作的等效实施方式或变更均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!