一种小小区动态时分双工结合Q学习的上下行子帧的配置方法与流程
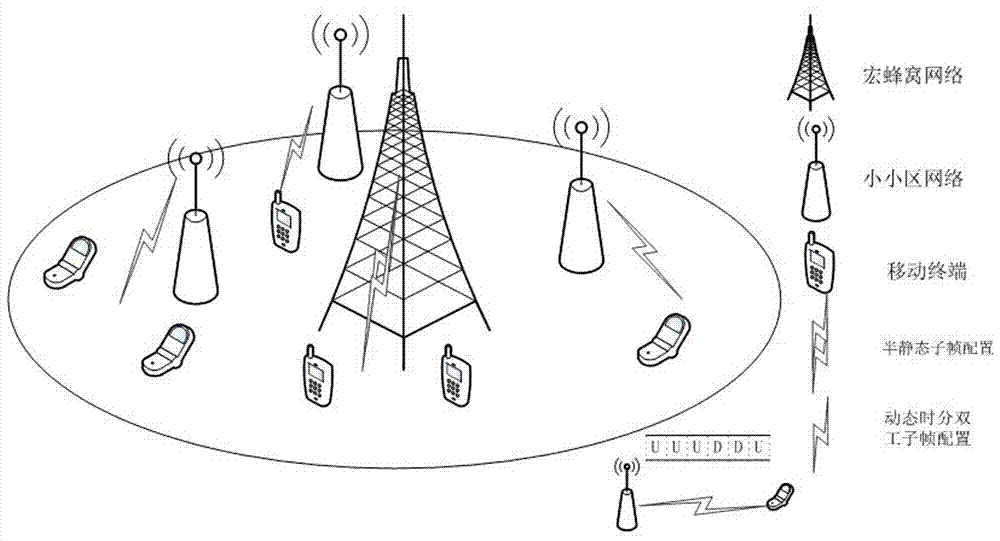
本发明涉及无线通信技术领域,具体是一种小小区动态时分双工结合q学习的上下行子帧的配置方法。
背景技术:
小小区网络技术被认为是一种解决当前移动数据流量爆炸式增长的通信技术手段之一,也是移动通信技术演进及下一代移动通信网络的关键技术之一。但由于小小区网络所服务的移动终端较少,移动终端在小区间的切换较为频繁,导致了小小区网络中数据业务的变化难以计算,上下行业务量很难维持在一个相对比较稳定的比例,因此,传统宏蜂窝小区里的半静态子帧重配置将无法使用,不能满足不同移动终端的业务量需求,造成频谱资源的巨大浪费。如何使小小区网络能够及时有效地调整其子帧配置成为当前急需解决的问题。动态时分双工技术为克服这一问题提供了很好的方向,动态时分双工作为当前热门的移动通信技术,其特点为不需要成对的频率、能使用各种频率资源、适用于不对称的上下行数据传输速率,能明显的表现出频谱资源丰富的优势。
技术实现要素:
本发明的目的是针对现有技术的不足,而提供一种小小区动态时分双工结合q学习的上下行子帧的配置方法。这种方法能使小小区频谱高效地用在智能终端、能提高小小区频谱效率和能量效率。
实现本发明目的的技术方案是:
一种小小区动态时分双工结合q学习的上下行子帧的配置方法,包括如下步骤:
1)构建动态时分双工小小区系统模型:定义系统模型中,宏蜂窝网络和小小区网络使用不同的频谱,将动态时分双工技术运用在小小区网络中,在这种系统模型场景中,宏蜂窝网络和宏蜂窝网络所连接的移动终端对小小区网络以及小小区网络所连接的移动终端的影响可以忽略不计,为实际应用提供了可能性,在固定时刻内,每一个小小区的上下行子帧重配置决策独立于其他小小区,即一部分小小区处于下行阶段,另一部分小小区处于上行阶段,因此,在这种系统场景下,小小区网络之间不需要保持同步,系统模型中包含(s,a,p,r)四个集合,其中s是环境状态的离散集合,s={s0,s10,lstls100},每个环境状态的下标表示在固定周期内,小小区网络接收到其连接的移动终端所反馈的下行缓存中待传总比特数的百分比,a是动作状态的离散集合a={ai,aj},ai表示小小区网络保持之前的子帧配置不变,aj表示小小区网络改变之前的子帧配置,p是一个状态转移函数:p=s*a*s∈[0,1],r是回报函数,r={r-5,r-4,lrdlr5},(-5≤d≤5);
2)定义系统模型的状态转移函数p和回报函数r:系统模型假设小小区网络不知道状态转移函数p和回报函数r,在系统模型中,小小区网络的任务是学习从环境状态到动作状态的对应,从而获得最佳的回报函数,小小区网络根据其连接的移动终端所反馈的上下行缓存中待传总比特数量,调整子帧的配置方案。每个回报函数的下标表示在固定周期内,小小区网络根据选择的动作动态配置子帧所产生的回报信号,系统中采用的动作模型为无限范围模型,即折扣回报模型或动作序列无限模型,其回报函数r表示为公式(1):
式中,γ为折扣因子(0<γ<1),用来调整小小区在系统中的配置周期,当γ=0时,表示小小区网络只考虑立即回报;γ越接近1,表示小小区网络考虑了长期回报,系统中的最终目标为促使小小区获得最佳的回报函数r,小小区与其所连接的移动终端设备的交互行为是马尔科夫决策过程,通过动态规划的方法解决,在状态转移函数p中,小小区设备从状态t到状态t+1的转移概率只依赖于状态t的动作,即为一个随机过程x,用at,(at∈a)表示在小小区设备在状态t时的所有可能的动作集,则状态转移概率函数表示为公式(2):
ptt+1(at)=pr(xt+1=st+1|xt=st,a(t)=at)(2);
3)设置上下行子帧重配置周期:设置系统模型中动态时分双工技术的上下行子帧重配置周期为10ms-200ms,越短的重配置周期具有较强适应动态变化的能力,但是所需要的网络开销也越大,区别于传统时分双工的子帧类型,系统中不设置特殊子帧,每个子帧都可以动态变化为上行或下行子帧,转换时的保护间隔可放在下行子帧的最后面或者上行子帧的最前面;
4)配置单位周期内小小区上下行子帧:在每一个周期内,小小区网络根据连接的移动终端所反馈的业务类型中得到一个环境状态信号st,st∈s,通过这个环境状态信号在动作状态的离散集合中选择一个动作a,a∈a,一旦动作a执行,小小区就针对性的调整上下行子帧配置并产生一个回报信号rd,rd∈r,即rd表示在状态st时选择动作a后的回报;
5)构造系统模型目标函数:系统模型的最终的目标是小小区获得最佳的回报函数r,即小小区在固定周期内寻求一个策略π,考量策略的标准是根据策略在未来的折扣回报期望值,即值函数vπ(st):
值函数vπ(st)在状态st,策略π下表示为公式(3):
式中,r(st,π(st))定义为系统模型中小小区设备在状态st时采取策略π得到的期望回报,γ为折扣因子,
6)优化目标函数:在系统模型中,优化目标函数采用值迭代方法中的q学习方法,小小区设备通过优化更新值函数来寻找最优策略,并从反馈函数中通过不断迭代获得值函数的估计值,即值迭代方法,在值迭代方法中,不需要知道详细的策略,只需要了解每个状态的最优值对应的动作状态,q学习方法即属于值迭代方法中较为常见的一类,假设公式(5)qπ(st,a)表示在策略π下,状态st时采取动作a后的折扣回报函数,则
系统模型中小小区设备执行动作得到回报函数后更新相应的qπ(s,a)表来评价决策的性能,
更新qπ(s,a)的表达式为公式(6):
qπ(st,a)=qπ(st,a)+α(r(st,a)+γmaxq(st+1,ai)-qπ(st,a))(6),
其中α为学习率(0<α<1),γ是折扣因子(0<γ<1),st+1,ai分别表示转移到的下一状态及在状态st+1时可能采取的动作,系统模型中小小区设备为了得到最佳值函数为
①对于所有状态集s,初始化值函数v0(st),st∈s;
②n≥0,对所有的环境状态st∈s,动作状态a∈a,进行迭代,
动作值函数为公式(7):
状态值函数公式(8):vn+1(st)=maxqn+1(st,a)(8)
③迭代有限次数后,算法能收敛到最优策略为公式(9):
步骤3)中所述的上下行子帧重配置周期为200ms。
这种方法设计了一种系统模型:小小区设备采用动态时分双工技术,利用q学习算法,学习环境状态到动作的映射来获得最佳上下行子帧配置比,当移动终端有更多的下行包需要传送时,小小区设备利用基于q学习算法的动态时分双工技术让系统自动选择下行子帧较多的配置,当小小区网络中上行包的数量大于下行包的数量时,小小区设备选择上行子帧较多的配置,小小区网络根据自身的业务量状况动态的选择合适的上下行子帧配置,能更加灵活适应业务需求,对降低小小区基站端能耗也有一定作用,动态时分双工上下行子帧配置有两方面的含义:从时间上看,某一个特定小小区设备在一段时间内可能会根据网络情况采用不同的上下行子帧配置;从空间上看,对于较大区域中的网络内各个小小区设备可能采用不同的上下行子帧配置。
这种方法解决了因传统的半静态子帧重配置而造成频谱资源的巨大浪费问题,将小小区网络根据所处的复杂环境,不断学习、不断“试错”,得到环境信息从而调整上下行子帧配置来达到最大回报,使频谱高效地用在智能终端、能提高频谱效率以及能量效率。
附图说明
图1为实施例中方法流程示意图;
图2为实施例中小小区网络中动态时分双工系统模型示意图。
具体实施方式
下面结合附图和实施例对本发明内容作进一步的说明,但不是对本发明的限定。
实施例
参照图1,图2,一种小小区动态时分双工结合q学习的上下行子帧的配置方法,包括如下步骤:
1)构建动态时分双工小小区系统模型:定义系统模型中,宏蜂窝网络和小小区网络使用不同的频谱,将动态时分双工技术运用在小小区网络中,在这种场景中,宏蜂窝网络和宏蜂窝网络所连接的移动终端对小小区网络以及小小区网络所连接的移动终端的影响可以忽略不计,为实际应用提供了可能性,在固定时刻内,每一个小小区的上下行子帧重配置决策独立于其他小小区,即一部分小小区处于下行阶段,另一部分小小区处于上行阶段,因此,在这种系统系统模型场景下,小小区网络之间不需要保持同步,系统模型中包含(s,a,p,r)四个集合,其中s是环境状态的离散集合,s={s0,s10,lstls100},每个环境状态的下标表示在固定周期内,小小区网络接收到其连接的移动终端所反馈的下行缓存中待传总比特数的百分比,a是动作状态的离散集合a={ai,aj},ai表示小小区网络保持之前的子帧配置不变,aj表示小小区网络改变之前的子帧配置,p是一个状态转移函数:p=s*a*s∈[0,1],r是回报函数,r={r-5,r-4,lrdlr5},(-5≤d≤5);
2)定义系统模型的状态转移函数p和回报函数r:系统模型假设小小区网络不知道状态转移函数p和回报函数r,在系统模型中,在系统模型中,小小区网络的任务是学习从环境状态到动作状态的对应,从而获得最佳的回报函数。小小区网络根据其连接的移动终端所反馈的上下行缓存中待传总比特数量,调整子帧的配置方案,每个回报函数的下标表示在固定周期内,小小区网络根据选择的动作动态配置子帧所产生的回报信号,系统中采用的动作模型为无限范围模型,即折扣回报模型或动作序列无限模型,其回报函数r表示为公式(1):
式中,γ为折扣因子(0<γ<1),用来调整小小区在系统中的配置周期,当γ=0时,表示小小区网络只考虑立即回报;γ越接近1,表示小小区网络考虑了长期回报,系统中的最终目标为促使小小区获得最佳的回报函数r,小小区与其所连接的移动终端设备的交互行为是马尔科夫决策过程,通过动态规划的方法解决,在状态转移函数p中,小小区设备从状态t到状态t+1的转移概率只依赖于状态t的动作,即为一个随机过程x,用at,(at∈a)表示在小小区设备在状态t时的所有可能的动作集,则状态转移概率函数表示为公式(2):
ptt+1(at)=pr(xt+1=st+1|xt=st,a(t)=at)(2);
3)设置上下行子帧重配置周期:设置系统模型中动态时分双工技术的上下行子帧重配置周期为10ms-200ms,越短的重配置周期具有较强适应动态变化的能力,但是所需要的网络开销也越大,区别于传统时分双工的子帧类型,系统中不设置特殊子帧,每个子帧都可以动态变化为上行或下行子帧,转换时的保护间隔可放在下行子帧的最后面或者上行子帧的最前面;
4)配置单位周期内小小区上下行子帧:在每一个周期内,小小区网络根据连接的移动终端所反馈的业务类型中得到一个环境状态信号st,st∈s,通过这个环境状态信号在动作状态的离散集合中选择一个动作a,a∈a,一旦动作a执行,小小区就针对性的调整上下行子帧配置并产生一个回报信号rd,rd∈r,即rd表示在状态st时选择动作a后的回报;
5)构造系统模型目标函数:系统模型的最终的目标是小小区获得最佳的回报函数r,即小小区在固定周期内寻求一个策略π,考量策略的标准是根据策略在未来的折扣回报期望值,即值函数vπ(st):
值函数vπ(st)在状态st,策略π下表示为公式(3):
式中,r(st,π(st))定义为系统模型中小小区设备在状态st时采取策略π得到的期望回报,γ为折扣因子,
6)优化目标函数:在系统模型中,优化目标函数采用值迭代方法中的q学习方法,小小区设备通过优化更新值函数来寻找最优策略,并从反馈函数中通过不断迭代获得值函数的估计值,即值迭代方法,在值迭代方法中,不需要知道详细的策略,只需要了解每个状态的最优值对应的动作状态,q学习方法即属于值迭代方法中较为常见的一类,假设公式(5)qπ(st,a)表示在策略π下,状态st时采取动作a后的折扣回报函数,则
系统模型中小小区设备执行动作得到回报函数后更新相应的qπ(s,a)表来评价决策的性能,
更新qπ(s,a)的表达式为公式(6):
qπ(st,a)=qπ(st,a)+α(r(st,a)+γmaxq(st+1,ai)-qπ(st,a))(6),
其中α为学习率(0<α<1),γ是折扣因子(0<γ<1),st+1,ai分别表示转移到的下一状态及在状态st+1时可能采取的动作,系统模型中小小区设备为了得到最佳值函数为
①对于所有状态集s,初始化值函数v0(st),st∈s;
②n≥0,对所有的环境状态st∈s,动作状态a∈a,进行迭代,
动作值函数为公式(7):
状态值函数公式(8):vn+1(st)=maxqn+1(st,a)(8)
③迭代有限次数后,算法能收敛到最优策略为公式(9):
本例步骤3)中所述的上下行子帧重配置周期为200ms。
- 还没有人留言评论。精彩留言会获得点赞!