一种NB-loT系统中下行主同步信号精同步的检测和估计方法与流程
本发明涉及蜂窝窄带物联网nb-lot技术领域,尤其是一种nb-lot系统中下行主同步信号精同步的检测和估计方法。
背景技术:
nb-iot技术是iot领域一个新兴的技术,支持低功耗设备在广域网的蜂窝数据连接。nb-iot技术是针对窄带、低速业务场景全新定义的通信协议。其相对于lte协议来说在物理层进行了全新设计,其中对于基站下行发送信号来说,主辅同步信号虽然依然采用zc序列,然而由于带宽等参数的变化,信号序列和结构都发生了较大变化,而针对nb-iot下行信号的检测也成为研究热点之一。
由于npss粗同步是在240khz上进行的,因此其得到的时偏在工作频率1.92mhz下的精度来看存在前后8个采样点的误差。同时,粗同步在240khz下采样做间隔为17点的差分,当差分两点的相位差为2π的整数倍时,该算法无法检测出相位为2π的整数倍频偏,因此其频偏估计的精度范围被限制在(-8/17,8/17)×15khz区间中。同步的实际频偏往往大于此范围,所以精同步除了要完成1.92mhz下的时间同步外,还需要完成整数倍频偏的纠正。
nb-iot系统中的npss序列由zadoff-chu序列生成。zadoff-chu有非常良好的循环自相关性,即基于同一组基序列的zadoff-chu序列同其每个循环移位得到的序列都是正交的(相关为0)。同时,基于同步基序列的zadoff-chu序列同样正交。同时,zadoff-chu序列为恒幅相位跳变的序列,该序列经过fft/ifft变换以后依然能保持恒幅的特性。由于zadoff-chu有以上理想的特性,因此该序列在lte和nb-iot标准中被广泛采用。
相对于lte的更大带宽(主同步信号占据1.08mhz)的带宽,即6个rb共72个子载波(66个载波发送有效信号),nb-iot同步信号的最大带宽仅为1个rb共12个子载波(11个载波发送有效信号)。考虑到检测信噪比,因此nb-iot在时域上延展了10个符号,即在时/频域上分别都有11个re(resourceelement)资源组成的方块。在zc序列的选择方面,采用了短zc序列的方式,即每个符号下使用相同的11点的zc序列,再在不同符号下使用扰码(codecover)进行极性变换进行进一步加扰。
每个符号(从符号3开始)发送的数据为发送zc序列用dl(n)表示为如下公式,其中u等于5,n表示频域标示符。
生成zc序列映射到该符号下的0~10号载波下。这样经过映射以后得到11*11的方阵。再逐符号执行ifft以及插入循环前缀(cp)后形成时域波形。不同符号之间,使用如下的code-cover码进行区分,code-cover码用sii=3,...,13表示。对每个符号的时域信号乘以对应的扰码值。
根据zadoff-chu序列的特性,nb-iot终端采用相关检测的方式进行检测。该相关检测器可以设计在时域,也可以设计在频域,然而由于在符号未同步的情况下,滑窗逐点fft将大大提升复杂度,因此大部分方法均在时域中进行估计。
不同的在npss定时同步中,用户预先端储存本地的复数npss序列,与接收数据进行滑动相关,通过相关输出模值的峰值,从而完成npss的定时同步。
精同步原理采用接收序列与本地生成序列进行互相关,根据互相关峰值计算时偏和频偏。在1.92mhz采样率下去除cp后一个符号的序列长度为128点。假设接收到的序列
γ(τ)=[r1r2…r10r11]
其中,rii=1,…,11表示一个ofdm符号时域的采样点,长度为128点的向量ri=[r1,r2,…r128]。
本地序列为η=[s1s2…s10s11],其中sii=1,…,11是长度为128点的时域信号,si=[s1,s2,…s128]
接收序列与本地序列互相关得到的结果为ρ(τ)
假设接收序列的起始位置τ和整数倍频偏,去除cp后组成1408长的序列,与本地生成的长度为1408的时域序列互相关,找出互相关的峰值,从而得到时偏和频偏估计结果。该算法每次需要计算不同的起始位置和整数倍频偏的序列值,序列存储大,算法复杂度高,不利于硬件实现。
技术实现要素:
本发明所要解决的技术问题在于,提供一种nb-lot系统中下行主同步信号精同步的检测和估计方法,能够采用流水线的设计结构实现时频偏的初步搜索估计,采用多符号累加的流水线结构减少了后续的计算量和存储大小。
为解决上述技术问题,本发明提供一种nb-lot系统中下行主同步信号精同步的检测和估计方法,包括如下步骤:
(1)空口接收机采用1.92mhz的采样速率得到时域采样序列;
(2)终端接收机进行npss粗同步估计;
(3)根据步骤(2)中粗同步估计出的时偏和频偏结果在1.92msps采样率下进行二次精同步,使用npss序列与本地序列进行自相关操作;本地序列使用整数倍频偏生成,根据峰值位置最大值确定精确时偏和整数倍频偏。
优选的,步骤(3)中,二次精同步具体包括如下步骤:
(31)在npss初始粗同步过门限以后,随机启动计时器开启npss精同步的操作;计时器记录一个无线帧长度后,于下个无线帧的npss起始位置,使能npss精同步;
(32)npss输入时域信号经过两个加法器存储到长度为128+17长的序列中;
(33)各个符号之间的累加使用两个加法器逐点进行;其中,第一个加法器负责前128点的第n次累加的;而后一个加法器负责后17点的第n-1次累加;当数据点逐点输入时,前一个加法器实现对应的寄存器中的历史值同当前值的计算,并将计算结果写回到寄存器中更新历史值;当第一个加法器执行完128点后,第一个加法器停止执行,其将等待10或9个采样点后,跳回寄存器初始位置开始下一次累加;而当第一个加法器停止执行后,第二个加法器开始执行操作,其将继续完成17点的累加和更新操作,并等待第一个加法器执行完128点;
(34)当11点的ofdm符号的11次累加都结束以后,开始执行预存的本地序列同寄存器中的序列的逐点相乘;其中每一种本地序列5种和一种起始位置17种下的寄存器序列相乘累加后的结果值依序保存到一个85点的buffer中;
(35)在85点的缓存中取模,找到最大值后确定整数频偏和时偏结果。
优选的,步骤(31)中,初始粗同步的门限值为240khz。
优选的,步骤(34)中,5组整数倍频偏仅保存一组,其他整数倍的频偏的结果通过其同预存的一倍整数频偏的结果逐点相乘后再同接收序列相乘并累加。
优选的,步骤(34)中,需要两个长度为128点的缓存器;第一缓存器中存放的是带有2δf频偏的不包含covercode的本地npss时域序列,用d-2δfnpss(t)表示即
其中,t取值0-127,表示每个ofdm符号128点的采样长度;
第二缓存器中存放的是固定为δf的频偏的128长度的序列:
dδf(t)=e-j2π·(δf)tt=0,…,127
上述两公式相乘,则有
本发明的有益效果为:精同步采用先累加后相关操作,从而降低了存储量;精同步采用基于两个加法器和一个乘法器的流水线结构减小了计算量和存储大小;精同步频偏估计采用存储一组本地序列并进行迭代更新来替代多组本地序列,从而降低了存储量。
附图说明
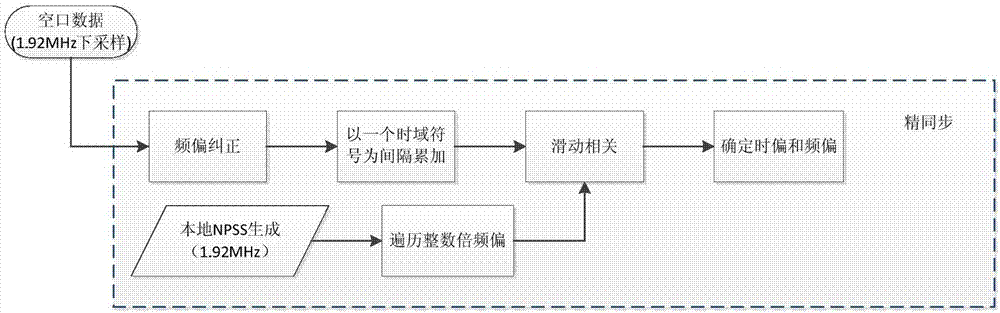
图1为本发明的方法流程示意图。
图2为本发明的精同步硬件实现结构示意图。
图3为本发明的二次精同步中使用两个加法器逐点进行累加和更新操作过程中的时序图。
具体实施方式
如图1所示,一种nb-lot系统中下行主同步信号精同步的检测和估计方法,包括如下步骤:
(1)空口接收机采用1.92mhz的采样速率得到时域采样序列;
(2)终端接收机进行npss粗同步估计;粗同步在240khz的采样率下进行,使用差分自相关的方法估计出时偏和分数倍频偏粗估计;
(3)根据步骤(2)中粗同步估计出的时偏和频偏结果在1.92msps采样率下进行二次精同步,使用npss序列与本地序列进行自相关操作;本地序列使用整数倍频偏生成,根据峰值位置最大值确定精确时偏和整数倍频偏。
精同步原理本质上是使用npss本地序列同接收信号序列进行互相关,通过找出互相关的最大值来实现检测的。精同步是为了纠正粗同步后残留的时偏和频偏。粗同步已经大大缩小了时偏的搜索范围,有效减少了直接在1.92m下同步的运算复杂度。
由于npss粗同步是在240khz上进行的,因此其得到的时偏在工作频率1.92mhz下的精度来看存在前后8个采样点的误差。二次精通步工作在1.92mhz可以纠正240k下残留的时偏估计的误差。
同时,由于粗同步使用的是间隔为17点的差分,因此其频偏估计的精度范围被限制在(-8/17,8/17)×15khz,在实际接收中,频偏有可能会远远大于该范围,因此需要遍历多种整数频偏(n倍的(128/137)×15khz)进行检验。根据经验,这里n选择0,正负1,正负2。
npss信号序列在去掉循环前缀cp后为(1.92mhz)是1408点。另一方面,本地序列可以根据不同的整数频偏生成5组进行缓存,而接收信号由于时偏的不确定,可以存储一个大于1408点的窗并在上面进行滑动相关。然而,由于npss发送的是分段的短zc序列,即每个符号长度下的zc序列都是一样的,所不同的只是在不同的符号下,其序列的极性可能整体取反。其是否取反根据预设的加扰码(codecover)来确定。
因此,我们可以考虑将不同端(不同符号)的128点接收信号进行累加(根据codecover的极性)后对接收信号和本地序列都仅保留一个符号的长度,从而降低了存储器的要求和乘法器的运算量。
本发明中,首先对每个ofdm符号发送的是zc序列可以进行合并,一个ofdm的时序符号在1.92mhz下采样为128点,从而将1408的序列长度降低到128,节省了储存空间;其次由于整数倍频偏是个固定值可以预先将结果存储下来以节省运算开销。
工作在1.92mhz下的二次精通步在纠正240khz下残留的时偏估计的误差时,根据粗同步估计出的起始位置,将在1.92mhz采样率下选取前后17点做滑动相关。这是由于考虑到粗同步下的时偏可能存在正负8点的偏差,因此多前后多存储各8个点以保证时偏的正确性。根据17点不同的起始位置去除cp,将不同符号合并,所以在合并接收信号时缓存大小一共需要145点。精同步还需要遍历多种整数倍频偏。根据经验,整数倍频偏的遍历选择0,±1,±2。
由于npss发送的是分段的短zc序列,即每个符号长度下的zc序列都是一样的,所不同的只是在不同的符号下,其序列的极性可能整体取反。其是否取反根据预设的加扰码(codecover)来确定。因此,我们可以考虑先消去codecover的极性,然后将不同ofdm符号的接收信号进行累加,最后接收信号可以合并为一个ofdm符号的长度。同理,本地相关序列也只需要一个ofdm的符号长度即可完成互相关,从而降低了存储器的要求和乘法器的运算量。另一方面,本地序列可以根据不同的整数频偏生成5组预先缓存。
step0:在npss初始粗同步(240khz)过门限以后,随机启动计时器开启npss精同步的操作。计时器记录一个无线帧长度后,于下个无线帧的npss起始位置(第一个有效符号,不含cp),使能npss精同步。
step1:npss输入信号经过两个加法器存储到长度为128+17长的序列中。之所以选择该长度的序列是出于两方面考虑。其一,由于前述的短zc序列的性质,因此通过不同符号的累加操作将各个符号的128点对位相加;其二,额外的17点是考虑粗同步下的时偏可能存在正负8点的偏差,因此多前后多存储各8个点。
step2:如图3所示,各个符号的累加使用两个加法器逐点进行的。其中,第一个加法器负责前128点的第n次累加的;而后一个加法器负责后17点的第n-1次累加。当数据点逐点输入时,前一个加法器实现对应的寄存器中的历史值同当前值的计算,并将计算结果写回到寄存器中更新历史值。当第一个加法器执行完128点后。第一个加法器停止执行。其将等待10或9个采样点(具体取值取决于当前操作第几个符号,即第几次累加)后,跳回寄存器初始位置开始下一次(下一个符号)累加。而当第一个加法器停止执行后,第二个加法器开始执行操作。其将继续完成17点的累加和更新操作,并等待第一个加法器执行完128点。
step3:当11次累加都结束以后,开始执行预存的本地序列同寄存器中的序列的逐点相乘。其中每一种本地序列(对应一种整数频偏)和一种起始位置下的寄存器序列相乘累加后的结果保存到一个85点的buffer中(5×17=85)。
step4:在85点的缓存中取模,找到最大值后确定整数频偏和时偏结果。
考虑到为了进一步节省本地存储的空间,5组整数倍频偏可以仅保存一组,如-2倍的整数频偏的结果。而其他整数倍频偏的结果可以通过其同预存的一倍整数频偏的结果逐点相乘后再同接收序列相乘并累加。
本发明中的精同步采用先累加后相关操作,从而降低了存储量;精同步采用基于两个加法器和一个乘法器的流水线结构减小了计算量和存储大小;精同步频偏估计采用存储一组本地序列并进行迭代更新来替代多组本地序列,从而降低了存储量。
如图2所示,用本地序列互相关算法来实现符号、帧头在高采样率下的精同步,并估计整数频偏,从而实现初始的同步接收。该方法在保证性能的情况下,有效的降低了实现复杂度。同时,本发明在给出算法的同时还给出了fpga的实现方案。
尽管本发明就优选实施方式进行了示意和描述,但本领域的技术人员应当理解,只要不超出本发明的权利要求所限定的范围,可以对本发明进行各种变化和修改。
- 还没有人留言评论。精彩留言会获得点赞!