一种基于LDA主题模型的电信用户相似度发现方法与流程
本发明涉及一种基于lda(latentdirichletallocation潜在狄利克雷分布)主题模型的电信用户相似度发现方法,属于数据挖掘、主题模型领域。
背景技术:
近年来,随着移动互联网行业的兴起,全球电信市场的规模越来越大,技术更新越来越快,各运营商之间以及运营商与互联网公司之间的竞争也日趋激烈。传统的通话业务和短信业务受到互联网公司旗下社交网络产品的猛烈冲击,针对这一现象,全球电信运营商纷纷提出转型战略,将服务策略从以业务为中心转向以客户为中心。因此,运营商必须更加深入地了解客户,进而调整运营策略,向用户提供更加优质的服务。
在大数据上升到国家战略的时代背景下,加上多年来运营商累积的海量用户数据条件下,充分挖掘电信用户数据的潜在价值不仅仅对于运营商,乃至社会各个行业都具有重要意义。
为了达到上述目标,对电信用户网络进行社团划分是其中一个研究方向,而社团划分中的一个重要环节就是对相似用户进行聚类。聚类是把相似对象归入同一簇,不同对象归到不同簇。由于通过聚类分析可以建立宏观的数据分布模式,了解数据属性之间的相关度,并推测相互关系,所以聚类在数据挖掘中得到广泛应用。
现有的电信用户相似度计算方法,虽然考虑了用户相关维度的特征属性,但并未结合移动用户的其他特点,例如手机app的使用情况、浏览历史记录、基站位置信息等,因此计算出来的相似度值具有一定的局限性,也间接影响之后聚类的准确性。而lda模型是一种对文档集建模的概率主题模型,是一种对文本数据的主题信息进行建模的方法。它由三层生成式贝叶斯网络结构组成,基于这样一种前提假设:在忽略文档中的语法结构和词语出现的先后顺序的情况下,文档是由若干个隐含的主题组成,而这些主题是由若干个特定词汇组成。因此,将电信用户所属基站位置信息抽象为文档,利用lda主题模型计算文档主题间的相似度,再结合用户基本属性、通话关系和短信关系这三方面内容,综合考虑用户的相似程度。
技术实现要素:
为解决现有技术的不足,本发明的目的在于提出一种基于lda主题模型的电信用户相似度发现方法,该方法将电信用户的多维特征与基于概率模型的主题发现算法有机地联系在一起,从四个层面考虑如何计算电信用户相似度,为聚类的准确性提供保证。
为了实现上述目标,本发明实施例采用如下的技术方案,包括以下步骤:
s1:采集用户信息;
s2:对s1中采集的用户信息进行预处理;
s3:对s2中预处理信息中的基本属性、用户通话记录和用户短信记录进行相似度计算;
s4:对s2中预处理信息中的用户在一天内所连基站位置信息,建立lda模型,计算该信息相似度;
s5:综合相识度计算,推测相互关系;
s6:以s4中推测出的相互关系进行聚类。
s2中采集的用户信息进行预处理,包括数据清理、数据集成、数据变换、数据规约4个步骤。
s3中用户基本属性,为以下14个属性,包括:消费金额、上网时长、性别是否不详、性别是否为女、性别是否为男、是否市区、是否县城、是否农村、消费金额是否在0~100间、消费金额是否在100~200间、消费金额是否在200~300间、消费金额是否在300~500间、消费金额是否在500~1000间、消费金额是否大于1000。
电信用户的基本属性:将每个用户抽象成一个特征向量,用向量夹角的余弦值衡量用户基本属性的相似性。值越大,则用户基本属性中的相似特征就越多。
用户通话记录:一是从通话时长角度,通话时长不仅仅取决于两用户互通电话的时间度量,还应考虑这两个用户与相邻用户的通话情况。二是从通话次数角度,假设在相同统计周期内,用户a与用户b进行了一次30分钟的通话,用户a与用户c进行6次5分钟的通话,显然用户a与用户c联系更加紧密。因此,两用户间相对通话时长越长,通话次数越多,相似度越高。
用户短信记录:短信记录与通话记录类似,但仅考虑用户间短信交流的条数,双方短信交流条数占其与相邻用户交流条数的比例越大,相似度越高。
用户在一天内所连基站位置信息:将一天划分为若干时间段,根据用户在不同时间段内连接基站的位置标签,构建地点转移文档作为lda主题模型的输入,得到文档的主题分布,以此计算文档间的相似度。
所述基于电信用户基本属性的相似度计算方法,公式如下:
其中,
基于电信用户通话记录和短信记录的相似度计算公式如下:
其中,c代表通话时长,f代表通话频率,s代表短信次数。cij表示用户i向用户j发起通话的时长,cji表示用户j向用户i发起通话的时长,ci代表用户i与相邻用户(包含用户j)的通话总时长,cj代表用户j与相邻用户(包含用户i)的通话总时长,其他变量的含义以此类推。
用户在一天内所连基站的位置信息建立lda模型,建模之前包括以下步骤:
(1)为某个地区的基站位置贴上4种标签:分别是家庭位置基站(home),工作地点基站(work),其他基站(other),未接收到任何连接请求基站(noreception)。这4种标签的含义分别是:用户处于家中;用户处于工作状态;用户在离住址和工作地点较远的位置;用户手机处于关机状态。
(2)将电信用户一天的行程抽象为地理位置标签序列。首先,构建一个细粒度的位置描述方式:将一天分为每20分钟一个时间块,选择该块内持续时间最长的基站位置标签作为该块的标签。因此某用户的一天就抽象为由72个位置标签组成的向量。
(3)为防止出现过拟合的情况,接着构建一个粗粒度的时间描述方式,将一天分为8个时间片,分别是:0~6am,6~9am,9~12am,12~2pm,2~5pm,5~7pm,7~9pm,9-12pm,编号为0~7。
(4)最后,构建地点转移语料库。语料库中某个文档下的一个词项包含连续2小时内的细粒度位置标签和一个粗粒度时间标签,例如hhhhhh0,hwwwww2等。
根据既定地点转移语料库中的所有文档,构建lda模型。所述文档集由指定用户一天中地点变化序列组成,所述词项集由6个细粒度位置标签和1个粗粒度时间标签构成。lda模型的生成过程,包括如下步骤:
(1)选择文档i的主题概率分布为
(2)选择主题k的词项概率分布为
(3)对于文档中的每个单词wi,j,选择一个主题zi,j~multinomial(θi)服从多项式分布;选择一个词项
根据上述过程得到的lda模型,计算某个文档基于超参数的联合概率分布:
其中ωm代表文档m中所有词构成的向量,zm表示文档m所对应的主题向量,θm代表文档m的主题概率分布,φ表示所有主题的词项概率分布,α,β是狄利克雷分布的超参数,nm代表文档m的长度,wm,n代表第m个文档下第n个词项,
根据上述过程所得联合概率分布,在建模过程中,利用吉布斯抽样方法进行参数估计,设置topic(主题)的初始个数k=30,超参数α=30/k,β=0.01,吉布斯采样的迭代次数为1000次,对语料库进行主题挖掘,生成每篇文章的主题概率分布p(z=k)=θk(d),每个主题下的词项概率分布p(w|z=k)=φw(k)。
所述每篇文章的主题概率分布计算公式如下:
其中,θm,k代表第m篇文章的第k个主题,nm,k表示文档m中出现第k主题的次数,k表示第m篇文档中主题总数,α为第一参数向量。
所述每个主题下的词项概率分布的计算公式如下:
其中,φk,w表示第k个主题下的第w号词,nk,w表示第k个主题下第w号词项出现的次数,v表示第k个主题下词的总数,β为第二参数向量。
根据上述所得文档的主题概率分布,计算两个文档主题间概率分布差异的距离,公式如下:
其中,d1、d2代表两个文档,i表示第i个主题编号,
所述一种基于lda主题模型的电信用户相似度发现方法,将用户的多维特征与基于概率的主题发现算法(lda)有机结合,综合得出用户的相似度计算公式如下:
其中,u1、u2代表用户1和用户2;η1表示利用基本属性计算的权值,设置η1=0.1;η2表示利用通话记录和短信记录计算的权值,设置η2=0.3;η3代表利用用户一天中连接基站位置信息计算的权值,设置η3=0.6,其余参数和上文保持一致。
本发明有益效果:
1.引入电信用户所连基站信息,将基站划分为不同类别,对用户一天中的位置行为利用lda进行建模,充分挖掘用户在日常行为中的相似性。
2.引入时间片划分用户,从粗、细两个粒度刻画用户一天中的日常习惯。最大程度避免了过拟合现象的产生。
3.将电信用户的多维特征与基于概率模型的主题发现算法(lda)有机地联系在一起,从四个层面考虑电信用户相似度,全面而合理。
附图说明
图1是本发明的相似度计算方法示意图。
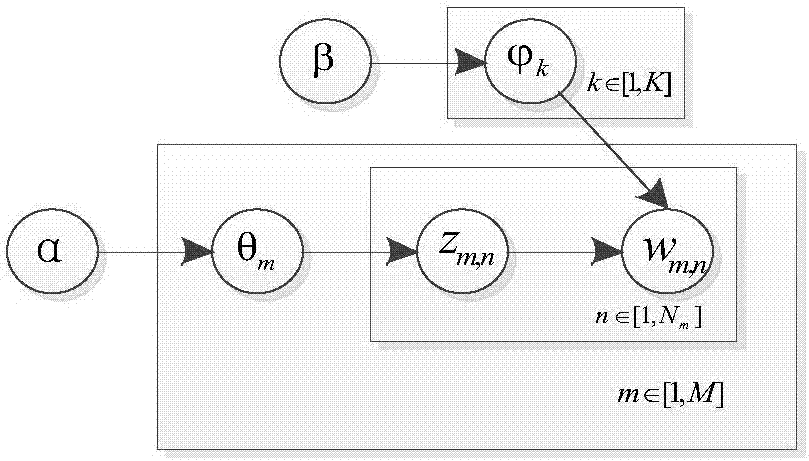
图2是本发明的lda主题模型图。
图3是本发明采用的lda模型的拓扑结构示意图。lda模型认为每篇文档是由多个主题混合而成,而每个主题又由多个词项表征。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合具体实施例,对本发明进行进一步详细说明。应当理解,此处所述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
一种基于lda主题模型的电信用户相似度发现方法,从四个层面考虑用户的相似度特性,包括:
电信用户的基本属性:将每个用户抽象成一个特征向量,用向量夹角的余弦值衡量用户基本属性的相似性。值越大,则用户基本属性中的相似特征就越多。
用户通话记录:一是从通话时长角度,通话时长不仅仅取决于两用户互通电话的时间度量,还应考虑这两个用户与相邻用户的通话情况。二是从通话次数角度,假设在相同统计周期内,用户a与用户b进行了一次30分钟的通话,用户a与用户c进行6次5分钟的通话,显然用户a与用户c联系更加紧密。因此,两用户间相对通话时长越长,通话次数越多,相似度越高。
用户短信记录:短信记录与通话记录类似,但仅考虑用户间短信交流的条数,双方短信交流条数占其与相邻用户交流条数的比例越大,相似度越高。
用户在一天内所连基站位置信息:将一天24小时划分为若干时间段,根据用户在不同时间段内连接基站的位置标签,构建地点转移文档作为lda主题模型的输入,得到文档的主题分布,以此计算文档间的相似度。
如图1所示,所述一种基于lda主题模型的电信用户相似度发现方法,其所需数据在使用前均已经过以下步骤,包括:数据清理、数据集成、数据规约、数据变换。
接下来从预处理完成后的数据中提取用户的基本属性,有如下14个:消费金额、上网时长、性别是否不详、性别是否为女、性别是否为男、是否市区、是否县城、是否农村、消费金额是否在0~100间、消费金额是否在100~200间、消费金额是否在200~300间、消费金额是否在300~500间、消费金额是否在500~1000间、消费金额是否大于1000。这些属性均已经过数据规约和变换,因此可以将用户属性抽象为特征向量,利用如下公式计算相似度:
其中,
然后从数据集中提取用户的通话记录和短信记录,统计用户间通话时长、通话次数和短信次数,利用如下公式计算相似度:
其中,c代表通话时长,f代表通话频率,s代表短信次数。cij表示用户i向用户j发起通话的时长,cji表示用户j向用户i发起通话的时长,ci代表用户i与相邻用户(包含用户j)的通话总时长,cj代表用户j与相邻用户(包含用户i)的通话总时长,其他变量的含义以此类推。
最后根据用户所连基站信息建立lda模型,具体包括如下步骤:
(1)为某个地区的基站位置贴上4种标签:分别是家庭位置基站(home),工作地点基站(work),其他基站(other),未接收到任何连接请求基站(noreception)。这4种标签的含义分别是:用户处于家中;用户处于工作状态;用户在离住址和工作地点较远的位置;用户手机处于关机状态。
(2)将电信用户一天的行程抽象为地理位置标签序列。首先,构建一个细粒度的位置描述方式:将一天分为每20分钟一个时间块,选择该块内持续时间最长的基站位置标签作为该块的标签。因此某用户的一天就抽象为由72个位置标签组成的向量。为防止出现过拟合的情况,接着构建一个粗粒度的时间描述方式,将一天分为8个时间片,分别是:0~6am,6~9am,9~12am,12~2pm,2~5pm,5~7pm,7~9pm,9-12pm,编号为0~7。
(3)构建地点转移语料库,语料库中某个文档下的一个词项包含连续2小时内的细粒度基站位置标签和一个粗粒度时间标签,根据既定地点转移语料库中的所有文档,构建lda模型,如图2所示。
lda模型的生成过程,包括如下步骤:
(1)选择文档i的主题概率分布
(2)选择主题k的词项概率分布
(3)对于文档中的每个单词wi,j,选择一个主题zi,j~multinomial(θi)服从多项式分布;选择一个词项
根据上述过程得到的lda模型,可以发现lda模型具有清晰的层次结构,如图3所示,每篇文档由多个主题混合而成,而每个主题又由多个词项表征。由此计算某个文档基于超参数的联合概率分布:
其中ωm代表文档m中所有词构成的向量,zm表示文档m所对应的主题向量,θm代表文档m的主题概率分布,φ表示所有主题的词项概率分布,α,β是狄利克雷分布的超参数,nm代表文档m的长度,wm,n代表第m个文档下第n个词项,
根据上述过程所得联合概率分布,在建模过程中,利用吉布斯抽样方法进行参数估计。设置topic(主题)的初始个数k=30,超参数α=30/k,β=0.01,吉布斯采样的迭代次数为1000次,对语料库进行主题挖掘,生成每篇文章的主题概率分布p(z=k)=θk(d),每个主题下的词项概率分布p(w|z=k)=φw(k)。
每篇文章的主题概率分布计算公式如下:
其中,θm,k代表第m篇文章的第k个主题,nm,k表示文档m中出现第k主题的次数,k表示第m篇文档中主题总数,α为第一参数向量。
每个主题下词项概率分布的计算公式如下:
其中,φk,w表示第k个主题下的第w号词,nk,w表示第k个主题下第w号词项出现的次数,v表示第k个主题下词的总数,β为第二参数向量。
因此,可以根据两个文档主题间概率分布的距离度量文档相似度,计算公式如下:
其中,d1、d2代表两个文档,i表示第i个主题编号,
最后,将用户的多维特征与基于概率的主题发现算法(lda)有机结合,综合得出用户的相似度计算公式如下:
其中,u1、u2代表用户1和用户2;η1表示利用基本属性计算的权值,设置η1=0.1;η2表示利用通话记录和短信记录计算的权值,设置η2=0.3;η3代表利用用户一天中连接基站位置信息计算的权值,设置η3=0.6,其余参数和上文保持一致。
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点看,均应将实例看做是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。
- 还没有人留言评论。精彩留言会获得点赞!