多维度收集URL链接及参数的方法、系统及设备与流程
本发明涉及url收集、漏洞检测,尤其涉及多维度收集url链接及参数的方法、系统及设备。
背景技术:
当前进行web系统安全测试,首先需要获取到该web系统中的url链接和参数。当前获取url链接和参数,一般通过网络爬虫方式进行。由于爬虫的局限性,往往不能很全面的获取系统中的url链接和参数,特别是针对ajax请求,几乎无法识别。无法获取到全面的url链接,也就无法全面的对该系统进行安全测试、安全评估。
技术实现要素:
为了解决上述技术问题,本发明提出一种基于b/s架构系统的多维度收集url链接及参数的方法、系统及设备,它能够全面的获取url链接与参数。保证了系统进行安全检测与评估的全面性。
为了实现上述目的,本发明的技术方案为:
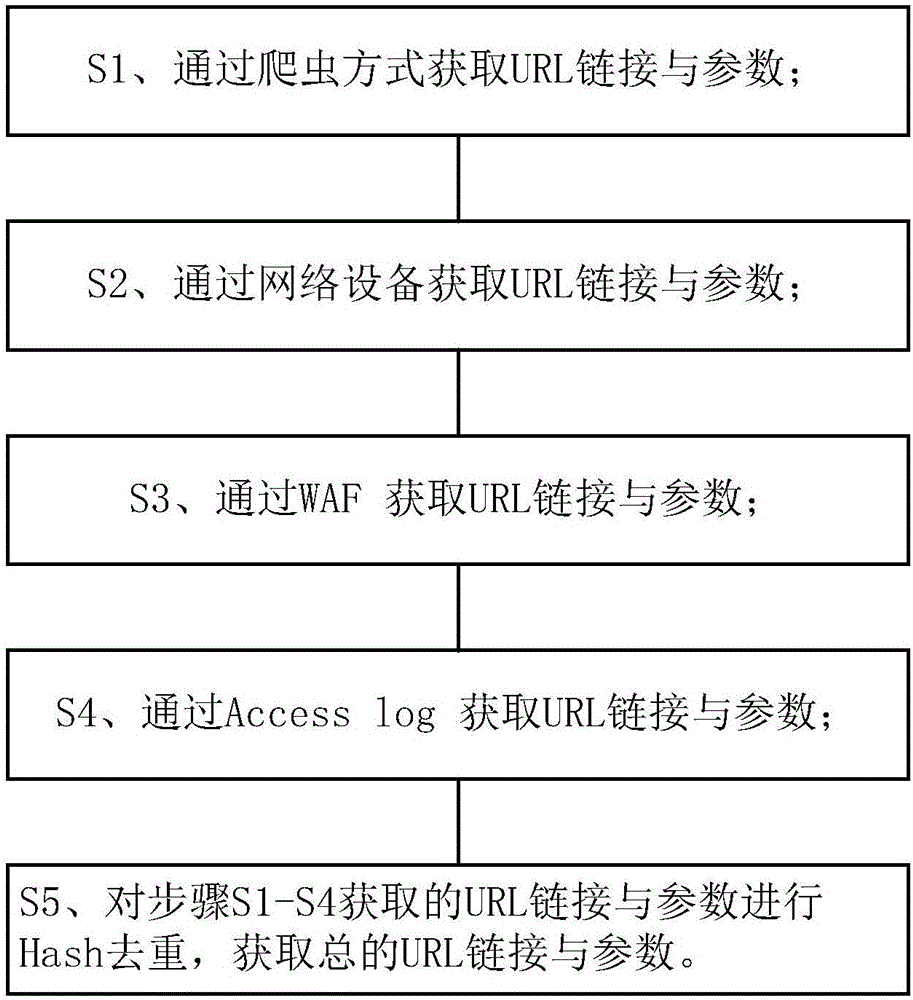
基于b/s架构系统的多维度收集url链接及参数的方法,包括步骤:
s1、通过爬虫方式获取url链接与参数;
s2、通过网络设备获取url链接与参数;
s3、通过waf获取url链接与参数;
s4、通过accesslog获取url链接与参数;
s5、对步骤s1-s4获取的url链接与参数进行hash去重,获取总的url链接与参数。
步骤s1包括步骤:
s11,获取页面;
s12,分析所述页面的get或post请求;
s13,重复步骤s11-s12,直至整个web系统中的链接与参数获取完毕。
步骤s2包括步骤:
s21,通过交换机以及路由器上的镜像端口分析镜像流量;
s22,将访问web服务器的请求通过拆解数据包进行分析;
s23,整理全部web服务器的请求url地址和参数。
步骤s21包括步骤:
s211,对路由器的流量数据包进行解析,若传输层显示为tcp,端口为80/8080/443,则解析数据包;否则不进行拆包。
步骤s22包括步骤:
s221,按照标准网络数据包组成格式,通过解析各个协议层的包头,分别依次拆除网络层包头、传输层包头;
s222,确认传输层是否以http协议方式进行数据发送、接收。
步骤s23包括步骤:
s231,依次从每个解析出的数据包中获取web服务器url地址;
s232,将新的url地址库与旧的url地址库进行比对,并将新的url地址库中存在且旧的url地址库中不存在的数据添加至url数据库。
步骤s3包括步骤:
s31,分析所述waf通过的流量,识别web请求,并记录通过指定站点的web请求;
s32,将获取的url地址分类、记录并存储。
步骤s4包括步骤:
s41,将web容器中用户发送的请求信息记录到accesslog中。
步骤s41中所述的请求信息包括:用户的请求方式get/post,url地址与参数。
基于b/s架构系统的多维度收集url链接及参数的系统,包括:
爬虫监测模块,用于通过爬虫方式获取url链接与参数;
网络设备监测模块,用于通过网络设备获取url链接与参数;
waf监测模块,用于通过waf获取url链接与参数;
accesslog监测模块,用于通过accesslog获取url链接与参数;去重模块,用于对所述爬虫监测模块、网络设备监测模块、waf监测模块以及accesslog监测模块获取的url链接与参数进行hash去重,获取总的url链接与参数。
基于b/s架构系统的多维度收集url链接及参数的设备,包括存储有计算机程序的计算机可读介质,所述程序被运行用于执行:
s1、通过爬虫方式获取url链接与参数;
s2、通过网络设备获取url链接与参数;
s3、通过waf获取url链接与参数;
s4、通过accesslog获取url链接与参数;
s5、对步骤s1-s4获取的url链接与参数进行hash去重,获取总的url链接与参数。
本发明的有益效果是:从四个维度获取web系统的url接口和参数:爬虫、网络设备、waf、accesslog。综合这4个维度获取到的信息,进行url去重和静态资源去除,能有效、更全面的获取到web系统中的url链接和参数,从而进行更加全面的进行安全测试、安全评估。
附图说明
图1示出了根据本申请的流程图。
具体实施方式
为了更好的了解本发明的技术方案,下面结合附图1对本发明作进一步说明。
如图1所示,基于b/s架构系统的多维度收集url链接及参数的方法,包括步骤:
s1、通过爬虫方式获取url链接与参数。
包括步骤:
s11,获取页面;
s12,分析所述页面的get或post请求;
s13,重复步骤s11-s12,直至整个web系统中的链接与参数获取完毕。
每个所述页面都是<html>双标签包含的整个内容,<body>区域是页面显示部分,<body>中包含各种form表单、<a>链接标签、rc、href链接属性。
步骤s12中分析的过程为:<body>中的form、a、src、href链接的资源,页面在加载时,会分析资源的访问路径,例如<ahref=”index.jsp?username=admin”>,此时就可以分析到a标签资源地址是index.jsp?username=admin。分析完后获取到新的访问资源,类似于上面的index.jsp?username=admin,获取到这个页面后(这个页面又包含一个完整的html节点文档,body节点中也有各种form、a、src、href链接资源),又获取到新的url。s2、通过网络设备获取url链接与参数。
包括步骤:
s21,通过交换机以及路由器上的镜像端口分析镜像流量。此步骤中的分析是指:通过软件进行分析,或定制化的硬件行分析。由于在网络上的数据包遵循tcp/ip协议格式,从下而上包含mac封装、ip封装、tcp/udp封装。应用层若是http协议,则可获取到url。类似于get/index.jsp?username=adminhttp/1.1host:www.baidu.com。
步骤s21包括步骤:
s211,对路由器的流量(tcp、udp、icmp、vpn、ftp、arp、http、https等流量)数据包进行解析,若传输层显示为tcp,应用层包头端为80/8080/443端口,则解析数据包;否则不进行拆包。此步骤两处的解析相同,解析方式均是先查看以太网首部,再查看ip首部,再查看tcp首部,最后获取到应用层数据。附件图片是数据包封装格式、数据包样本。路由器获取到数据包后,先解析。
s22,将访问web服务器的请求通过拆解数据包进行分析;按照标准网络数据包组成格式,通过解析各个协议层的包头,分别依次拆除网络层包头、传输层包头;确认传输层是否以http协议方式进行数据发送、接收。
拆解数据包,指的是遵照目前都是tcp/ip协议族标准网络数据包组成格式,通过解析各个协议层(最底层是mac层,mac解析后再解析ip层包头,再解析tcp层,再解析http层。)的包头,分别依次拆解网络层包头、传输层包头,再确认传输层是否以http协议方式进行数据发送、接收。判断是否以http协议方式进行数据发送、接收的标准为:传输层端口号若是80、443、8080、7001、9080、9090,则判断应用层是http协议内容。http协议存在两种数据包:request、reply,存在两个客体:浏览器、服务器。request报文是浏览器发送给服务器,reply报文是服务器返回给浏览器。
s23,整理全部web服务器的请求url地址和参数。依次从每个解析出的数据包中获取web服务器url地址;将新的url地址库与旧的url地址库进行比对,并将新的url地址库中存在且旧的url地址库中不存在的数据添加至url数据库。此处的url数据是指,本技术方案中收集url地址分为4个维度,每个维度收集时,都会建立一个url数据库。此处存入该维度已有的url数据库。
在s211步骤中,若传输层满足为tcp,端口为80/8080/443/7001/9080/9090时,能从应用数据中获取到一个url地址,此时可以将这个url地址添加到数据库中,形成url地址库。下次再解析到新的url地址时,将此url地址与已有url地址库(文中的旧url地址库)进行对比,若比对确认已有url地址库中无此url地址,则将此url地址添加到已有url地址库中;若已有url地址库中已有该url地址,则不进行添加。即当获取到1个http数据包,解析到1个url地址,然后地址库就存在1条记录。后续获取到新的http,也进行解析,然后添加到之前存在的旧url地址库(已经存在1条)。url地址库不断更新。
s3、通过waf获取url链接与参数。
包括步骤:
s31,分析所述waf通过的流量,识别web请求:waf根据tcp/ip协议族进行解析,依次进行mac、ip、tcp拆包,发现数据包是否是web请求。waf来进行记录通过指定站点的web请求,将识别到的url地址存入到数据库。
s32,将获取的url地址分类、记录并存储。
s4、通过accesslog获取url链接与参数。
包括步骤:
s41,将web容器中用户发送的请求信息记录到accesslog中。默认情况下web服务器(包括nginx、apache、tomcat、jetty、jboss、weblogic、iis)等会在accesslog中记录完整get类的url请求,而不会记录完整post类的url请求。目前通过某些第三方组件,例如dumpio、requests嵌入到apache可完成post类参数的完整记录,其余的web服务器则需要自行研发组件嵌入到各服务器进行post类完整url获取。
步骤s41中所述的请求信息包括:用户的请求方式get/post,url地址与参数。
s5、对步骤s1-s4获取的url链接与参数进行hash去重,获取总的url链接与参数。
基于b/s架构系统的多维度收集url链接及参数的系统,包括:
爬虫监测模块,用于通过爬虫方式获取url链接与参数;
网络设备监测模块,用于通过网络设备获取url链接与参数;
waf监测模块,用于通过waf获取url链接与参数;
accesslog监测模块,用于通过accesslog获取url链接与参数;
去重模块,用于对所述爬虫监测模块、网络设备监测模块、waf监测模块以及accesslog监测模块获取的url链接与参数进行hash去重,获取总的url链接与参数。
基于b/s架构系统的多维度收集url链接及参数的设备,包括存储有计算机程序的计算机可读介质,所述程序被运行用于执行:
s1、通过爬虫方式获取url链接与参数;
s2、通过网络设备获取url链接与参数;
s3、通过waf获取url链接与参数;
s4、通过accesslog获取url链接与参数;
s5、对步骤s1-s4获取的url链接与参数进行hash去重,获取总的url链接与参数。
以上描述仅为本申请的较佳实施例以及对所运用技术原理的说明。本领域技术人员应当理解,本申请中所涉及的发明范围,并不限于上述技术特征的特定组合而成的技术方案,同时也应涵盖在不脱离所述发明构思的情况下,由上述技术特征或其等同特征进行任意组合而形成的其它技术方案。例如上述特征与本申请中公开的(但不限于)具有类似功能的技术特征进行互相替换而形成的技术方案。
- 还没有人留言评论。精彩留言会获得点赞!