一种集音装置、监控装置及集音方法与流程
本发明涉及一种集音装置、监控装置及集音方法。
背景技术:
在安保、安防,采访等领域,各类视频监控或视频采集系统已经得到广泛应用。依托各类视频监控或视频采集系统,可以对远距离视频中相关人员进行准确拍摄,但在利用视频监控系统进行远距离拍摄时很难进行远距离语音采集,如能通过远距离语音采集,视频监控系统即可利用语言、对话信息分析嫌疑人,视频采集系统可以视频语音同步记录,将可大大影响了工作效率。但在实际环境背景噪声条件下进行远距离语音采集的设备体积都较为庞大,难以与视频监控系统进行整合联动。
技术实现要素:
本发明要解决的技术问题是,提供一种体积小、指向性高的集音装置。
本发明的技术解决方案是,提供一种具有以下结构的集音装置,包括两个拾音单元,所述的拾音单元向背设置且两者之间设有一定距离,还包括单通道降噪处理模块、指向性处理模块,所述的单通道降噪处理模块接收两个拾音单元信号处理后再将信号传递至指向性处理模块,所述的指向性处理模块接收两路单通道降噪处理模块信号并输出语音增强信号。
优选的,还包括用于固定拾音单元的槽体,所述的槽体连接有云台。
优选的,所述的槽体开口处设有防水罩以及防风罩。优选的,所述的槽体开口处设有防水罩以及防风罩。
优选的,所述的拾音单元为指向性麦克风或全指向麦克风。
优选的,所述的单通道降噪处理模块以及指向性处理模块与拾音单元分体式设计,所述的单通道降噪处理模块以及指向性处理模块与拾音单元通过无线或有线方式连接。
采用以上结构后,本发明的集音装置,与现有技术相比,具有以下优点:通过2个麦克风组件实现指向性拾音,由于仅有两个麦克风和模块组成,结构紧凑便于整合至视频监控设备内,所述的单通道降噪处理模块接收拾音单元信号处理后发送至指向性处理模块,单通道降噪处理模块设计不同统计特性噪声所对应的滤波模型,以达到针对多种类型的噪声分别建模、分别予以消除的目标。由于针对性强且可以达到较强的降噪效果,且由于先进行降噪再进行延时相减,能大大提高波束信号的准确性,并结合降噪后的语音原始信号使最后的语音增加信号达到最优,通过指向性处理模块实现声音信号的处理,指向性处理模块接收两路存在不同时差的原始语音信号进行延时相减形成波束信号,根据波束信号的强弱得到语音方向信号并传递指向性处理模块,指向性处理模块根据语音方向信号对原始语音信号中特定方向之外的原始语音信号进行衰减,得到特定方向的语音增加信号,最后得到了清晰的语音输出。
本发明的另一技术解决方案是,提供一种监控装置,包括摄像组件、上述任一一种集音装置及音视频联动模块,所述的集音装置输出语音增强信号至音视频联动模块,所述的音视频联动模块根据摄像组件输出的变倍信号改变输出语音增强信号的音量大小,所述的摄像组件与集音装置同步运动。
优选的,还包括云台,所述的云台包括云台编解码模块,云台编解码模块读取云台转动产生的云台转动信号以及接收变倍信号并发送至音视频联动模块,所述的音视频联动模块根据变倍信号改变输出的语音增强信号的音量大小。
优选的,所述的摄像组件至少还包括网络摄像机,数字摄像机和模拟摄像机中的一种。
优选的,所述的音视频联动模块为编程放大器模块,编程放大器模块接收语音增强信号和摄像组件变焦后发出的变倍信号,根据变倍信号编程放大器模块改变语音增强信号音量大小并输出。
采用以上结构后,本发明的监控装置,与现有技术相比,具有以下优点:由于集音装置结构紧凑便于整合至视频监控设备内,可以很方便的将集音装置整合到监控装置内,两者固定连接实现联动,能在远距离拍摄时进行远距离语音采集,能在远距离拍摄时进行远距离语音采集,并通过音视频联动模块识别摄像组件输出的变倍信号,通过变倍信号改变输出语音增强信号的音量大小,实现监控视频播放的时候不仅能对应采集声音且可以自动调节到合适的声音播放。
本发明的另一技术解决方案是,提供一种集音方法,包括以下步骤:
s1、2个拾音单元向背设置且两者之间设有一定距离,2个拾音单元均接收不同方向的原始语音信号,并将原始语音信号传递至单通道降噪处理模块;
s2、单通道降噪处理模块接收两路存在不同时差的原始语音信号经过放大和消噪后得到两路降噪语音信号并输入至指向性处理模块;
s3、指向性处理模块根据两路降噪语音信号的时频特性对语音信号和噪声信号掩蔽值处理,最后经过重建合成心形或超心形拾音模式,得到特定方向的语音增强信号;
优选的,还包括音视频联动模块,
音视频联动模块接收指向性处理模块波束方向参数和摄像机变倍参数,建立音视频同步放缩参数映射表,输出音视频联动混合信号。
根据摄像机变倍参数调整波束形成参数,以使得指向性处理模块的波束形成参数符合声源在摄像机图像中的空间位置;
近焦情况下,波束角度变大,摄像机变倍参数变小,声源音量缩小;远焦情况下,波束角度变小,摄像机变倍参数放大,声源音量放大。
优选的,所述的步骤s2滤波降噪处理包括如下步骤,利用端点检测的结果对噪声的频谱进行估计,频域维纳滤波系数通过mel滤波器组转化为mel域的维纳滤波系数,接着采用melidct得到滤波器的时域冲激响应,最终使用卷积得到增强后的时域语音信号用于后端的模型匹配。
优选的,所述的步骤s3还包括如下步骤,
对两路语音信号进行多子带滤波,分帧加窗处理,由此得到两路语音信号的时频表达。某一时间帧的某个频带的信号称为一个时频单元;
计算两路语音信号对应t-f单元之间的iid值;
根据各个t-f单元的iid值,设定其加权掩蔽值。根据各子带的iid值进行语音活动检测;
结合语音激活检测结果,对上步初步生成的掩蔽值纯噪声段直接赋予较小的加权掩蔽值;
对于采集后方的语音信号进行掩蔽值处理,最后经过重建合成心形或超心形拾音模式,得到特定方向的语音增强信号。
优选的,所述的步骤s2和步骤s3之间还包括以下步骤:音视频联动模块检测空间中声源的空间信息参数;指向性处理模块根据检测到的空间信息参数确定对应的波束形成参数以及相应的拾音模型;
采用以上方法后,本发明的集音方法,与现有技术相比,具有以下优点:两麦克风同步录音,由于存在一定距离,不同方向的语音到两个麦克风存在较为明显的不同时差,两路原始语音信号通过指向性处理模块进行延时相减形成波束信号,波束信号的强弱反应了语音的方向,指向性处理模块根椐语音方向信号来对不同的语音信号进行衰减,最后得到语音增加信号,得到了清晰的语音输出,单通道降噪处理模块设计不同统计特性噪声所对应的滤波模型,以达到针对多种类型的噪声分别建模、分别予以消除的目标。由于针对性强且可以达到较强的降噪效果,且由于先进行降噪再进行延时相减,能大大提高波束信号的准确性,并结合降噪后的语音原始信号使最后的语音增加信号达到最优。
附图说明
图1是本发明的监控装置的结构示意图一。
图2是本发明的监控装置的结构示意图二。
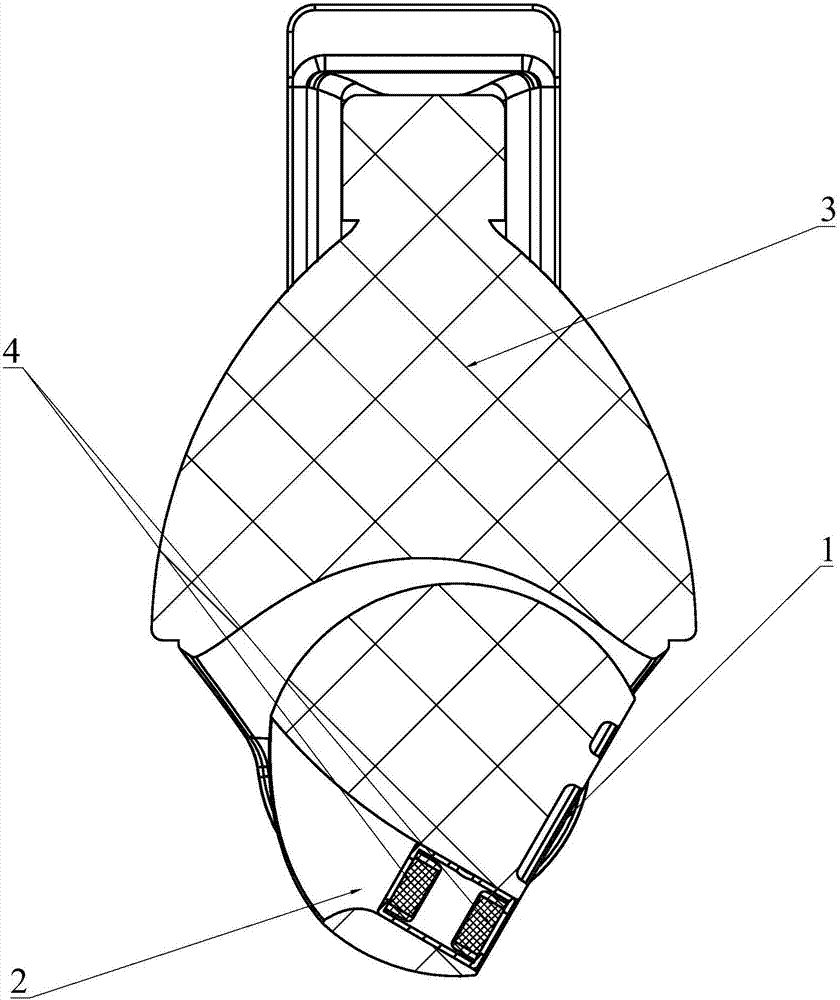
图中所示:1、摄像组件;2、槽体;3、云台;4、拾音单元。
具体实施方式
下面结合附图和具体实施例对本发明作进一步说明。
请参阅图1、图2所示,本发明的技术解决方案是,本发明的技术解决方案是,提供一种具有以下结构的集音装置,包括两个拾音单元4,所述的拾音单元4向背设置且两者之间设有一定距离,还包括单通道降噪处理模块、指向性处理模块,所述的单通道降噪处理模块接收两个拾音单元4信号处理后再将信号传递至指向性处理模块,所述的指向性处理模块接收两路单通道降噪处理模块信号并输出语音增强信号,通过2个麦克风组件实现指向性拾音,由于仅有两个麦克风和模块组成,结构紧凑便于整合至视频监控设备内,所述的单通道降噪处理模块接收拾音单元4信号处理后发送至指向性处理模块,单通道降噪处理模块设计不同统计特性噪声所对应的滤波模型,以达到针对多种类型的噪声分别建模、分别予以消除的目标。由于针对性强且可以达到较强的降噪效果,且由于先进行降噪再进行延时相减,能大大提高波束信号的准确性,并结合降噪后的语音原始信号使最后的语音增加信号达到最优,通过指向性处理模块实现声音信号的处理,指向性处理模块接收两路存在不同时差的原始语音信号进行延时相减形成波束信号,根据波束信号的强弱得到语音方向信号并传递指向性处理模块,指向性处理模块根据语音方向信号对原始语音信号中特定方向之外的原始语音信号进行衰减,得到特定方向的语音增加信号,最后得到了清晰的语音输出。
集音装置还包括用于固定麦克风组件的槽体2,所述的槽体2连接有云台3,通过槽体2安装拾音单元4方便可靠且便于集音。另外由于云台3可多方向转动也可以与视频监控设备联动。所述的槽体2开口处设有防水罩以及防风罩,提高户外使用效果。
所述的指向性处理模块与拾音单元4分体式设计,所述的指向性处理模块与拾音单元4通过无线信号或电缆连接,即可以进一步减少集音装置的体积,由其是外置拾音单元4的体积,且由于拾音单元4单独设置,即在声音处理上更加多样化,可以采集多组不同区域的拾音单元4进行整合处理,能更加清晰的分辩噪声并去除噪声,例如提取相同波束信号下不同组拾音单元4的信号进行增益,能有效提高语音清晰度。
请参阅图1、图2所示,本发明的另一技术解决方案是,一种监控装置,包括摄像组件1、上述任一一种集音装置及音视频联动模块,所述的集音装置输出语音增强信号至音视频联动模块,所述的音视频联动模块根据摄像组件1输出的变倍信号改变输出语音增强信号的音量大小,所述的摄像组件1与集音装置同步运动,由于集音装置结构紧凑便于整合至视频监控设备内,可以很方便的将集音装置整合到监控装置内,两者固定连接实现联动,能在远距离拍摄时进行远距离语音采集,能在远距离拍摄时进行远距离语音采集,并通过音视频联动模块识别摄像组件1输出的变倍信号,通过变倍信号改变输出语音增强信号的音量大小,实现监控视频播放的时候不仅能对应采集声音且可以自动调节到合适的声音播放。所述的摄像组件1至少还包括网络摄像机,数字摄像机和模拟摄像机中的一种。所述的音视频联动模块为编程放大器模块,编程放大器模块接收语音增强信号和摄像组件1变焦后发出的变倍信号,根据变倍信号编程放大器模块改变语音增强信号音量大小并输出。
还包括云台3,所述的云台3包括云台3编解码模块,云台3编解码模块读取云台3转动产生的云台3转动信号以及接收变倍信号并发送至音视频联动模块,所述的音视频联动模块根据变倍信号改变输出的语音增强信号的音量大小,即变倍信号可以发送至音视频联动模块或发送至云台3编解码模块,处理方式更加多样话,另外通过云台3接收云台3转动信号以及接收变倍信号实现视频和音频同步定位功能,即在操作时,操作者在捕捉目标对象的时候,直接用鼠标或触摸方式框选目标所在区域,监视画面自动聚焦到目标对象上,对目标对象图像放大缩小的同时,目标对象的语音也同步放缩。另外,设置有云台3的时候变倍信号也可以直接发送至音视频联动模块。
所述的单通道降噪处理模块以及指向性处理模块与拾音单元4分体式设计,所述的指向性处理模块与拾音单元4通过无线信号或电缆连接,即可以进一步减少集音装置的体积,由其是外置拾音单元4的体积,且由于拾音单元4单独设置,即在声音处理上更加多样化,可以采集多组不同区域的拾音单元4进行整合处理,能更加清晰的分辩噪声并去除噪声,例如提取相同波束信号下不同组拾音单元4的信号进行增益,能有效提高语音清晰度。
本发明的另一技术解决方案是,提供一种集音方法,包括以下步骤:
s1、2个拾音单元4向背设置且两者之间设有一定距离,2个拾音单元4均接收不同方向的原始语音信号,并将原始语音信号传递至单通道降噪处理模块;
s2、单通道降噪处理模块接收两路存在不同时差的原始语音信号经过放大和消噪后得到两路降噪语音信号并输入至指向性处理模块;
s3、指向性处理模块根据两路降噪语音信号的时频特性对语音信号和噪声信号掩蔽值处理,最后经过重建合成心形或超心形拾音模式,得到特定方向的语音增强信号;
两麦克风同步录音,由于存在一定距离,不同方向的语音到两个麦克风存在较为明显的不同时差,两路原始语音信号通过指向性处理模块进行延时相减形成波束信号,波束信号的强弱反应了语音的方向,指向性处理模块根椐语音方向信号来对不同的语音信号进行衰减,最后得到语音增加信号,得到了清晰的语音输出,单通道降噪处理模块设计不同统计特性噪声所对应的滤波模型,以达到针对多种类型的噪声分别建模、分别予以消除的目标。由于针对性强且可以达到较强的降噪效果,且由于先进行降噪再进行延时相减,能大大提高波束信号的准确性,并结合降噪后的语音原始信号使最后的语音增加信号达到最优。
本发明集音方法中还包括使用音视频联动模块,
(1)音视频联动模块接收指向性处理模块波束方向参数和摄像机变倍参数,建立音视频同步放缩参数映射表,输出音视频联动混合信号。
(2)根据摄像机变倍参数调整波束形成参数,以使得指向性处理模块的波束形成参数符合声源在摄像机图像中的空间位置;
(3)近焦情况下,波束角度变大,摄像机变倍参数变小,声源音量缩小;远焦情况下,波束角度变小,摄像机变倍参数放大,声源音量放大。
通过音视频联动模块可以更加准确的接收目标区域的声源,能更好的和摄像机中图像匹配,大大提升了集音效果和监控效果。
优选的,所述的步骤s2滤波降噪处理包括如下步骤,利用端点检测的结果对噪声的频谱进行估计,频域维纳滤波系数通过mel滤波器组转化为mel域的维纳滤波系数,接着采用melidct得到滤波器的时域冲激响应,最终使用卷积得到增强后的时域语音信号用于后端的模型匹配。具体情况如下:
频域滤波器系数h(k)经过mel滤波器组的计算公式推导如下所示。语音采样率fsamp为8000hz。mel滤波器组数目kfb为23。则每一个mel滤波器的中心mel值为
其中,算子mel是将频率值转为mel值,转换公式为
mel{f}=2595×log10(1+f/700)
根据每一个mel滤波器的中心mel可以求得对应的中心频率
同时设定fcentr(0)=0,fcentr(24)=4000。系统采用256点fft,根据实数fft的对称性质,只需要计算前128点的滤波器系数。各个mel滤波器中心频率对应的fft序号为
算子int用于将浮点数取整。利用三角窗滤波器可以将频域维纳滤波系数h(k)转化为mel域维纳滤波器。
根据上式,可以得到mel域维纳滤波系数hmel(k),完成了从频域到mel域的转化。另外,由于从mel域到时域是实数到实数的转化,所以采用了逆离散余弦变换(inversediscretecosinetransformidct)。另外由于每个mel滤波器覆盖的频段长度不同,因此要附加不同的权重。melidct的计算公式如下。
idctmel(k,n)是melidct的系数,其中
最终的维纳滤波器的时域冲激响应为
所述的步骤s3还包括如下步骤,
(1)对两路语音信号进行多子带滤波,分帧加窗处理,由此得到两路语音信号的时频表达。某一时间帧的某个频带的信号称为一个时频单元;
(2)计算两路语音信号对应t-f单元之间的iid值;
(3)根据各个t-f单元的iid值,设定其加权掩蔽值。根据各子带的iid值进行语音活动检测;
(4)结合语音激活检测结果,对上步初步生成的掩蔽值纯噪声段直接赋予较小的加权掩蔽值;
(5)对于采集后方的语音信号进行掩蔽值处理,最后经过重建合成心形或超心形拾音模式,得到特定方向的语音增强信号。
通过进行加权测量得到纯噪声段,并针对该纯噪声段进行更小的加权,能得到特定方向的语音增强信号。
所述的步骤s2和步骤s3之间还包括以下步骤:音视频联动模块检测空间中声源的空间信息参数;指向性处理模块根据检测到的空间信息参数确定对应的波束形成参数以及相应的拾音模型,即通过音视频联动模块先检测声源的空间信息参数,根据预设数据得到较为合适的波束形成参数以及相应的拾音模型,大大减少了运算过程且使集音效果更佳。
以上所述仅是本发明的优选实施方式,本发明的保护范围并不仅局限于上述实施例,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!