双耳波束形成器滤波单元、听力系统及听力装置的制作方法
本发明涉及用于对表示环境中的声音的电输入信号进行空间滤波的波束形成。
背景技术:
听力装置如助听器例如涉及表示其环境中的声音的电输入信号的数字信号处理的助听器例如设计来帮助听力受损人员补偿他们的听力损失。它们的目标在于在存在环境噪声的情形下提高一个或多个传声器捕获的语音的可懂度。为此,它们采用波束形成技术,即组合传声器信号以增强感兴趣的信号(如语音)的信号处理技术。双耳听力系统由位于用户的左和右耳处的两个听力装置(如助听器)组成。至少在一些运行模式下,左和右听力装置可通过有线或无线耳间传输通道协作。双耳听力系统使能使用将传声器信号(或其部分)从一听力装置传到另一听力装置(如左到右和/或右到左)的耳间传输通道构建双耳波束形成器。从另一听力装置接收一个或多个传声器信号的给定听力装置则在其本地波束形成处理中使用所接收的传声器信号,从而增加给波束形成器的传声器输入的数量(例如从一个增加到两个,或者从两个增加到三个,或者从两个增加到四个(如果两个传声器信号被接收(如交换)))。这样做的优点在于潜在更有效率的降噪。双耳波束形成器是目前技术发展水平的东西并已在文献中描述,但(就发明人的了解)尚未在商用产品中使用。
通过无线通信链路协作的双耳助听器中的多传声器降噪算法具有在未来助听器系统中变得非常重要的潜力。然而,这些装置的有限的传输容量需要从一助听器传到对侧助听器的信号的数据压缩。有限的传输容量例如可导致通信链路的有限的带宽(比特率)。这些限制例如可因前述装置的便携性、有限的空间因而有限的功率容量如电池容量引起。
在现有技术中,用于助听器的双耳波束形成器通常人工构建。假定来自一助听器的传声器信号可即刻且没有误差地传给另一助听器。然而,在实践中,传声器信号在传输之前必须量化。量化引入噪声,其不可避免。现有技术双耳波束成形系统忽略量化噪声的存在。如果在实践中使用,这样的系统表现较差。
技术实现要素:
在设计双耳波束形成器时考虑量化噪声的存在应是有利的。
听力装置
在本申请的一方面,提供适于位于用户的第一耳朵处或第一耳朵中或者完全或部分植入在用户的第一耳朵处的头部中的听力装置。该听力装置包括:
-第一输入变换器,用于将来自用户周围第一位置处的声场的第一输入声音信号转换为第一电输入信号,所述第一位置为第一输入变换器的位置,所述声场包括来自目标声源的目标声音与可能的声学噪声的混合;
-收发器单元,配置成经通信链路接收第一量化的电输入信号;所述第一量化的电输入信号表示用户周围第二位置处的声场,所述第一量化的电输入信号包括因特定量化方案引起的量化噪声;
-波束形成器滤波单元,适于接收所述第一电输入信号和所述量化的电输入信号及确定波束形成器滤波权重,当所述波束形成器滤波权重应用于所述第一电输入信号和所述量化的电输入信号时提供波束成形信号;及
-控制单元,适于控制所述波束形成器滤波单元。
所述控制单元配置成考虑所述量化噪声对波束形成器滤波单元进行控制,例如通过根据所述量化噪声确定所述波束形成器滤波权重。
从而,提供改进的听力装置。
经通信链路接收的第一量化的电输入信号可以是时域中的数字化信号或者多个数字化的子频带信号,每一子频带信号按时频表示表示量化的信号。
第一量化的电信号的子频带信号可以是包括幅度部分和相位部分的复合信号,其可个别地进行量化(例如根据同样或不同的量化方案)。也可使用更高阶的量化方案如向量量化(vq)(例如以提供更有效率的量化)。
在实施例中,控制单元配置成基于所述特定量化方案的了解而考虑所述量化噪声控制所述波束形成器滤波单元。在实施例中,控制单元配置成接收标示所述特定量化方案的信息信号。在实施例中,控制单元适应特定量化方案。在实施例中,控制单元包括存储器单元,其包括多个不同的可能的量化方案(及例如针对所涉及助听器的配置的对应的噪声协方差矩阵)。在实施例中,控制单元配置成在所述多个(已知的)量化方案之中选择特定量化方案。在实施例中,控制单元配置成根据输入信号(如其带宽)、电池状态(如剩余容量)、可用链路带宽等选择量化方案。在实施例中,控制单元配置成基于价值函数的最小化在所述多个量化方案之中选择特定量化方案。
在实施例中,量化因a/d转换和/或压缩引起。在本说明书中,量化通常对(已经)数字化的信号进行。
在实施例中,波束形成器滤波权重根据视向量和噪声协方差矩阵确定。
在实施例中,噪声协方差矩阵
在实施例中,波束形成器滤波单元为最小方差无失真响应(mvdr)波束形成器。
听力装置可包括存储器单元,其包括多个不同的可能量化方案。控制单元可配置成在所述多个不同的量化方案之中选择特定量化方案。存储器也可包括关于不同的声学噪声分布的信息,例如针对前述噪声分布如针对各向同性分布的噪声协方差矩阵元素。
控制单元可配置成根据输入信号、电池状态和可用链路带宽中的一个或多个选择量化方案。
控制单元可配置成从另一装置如另一听力装置例如双耳助听器系统的对侧听力装置接收关于特定量化方案的信息。关于特定量化方案的信息可包括其分布和/或方差。
多个不同的可能量化方案可包括水平-中点型和/或上升-中点型量化方案。
收发器单元可包括天线和收发器电路,配置成建立与另一装置如另一听力装置的无线通信链路,以使能经该无线通信链路与另一装置交换量化的电输入信号及特定量化方案的信息。
在实施例中,听力装置适于提供随频率而变的增益和/或随电平而变的压缩和/或一个或多个频率范围到一个或多个其它频率范围的移频(具有或没有频率压缩)以补偿用户的听力受损。在实施例中,听力装置包括用于增强输入信号并提供处理后的输出信号的信号处理单元。
在实施例中,听力装置包括输出单元,用于基于处理后的电信号提供由用户感知为声学信号的刺激。在实施例中,输出单元包括耳蜗植入物的多个电极或者骨导听力装置的振动器。在实施例中,输出单元包括输出变换器。在实施例中,输出变换器包括用于将刺激作为声信号提供给用户的接收器(扬声器)。在实施例中,输出变换器包括用于将刺激作为颅骨的机械振动提供给用户的振动器(例如在附着到骨头的或骨锚式听力装置中)。
在实施例中,听力装置包括用于提供表示声音的电输入信号的输入单元。在实施例中,输入单元包括用于将输入声音转换为电输入信号的输入变换器如传声器。在实施例中,输入单元包括用于接收包括声音的无线信号并提供表示所述声音的电输入信号的无线接收器。
听力装置包括定向传声器系统,其适于对来自环境的声音进行空间滤波从而增强佩戴听力装置的用户的局部环境中的多个声源之中的目标声源。在实施例中,定向系统适于检测(如自适应检测)传声器信号的特定部分源自哪一方向(例如,识别到达方向doa)。这可以现有技术中描述的多种不同方式实现。
在实施例中,听力装置包括用于从另一装置如通信装置或另一听力装置接收直接电输入信号的天线和收发器电路。在实施例中,听力装置包括(可能标准化的)电接口(例如连接器的形式),用于从另一装置如通信装置或另一听力装置接收有线直接电输入信号。在实施例中,直接电输入信号表示或包括音频信号和/或控制信号和/或信息信号。在实施例中,听力装置包括用于对所接收的直接电输入进行解调的解调电路,以提供表示音频信号和/或控制信号的直接电输入信号,例如用于设置听力装置的运行参数(如音量)和/或处理参数。总的来说,听力装置的发射器和天线及收发器电路建立的无线链路可以是任何类型。在实施例中,无线链路在功率约束条件下使用,例如由于听力装置是或包括便携式(通常电池驱动的)装置。在实施例中,无线链路为基于近场通信的链路,例如基于发射器部分和接收器部分的天线线圈之间的感应耦合的感应链路。在另一实施例中,无线链路基于远场电磁辐射。在实施例中,经无线链路的通信根据特定调制方案进行安排,例如模拟调制方案,如fm(调频)或am(调幅)或pm(调相),或数字调制方案,如ask(幅移键控)如开-关键控、fsk(频移键控)、psk(相移键控)如msk(最小频移键控)或qam(正交调幅)。
在实施例中,听力装置和另一装置之间的通信处于基带(音频频率范围,如在0和20khz之间)。优选地,听力装置和另一装置之间的通信基于高于100khz的频率下的某类调制。优选地,用于在听力装置和另一装置之间建立通信链路的频率低于50ghz,例如位于从50mhz到50ghz的范围中,例如高于300mhz,例如在高于300mhz的ism范围中,例如在900mhz范围中或在2.4ghz范围中或在5.8ghz范围中或在60ghz范围中(ism=工业、科学和医学,这样的标准化范围例如由国际电信联盟itu定义)。在实施例中,无线链路基于标准化或专用技术。在实施例中,无线链路基于蓝牙技术(如蓝牙低功率技术)。
在实施例中,听力装置为便携装置,如包括本机能源如电池例如可再充电电池的装置。
在实施例中,听力装置包括输入变换器(传声器系统和/或直接电输入(如无线接收器))和输出变换器之间的正向或信号通路。在实施例中,信号处理单元位于该正向通路中。在实施例中,信号处理单元适于根据用户的特定需要提供随频率而变的增益。在实施例中,听力装置包括具有用于分析输入信号(如确定电平、调制、信号类型、声反馈估计量等)的功能件的分析通路。在实施例中,分析通路和/或信号通路的部分或所有信号处理在频域进行。在实施例中,分析通路和/或信号通路的部分或所有信号处理在时域进行。
在实施例中,表示声信号的模拟电信号在模数(ad)转换过程中转换为数字音频信号,其中模拟信号以预定采样频率或采样速率fs进行采样,fs例如在从8khz到48khz的范围中(适应应用的特定需要)以在离散的时间点tn(或n)提供数字样本xn(或x[n]),每一音频样本通过预定的ns比特表示声信号在tn时的值,ns例如在从1到16比特或者1到48比特的范围中,例如24比特。数字样本x具有1/fs的时间长度,如50μs,对于fs=20khz。在实施例中,多个音频样本按时间帧安排。在实施例中,一时间帧包括64个或128个音频数据样本。根据实际应用可使用其它帧长度。
在实施例中,听力装置包括模数(ad)转换器以按预定的采样速率如20khz对模拟输入进行数字化。在实施例中,听力装置包括数模(da)转换器以将数字信号转换为模拟输出信号,例如用于经输出变换器呈现给用户。
在实施例中,听力装置如传声器单元和/或收发器单元包括用于提供输入信号的时频表示的tf转换单元。在实施例中,时频表示包括所涉及信号在特定时间和频率范围的相应复值或实值的阵列或映射。在实施例中,tf转换单元包括用于对(时变)输入信号进行滤波并提供多个(时变)输出信号的滤波器组,每一输出信号包括截然不同的输入信号频率范围。在实施例中,tf转换单元包括用于将时变输入信号转换为频域中的(时变)信号的傅里叶变换单元。在实施例中,听力装置考虑的、从最小频率fmin到最大频率fmax的频率范围包括从20hz到20khz的典型人听频范围的一部分,例如从20hz到12khz的范围的一部分。在实施例中,听力装置的正向通路和/或分析通路的信号拆分为ni个频带,其中ni例如大于5,如大于10,如大于50,如大于100,如大于500,至少其部分个别进行处理。在实施例中,助听器适于在np个不同频道处理正向和/或分析通路的信号(np≤ni)。频道可以宽度一致或不一致(如宽度随频率增加)、重叠或不重叠。
在实施例中,听力装置包括多个检测器,其配置成提供与听力装置的当前网络环境(如当前声环境)有关、和/或与佩戴听力装置的用户的当前状态有关、和/或与听力装置的当前状态或运行模式有关的状态信号。作为备选或另外,一个或多个检测器可形成与听力装置(如无线)通信的外部装置的一部分。外部装置例如可包括另一助听装置、遥控器、音频传输装置、电话(如智能电话)、外部传感器等。
在实施例中,多个检测器中的一个或多个对全带信号起作用(时域)。在实施例中,多个检测器中的一个或多个对频带拆分的信号起作用((时-)频域)。
在实施例中,多个检测器包括电平检测器,用于估计正向通路的信号的当前电平。在实施例中,预定判据包括正向通路的信号的当前电平是否高于或低于给定(l-)阈值。
在特定实施例中,听力装置包括话音检测器(vd),用于确定输入信号(在特定时间点)是否包括话音信号。在本说明书中,话音信号包括来自人类的语音信号。其还可包括由人类语音系统产生的其它形式的发声(如唱歌)。在实施例中,话音检测器单元适于将用户当前的声环境分类为“话音”或“无话音”环境。这具有下述优点:包括用户环境中的人发声(如语音)的电传声器信号的时间段可被识别,因而与仅包括其它声源(如人工产生的噪声)的时间段分离。在实施例中,话音检测器适于将用户自己的话音也检测为“话音”。作为备选,话音检测器适于从“话音”的检测排除用户自己的话音。
在实施例中,听力装置包括自我话音检测器,用于检测特定输入声音(如话音)是否源自系统用户的话音。在实施例中,听力装置的传声器系统适于能够在用户自己的话音及另一人的话音之间进行区分及可能与无话音声音区分。
在实施例中,助听装置包括分类单元,配置成基于来自(至少部分)检测器的输入信号及可能其它输入对当前情形进行分类。在本说明书中,“当前情形”意指下述之一或多个:
a)物理环境(如包括当前电磁环境,例如发生计划或者未计划由听力装置接收的电磁信号(如包括音频和/或控制信号),或者当前环境不同于声学的其它性质);
b)当前声学情形(输入电平、反馈等);
c)用户的当前模式或状态(运动、温度等);
d)助听装置和/或与听力装置通信的另一装置的当前模式或状态(所选的程序、自上次用户交互作用之后已消逝的时间等)。
在实施例中,听力装置还包括用于所涉及应用的其它适宜功能,如压缩、反馈抵消、降噪等。
在实施例中,听力装置包括听音装置如助听器、听力仪器例如适于位于用户耳朵处或者完全或部分位于耳道中的听力仪器,例如头戴式耳机、耳麦、耳朵保护装置或其组合。在实施例中,听力装置是或包括助听器。
应用
一方面,提供如上所述的、“具体实施方式”部分中详细描述的和权利要求中限定的听力装置的应用。在实施例中,提供在包括音频分布的系统中的应用,例如包括传声器和扬声器的系统。在实施例中,提供在包括一个或多个听力仪器的系统、头戴式耳机、耳麦、主动耳朵保护系统等中的应用,例如在免提电话系统、远程会议系统、广播系统、卡拉ok系统、教室放大系统等中的用途。
听力系统
另一方面,本发明提供包括上面描述的、“具体实施方式”中详细描述的及权利要求中限定的听力装置及包括辅助装置的听力系统。
在实施例中,该听力系统适于在听力装置和辅助装置之间建立通信链路以使信息(如控制和状态信号,可能音频信号)能在其间进行交换或从一装置转发给另一装置。
在实施例中,辅助装置是或包括音频网关设备,其适于(如从娱乐装置例如tv或音乐播放器,从电话装置例如移动电话,或从计算机例如pc)接收多个音频信号,及适于选择和/或组合所接收音频信号(或信号组合)中的适当信号以传给听力装置。在实施例中,辅助装置是或包括遥控器,用于控制听力装置的功能和运行。在实施例中,遥控器的功能实施在智能电话中,该智能电话可能运行使能经智能电话控制音频处理装置的功能的app(听力装置包括适当的到智能电话的无线接口,例如基于蓝牙或一些其它标准化或专有方案)。
在实施例中,辅助装置为另一听力装置。在实施例中,听力系统包括适于实施双耳听力系统如双耳助听器系统的两个听力装置。
定义
在本说明书中,“听力装置”指适于改善、增强和/或保护用户的听觉能力的装置如听力仪器或有源耳朵保护装置或其它音频处理装置,其通过从用户环境接收声信号、产生对应的音频信号、可能修改该音频信号、及将可能已修改的音频信号作为可听见的信号提供给用户的至少一只耳朵而实现。“听力装置”还指适于以电子方式接收音频信号、可能修改该音频信号、及将可能已修改的音频信号作为听得见的信号提供给用户的至少一只耳朵的装置如头戴式耳机或耳麦。听得见的信号例如可以下述形式提供:辐射到用户外耳内的声信号、作为机械振动通过用户头部的骨结构和/或通过中耳的部分传到用户内耳的声信号、及直接或间接传到用户耳蜗神经的电信号。
听力装置可构造成以任何已知的方式进行佩戴,如作为佩戴在耳后的单元(具有将辐射的声信号导入耳道内的管或者具有安排成靠近耳道或位于耳道中的扬声器)、作为整个或部分安排在耳廓和/或耳道中的单元、作为连到植入在颅骨内的固定结构的单元、或作为整个或部分植入的单元等。听力装置可包括单一单元或几个彼此电子通信的单元。
更一般地,听力装置包括用于从用户环境接收声信号并提供对应的输入音频信号的输入变换器和/或以电子方式(即有线或无线)接收输入音频信号的接收器、用于处理输入音频信号的(通常可配置的)信号处理电路、及用于根据处理后的音频信号将听得见的信号提供给用户的输出装置。在一些听力装置中,放大器可构成信号处理电路。信号处理电路通常包括一个或多个(集成或单独的)存储元件,用于执行程序和/或用于保存在处理中使用(或可能使用)的参数和/或用于保存适合听力装置功能的信息和/或用于保存例如结合到用户的接口和/或到编程装置的接口使用的信息(如处理后的信息,例如由信号处理电路提供)。在一些听力装置中,输出装置可包括输出变换器,例如用于提供空传声信号的扬声器或用于提供结构或液体传播的声信号的振动器。在一些听力装置中,输出装置可包括一个或多个用于提供电信号的输出电极。
在一些听力装置中,振动器可适于经皮或由皮将结构传播的声信号传给颅骨。在一些听力装置中,振动器可植入在中耳和/或内耳中。在一些听力装置中,振动器可适于将结构传播的声信号提供给中耳骨和/或耳蜗。在一些听力装置中,振动器可适于例如通过卵圆窗将液体传播的声信号提供到耳蜗液体。在一些听力装置中,输出电极可植入在耳蜗中或植入在颅骨内侧上,并可适于将电信号提供给耳蜗的毛细胞、一个或多个听觉神经、听觉脑干、听觉中脑、听觉皮层和/或大脑皮层的其它部分。
“听力系统”指包括一个或两个听力装置的系统。“双耳听力系统”指包括两个听力装置并适于协同地向用户的两只耳朵提供听得见的信号的系统。听力系统或双耳听力系统还可包括一个或多个“辅助装置”,其与听力装置通信并影响和/或受益于听力装置的功能。辅助装置例如可以是遥控器、音频网关设备、移动电话(如智能电话)、广播系统、汽车音频系统或音乐播放器。听力装置、听力系统或双耳听力系统例如可用于补偿听力受损人员的听觉能力损失、增强或保护正常听力人员的听觉能力和/或将电子音频信号传给人。
本发明的实施例例如可用在助听器及具有有限功率容量的其它便携式电子装置的应用中。
附图说明
本发明的各个方面将从下面结合附图进行的详细描述得以最佳地理解。为清晰起见,这些附图均为示意性及简化的图,它们只给出了对于理解本发明所必要的细节,而省略其他细节。在整个说明书中,同样的附图标记用于同样或对应的部分。每一方面的各个特征可与其他方面的任何或所有特征组合。这些及其他方面、特征和/或技术效果将从下面的图示明显看出并结合其阐明,其中:
图1a示意性地示出了样本中的时变模拟信号(振幅-时间)及其数字化,这些样本安排在多个时间帧中,每一时间帧包括ns个样本。
图1b示出了图1a的时变电信号的时频图表示。
图1c示意性地示出了为提供数字化信号,模拟信号的示例性数字化,从而引入量化误差(导致量化噪声)。
图1d示意性地示出了已经数字化的信号的示例性的进一步量化,从而引入进一步(通常更大的)量化误差。
图2a和2b示意性地示出了声源相对于双耳助听器系统的第一和第二实施例的几何布置,双耳助听器系统包括分别位于用户的第一(左)和第二(右)耳之处或之中的第一和第二听力装置。
图3示出了根据本发明的双耳助听器系统的实施例。
图4a示出了根据本发明实施例的助听器的简化框图。
图4b示出了图4a的信号处理器的示例性波束形成器滤波单元形成部分的音频信号输入和输出。
通过下面给出的详细描述,本发明进一步的适用范围将显而易见。然而,应当理解,在详细描述和具体例子表明本发明优选实施例的同时,它们仅为说明目的给出。对于本领域技术人员来说,基于下面的详细描述,本发明的其它实施方式将显而易见。
具体实施方式
下面结合附图提出的具体描述用作多种不同配置的描述。具体描述包括用于提供多个不同概念的彻底理解的具体细节。然而,对本领域技术人员显而易见的是,这些概念可在没有这些具体细节的情形下实施。装置和方法的几个方面通过多个不同的块、功能单元、模块、元件、电路、步骤、处理、算法等(统称为“元素”)进行描述。根据特定应用、设计限制或其他原因,这些元素可使用电子硬件、计算机程序或其任何组合实施。
电子硬件可包括微处理器、微控制器、数字信号处理器(dsp)、现场可编程门阵列(fpga)、可编程逻辑器件(pld)、选通逻辑、分立硬件电路、及配置成执行本说明书中描述的多个不同功能的其它适当硬件。计算机程序应广义地解释为指令、指令集、代码、代码段、程序代码、程序、子程序、软件模块、应用、软件应用、软件包、例程、子例程、对象、可执行、执行线程、程序、函数等,无论是称为软件、固件、中间件、微码、硬件描述语言还是其他名称。
本申请涉及听力装置如助听器领域。
本申请涉及作为数据压缩方案的量化对多传声器降噪算法如波束形成器例如双耳波束形成器的影响。术语“波束形成”在本说明书中用于指为提供波束成形信号,至少两个声音信号的空间滤波。术语“双耳波束形成”在本说明书中指基于位于左耳处的至少一输入变换器及位于右耳处的至少一输入变换器接收的声音信号的波束形成。在下面的例子中,双耳最小方差无失真响应(bmvdr)波束形成器用作实例。作为备选,可使用其它波束形成器。最小方差无失真响应(mvdr)波束形成器为线性约束最小方差(lcmv)波束形成器的例子。可使用来自该组的不同于mvdr波束形成器的其它波束形成器。可使用不同于双耳lcmv波束形成器的其它双耳波束形成器,例如基于多通道齐纳滤波器(bmwf)波束形成器。在实施例中,提出了知道量化的波束形成方案,其使用包括量化噪声(qn)的系统噪声的修改的互功率谱密度(cpsd)。
助听器装置设计来帮助听力受损人员补偿他们的听力损失。它们的目标在于在存在环境噪声的情形下提高一个或多个传声器捕获的语音的可懂度。双耳助听器系统由可能通过无线链路协作的两个助听器组成。使用协作的助听器可有助于保留空间双耳线索(其在使用传统方法时可能失真),并可增加噪声抑制的量。这可借助于多传声器降噪算法实现,其相较单通道方法通常导致更好的语音可懂度。双耳多传声器降噪算法的例子为双耳最小方差无失真响应(bmvdr)波束形成器(例如参见[haykin&liu,2010]),其为基于双耳线性约束最小方差(blcmv)的方法的特殊情形。bmvdr由两个分开的mvdr波束形成器组成,其试图估计左侧和右侧助听器处所需语音信号的无失真版本,同时抑制环境噪声并保留目标信号的空间线索。
使用双耳算法需要一助听器处记录的信号通过无线链路传给对侧助听器。由于有限的传输容量,必须对将要传输的信号进行数据压缩。这意味着因数据压缩(量化)引起的另外的噪声在传输之前添加到传声器信号。通常,双耳波束形成器不考虑该另外的压缩噪声。在[srinivasanetal.,2008]中,提出了量化误差下的基于双耳降噪方案的广义旁瓣抵消器(gsc)波束形成器。然而,[srinivasanetal.,2008]中使用的量化方案假定声学场景由固定不动的点源组成,这在实践中并不现实。目标信号通常并非为固定不动的语音源。此外,[srinivasanetal.,2008]中假设的远场场景不能支持波束形成性能的真实和实际分析。
本发明涉及作为数据压缩方法的量化对双耳波束形成的性能的影响。bmvdr波束形成器用作例示,但研究结果可容易地应用于其它双耳算法。最佳的波束形成器依赖于所有噪声源的统计(如基于噪声协方差矩阵的估计),包括量化噪声(qn)。幸运地,qn统计数据在传输助听器处容易得到(现有知识)。我们提出基于包括qn的修改的噪声互功率谱密度(cpsd)矩阵的双耳方案以考虑qn。为此,在本发明的实施例中,我们引入两个假设:
1)qn跨传声器不相关;及
2)qn及环境噪声不相关。
这些假设的有效性取决于使用的比特率及精确的推测。在低比特率条件下,使用相减抖动,两个假设总是适用。在没有抖动的情形下,这些假设对于较高的比特率大约适用。然而,对于许多实际情形,因这些假设不绝对的有效性引起的性能损失可忽略。
图1a示意性地示出了样本中的时变模拟信号(振幅-时间)及其数字化,这些样本安排在多个时间帧中,每一时间帧包括ns个样本。图1a示出了模拟电信号(实线曲线),例如表示来自传声器的声输入信号,其在模数(ad)转换过程中转换为数字音频信号,在模数转换过程中,模拟信号以预定采样频率或速率fs进行采样,fs例如在从8khz到40khz的范围中(适应应用的特定需要),以在离散时间点n提供数字样本y(n),如从时间轴延伸的在其与所述曲线重合的端点处具有实心点的垂直线所示,表示在对应的不同时间点n的数字样本值。每一(音频)样本y(n)表示声信号在n(或tn)的值,通过预定数量(nb)的比特表达,nb例如在从1到48比特的范围中如24比特。因此,每一音频样本使用nb个比特量化(导致音频样本的2nb个不同的可能值)。
所使用的量化比特的数量nb可根据例如同一装置内的应用而不同。在配置成与另一装置(如对侧助听器)建立无线通信链路的听力装置如助听器中,在将要传输的信号的量化中使用的比特数n’b可小于助听器的正向通路中的正常信号处理使用的比特数nb(n’b<nb)(以减小无线通信链路所需要的带宽)。减小的比特数n’b可以是用较大的比特数(nb)量化的信号的数字压缩或者在量化中使用n’b个比特的直接模数转换的结果。
在模数(ad)处理中,数字样本y(n)具有1/fs的时间长度,例如对于fs=20khz,该时间长度为50μs。多个(音频)样本ns例如安排在时间帧中,如图1a下部示意性图示的,其中各个(在此均匀间隔的)样本按时间帧分组(1,2,…,ns)。同样如图1a的下部图示的,时间帧可连续地安排成非重叠(时间帧1,2,…,m,…,m)或重叠(在此为50%,时间帧1,2,…,m,…,m’),其中m为时间帧指数。在实施例中,一时间帧包括64个音频数据样本。根据实际应用,也可使用其它帧长度。
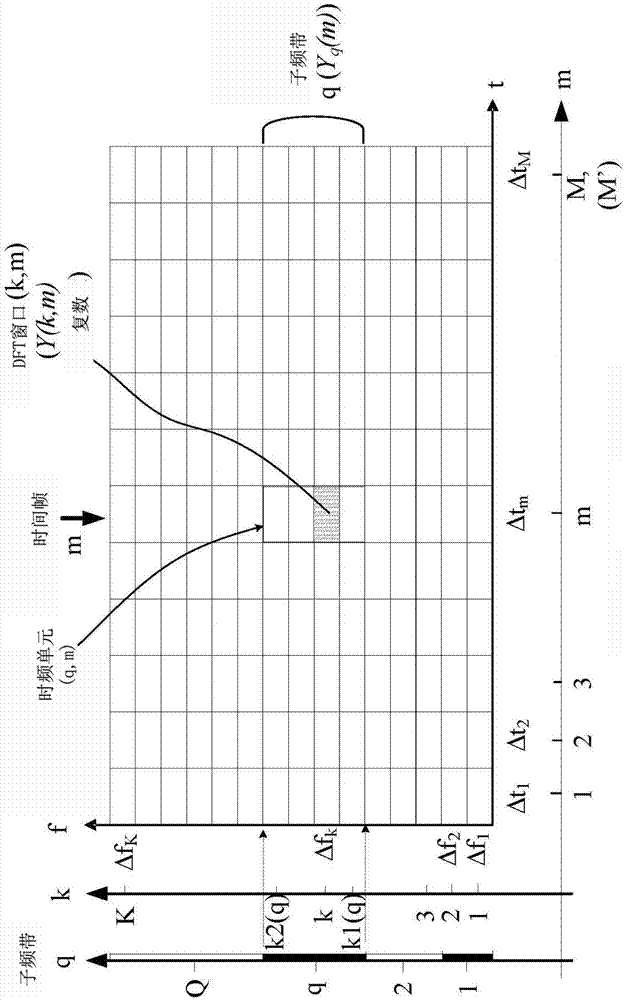
图1b示意性地示出了图1a的(数字化)时变电信号y(n)的时频表示。该时频表示包括信号的对应复值或实值在特定时间和频率范围的阵列或映射。该时频表示例如可以是将时变输入信号y(n)转换为时频域的(时变)信号y(k,m)的傅里叶变换的结果。在实施例中,傅里叶变换包括离散傅里叶变换算法(dft)。典型助听器考虑的从最小频率fmin到最大频率fmax的频率范围包括从20hz到20khz的典型人听频范围的一部分,如从20hz到12khz的范围的一部分。在图1b中,信号y(n)的时频表示y(k,m)包括信号在指数(k,m)确定的多个dft窗口(或瓦)中的复值(包括量值和/或相位),其中k=1,….,k表示k个频率值(参见图1b中的纵向k轴),及m=1,….,m(m’)表示m(m’)个时间帧(参见图1b中的水平m轴)。时间帧由特定时间指数m和对应的k个dft窗口确定(参见图1b中的时间帧m的指示)。时间帧m表示信号x在时间m的频谱。包括所涉及信号的(实或)复值y(k,m)的dft窗口(或瓦)(k,m)在图1b中通过时频图中对应场的阴影图示。频率指数k的每一值对应于频率范围δfk,如图1b中通过纵向频率轴f指明。时间指数m的每一值表示时间帧。连续时间指数跨越的时间δtm取决于时间帧的长度(如25ms)及相邻时间帧之间的重叠程度(参见图1a及图1b中的水平t轴)。
在本申请中,定义具有子频带指数q=1,2,…,q的q个(可能非均匀,例如对数)子频带,每一子频带包括一个或多个dft窗口(参见图1b中的纵向子频带q轴)。第q个子频带(由图1b的右部的子频带q(yq(m))指明)包括分别具有低和高指数k1(q)和k2(q)的dft窗口(或瓦),其分别定义第q个子频带的低和高截止频率。特定时频单元(q,m)由特定时间指数m和dft窗口指数k1(q)-k2(q)定义,如图1b中通过对应dft窗口(或瓦)周围的粗框架指明。特定时频单元(q,m)包含第q个子频带信号yq(m)在时间m的复值或实值。在实施例中,子频带为三分之一倍频带。ωq指第q个频带的中心频率。
图1c示意性地示出了为提供数字化电输入信号y(n),时变模拟电输入信号y(t)的示例性数字化,从而引入量化误差(导致量化噪声)。电输入信号被归一化为0和1之间的值(归一化振幅)并对时间(t或n)示出。量化误差例如可指明为模拟电输入信号y(t)(粗线曲线)与数字化电输入信号y(n)(逐步线性点线)之间的差y(t)-y(n)。如从图1c直观看出的,量化误差随着量化比特的数量n’b增加而减小。在实施例中,量化比特的数量n’b等于3(导致23=8个台阶)或者更大,如等于8(导致28=256个台阶),或者更大。
在实施例中,模数转换器的输出,例如以20khz的采样频率及多个量化比特nb=24数字化,量化到nb=8以减小用于将正向通路的信号(如来自传声器的电输入信号)传给另一装置如另一助听器的无线链路所需要的带宽(例如参见图4a)。在实施例中,正向通路的信号可被下采样以进一步减少链路带宽的需要。
图1d示意性地示出了已经数字化的信号的量化的例子。图1d示意性地示出了模拟信号y(t)(实线)的振幅-时间曲线图,其例如表示给a/d转换器的电输入(如传声器信号)。由a/d转换器提供的数字化信号y(n)(n为时间指数)被示为点线条,具有标记特定时间指数的振幅值的小的实心点。a/d转换之后的数字化信号假定用nb=5比特进行量化(25=32级,远低于通常使用的值,但为说明目的进行选择),参见最右边的记为“归一化振幅”“nb=5”的纵轴。来自a/d转换器的数字化信号的示例性量化由开着的点示意性图示,反映nb=3比特的量化方案(23=8级,用于说明目的),参见最左边的记为“归一化振幅”“nb=3”的纵轴。知道来自a/d转换器的信号的(数字)值及针对给定量化方案的量化信号的(数字)值,从而知道因转换引入的量化误差。针对图1d中的时刻n=5、9和17的量化误差(qe)在图1d中通过记为qe(n)的向上和向下指向的箭头标示,向下和向上指向的箭头分别标示负和正量化误差。向下和向上指向的箭头用于分别标示量化信号的值小于和大于信号量化之前的(在此为来自a/d转换器的信号的)值。在图1d的示意性图示中,假定“采样率”(指数n)在量化之前及之后均一样。然而,并不必须如此。较低的采样率可进一步减少对链路带宽的需要。总的来说,采样率可适应电输入信号的频率含量。例如,如果预期所有频率均低于比正常最大工作频率低的某一频率,量化信号可对应地向下采样。对于给定量化方案,可假定量化误差的预定统计分布。例如,对于中平量化器,方差
量化及抖动
为简化起见,我们假定数据压缩方案简单地由均匀n’b比特量化器给出。在实施例中,数据可能已经在助听器的正向通路中以相当高的速率(如nb=16比特或更大)进行量化。对称的均匀量化器将信号的实际范围xmin≤x≤xmax映射到量化范围
振幅范围细分为宽度δ=(2xmax)/2n’b的k’=2n’b个均匀间隔,其中xmax为将要量化的信号的最大值。众所周知的量化器为具有阶梯映射函数f(x)的中平量化器,定义为:
其中
p(e)=δ-1,对于–δ/2≤e≤δ/2
p(e)=0,否则
具有方差σ2=δ2/12。出现这种情形的条件之一为量化的变量的特征函数(cf)(其为概率密度函数的傅里叶变换)频带有限时。在该情形下,qn均匀。然而,许多随机变量的特征函数并非频带有限(例如考虑高斯随机变量)。不太严格的条件为,对于除k=0之外的所有k,特征函数在频率kδ1具有零值。作为备选,可应用相减抖动,其可用于保证满足上面的条件之一。
在相减抖动的拓扑中,量化器输入包括量化系统输入x加上附加的随机信号(如均匀分布的),称为抖动信号,记为v,其假定固定不变且统计上独立于将要量化的信号[lipshitzetal.,1992]。抖动信号在量化之前加上及在量化之后减去(在接收器处)。对于对抖动信号的精确需要及抖动处理的结果,参见[lipshitzetal.,1992]。实际上,相减抖动假定同样的噪声处理v可在发射器和接收器处产生,并保证独立于量化器输入的均匀qne。
量化知道的波束形成
在现有技术解决方案中,通常已假定双耳助听器系统的一助听器中的传声器处接收的信号无误差地传到对侧,反之亦然。在实践中并非如此。为了在波束形成任务中考虑qn,我们引入新的表示量化噪声的有噪声信号。
波束形成器滤波权重为m维视向量d(其中m为传声器的数量)和噪声协方差矩阵cv(其为m×m矩阵)的函数,例如参见ep2701145a1。
量化知道的波束形成的概念由本申请的发明人在[aminietal.,2016]中进一步描述,其引用于此以了解其进一步的细节。
图2a和2b示意性地示出了声源相对于包括第一和第二听力装置(当分别位于第一(左)和第二(右)耳之处或之中时)的双耳助听器系统的第一和第二实施例的相应几何设置。
图2a示意性地示出了声源相对于包括左和右听力装置hdl,hdr(当分别位于用户u的左和右耳处或左和右耳中时)的助听器系统的几何设置。空间的前和后方向及前和后半平面(参见箭头“前”和“后”)相对于用户u形成并通过用户的视向look-dir(虚线箭头)(在此通过用户的鼻子确定)及通过用户耳朵的(纵向)参考平面(垂直于视向look-dir的实线)确定。左和右听力装置hdl,hdr中的每一个包括位于用户处或耳后(bte)的bte部分。在图1b的例子中,每一bte部分包括两个传声器,即左和右听力装置的位于前面的传声器fml,fmr和位于后面的传声器rml,rmr。每一bte部分上的前和后传声器沿(实质上)平行于视向look-dir的线间隔开距离,分别参见点线ref-dirl和ref-dirr。目标声源s位于距用户距离d处并具有由相对于参考方向(在此为用户的视向look-dir)的角度θ定义的到达方向(在水平面中)。在实施例中,用户u位于声源s的远场中(如断开的实线d所示)。两组传声器(fml,rml),(fmr,rmr)间隔开距离a。
来自前面传声器fml,fmr的传声器信号ifml,ifmr经无线链路在左和右听力装置之间交换。传声器信号包括量化噪声。每一听力装置包括双耳波束形成器滤波单元,设置成从相应的前和后传声器获得两个本地传声器输入(假定实质上不包括量化噪声)及经无线通信链路获得从对侧听力装置接收的一个传声器输入(包括量化噪声)。
图2b示出了根据本发明的双耳助听器系统的第二实施例。其设置与上面结合图2a所述的类似。唯一差别在于,左和右听力装置hdl,hdr中的每一个分别包含单一输入变换器(如传声器)fml和fmr。至少传声器信号imr(包括量化噪声)从右听力装置传到左听力装置并用在那里的双耳波束形成器中。
从目标声源到左和右听力装置的方向被指明(到达方向doa因而可通过角度θ确定)。
图3示出了根据双耳助听器系统bhas的实施例,其包括适于分别位于左和右耳处或左和右耳中或者适于完全或部分植入在用户头部中的左(hadl)和右(hadr)助听装置。双耳助听系统bhas还包括通信链路,配置成在左和右助听装置之间传送量化音频信号,从而使能左和右助听装置中的双耳波束形成。
实线模块(输入单元iul,iur、波束形成器滤波单元bfl,bfr、控制单元cnt及无线通信链路)构成根据本发明的助听系统bhas的基本元件。左(hadl)和右(hadr)助听装置中的每一个包括多个输入单元iui,i=1,…,m,m大于或等于2。相应的输入单元iul,iur提供第i个输入单元处在多个频带及多个时刻的输入信号xi(n)(分别为信号x1l,…,xmal和x1r,…,xmbr)的时频表示xi(k,m)(信号xl和xr中的每一个分别表示左和右助听装置的m个信号),k为频带指数,m为时间指数,n表示时间。左和右助听装置中的每一个的输入单元的数量假定为m个,例如等于2。作为备选,两个装置的输入单元的数量可以不同。如图3中通过记为xil,xir的虚线箭头所示,一个或多个量化传声器信号分别从左助听装置传到右助听装置及从右助听装置传到左助听装置。信号xil,xir(每一个表示一只耳朵处的装置拾取并传给另一只耳朵处的装置的一个或多个传声器信号)用作所涉及听力装置的相应波束形成器滤波单元bfl,bfr的输入,分别参见左和右听力装置中的信号x’ir和x’il。装置之间信号的通信原则上可经有线连接,但在此假定经无线链路,并经适当的天线和收发器电路实施。随时间而变的输入信号xi(n)及第i个输入信号的时频表示xi(k,m)(i=1,…,m)包括目标信号分量和声学噪声信号分量,目标信号分量源自目标信号源。无线交换的传声器信号xir和xil也被假定包括相应的目标和声学噪声信号分量,另外包括量化噪声分量(源自经无线链路交换的传声器信号的量化)。
左(hadl)和右(hadr)助听装置中的每一个包括波束形成器滤波单元(bfl,bfr),其在运行时连接到左和右助听装置的多个输入单元iui,i=1,…,m(iul和iur)并配置成提供(合成)波束成形信号
图3的虚线模块(信号处理单元spl,spr和输出单元oul,our)表示形成助听系统bhas的实施例的一部分的非必需的另外的功能。信号处理单元spl,spr例如可提供波束成形信号
波束形成器滤波单元适于接收至少一本地电输入信号及来自对侧听力装置的至少一量化电输入信号。波束形成器滤波单元配置成确定波束形成器滤波权重(如mvdr滤波权重),当应用于第一电输入信号和量化电输入信号时,其提供相应的波束成形信号。相应的控制单元适于基于特定量化方案的知识考虑量化噪声控制波束形成器滤波单元(经相应控制信号cntl和cntr)。波束形成器滤波权重根据视向量和(合成)噪声协方差矩阵确定,其中总噪声协方差矩阵
其中
例如如果选择中平量化器,方差(如上面指出的)可表达为σ2=δ2/12,其中δ为量化步长,因而量化中使用的比特数nb的函数(对于量化中给定比特数nb’,步长δ因而方差σ2已知)。对于三传声器配置,其中一传声器信号在两个助听器之间交换(及两个本地提供),量化分量的噪声协方差矩阵
其中
左和右助听器hadl,hadr的合成波束形成器滤波权重(考虑量化噪声)可表达为:
其中x=l,r,及dx表示左(x=l)或右(x=r)助听器的波束形成器滤波单元的视向量。视向量dx为m’×1向量,其包含声音从目标声音源到其电信号被所涉及的波束形成器滤波单元考虑的左和右助听器的传声器的传递函数(在图3的例子中,m’=mal+mbr(左和右助听器hadl,hadr的传声器的数量mal,mbl的和;在图4a、4b的例子中,m’=2+2=4))。作为备选,视向量dx包括相对传递函数(rtf),即从目标信号源到助听器系统中相对于(传声器之中的)参考传声器的任何传声器的声传递函数。
图4a示出了听力装置hadl如助听器,适于位于用户的第一耳朵处或第一耳朵中,或者适于完全或部分植入在用户的第一耳朵处的头部中。在此,示出了用于左耳的助听器(参见助听器hadl中的标示“l”,及信号名称x1l,x2l等中的“l”),但其也可用于右耳。听力装置包括第一和第二输入变换器(在此体现在传声器m1,m2中),用于将分别佩戴在第一和第二输入变换器位置处的听力装置的用户周围的声音分别转换为第一和第二(模拟)电输入信号x1l和x2l(参见第一传声器通路上面的表示声音的模拟信号(x1l)的示例性曲线(连续实线曲线))。用户周围的声场假定,至少对于一些时间段,包括来自目标声音源的目标声音与可能的声学噪声的混合。助听器还包括接收器,配置成经通信链路(例如与另一如对侧助听器hadr之间的通信链路,未在图4a中示出)接收第一量化电输入信号。助听器包括分别连接到第一和第二传声器m1,m2的第一和第二模数转换器a/d,分别提供第一和第二数字化电输入信号dx1l,dx2l(参见第一信号通路上面的模拟信号的数字化版本(dx1l)的示例性曲线(由实心点表示))。第一和第二电输入信号例如以在20khz到25khz或更大范围中的频率采样。每一音频样本例如按nb=24比特(或更大)表示的值量化。从而在第一和第二数字化电输入信号dx1l,dx2l中引入小的(且可以忽略的)量化误差(给定样本的模拟值与数字值之间的差)。另外,每一数字化电输入信号可通过滤波器组拆分为子频带信号,从而按时频表示(k,m)提供信号。子频带滤波可结合a/d转换或者在信号处理器hapu中发生,或者在别处发生,只要适当。在该情形下,正向通路的处理如波束形成可在时频域进行。第一和第二数字化电输入信号dx1l,dx2l(其被量化并经通信链路传给另一助听器hadr)及第一和第二量化电信号dx1rq,dx2rq(其经通信链路从另一助听器hadr接收)可以是时域的数字化信号或者由多个数字化子频带信号表示,每一子频带信号表示时频表示的量化信号。子频带信号可由复数部分(幅度和相位)表示,其个别地量化,或者作为备选,使用向量量化(vq)进行量化。
第一和第二数字化电输入信号dx1l,dx2l馈给信号处理器hapu,如包括多输入波束形成器滤波单元(例如参见图3)。在准备传给另一装置时,第一和第二数字化电输入信号dx1l,dx2l中的至少一个(在此为两个)也馈给量化单元qua进行以比ad转换中使用的比特数小的比特数nb’量化(如nb’=8,代替nb=24),从而节约无线链路中的带宽。量化单元qua提供第一和第二量化的数字化电输入信号dx1lq,dx2lq(参见第一信号通路左边的(由开放圆圈表示的)数字化信号的进一步量化的版本(dx1lq)的示例曲线)。该量化具有在传输(或接收)的“传声器信号”中引入不可忽略的量化误差(称为“量化噪声”)的缺点。如结合图1d讨论的,对于给定量化方案(如24到8比特量化),该量化误差已知。量化方案例如固定或者可经从信号处理器到(可能可配置的)量化单元qua的信号qsl配置。关于量化方案的信息(例如nb->nb’),参见信号qsl,例如在量化及可能编码的(参见编码器enc)传声器信号之前或者连同其一起传给另一装置,分别参见信号dx1lq,dx2lq和ex1lq,ex2lq,以使另一装置能考虑传给另一装置及另一装置中接收的传声器信号中的量化。编码器enc将特定音频编码算法应用于量化信号dx1lq,dx2lq,并提供对应的编码信号ex1lq,ex2lq,其馈给发射器tx以传给另一装置如双耳助听器系统的对侧助听器hadr(例如参见图3)或者传给分开的处理装置如智能电话。所选的音频编码算法,如g722、sbc、mp3、mpeg-4等或者专用(非标准)方案,可提供输入信号的无损或有损压缩以进一步减少必要的无线链路带宽。在音频编码方案可配置的情形下,所选方案应传给另一装置(如经信号qsl)。同样,在采样率在量化过程中变化的情形下,这样的信息也应传给另一装置。
类似地,图4a的(左)助听器hadl配置成从另一装置如双耳助听器系统的对侧助听器hadr(例如参见图3)或者从分开的处理装置如无线传声器或智能电话接收一个或多个音频信号。该助听器hadl包括接收器rx,用于无线接收和解调所述一个或多个音频信号并提供对应的(如编码的)电信号dx1rq,dx2rq。另外,该助听器hadl配置成接收关于所接收的音频信号已遭受的量化方案(如nb->nb’)的信息,参见信号qsr,其馈给处理单元hapu。该助听器hadl包括音频解码器,用于对编码的电信号ex1rq,ex2rq进行解码以提供解码的量化信号dx1rq,dx2rq(参见第二信号通路右边的数字化信号(由开放圆圈表示)的量化版本(dx2rq)的示例曲线)。
图4a的(左)助听器hadl还包括输出单元如输出变换器,在此为扬声器sp,用于将来自信号处理器hapu的处理后的电信号out转换为可由用户感知为声音的刺激(在此为声学刺激)。输出单元可包括合成滤波器,用于将子频带信号转换为合成时域信号,只要适当。
信号处理器hapu包括多输入波束形成器滤波单元(例如参见图3和图4b),适于接收本地来源的第一和第二数字化电输入信号dx1l,dx2l及从另一装置接收的第一和第二量化电输入信号dx1rq,dx2rq,并确定波束形成器滤波权重,当应用于第一电输入信号和量化电输入信号时,其提供波束成形信号xbf,参见图4b。信号处理器hapu通常包括另外的处理算法,用于进一步增强空间滤波的信号xbf,例如用于提供进一步的降噪、压缩放大、频移、输出和输入的去相关等,以提供用于呈现给用户的合成的处理后的信号out(和/或传给另一装置进行分析和/或在那里进行进一步处理)。
图4b示出了图4a的信号处理器的示例性波束形成器滤波单元bf形成部分的音频信号输入和输出。波束形成器滤波单元bf通过将适当的波束形成器滤波权重w应用于输入信号(在此为本地来源的第一和第二数字化电输入信号dx1l,dx2l及从另一装置接收的第一和第二量化电输入信号dx1rq,dx2rq)而提供波束成形信号xbf。左助听器hadl的第一和第二(有噪声)数字化信号dx1l,dx2l(及右助听器hadr的dx1r,dx2r)中的每一个(至少在某些时间段)包括目标信号分量s和声学噪声分量v。第一和第二量化电输入信号包括源自有噪声声学信号(‘s+v’)的部分(如通过噪声协方差矩阵
其中两个非零对角线矩阵元素
在图4a、4b的例子中,第一和第二量化电输入信号源自右助听器hadr:
dx1rq=dx1r+qn1r
dx2rq=dx2r+qn2r
对于给定量化方案,量化噪声的统计性质已知(及有关参数可在所涉及的助听器中得到),及相应量化噪声协方差矩阵
其中xl(k,m)=(dx1l(k,m),dx2l(k,m),dx1rq(k,m),dx2rq(k,m))h,其中k和m分别为频率和时间指数,及h指厄米转置。在图4a、4b的例子中,
从而,考虑量化噪声以提供优化的波束形成器。忽略量化噪声将导致欠佳的波束形成器。
当由对应的过程适当代替时,上面描述的、“具体实施方式”中详细描述的及权利要求中限定的装置的结构特征可与本发明方法的步骤结合。
除非明确指出,在此所用的单数形式“一”、“该”的含义均包括复数形式(即具有“至少一”的意思)。应当进一步理解,说明书中使用的术语“具有”、“包括”和/或“包含”表明存在所述的特征、整数、步骤、操作、元件和/或部件,但不排除存在或增加一个或多个其他特征、整数、步骤、操作、元件、部件和/或其组合。应当理解,除非明确指出,当元件被称为“连接”或“耦合”到另一元件时,可以是直接连接或耦合到其他元件,也可以存在中间插入元件。如在此所用的术语“和/或”包括一个或多个列举的相关项目的任何及所有组合。除非明确指出,在此公开的任何方法的步骤不必须精确按所公开的顺序执行。
应意识到,本说明书中提及“一实施例”或“实施例”或“方面”或者“可”包括的特征意为结合该实施例描述的特定特征、结构或特性包括在本发明的至少一实施方式中。此外,特定特征、结构或特性可在本发明的一个或多个实施方式中适当组合。提供前面的描述是为了使本领域技术人员能够实施在此描述的各个方面。各种修改对本领域技术人员将显而易见,及在此定义的一般原理可应用于其他方面。
权利要求不限于在此所示的各个方面,而是包含与权利要求语言一致的全部范围,其中除非明确指出,以单数形式提及的元件不意指“一个及只有一个”,而是指“一个或多个”。除非明确指出,术语“一些”指一个或多个。
因而,本发明的范围应依据权利要求进行判断。
参考文献
·[haykin&liu,2010]s.haykinandk.j.r.liu,“handbookonarrayprocessingandsensornetworks,”pp.269–302,2010.
·[srinivasanetal.,2008]s.srinivasan,a.pandharipande,andk.janse,“beamformingunderquantizationerrorsinwirelessbinauralhearingaids,”eurasipjournalonaudio,speech,andmusicprocessing,vol.2008,no.1,pp.1–8,2008.
·[lipshitzetal.,1992]s.p.lipshitz,r.a.wannamaker,andj.vanderkooy,“quantizationanddither:atheoreticalsurvey,”audioeng.soc.,vol.40,pp.355–375,1992.
·[aminietal.,2016]jamalamini,richardc.hendriks,richardheusdens,mengguo,andjesperjensen,“ontheimpactofquantizationonbinauralmvdrbeamforming”,speechcommunication;12.itgsymposium;proceedingsof,paderborn,germany,5-7oct.2016,publicationyear:2016,page(s):1–5,isbn:978-3-8007-4275-2.
·ep2701145a1
- 还没有人留言评论。精彩留言会获得点赞!