一种基于字符特征的无载体文本隐写方法与流程
本发明涉及信息隐藏技术领域,特别是涉及一种基于网络文本大数据的无载体文本隐写方法。
背景技术:
信息隐藏旨在隐藏秘密信息的存在,可应用于隐蔽通信、数字水印等领域。目前已有文本隐写方法,如:基于格式变换的文本隐写方法、基于同义词替换的文本隐写方法、基于文本生成的文本隐写方法等。这些文本隐写方法在应用时各有优缺点,如:基于格式变换的文本隐写方法主要通过改变文本文件的行间距、字间距、颜色等格式属性达到表达秘密信息的目的,它的缺点在于格式变换会导致文本产生失真,因而无法抵抗重新输入和格式重排的攻击手段。基于同义词替换的文本隐写方法是通过替换同义词实现对秘密信息的表达,它的缺点是替换的同义词不一定符合语句的语义环境,造成文本语义层面的异常。基于文本生成的文本隐写方法受限于自然语言处理技术,生成较长文本时容易出现可读性差、语义异常等问题。综上所述,目前的文本隐写技术存在易失真、抵抗攻击能力差等局限,使得它们在很多情况下无法保证隐写系统拥有较高的隐蔽性。
技术实现要素:
为了克服上述现有技术的不足,本发明提供一种基于字符特征的新型文本隐写方法。该方法选取字符特征表示二进制数字,将秘密信息处理为二进制形式后,利用网络大数据环境下丰富的网页文本资源,寻找并选取一个或多个合适的网络文本作为载体,将二进制密文串嵌入到相应的文本中完成秘密信息的传递与交互。该方法不仅解决了现有文本隐写方法中载体被修改和语义异常等文本失真问题,还可有效地避免用于通信的载体不符合语境或者可读性差等问题,具有隐蔽性高、可扩展性强、嵌入率高等优势,有利于促进隐写技术的应用与发展。
本发明解决技术问题所采用的技术方案是:一种基于字符特征的无载体文本隐写方法,包括发送方的嵌入过程和接收方的提取过程,其特征在于:
所述的嵌入过程:定义字符特征,建立文本语料库并根据所选取的字符特征建立其索引二叉树,对秘密消息预处理为二进制密文串,对该密文串进行封装、与二叉索引树进行匹配及分段后找到与接收方交互的urls或文本;
所述的提取过程:接收方收到urls或文本后检查有效性,分析和提取头部,依据发送方使用的分段方式处理后续文本内容得到原始二进制密文串,进而解码或解密获得原始秘密消息。
所述的嵌入过程包括以下步骤:
1)选取字符特征,对字符特征进行编码,即确定用来表达二进制位“0”和“1”的字符特征;
2)获取大量文本创建文本大数据语料库,语料库中要包括网络文本及其url元数据相关信息;
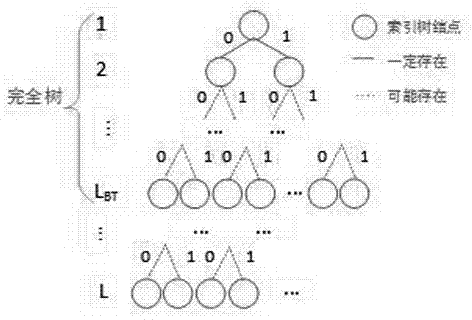
3)根据所选取的字符特征为所创建的文本语料库建立二叉索引树,并记以该索引二叉树根结点为根的最大完全二叉子树的深度为lct;
4)预处理秘密信息,将秘密信息转换为二进制密文串形式,将秘密信息转换为二进制密文串形式的转换方式包括编码或加密方式;
5)在二进制密文串前增加头部,构建二进制密文包;头部要包含二进制密文串分段方式,可选项有二进制密文串长度信息;
6)密文匹配与分段:从二叉索引树的根,将二进制密文包与二叉索引树边代表的值进行匹配,找到与二进制密文串相匹配的路径,该路径的另一端结点中的存储的urls值就是所要找的值;存在二进制密文串的长度超过路径长度的可能,此时在对二进制密文串匹配过程中进行分段处理,并对截取后的二进制子串继续匹配与分段;
7)依次从前述每次匹配得到的urls中选取一个url或其对应文本,发送给接收方,完成秘密信息发送过程。
所述的提取过程包括以下步骤:
1)接收发送端发送来的urls或文本:基于网络的可靠传输,接收端以发送顺序接收到所有的urls或文本;若接收到的是urls,则从网络上或者与发送方共享的语料库中获取urls对应的文本。
2)对所收到的文本进行有效性检查;此步骤为可选项。
3)分析第一个文本,确定分段方式,对定长分段还继续分析第一个文本的后续内容,确定定长分段的长度和最后一个文本的有效字符个数;对变长分段,该文本中的后续所有字符组成新文本进行后续处理。
4)根据确定的二进制密文串分段方式,对后续文本从文本开始选取定长或变长的文本段进行字符特征分析,得到对应的二进制串片断。
5)依次连接前述所得二进制密文串片断得到完整的原始二进制密文串。
6)提取秘密信息:根据双方约定的编码或加密规则将完整的二进制密文串进行解码或解密得到秘密信息。
本发明的有益效果具体如下:
1)选取字符特征进行编码,并基于搜索思想,整个隐写过程不存在文本的修改和替换,因而可以有效避免文本的失真。
2)文本传输在网络中主要借助url完成,url是一种网络中统一的资源定位符,它符合作为隐写载体被普遍使用的要求,且它真实存在于网络中,故不易引起攻击者注意。url可扩展为uri,增加适用场景;同时直接进行文本交互也不容易引起攻击者注意。
3)该方案可以有效应用于即时通信或博客等不同场景下的短文本。
附图说明
图1为本发明的嵌入过程和提取过程的流程图;
图2为本发明的二叉索引树实例的结构示意图。
具体实施方式
如图1所示,本方法分为嵌入过程和提取过程两部分,具体过程如下:
一、嵌入过程,包括以下步骤:
1)选取字符特征,对字符特征进行编码。字符特征的选取有多种,如字符笔画数、结构等。这里以字符笔画数的奇偶性特征为例,以字符笔画数为偶数表示“0”,笔画数为奇数表示“1”。
2)抓取互联网文本并创建网络文本大数据语料库。通过网络爬虫等方法抓取网页,解析出其中文本或其它方式获取文本,构建通用网络文本语料库;也可根据爱好、话题等获取主题相关的文本,建立专用文本语料库。语料库要至少包含文本本身内容和其对应的url信息。
3)依据选定的字符笔画数奇偶性特征,为所构建的网络文本语料库建立二叉索引树,如图2所示。二叉索引树根结点有且仅有两个子结点,其它结点至多有两个子结点,每个结点表示文本中的一个字符,存放以该字符结尾的文本对应的一个或多个urls,文中相邻字符在二叉索引树中表现为父子关系。根结点可以是空或者文本的第一个字符,若文中后继字符的笔画数为偶数,则将其作为其父结点的左孩子,连接父子结点的边表示“0”;若后继字符的笔画数为奇数,则将其作为其父结点的右孩子,连接父子结点的边表示“1”,直到文本结束为止。这样每个文本在二叉索引树中对应着一条从根结点开始的路径。记以该二叉索引树的根为根结点的最大完全二叉树的深度为lct。
4)预处理秘密消息(需要隐藏的信息)。为保证信息安全传输,通常要通过加密或编码等方法将密文转换成二进制密文串,具体的编码方式和加密方法(常规技术,如:区位码或其它字符编码方式或加密技术)可任意选择,只要有可逆运算方法即可,以便在接收端可还原秘密消息。
5)在二进制密文串增加头部。头部的首个比特位表示密文二进制串与二叉索引树路径匹配的分段方式,如该比特值为“0”,则表示定长匹配分段,若为“1”,则表示变长匹配分段;若后续匹配过程中对二进制密文串采用定长分段时,则在首个比特后跟双方约定的n(n为正整数,且n≥7)个比特存放二进制密文串的长度,以便于在接收方通过该长度与分段数量和分段长度之间的关系准确提取秘密信息;若采用变长匹配方式,则可无其它头部信息。
6)密文匹配与分段。在定长匹配中,首先在索引二叉树中找到与头部匹配的路径所对应的一个或多个urls,再对二进制密文串与从二叉索引树根开始与其前缀片段匹配的路径;若是变长匹配,则将整个二进制密文包与从二叉索引树根开始与其前缀片段相匹配的路径;每次匹配都从根结点开始,将得到与定长或变长二进制密文片段匹配的一个或多个表达秘密信息的urls。定长分段以lct为分段长度;变长分段则以每次匹配被截取后的二进制密文串在二叉索引树中的最大匹配深度为分段长度。具体应用时,可选择使用url最少的分段方式,并在头部首比特中指明所选择的分段方式。
7)选取url,将其或其对应的文本发送给接收方。在二叉索引树中得到每个二进制密文串片段的路径,除根结点外的另一端结点中的所有url值都可代表该二进制密文串,选取与密文相似度最小的url或其对应文本。将所有片段对应的url或其文本按序发送给接收方。
二、提取过程,包括以下步骤:
1)接收并保存从发送方来的urls或文本。这里基于网络进行可靠传输的基本假设,认为接收端按照发送端发送的顺序接收所有urls或文本,若接收到的是urls,则从网络上或者从与发送方共享的语料库中获取url对应文本。
2)可选地对所获的文本进行安全检查。通过检查它们是否属于相同话题或者是否是收发双方都关注的话题以及urls的合法性等,在一定程度上判断接收到的信息是否有效或被篡改等。
3)确定分段方式,确定定长分段的长度和最后一个文本的有效字符个数。分析第一个文本中的首字符特征,若其字符特征值为“0”,则表示发送方以定长分段方式处理密文串;若该值为“1”,则表示以变长分段方式处理密文串。确定发送方采用的密文分段方式后,若为定长分段方式,则继续分析第一个文本从第2个汉字开始的n个字符的特征,以确定二进制串密文长度,进而根据文本个数确定分段长度及最后一个文本中嵌入的二进制位数。若为变长分段,则分析该文本的后续所有字符组成新文本继续进行下面的分析。
4)根据确定的密文分段方式,对后续文本从文本开始选取定长或变长的文本段进行字符特征分析,得到对应的二进制密文串片断。对定长分段方式,仅读取最后一个文本中的有效长度的字符串,并获得对应的二进制密文片段。对变长分段方式,每个文本都读取其所有字符并分析它在二叉索引树中对应的有效路径,获得二进制密文片段。
5)按照接收到的文本顺序将所得二进制密文片段连接形成完整的密文二进制串。
6)对所得二进制密文串采取发送方操作的逆运算进行解码或解密,获得原始秘密消息。
如上所述,本发明在发端需要建立文本语料库,为减少搜索时间、提高隐写速度、便于扩展,本发明建立文本语料库的二叉树索引树,如图2所示。二叉索引树包括根节点、中间结点、叶子结点三类结点。索引树的所有结点都有共同的数据结构,它由四个指针组成,分别指向其父结点、左右孩子结点和urls数组。
其中根节点没有父结点且指向url数组的指针为空;中间结点有且只有一个父节点,且至多2个子节点,它的url数组指针可以为空或指向urls;叶子结点的urls数组指针不能为空。由图2中的索引树结构可以发现,索引树的上部分的节点可构成完全二叉树,该完全二叉树的深度反映了语料库表达等长二进制串的能力。在进行隐写时可选取该完全二叉树与二进制密文进行匹配,即定长匹配分段方式,也可让整个二叉索引树参与匹配,即变长匹配分段方式。
本发明的工作原理:
本发明利用字符特征表示二进制位“0”和“1”,实现了秘密信息由文本字符特征表示;秘密信息经过编码或加密等操作转换为二进制形式后对二进制密文串进行封装、分段;并基于网络大数据环境下的网页文本资源寻找候选载体,以合适的urls或文本进行表示二进制密文片段,最终通过发送urls或文本完成秘密信息的传递。接收端获得文本后,分析文本字符特征,确定二进制密文分段方式和长度,进而分析后续文本字符特征得到二进制密文片段,并将这些片段重组为完整的密文二进制串,然后再解码或解密获得秘密信息。
显然,本领域技术人员基于本发明的宗旨所做的许多修改和变化属于本发明的保护范围。
如上所述,对本发明的实施例进行了详细地说明,但是只要实质上没有脱离本发明的发明点及效果可以有很多的变形,这对本领域的技术人员来说是显而易见的。因此,这样的变形例也全部包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!