基于服务发现和容器技术的大数据平台弹性伸缩方法与流程
本发明涉及云计算大数据弹性伸缩领域,特别涉及一种基于服务发现和容器技术的大数据平台弹性伸缩方法。
背景技术:
在云计算相关领域,弹性伸缩有助于数据中心保持资源管理的鲁棒性,能够降低能耗缓解系统资源浪费。目前不管是流量巨大的电商、游戏等娱乐行业,还是请求量波动极大的视频、直播等新媒体行业,都需要在“资源不足”和“资源浪费”之间做权衡。邓子凡针对水平伸缩和垂直伸缩各自的缺点,提出一种将水平伸缩和垂直伸缩两种方式相结合的弹性伸缩模式,但依然存在虚拟机技术带来的缺点。在gandhi等人的研究中指出了传统的解决方案的缺陷:alwayson采用全冗余的方式会造成严重的资源浪费;reactive采用延迟启动策略,但在虚拟机或应用环境启动时setup延迟时间太长,一般都会超过200秒;predictive尝试利用线性回归等策略来拟合负载模型,提前启动虚拟机来缩短setup时间;弹性伸缩方法根据请求量动态调整资源配给,但由于虚拟机的启动延迟等缺陷,而采用了与predictive结合的方式。
随着容器技术的发展,弹性伸缩方法得到了更广泛的利用。例如在ywchen等人的研究中利用容器的弹性伸缩加速异构环境中的大数据作业,但在其解决方案中需要扩展大数据平台的相关模块,缺乏通用性。toffettig等人利用容器的弹性伸缩提出了一种能够自我管理的微服务架构,在其实现中采用etcd作为状态持久化中心,可以实时响应到集群状态的节点故障,从而实现自我恢复。heyu等人提出了一种基于容器的高性能计算集群弹性伸缩架构,但其实现中用单节点维护服务状态,容易出现单点故障,缺乏可用性,kanc等人实现了一种基于容器的弹性伸缩云平台,该实现采用了与predictive方法相结合的方式来预测流量变化,不能应对流量突变。
虽然最近几年在面向大数据平台的弹性伸缩方向上已经开展了不少研究工作,然而,从传统的架构上来看,弹性伸缩需要结合predictive方法预测流量的变化,这是由于虚拟机具有较高的启动延迟的缺点,而且这样的方法无法实时应对流量突变。此外,当前基于容器技术的弹性伸缩方法要不就是需要额外的扩展,要不就是存在功能上的缺陷,对目前流行的大数据平台不具有普遍适用性。
技术实现要素:
鉴于上述现有技术存在的不足,本发明目的是提供一种基于服务发现和容器技术的大数据平台弹性伸缩方法,能根据服务代理提供大数据服务的生命周期信息,从而能够感知到集群内部的状态变化,为大数据集群提供按需的、灵活的弹性伸缩服务,并有效提高集群资源利用率。
为实现以上目的,本发明采取如下技术方案:
本发明的一种基于服务发现和容器技术的大数据平台弹性伸缩方法,包括以下步骤:
第一步骤:使用容器技术对各大数据平台进行组件化封装处理;
第二步骤:初始化大数据集群管理的元数据目录,在大数据集群启动时,拉取并启动相应大数据平台组件,并将集群元数据信息注册到服务代理;
第三步骤:每个主机集群节点的状态监控器周期向服务代理汇报心跳数据,并更新相关信息,实现对集群内部的状态感知;
第四步骤:主机集群的代理服务周期向服务代理读取大数据集群管理信息,判断是否存在节点失效或需求变更情况,若在心跳周期内服务代理未接收到容器节点的状态数据则将该节点视为节点失效,此时服务代理从元数据中将该节点运行状态标记为失效,反之节点运行状态标记为有效,如果存在节点失效或需求变更情况,则执行第五步骤;否则,执行第六步骤;
第五步骤:若存在节点失效情况,则尝试恢复失效的节点容器;若存在需求变更情况,则根据需求变更元数据,相应代理服务为集群添加或删除节点容器;
第六步骤:重复执行以上第三至第五步骤,直至集群服务终止运行。
作为优选的技术方案,在第一步骤中,所述对各大数据平台的进行组件化封装处理,具体使用docker容器虚拟化技术对大数据平台进行镜像化封装处理,形成大数据组件库,包括hadoop镜像、spark镜像、kafka镜像、以及storm镜像。
作为优选的技术方案,在第二步骤中,所述元数据目录,具体包括根目录为每个注册的大数据集群单独维护的一个128位guid、作为每个独立大数据集群个体的标识、子目录存储集群各节点的相关信息、以及集群需求变更元数据信息,其中,所述集群需求变更元数据信息,无变更以0标识,增加节点以“1”+主机ip字符串标识,删除节点以“2”+主机ip字符串标识;所述子目录存储集群各节点的相关信息,具体包括所属集群id、自身ip地址、节点运行状态、cpu使用率、内存使用率、以及io负载情况,并使用json格式进行存储,所述节点运行状态,有效以0标记,失效以1标记。
作为优选的技术方案,在第三步骤中,所述每个主机集群节点的状态监控器周期向服务代理汇报心跳数据,并更新相关信息的方法为:
状态监控器获取当前主机以及通过容器api获取运行在当前主机上的所有容器的相关信息,向服务代理汇报心跳数据并进行更新,其中,所述相关信息具体包括当前主机以及运行在当前主机上的各容器的ip地址、运行状态和各资源信息,所述各资源信息包括cpu使用率、内存使用率以及io负载情况;同时设置心跳包响应超时周期为5s。
作为优选的技术方案,在第四步骤中,所述服务代理作为服务与外界通信的桥梁,提供一切保存在服务端的相关信息,同时具备更新相关信息的功能,所述相关信息包括服务运行的程序文件、依赖库、配置和数据;所述代理服务采用订阅发布设计模式实现异步通信,负责周期性的轮询访问订阅列表中的所有组件信息,根据获取的服务状态信息处理各节点的节点失效或需求变更情况,按需求进行重启节点或增删节点操作;所述判断是否存在节点失效或需求变更的具体方法为:
根据各节点周期反馈的资源信息,获取最近的10个心跳周期的资源利用率信息,设一个大数据集群容器节点有n个,用ci、mi、ii分别表示第i个节点的cpu使用率、内存使用率、以及io负载,则各资源平均使用率为
作为优选的技术方案,在第五步骤中,所述根据需求变更元数据,相应代理服务为集群添加或删除节点容器的方法为:
若字符串的首字母为“1”时,当其中一个代理服务读取到字符串剩余部分所代表ip与自身所属主机ip相同时,则进行增加容器节点操作;若字符串的首字母为“2”时,当其中一个代理服务读取到字符串剩余部分所代表ip与自身所属主机ip相同时,则进行删除容器节点操作。
本发明相对于现有技术具有如下的优点和效果:
1、本发明采用容器化解决方案,流量变化可以从服务代理中实时获得,不但极大的降低弹性伸缩的响应时间,还可以实时感知到负载的变化,从而直接调整容器数量,不再需要与predictive方法相结合。
2、本发明相对于传统的大数据平台的生命周期及服务状态会封闭在平台内部实现,平台外部是无状态感知的,而提供的基于服务发现和容器技术的大数据平台弹性伸缩方法不需要修改大数据平台的特定模块,采用外部监控轮询的方式检查服务状态,适用于大多数的大数据平台,具体普遍适用性。
附图说明
图1为本发明方法的流程图;
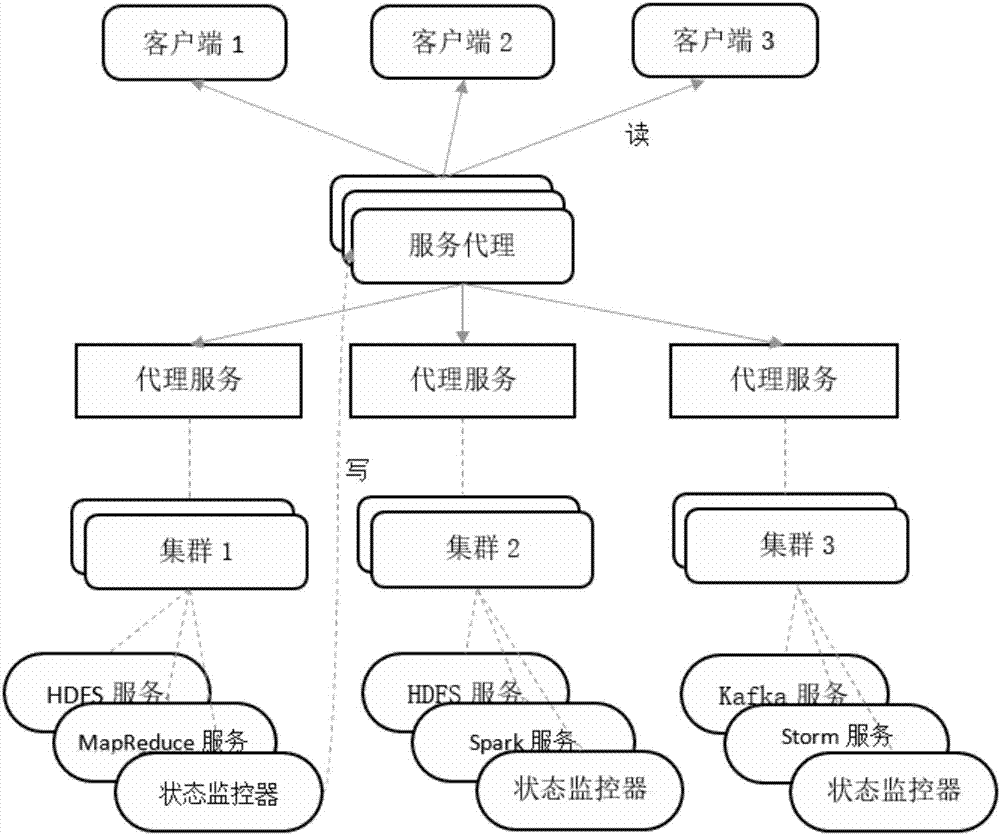
图2为基于服务发现和容器技术的大数据平台弹性伸缩方法的实施示意图。
具体实施方式
下面结合附图对本发明作进一步的详细描述,但本发明的实施和保护范围不限于此。
实施例
如图1所示,为本发明方法的流程图,本发明基于服务发现和容器技术的大数据平台弹性伸缩方法,具体包括下述内容:
1、使用docker容器虚拟化技术对大数据平台进行镜像化封装处理,形成大数据组件库;
2、初始化大数据集群管理的元数据目录,在大数据集群启动时,拉取并启动相应大数据平台组件,并将集群元数据信息注册到服务代理,其中,元数据目录包括根目录为每个注册的大数据集群单独维护的一个128位guid,作为每个独立大数据集群个体的标识,子目录存储集群各节点的状态信息以及集群需求变更元数据信息,而各节点的状态信息具体包括所属集群id、ip地址,节点运行状态,cpu使用率,内存使用率,io负载情况,并使用json格式进行存储;
3、每个主机集群节点的状态监控器周期向服务代理汇报心跳数据,并更新所有相关信息,包括当前主机的ip地址、运行状态和各资源信息(包括cpu使用率、内存使用率以及io负载情况),以及运行在主机上的各容器的ip地址、运行状态和各资源信息(包括cpu使用率、内存使用率以及io负载情况),同时设置心跳包响应超时周期为5s,实现了对集群内部的状态感知;
4、主机集群的代理服务周期向服务代理读取大数据集群管理信息,判断是否存在节点失效或者需求变更情况,如果存在,则转入步骤5;否则,转入步骤6;
具体判断的方法为:
若在心跳周期内服务代理未接收到容器节点的状态数据则将该节点视为节点失效,此时服务代理从元数据中将该节点运行状态标记为失效,反之节点运行状态标记为有效;根据各节点周期反馈的资源信息,获取最近的10个心跳周期的资源利用率信息,设一个大数据集群容器节点有n个,用ci、mi、ii分别表示第i个节点的cpu使用率,内存使用率以及io负载,则各资源平均使用率为
5、若存在节点失效情况,则尝试恢复失效的节点容器;若存在需求变更情况,则根据需求变更元数据,相应代理服务为集群添加或者删除节点容器。
6、重复执行以上步骤3到步骤5,直至集群服务终止运行。
如图2所示,给出了基于服务发现和容器技术的大数据平台弹性伸缩方法的一种实施方式,该状态感知弹性伸缩模型由服务代理、代理服务和状态监控器3个部分组成,总体结构采用主从式架构设计,其中服务代理作为服务与外界通信的桥梁,提供一切保存在服务端的相关信息,包括服务运行的程序文件、依赖库、配置和数据等,同时具备更新相关信息的功能;代理服务采用订阅发布设计模式实现异步通信,负责周期性的轮询访问订阅列表中的所有组件信息,根据获取的服务状态信息处理各节点的节点失效或者需求变更情况,按需地进行重启节点或者增删节点操作;状态监控器是服务运行过程中与注册中心保持有状态连接的核心,主要任务是实时监测服务可达性、配置信息和各节点组件的状态信息,即周期性向服务代理汇报心跳数据,使服务代理能够更新相关状态信息。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!