基于密度聚类的容迟网络路由方法与流程
本发明属于通信技术领域,主要涉及容迟网络路由方法,可用于移动车载网、野生动物监测传感网和移动社交网的路由决策。
背景技术:
容迟网络指部署在极端环境下由于节点的移动或者能量调度等原因而导致节点间只能间歇性进行通信,甚至长时间处于中断状态的一类网络。vahdat等提出著名的传染病路由算法epidemic是基于洪泛的代表性路由协议,每个节点存储所要转发的消息,优点是不需要额外的拓扑控制信息,同时可以取得较高消息投递率和低的端到端时延,无需对链路状态进行预测与估计,但网络中存在大量的冗余副本将导致节点能耗增加和缓存溢出,进而导致网络的资源利用率低和整体运行效能低下。spray&wait算法是一种单一副本路由和多副本复制路由方案之间的权衡策略,它由spray阶段和wait阶段组成。spray阶段源节点将需要传输的消息复制l份,并独立地转发给l个不同的中继节点,如果此阶段发现目的节点,则消息传输结束,若在该阶段没有发现目的节点,则转入wait阶段,携带消息副本的l个中继节点不再转发消息,而是各自执行直接传输算法,等待与目的节点的相遇机会。spray&wait算法与传染病路由算法相比,一定程度减少了网络中传输的信息数量,降低网络的负载,但加大了消息传输的平均时延。
prophet路由算法是基于历史预测策略的典型代表,为克服基于复制策略中的消息自制的盲目性而提出的,通过消息历史传输的成功概率进行估算和比较,选择到达目的节点概率更高的中继节点,通过这种有选择性的复制消息,避免生成低效传输的消息副本,提高网络的资源利用率。prophet路由算法与传染病路由算法相比,具有更高的平均消息传输率和更低的通信负载,平均时延也表现较好。
prorhet路由算法的具体内容:当两节点相遇时,它们将相互交换各自的预测向量,其中预测向量包含了该节点到达其它所有节点的传送预测概率信息,如传送预测概率p(a,b)表明节点a能够发送信息到节点b的概率。首先,节点将利用从另一节点接收到的预测向量来更新本节点上的旧预测向量信息。具体实现分以下三步:
1)更新相遇的两节点a,b之间的传送预测概率(pinit是初始化常数)如(1)式:
p(a,b)=p(a,b)old+(1-p(a,b)old)×pinit(1)
2)如果一对节点在一段时间内没有相遇,传送预测概率将要衰减。衰减的方程如(2)式:
p(a,b)=p(a,b)old×γk(2)
其中γ是衰减常数,k表示衰减的时间间隔,如果在k时间单位内两节点没有相遇,则两节点之间的传送预测概率要衰减。k的取值要根据具体的网络情况来设定。
3)利用传送预测概率的传递性更新。例如,如果a经常遇到b,b又经常遇到c,则可以这么说,a通过b传递,a能够发送信息到节点c的概率也不会低。具体的传递方程如(3)式:
p(a,c)=p(a,c)old+(1-p(a,c)old)×p(a,b)×p(b,c)×β(3)
其中β是传递系数,反映了传递对于传送预测概率的影响大小。进行完以上三步预测向量更新后,两节点开始进行传送数据包。发送策略如下:如果p(b,d)>p(a,d)则节点a将发送数据包到相遇节点b。信息根据发送策略不断转发,直到该数据包到达目的节点。
prophet路由算法存在的问题是:每个节点需要存储本节点与网络其它节点的投递预测值,并且每当两节点相遇时,需要对投递预测值进行更新、衰退、传递性的计算,网络的开销很大。
技术实现要素:
本发明的目的在于克服prophet路由算法已有技术的不足,提出一种基于密度聚类的容迟网络路由方法,网络中,基于密度聚类的簇内节点不需要计算投递预测值,数据采用贪婪转发,在容迟网络中控制开销大为减小,提高了数据包传送成功率。
本发明中基于密度聚类的容迟网络路由方法的具体步骤为:
1)考虑容迟网络节点密度比较稀疏,每个节点通过gps获取地理位置信息,用自己的节点标识号、位置信息构造hello报文,向自己的一跳邻居周期性广播hello报文,每一个节点通过两次hello报文交换,分别将自己和自己一跳邻居节点的邻居节点个数广播给自己的一跳邻居节点.来获得两跳邻居节点个数。如果至少连续两跳的邻居节点个数都大于或等于节点个数阈值,可获得一组密度相连的节点,即形成密度聚类簇,簇内的节点设定簇标识;
密度聚类簇指设定节点的邻域密度阈值,也就是节点通信半径内的节点个数阈值。每个节点通过gps获取地理位置信息,通过计算两节点和之间的距离,确定节点通信半径内的节点个数。一个节点p在通信半径内的节点个数至少大于等于邻域密度阈值时,称此节点为核节点。若节点q在另一个节点p的通信半径内且p为核节点,则称节点q从节点p直接密度可达。若存在一个节点链p1、p2、...、pn,对于pi∈d(1<i<n),d为网络中的节点,且pi+1是从pi的直接密度可达,则点pn从p1密度可达。若存在节点o,使得节点p和q都从o密度可达,则节点p和q密度相连。使用密度相连的闭包来发现连通的稠密区域作为簇,基于密度聚类的簇就是一组密度相连的节点,以实现最大化的密度可达。
2)从源节点开始,判断该节点是否在簇内,若是,采用贪婪地理路由协议转发数据包,否则采用prophet路由协议转发数据包,执行步骤(4);
3)计算核节点邻居个数,判断其是否小于领域密度阈值,若是,核节点降为普通节点,产生了簇分裂或簇消失,此节点变为簇外节点;
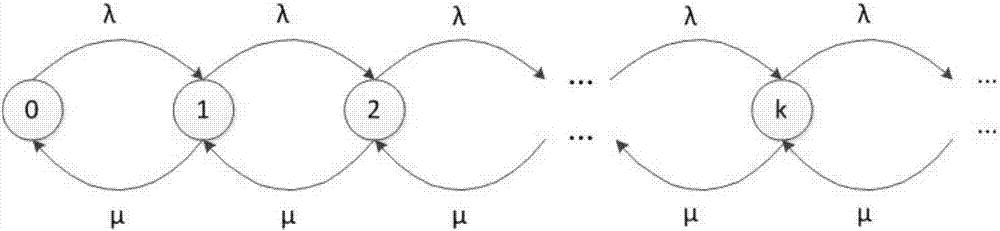
核节点邻居个数是否小于领域密度阈值的判断:采用生灭过程计算核节点邻居个数。设网络有n个节点,其中某个节点通信半径内,其它的节点按强度为λ的poisson过程到达,离开时间t服从参数为μ的负指数分布。
①在时刻t,一节点在(t,t+δt)内进入通信半径的概率为λδt+o(δt).
②在时刻t,一节点在(t,t+δt)内移出通信半径的概率为μδt+o(δt).
③各节点之间的状态是相互独立的。
此节点通信半径内可能的状态0、1、2…k
0---通信范围内无其它节点。
1---通信范围内有一个节点。
2---通信范围内有两个节点,一个停留,一个要离开。
k---通信范围内有k个节点,k-1个停留,一个要离开。
某节点通信半径内的节点变化是一个生灭过程,当进入到平稳状态后,
状态0处:
状态1处:
在状态k处:
当ρ<1时,有
ρ<1说明两个节点先后离开的时间小于两个先后到达的节点的时间。
通信范围内节点的平均数
通信范围内节点停留所花费时间的平均值:
①在一个周期内,通过hello报文交换,节点的标识号检测到达通信范围的节点个数及移出通信范围的节点个数,确定λ和μ的值。
②确定核节点通信范围内节点的平均数l,如果小于邻域密度阈值,核节点降为普通节点,簇在此处产生分裂或消失。
4)簇外节点采用prophet路由协议转发数据包,当数据包转发到簇内节点时,此簇内节点需要向簇内广播已收到数据包,簇内其它节点不再接收簇外的信息,返回步骤(2)。
附图说明
图1是基于密度聚类的簇拓扑图。
图2是核节点的邻居节点状态转移图。
图3是本发明的流程图。
图4消息投递率图。
图5网络负载率图。
图6平均时延图。
图7平均跳数图。
具体实施方式
下面结合实施例和流程图图3对本发明作进一步的说明。
1)考虑容迟网络节点密度比较稀疏,每个节点通过gps获取地理位置信息,用自己的节点标识号、位置信息构造hello报文,向自己的一跳邻居周期性广播hello报文,每一个节点通过两次hello报文交换,分别将自己和自己一跳邻居节点的邻居节点个数广播给自己的一跳邻居节点.来获得两跳邻居节点个数。如果至少连续两跳的邻居节点个数都大于或等于节点个数阈值,可获得一组密度相连的节点,即形成密度聚类簇,簇内的节点设定标识;
密度聚类簇指设定节点的邻域密度阈值,也就是节点通信半径内的节点个数阈值。每个节点通过gps获取地理位置信息,通过计算两节点和之间的距离,确定节点通信半径内的节点个数。一个节点p在通信半径内的节点个数至少大于等于邻域密度阈值时,称此节点为核节点。若节点q在另一个节点p的通信半径且p为核节点,则称节点q从节点p直接密度可达。如图1,存在一个节点链m1、m2、...、m5,点m5从m1密度可达,存在一个节点链n1、n2、...、n6,点n6从n1密度可达。存在节点o,使得节点m和n都从o密度可达,则节点m和n密度相连。如图1所示,密度相连的闭包作为密度聚类的簇。
2)从源节点开始,判断该节点是否在簇内,若是,采用贪婪地理路由协议转发数据包,否则采用prophet路由协议转发数据包,执行步骤(4);
3)计算核节点邻居个数,判断其是否小于领域密度阈值,若是,核节点降为普通节点,产生了簇分裂或簇消失,此节点变为簇外节点;
簇内节点的hello报文交换15秒一个周期,在一个周期内,通过节点的标识号检测到达通信范围的节点个数及移出通信范围的节点个数,确定λ和μ的值,为了在簇内贪婪地理路由协议能正常运行,设定领域密度值为8个节点,核节点邻居个数是否小于领域密度阈值的判断:采用生灭过程计算核节点邻居个数。设网络有n个节点,其中在o节点通信半径内,其邻居节点按强度为λ=40个/小时的poisson过程到达,离开时间t服从参数为μ=46个/小时的负指数分布。
①在时刻t,一节点在(t,t+δt)内进入通信半径的概率为λδt+o(δt).
②在时刻t,一节点在(t,t+δt)内移出通信半径的概率为μδt+o(δt).
③各节点之间的状态是相互独立的。
此节点通信半径内可能的状态0、1、2…
0---通信范围内无其它节点。
1---通信范围内有一个节点。
2---通信范围内有两个节点,一个停留,一个要离开。
k---通信范围内有k个节点,k-1个停留,一个要离开。
如图2所示,某节点通信半径内的节点变化是一个生灭过程,当进入到平稳状态后,
状态0处:
状态1处:
在状态k处:
当ρ<1时,有
ρ<1说明两个节点先后离开的时间小于两个先后到达的节点的时间。
通信范围内节点的平均数
通信范围内节点停留所花费时间的平均值:
从hello报文交换开始,o节点是核节点,经过0.17小时,通信范围内节点的平均数为6.6,小于邻域密度阈值8,o节点降为普通节点,簇在此处产生分裂,节点链m1、m2、...、m5形成一个簇,节点链n1、n2、...、n6形成另一个簇。
4)簇外节点采用prophet路由协议转发数据包,当数据包转发到簇内节点时,此簇内节点需要向簇内广播已收到数据包,簇内其它节点不再接收簇外的信息,返回步骤(2);
5)把基于密度聚类的容迟网络路由简称为dnrdc,利用网络仿真平台one,对dnrdc进行仿真,综合评测了dnrdc与epidemic、prophet三种路由算法在不同的缓存空间大小下的不同性能表现。仿真参数设置如表1:
表1仿真参数设置
如图4、5、6、7所示,在不同缓存空间下,epidemic将消息洪泛给每一个相遇的节点,它不可避免地生成大量的冗余消息副本,相比dnrdc与prophet,明显加剧了网络资源的消耗,当节点缓存空间受限时,epidemic会丢弃大量的消息副本,明显增加了网络负载率,消息投递率较低。prophet通过捕获节点间相遇的历史信息,根据消息预测值控制消息冗余,负载率有所下降,相比epidemic有更少的平均跳数,说明路由选择的准确性更高。dnrdc在网络拓扑中建立了基于密度聚类的簇,簇内节点不会产生消息副本,网络负载率大为降低,消息投递率得到提高,相比prophet平均跳数有所减少,说明簇内使用贪婪地理路由协议,可以选择最佳路由,dnrdc在消息传输的平均时延表现也最好。
本发明与现有技术相比,具有如下优点:
1)考虑在容迟网络中,存在部分拓扑节点密度较高,本发明采用基于密度聚类形成簇,与prophet路由协议相比,簇内节点不再计算投递预测值,控制开销大为减少。
2)采用基于两跳的hello报文交换,可以避免从源节点转发的拓扑发现报文在整个网络广播带来的过大控制开销。
3)由于prophet算法对消息副本数量有一定控制,网络中还是会产生很多消息副本,需要对缓存进行管理,但删包机制并不能有效地避免拥塞现象的产生。本发明在簇内采用贪婪地理路由协议,簇内节点不会产生消息副本,不用对缓存进行管理。
- 还没有人留言评论。精彩留言会获得点赞!