一种IEEE802.22WRAN动态信任管理模型及其与感知循环的结合方法与流程
本发明属于无线通信技术领域,尤其是一种IEEE 802.22 WRAN动态信任管理模型及其与感知循环的结合方法。
背景技术:
随着无线通信技术的发展,网络宽带不断提升。即使如此,也无法满足人们日益增长的无线接入需求。无线频谱已成为现代社会不可或缺的宝贵资源。然而另一方面,美国联邦通信委员会FCC(Federal Communication Commission)的研究表明频谱的利用情况极不均衡,一些非授权频段(如ISM频段)拥挤不堪,而有些授权频段(如广播电视TV频段)则经常空闲,频谱利用率极低,造成频谱资源的巨大浪费。2008年11月,FCC公布了修正案,规定“只要具备认知无线电功能,即使是其用途未获许可的无线终端,在不干扰现有用户的前提下,也能使用需要无线许可的现有无线频段”,为新的无线资源管理技术奠定了法律基础。2010 年11月第一个基于认知无线电的无线标准IEEE 802.22 WRAN(Wireless Region Area Network)发布,目的在于利用广播电视频段的空闲频谱资源提供广域无线接入网络服务。 IEEE 802.22 WRAN工作在54MHz~862MHz VHF/UHF(扩展频率范围47MHz~910MHz) 频段中的TV信道。它可自动检测到TV频段的空闲资源TVWS(TVWhite Space),并利用 TVWS进行通信,因此不会干扰到现有的TV广播站接收,即对原有授权用户没有影响。
IEEE 802.22 WRAN系统由SUBS(Secondary User Base Station)和CPE(Customer Primes Equipment)组成。每个CPE关联到某个SUBS,多个CPE间通过SUBS进行通信,CPE可以在不同的SUBS间切换。WRAN与主网络系统在时间上和空间上共存。主网络系统包含主基站PUBS(Primary User Base Station)和与其相关联的主用户PUs(Primary Usrs)。主网络有两类PUs,一类是电视,另一类是无线麦克风。WRAN系统与传统授权宽带无线网络不同的是,WRAN整合了感知模块检测PUs。当PUs空闲时,CPE才能使用这些空闲的频谱。因此,为了避免干扰PUs的使用,CPE需要实时的感知频谱检测出空闲的频谱,当检测到Pus 到来时,CPE需要空出正在使用的频谱。
WRAN系统要求CPE在不能干扰主用户的前提下使用空闲的频谱。为此,CPE需要进行频谱感知,把空闲的频谱清单发送给SUBS,SUBS根据这些空闲频谱清单做频谱决策,并根据需求和环境分配频谱。CPE遵循系统规则使用这些空闲的频谱资源,即当PUs召回频谱时,CPE需要空出正在使用的频谱或者降低功率和主用户共同使用,以避免干扰主用户。然而由于CPE的频谱感知需要花费时间和资源,并且空出正在使用的频谱对CPE的服务造成影响,因此有些CPE会不遵守系统规则,产生恶意行为,例如不做频谱感知,不空出被主用户召回的频段等。所以,如何建立基于CPE的行为的信任管理模型规范CPE的行为,以及如何设计高效的频谱融合策略对IEEE 802.22 WRAN系统稳定运行有着重要的意义。
信任的一个广为接受的定义是计算机科学家Gambetta于1990年给出的。信任被定义为个体评估另一个体或集体执行某一特定行为的特定主观可能性等级,评估发生在个体能够观察到该特定行为之前(或该特定行为独立于个体能够观察到该行为的能力)且该特定行为会影响评估者自身的行为。Gambetta认为信任不是一个门限点,而应该是一个概率分布的概念,用介于完全不信任(用0表示)和完全信任(用1表示)之间的值表示,且以不确定性为中点(用0.5表示)。
Josang等人引入证据空间和观念空间的概念描述和度量信任关系,并提供一套主观逻辑算子推导和综合计算信任度。证据空间由一系列主体产生的可观察到的事件组成,产生的事件被简单地划分为肯定事件和否定事件。Josang基于Beta分布函数描述二值事件后验概率的思想,提出一个由观察到的肯定事件数和否定事件数决定的概率确定性密度函数,并以此计算主体产生某个事件的概率的可信度。主观逻辑算子中主要的算子有合并、合意和推荐。其中合并用于不同信任内容的信任度综合计算。合意根据参与运算的观念信任度之间的关系分为独立观念间的合意、依赖观念间的合意和部分依赖观念间的合意。所谓观念依赖是指观念是否部分或全部由观察相同的事件所形成。合意主要用于对多个相同信任内容的信任度综合计算。推荐主要用于信任度的推导计算。
Josang模型对信任的定义较宽松,同时使用了证据空间中的肯定事件和否定事件对信任关系进行度量,模型没有明确区分直接信任和推荐信任,但提供了推荐算子用于信任度的推导。直接将Josang模型引入到IEEE 802.22 WRAN系统中,不能快速发现不遵守规则的CPE、有效管理CPE的行为以及克服内部攻击。
另外,针对IEEE 802.22 WRAN中的频谱感知算法主要采用能量检测技术、匹配滤波器检测技术以及循坏平稳特征检测方法等。尽管能量检测技术已经比较成熟应用于频谱感知技术,但是在动态环境中的不确定的干扰,能量检测技术可能不能提供可靠的数据。匹配滤波器检测技术要求首先知道授权用户信号的先验信息,如果信息不准确,则检测结果将受到很大的影响,它是一种相干检测,因此对相位的同步要求很高,计算量也很大,而且各类授权用户,认知无线电都要有一个专门的接收器,这就增加了系统的资源耗费量和复杂度。平稳特征检测方法计算的复杂度高,要求的观测时间较长。这些常见的频谱检测技术不能很好的适应于IEEE 802.22 WRAN的动态环境。
通过检索,尚未发现与本发明相关的专利公开文献。
技术实现要素:
本发明的目的在于克服原有技术的不足之处,提供一种IEEE 802.22 WRAN动态信任管理模型及其与感知循环的结合方法,该模型能够有效地管理CPE的行为,保障在频谱感知和频谱分配过程中数据交换可靠和安全,能减少由自私用户、有缺陷用户和恶意用户带来的巨大影响,以及DTM在网络攻击力度下,减少SUBS频谱决策错误率,为IEEE 802.22 WRAN 系统的稳定运行提供了安全保障。
本发明解决技术问题所采用的技术方案是:
一种IEEE 802.22 WRAN动态信任管理模型,所述模型包括信任值模块、直接信任值模块、推荐信任值模块、激励信任值值模块、主观逻辑模块、动态行为模块、权值计算模块和信任值更新模块,所述信任值模块与权值计算模块、信任值更新模块分别相连接设置,所述权值计算模块与直接信任值模块、推荐信任值模块、激励信任值值模块分别相连接设置,所述直接信任值模块与主观逻辑模块和动态行为模块分别相连接设置。
而且,所述信任值模块的信任值为CPE的信任值。
而且,所述直接信任模块的信任值的计算基于CPE的历史行为,所述推荐信任模块的信任值的计算基于信任传播和其他SUBS的推荐,所述激励信任值模块反应的是当PUs到来之时,CPE是否能空出频谱,当激励信任值小于设定的阈值,其最后信任值被设为零;
所述信任值模块的信任值由直接信任值模块、推荐信任值模块、激励信任值值模块的权值和来决定;如果CPE的信任值小于给定的值,那么CPE不能访问网络。
而且,所述CPE的信任值的计算包括直接信任值的计算、推荐信任值的计算、激励信任值的计算、各个信任值的权值计算以及信任值的更新。
而且,所述直接信任值的计算方法如下:
基于行为的信任:直接信任值的计算基于CPE以前的行为信息;
采用基于主观逻辑框架的信任模型:SUBS对每个CPE的直接行为做一个评估算法由 f(i,j),0≤f(i,j)≤1表示,其中i代表SUBSi,j代表CPEj;为了获得准确的CPE的信任值, DTM采用时间间隔方法分配每一个间隔行为不同的权值;到当前时间,有n个间隔 [t1,t2,....,tn],在第k个行为间隔,有个行为记录,SUBSi对CPEj的直接信任值如式1所示:
基于主观逻辑框架,在第tm个间隔内,f(i,j)的计算公式如式2所示:
其中r是总的成功证据,s是总的失败证据,即在第tm个间隔内,CPEj给SUBSi发送正确频谱占有情况的总次数为r,发送错误频谱占有情况的总次数为s;
一个用户的信任值是随着时间的变化而变化的,所以CPE的信任值是动态的,在时间t 的信任与在时间t’的信任值会存在不一样的可能性;分配给最新的行为和以前的历史的权值决定信任建立的速度;
时间衰退因子:时间衰减因子fk由第k个间隔行为与最近的间隔行为相比较决定的,其计算公式如式3所示:
其中,基础系数表示衰减因子,越小,fk衰减的越快,越大,fk衰减的越慢;
利用时间衰减函数,所述直接信任值的计算如式4所示:
式4中,直接信任值表示在不同的行为间隔,SUBS对所有的CPE的行为评估的权值平均;更高的信任值表明CPE以前的频谱感知信息对SUBS做出正确频谱决策和分配更有帮助;在网络部署的初始阶段,假设没有恶意的用户有目标的发送错误的频谱感知数据;CPE的初始化信任值被SUBS设置成0.5;在网络运行一段时间,恶意的用户都会被发现;
所述推荐信任值的计算方法如下:
推荐信任也叫间接信任,是直接信任的一种特殊情况;当CPE进入到一个WRAN中, SUBS认证CPE;如果CPE被其他SUBSs认证过,那么当前的SUBS请求CPE曾经呆过的 SUBSs,获得CPE的信任值;由于信任是实时的,所以当前SUBS只请求CPE呆过的最后一个SUBS,其推荐信任值的计算如式5:
这个推荐值设置成CPE的初始化信任值,如果CPE从来没有访问过其他任何的WRAN,那么其初始化的信任值被设置成0.5;
所述激励信任值的计算方法如下:
激励信任值指激励CPE遵循FCC的规则,激励信任值惩罚那些没有遵循FCC规则的用户,激励信任值的计算如式6所示:
IFij=1-φ(n) (6)
其中φ(n)表示惩罚因子,表示CPE没有遵循FCC的规则;在当前行为间隔时间T内,主用户返回网络的总次数为NT,CPE没有遵循FCC规则的总次数为nT,惩罚因子φ(n)的计算公式如式7所示:
γ是控制参数,γ的值越小,φ(n)衰减的越快,γ的值越大,φ(n)衰减的越慢;
激励信任值在最后信任值的计算有最高的权限,即如果CPE的激励信任值小于阈值,那么CPE的最后信任值被设置为0;
所述权值的计算方法如下:
直接信任值、推荐信任值和激励信任值的权值分别是α、β和χ,其计算分别如式8,式 9,式10所示:
其中cf表示自信因子,影响直接信任值的权值,cf越高,直接信任值影响最后信任值越大;在当前间隔时间T内,SUBS请求频谱感知的总次数为MT,CPE发送错误数据的总次数为mT;a>0是一个规范参数,a越高,cf趋于1的速度越快,λ是衰减影子,λ越大,cf衰减越快,自信因子cf的计算如式11所示:
在式8,9,10中,ff代表反馈因子,其影响推荐信任值的权值,ff越高,推荐信任值影响最后信任值越大;在当前间隔时间T内,CPE向其他SUBS通信过的总次数为WT,其他 SUBS不相信CPE的总次数为wT;b>0是一个规范参数,b越高,ff趋于1的速度越快,κ越大,ff衰减越快,反馈因子ff的计算如式12所示:
在式8、式9和式10中,if代表激励因子,其影响激励信任值的权值,if越高,激励信任值影响最后信任值的计算越大;激励因子if的计算如式13所示:
if=IFij (13)
到当前间隔时间T内,最后信任值的计算如式14:
所述信任值更新模块的更新信任值的计算方法如下:
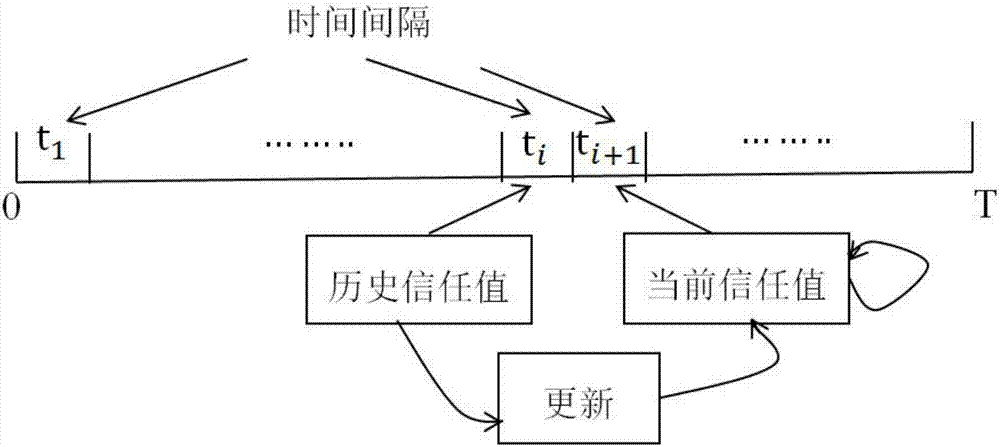
由于TVWS中WRAN的动态特性,比如当主用户到来时,CPE空出正在使用的频谱, CPE的信任值应该周期地更新。计算CPE的当前信任值即在下一个时间段ti+1的信任值考虑 CPE的历史信任值即上一个时间段ti的信任值,如图2所示。
让TV(ti)表示CPE的在时间间隔ti末的历史信任值,TV(ti+1)表示CPE的在一个时间间隔 ti+1的当前信任值,那么CPE如式15更新信任值:
其中和表示权值,并且引入时间衰减因子η作为信任值衰减计算如式16所示:
其中ti+1-ti表示计算信任值TV(ti+1)和TV(ti)的时间间隔;η越小,衰减的越快,当η趋向于0时,过去的历史行为完全被忽略,当η趋向于1时,最老的历史行为被永远记住;信任值的更新引入时间因子满足更长时间的历史信任值应该权值比最新的信任值小。
而且,所述直接信任值的计算中分配给最近的行为更高的权重。
如上所述的IEEE802.22 WRAN动态信任管理模型与感知循环的结合方法,步骤如下:
所述感知循环是对无线环境的频谱感知、频谱感知、频谱分析与频谱判决之间的循环,信任与感知循环有三个交换:
(1)信任与感知数据汇集过程的交换:SUBS从可靠的CPE搜集频谱感知数据,并做最后的频谱感知决策,把结果广播给所有的CPE;SUBS通过比较CPE发送的感知数据与最终判决的结果判断CPE的感知结果是否正确,这些构成证据空间e1;如果比较结果是相同的,则 e1被设置成为1,否则被设置成为0;
(2)信任与频谱决策过程的交互:在每个CPE接收到关于空闲频谱的清单之后,CPE请求使用合适的信道;SUBS接收这到这些请求后,通过需求考虑全局分配,优先满足可靠用户的请求,即信任值越大,可能得到的想要的频谱几率更大;
(3)信任与频谱访问的交互:CPE在获得请求的信道之后,CPE尝试访问信道,如果正好与主用户发生冲突,CPE给SUBS发送这个冲突消息,SUBS判断是否是一个冲突攻击,如果是,把证据空间的e2设置为0,证据空间e1等于1被设置为0;当主用户返回时,如果被SUBS监测到CPE仍然正常使用这个信道,SUBS减少CPE的信任值,并可能会撤销其频谱共享的权利。
本发明取得的优点和积极效果是:
1、本发明IEEE 802.22 WRAN中的动态信任管理模型(DTM)能够有效地管理CPE的行为,保障在频谱感知和频谱分配过程中数据交换可靠和安全,能减少由自私用户、有缺陷用户和恶意用户带来的巨大影响,以及DTM在网络攻击力度下,减少SUBS频谱决策错误率,为IEEE 802.22 WRAN系统的稳定运行提供了安全保障。
2、本发明模型能有效管理和规范CPE的行为,使其遵守系统规则,正确的感应频谱、发送正确的频谱感知数据、空出PUs召回的频谱;能够消除恶意用户对系统带来的负面影响;该模型提出的基于信任的频谱融合策略,在存在攻击的情况下,能有效地减少SUBS的频谱决策错误次数。
3、本发明基于CPE的行为,使用主观逻辑计算CPE的信任值,建立动态信任管理模型 DTM(Dynamic Trust Model)以管理CPE的行为,提出基于信任的频谱融合决策帮助SUBS 频谱决策;如果一个CPE的信任值小于给定的阈值,那么SUBS忽略CPE的感知数据并且不给CPE分配频谱资源;该信任管理模型减少用户恶意行为的影响并激励CPE参与到积极的行为;CPE的不信任主要来自CPE在频谱资源分配之前没有报告正确的频谱感知数据,以及在频谱资源分配之后没有空出被PUs召回的频谱,基于信任的频谱融合策略的原则是更高的信任值帮助CPE竞争到信道使用的优先权。
附图说明
图1为本发明模型的结构连接示意图;
图2为本发明中信任值更新过程图;
图3为本发明信任管理模型与感知循环的关系图。
具体实施方式
为能进一步了解本发明的内容、特点及功效,兹例举以下实施例,并配合附图详细说明如下。需要说明的是,本实施例是描述性的,不是限定性的,不能由此限定本发明的保护范围。
实施例1
一种IEEE 802.22 WRAN动态信任管理模型(该模型可以简称为DTM),所述模型包括信任值模块、直接信任值模块、推荐信任值模块、激励信任值值模块、主观逻辑模块、动态行为模块、权值计算模块和信任值更新模块,所述信任值模块与权值计算模块、信任值更新模块分别相连接设置,所述权值计算模块与直接信任值模块、推荐信任值模块、激励信任值值模块分别相连接设置,所述直接信任值模块与主观逻辑模块和动态行为模块分别相连接设置。
较优地,所述信任值模块的信任值为CPE的信任值。
较优地,所述直接信任模块的信任值的计算基于CPE的历史行为,所述推荐信任模块的信任值的计算基于信任传播和其他SUBS的推荐,所述激励信任值模块反应的是当PUs到来之时,CPE是否能空出频谱,当激励信任值小于设定的阈值,其最后信任值被设为零;
所述信任值模块的信任值由直接信任值模块、推荐信任值模块、激励信任值值模块的权值和来决定;如果CPE的信任值小于给定的值,那么CPE不能访问网络。
较优地,所述CPE的信任值的计算包括直接信任值的计算、推荐信任值的计算、激励信任值的计算、各个信任值的权值计算以及信任值的更新。
较优地,所述直接信任值的计算方法如下:
基于行为的信任:直接信任值的计算基于CPE以前的行为信息;
采用基于主观逻辑框架的信任模型:SUBS对每个CPE的直接行为做一个评估算法由 f(i,j),0≤f(i,j)≤1表示,其中i代表SUBSi,j代表CPEj;为了获得准确的CPE的信任值, DTM采用时间间隔方法分配每一个间隔行为不同的权值;到当前时间,有n个间隔 [t1,t2,....,tn],在第k个行为间隔,有个行为记录,SUBSi对CPEj的直接信任值如式1所示:
基于主观逻辑框架,在第tm个间隔内,f(i,j)的计算公式如式2所示:
其中r是总的成功证据,s是总的失败证据,即在第tm个间隔内,CPEj给SUBSi发送正确频谱占有情况的总次数为r,发送错误频谱占有情况的总次数为s;
一个用户的信任值是随着时间的变化而变化的,所以CPE的信任值是动态的,在时间t 的信任与在时间t’的信任值会存在不一样的可能性;分配给最新的行为和以前的历史的权值决定信任建立的速度;
时间衰退因子:时间衰减因子fk由第k个间隔行为与最近的间隔行为相比较决定的,其计算公式如式3所示:
其中,基础系数表示衰减因子,越小,fk衰减的越快,越大,fk衰减的越慢;
利用时间衰减函数,所述直接信任值的计算如式4所示:
式4中,直接信任值表示在不同的行为间隔,SUBS对所有的CPE的行为评估的权值平均;更高的信任值表明CPE以前的频谱感知信息对SUBS做出正确频谱决策和分配更有帮助;在网络部署的初始阶段,假设没有恶意的用户有目标的发送错误的频谱感知数据;CPE的初始化信任值被SUBS设置成0.5;在网络运行一段时间,恶意的用户都会被发现;
所述推荐信任值的计算方法如下:
推荐信任也叫间接信任,是直接信任的一种特殊情况;当CPE进入到一个WRAN中, SUBS认证CPE;如果CPE被其他SUBSs认证过,那么当前的SUBS请求CPE曾经呆过的 SUBSs,获得CPE的信任值;由于信任是实时的,所以当前SUBS只请求CPE呆过的最后一个SUBS,其推荐信任值的计算如式5:
这个推荐值设置成CPE的初始化信任值,如果CPE从来没有访问过其他任何的WRAN,那么其初始化的信任值被设置成0.5;
所述激励信任值的计算方法如下:
激励信任值指激励CPE遵循FCC的规则,激励信任值惩罚那些没有遵循FCC规则的用户,激励信任值的计算如式6所示:
IFij=1-φ(n)(6)
其中φ(n)表示惩罚因子,表示CPE没有遵循FCC的规则;在当前行为间隔时间T内,主用户返回网络的总次数为NT,CPE没有遵循FCC规则的总次数为nT,惩罚因子φ(n)的计算公式如式7所示:
γ是控制参数,γ的值越小,φ(n)衰减的越快,γ的值越大,φ(n)衰减的越慢;
激励信任值在最后信任值的计算有最高的权限,即如果CPE的激励信任值小于阈值,那么CPE的最后信任值被设置为0;
所述权值的计算方法如下:
直接信任值、推荐信任值和激励信任值的权值分别是α、β和χ,其计算分别如式8,式 9,式10所示:
其中cf表示自信因子,影响直接信任值的权值,cf越高,直接信任值影响最后信任值越大;在当前间隔时间T内,SUBS请求频谱感知的总次数为MT,CPE发送错误数据的总次数为mT;a>0是一个规范参数,a越高,cf趋于1的速度越快,λ是衰减影子,λ越大,cf衰减越快,自信因子cf的计算如式11所示:
在式8,9,10中,ff代表反馈因子,其影响推荐信任值的权值,ff越高,推荐信任值影响最后信任值越大;在当前间隔时间T内,CPE向其他SUBS通信过的总次数为WT,其他 SUBS不相信CPE的总次数为wT;b>0是一个规范参数,b越高,ff趋于1的速度越快,κ越大,ff衰减越快,反馈因子ff的计算如式12所示:
在式8、式9和式10中,if代表激励因子,其影响激励信任值的权值,if越高,激励信任值影响最后信任值的计算越大;激励因子if的计算如式13所示:
if=IFij (13)
到当前间隔时间T内,最后信任值的计算如式14:
所述信任值更新模块的更新信任值的计算方法如下:
由于TVWS中WRAN的动态特性,比如当主用户到来时,CPE空出正在使用的频谱, CPE的信任值应该周期地更新。计算CPE的当前信任值即在下一个时间段ti+1的信任值考虑 CPE的历史信任值即上一个时间段ti的信任值,如图2所示。
让TV(ti)表示CPE的在时间间隔ti末的历史信任值,TV(ti+1)表示CPE的在一个时间间隔 ti+1的当前信任值,那么CPE如式15更新信任值:
其中和表示权值,并且引入时间衰减因子η作为信任值衰减计算如式16所示:
其中ti+1-ti表示计算信任值TV(ti+1)和TV(ti)的时间间隔;η越小,衰减的越快,当η趋向于0时,过去的历史行为完全被忽略,当η趋向于1时,最老的历史行为被永远记住;信任值的更新引入时间因子满足更长时间的历史信任值应该权值比最新的信任值小。
较优地,所述直接信任值的计算中分配给最近的行为更高的权重。
如上所述的IEEE802.22 WRAN动态信任管理模型与感知循环的结合方法,步骤如下:
所述感知循环是对无线环境的频谱感知、频谱感知、频谱分析与频谱判决之间的循环,信任与感知循环有三个交换:
(1)信任与感知数据汇集过程的交换:SUBS从可靠的CPE搜集频谱感知数据,并做最后的频谱感知决策,把结果广播给所有的CPE;SUBS通过比较CPE发送的感知数据与最终判决的结果判断CPE的感知结果是否正确,这些构成证据空间e1;如果比较结果是相同的,则 e1被设置成为1,否则被设置成为0;
(2)信任与频谱决策过程的交互:在每个CPE接收到关于空闲频谱的清单之后,CPE请求使用合适的信道;SUBS接收这到这些请求后,通过需求考虑全局分配,优先满足可靠用户的请求,即信任值越大,可能得到的想要的频谱几率更大;
(3)信任与频谱访问的交互:CPE在获得请求的信道之后,CPE尝试访问信道,如果正好与主用户发生冲突,CPE给SUBS发送这个冲突消息,SUBS判断是否是一个冲突攻击,如果是,把证据空间的e2设置为0,证据空间e1等于1被设置为0;当主用户返回时,如果被SUBS监测到CPE仍然正常使用这个信道,SUBS减少CPE的信任值,并可能会撤销其频谱共享的权利。
实施例2
一种IEEE 802.22 WRAN动态信任管理模型,如图1所示,所述模型包括信任值模块、直接信任值模块、推荐信任值模块、激励信任值值模块、主观逻辑模块、动态行为模块、权值计算模块和信任值更新模块,所述信任值模块与权值计算模块、信任值更新模块分别相连接设置,所述权值计算模块与直接信任值模块、推荐信任值模块、激励信任值值模块分别相连接设置,所述直接信任值模块与主观逻辑模块和动态行为模块分别相连接设置。
在本实施例中,所述信任值模块的信任值为CPE的信任值。
在本实施例中,所述直接信任模块的信任值的计算基于CPE的历史行为,所述推荐信任模块的信任值的计算基于信任传播和其他SUBS的推荐,所述激励信任值模块反应的是当PUs 到来之时,CPE是否能空出频谱,当激励信任值小于设定的阈值,其最后信任值被设为零;
所述信任值模块的信任值由直接信任值模块、推荐信任值模块、激励信任值值模块的权值和来决定;如果CPE的信任值小于给定的值,那么CPE不能访问网络。
具体地,DTM中信任值的层级模型如图1所示,一个CPE的信任值包含直接信任模块、推荐信任模块和激励信任值模块。在直接信任模块中,信任值的计算基于CPE的历史行为,比如正确感知频谱信息,发送正确的频谱数据等。信任值是随着时间的变化而变化的。即在时间t的信任值和在另外一个时间t’的信任值有可能变化很大。推荐信任值的计算基于信任传播和其他SUBS的推荐。SUBS请求其他SUBS对CPE的信任值。由于信任值是动态的,所以只请求CPE的最后一个SUBS。在IEEE 802.22 WRAN中,FCC规则即不能干扰PUs是重要的,所以激励信任值模块反应的是当PUs到来之时,CPE是否能空出频谱,当激励信任值小于设定的阈值,其最后信任值被设为零。不同的信任模块有不同的权值,权值是由权值函数决定的。最后的信任值由三个信任模块的权值和来决定。如果CPE的信任值小于给定的值,那么CPE不能访问网络。
DTM中信任值的计算
CPE的信任值的计算,包括直接信任值的计算、推荐信任值的计算、激励信任值的计算、各个信任值的权值计算以及信任值的更新。
(1)直接信任值的计算
基于行为的信任:直接信任值的计算基于CPE以前的行为信息,行为包括CPE是否正确发送SUBS的感知频谱数据,这对SUBS网络频谱决策是否正确很重要。然而,由于信道衰减或Byzantine攻击,SUBS可能获得错误的频谱信息。两个原因导致Byzantine攻击,一个是CPE自私地或恶意地发送错误频谱数据,另外一个由于CPE的故障或者信道衰减,CPE 给SUBS发送正确的频谱数据失败。因此在WRAN中,管理CPE的行为考虑不确定性。为了处理这个不确定性,采用基于主观逻辑框架的信任模型。SUBS对每个CPE的直接行为做一个评估算法由f(i,j),0≤f(i,j)≤1表示,其中i代表SUBSi,j代表CPEj。为了获得准确的CPE的信任值,DTM采用时间间隔方法分配每一个间隔行为不同的权值。到当前时间,有n个间隔[t1,t2,....,tn],在第k个行为间隔,有Ntk个行为记录,SUBSi对CPEj的直接信任值如式1所示:
基于主观逻辑框架,在第tm个间隔内,f(i,j)的计算公式如式2所示:
其中r是总的成功证据,s是总的失败证据,即在第tm个间隔内,CPEj给SUBSi发送正确频谱占有情况的总次数为r,发送错误频谱占有情况的总次数为s。
一个用户的信任值是随着时间的变化而变化的,所以CPE的信任值是动态的,在时间t 的信任可能跟在时间t’的信任值不一样。分配给最新的行为和以前的历史的权值决定信任建立的速度。例如,如果最新的行为被分配到更高的权值,那么有了一些坏的行为之后,用户的信任值快速下降。信任是容易失去,很难获得。心理研究结果和ebay反馈机制的经验研究成果给的建议,在DTM中,分配给最近的行为更高的权重。
时间衰退因子:时间衰减因子fk由第k个间隔行为与最近的间隔行为相比较决定的,其计算公式如式3所示:
其中基础系数表示衰减因子,越小,fk衰减的越快,越大,fk衰减的越慢。
利用时间衰减函数,DTM的直接信任值的计算如式4所示:
式4中,直接信任值表示在不同的行为间隔,SUBS对所有的CPE的行为评估的权值平均。更高的信任值表明CPE以前的频谱感知信息对SUBS做出正确频谱决策和分配更有帮助。在网络部署的初始阶段,假设没有恶意的用户有目标的发送错误的频谱感知数据。CPE的初始化信任值被SUBS设置成0.5。在网络运行一段时间,恶意的用户都会被发现。
(2)推荐信任值的计算
推荐信任也叫间接信任,是直接信任的一种特殊情况。当CPE进入到一个WRAN中, SUBS认证CPE。如果CPE被其他SUBSs认证过,那么当前的SUBS请求CPE曾经呆过的 SUBSs,获得CPE的信任值。由于信任是实时的,所以当前SUBS只请求CPE呆过的最后一个SUBS。其推荐信任值的计算如式5:
这个推荐值设置成CPE的初始化信任值。如果CPE从来没有访问过其他任何的WRAN,那么其初始化的信任值被设置成0.5。
(3)激励信任值
激励信任值指激励CPE遵循FCC的规则。IEEE 802.22 WRAN中FCC的规则禁止干扰主系统的使用是至关重要的。当PUs收回CPE正在使用的频谱时,CPE必须空出频谱。而恶意的CPE可能不会空出正在使用的频谱,这会对主系统造成很严重的影响。所以激励信任值惩罚那些没有遵循FCC规则的用户。激励信任值的计算如式6所示:
IFij=1-φ(n) (6)
其中φ(n)表示惩罚因子,表示CPE没有遵循FCC的规则。在当前行为间隔时间T内,主用户返回网络的总次数为NT,CPE没有遵循FCC规则的总次数为nT,惩罚因子φ(n)的计算公式如式7所示:
γ是控制参数,γ的值越小,φ(n)衰减的越快,γ的值越大,φ(n)衰减的越慢。值得注意的是,激励信任值在最后信任值的计算有最高的权限,即如果CPE的激励信任值小于阈值,比如0.5,那么CPE的最后信任值被设置为0。
(4)权值计算
直接信任值,推荐信任值和激励信任值的权值分别是α、β和χ,其计算分别如式8,式 9,式10所示:
其中cf表示自信因子,影响直接信任值的权值,cf越高,直接信任值影响最后信任值越大。在当前间隔时间T内,SUBS请求频谱感知的总次数为MT,CPE发送错误数据的总次数为mT。a>0是一个规范参数,a越高,cf趋于1的速度越快,λ是衰减影子,λ越大,cf衰减越快,自信因子cf的计算如式11所示:
在式8,9,10中,ff代表反馈因子,其影响推荐信任值的权值,ff越高,推荐信任值影响最后信任值越大。在当前间隔时间T内,CPE向其他SUBS通信过的总次数为WT,其他 SUBS不相信CPE的总次数为wT。b>0是一个规范参数,b越高,ff趋于1的速度越快,κ越大,ff衰减越快,反馈因子ff的计算如式12所示:
在式8、式9和式10中,if代表激励因子,其影响激励信任值的权值,if越高,激励信任值影响最后信任值的计算越大。激励因子if的计算如式13所示:
if=IFij (13)
到当前间隔时间T内,最后信任值的计算如式14:
(5)信任值更新
由于TVWS中WRAN的动态特性,比如当主用户到来时,CPE空出正在使用的频谱, CPE的信任值应该周期地更新。计算CPE的当前信任值即在下一个时间段ti+1的信任值考虑 CPE的历史信任值即上一个时间段ti的信任值,如图2所示。
让TV(ti)表示CPE的在时间间隔ti末的历史信任值,TV(ti+1)表示CPE的在一个时间间隔ti+1的当前信任值,那么CPE如式15更新信任值:
其中和表示权值,并且引入时间衰减因子η作为信任值衰减计算如式16所示。
其中ti+1-ti表示计算信任值TV(ti+1)和TV(ti)的时间间隔。η越小,衰减的越快,当η趋向于0时,过去的历史行为完全被忽略,当η趋向于1时,最老的历史行为被永远记住。信任
值的更新引入时间因子满足更长时间的历史信任值应该权值比最新的信任值小。
图3描述的是DTM信任管理模型与感知循环的结合。感知循环是对无线环境的频谱感知、频谱感知、频谱分析与频谱判决之间的循环。信任与感知循环有三个交换。
(1)信任与感知数据汇集过程的交换:SUBS从可靠的CPE搜集频谱感知数据,并做最后的频谱感知决策,把结果广播给所有的CPE。SUBS通过比较CPE发送的感知数据与最终判决的结果判断CPE的感知结果是否正确,这些构成证据空间e1。如果比较结果是相同的,则 e1被设置成为1,否则被设置成为0。
(2)信任与频谱决策过程的交互:在每个CPE接收到关于空闲频谱的清单之后,CPE请求使用合适的信道。SUBS接收这到这些请求后,通过需求考虑全局分配,优先满足可靠用户的请求,即信任值越大,可能得到的想要的频谱几率更大。
(3)信任与频谱访问的交互:CPE在获得请求的信道之后,CPE尝试访问信道。如果正好与主用户发生冲突,CPE给SUBS发送这个冲突消息。SUBS判断是否是一个冲突攻击。如果是,把证据空间的e2设置为0,证据空间e1等于1被设置为0。当主用户返回时,如果被 SUBS监测到CPE仍然正常使用这个信道,SUBS减少CPE的信任值,并可能会撤销其频谱共享的权利。
CPE的信任值映射CPE的频谱感知数据的精确性以及遵循FCC规则的程度。以基于信任值的频谱融合决策能够推断每个CPE发送频谱感知数据的可靠性以及当PUs召回频谱时CPE 是否空出频谱,所以能够减少CPE错误的信息以及恶意的行为对WRAN系统的影响。基于信任值的频谱融合决策中,根据CPE的信任值分配给CPE不同的融合权值。例如,把信任值分为三个区间,包括可靠区间,其信任值范围为(0.6,1];不确定区间,其信任值范围为 (0.4,0.6];以及丢弃区间,其信任值范围为[0,0.4]。为了加强好的CPE的影响并减少恶意 CPE的影响,可靠区间的CPE的融合权值被设置成为1,不确定区间的CPE的融合权值被设置成相对应的信任值,而丢弃区间的CPE的信息被直接丢弃。最后频谱的判决基于在“占有”信任值和“空闲”信任值之间的较大值决定。
WRAN中与主用户频谱共享的前提是CPE不能干扰主用户,CPE必须提供准确的频谱感知数据,这个过程减少CPE的传输时间以及消耗能量。有些CPE可能不情愿参与到频谱感知活动中。再者,频繁的频谱切换行为也会影响CPE的服务质量,这可能会导致CPE不情愿空出正在使用的频谱。所以,需要一个激励以及惩罚的方法约束CPE的行为。因此,提出了一个基于信任值的DTM的资源分配方法,约束和激励CPE。当许多CPE请求使用同一个信道时,信道分配的原则是更高的信任值能够帮助CPE竞争到信道使用的优先权。
- 还没有人留言评论。精彩留言会获得点赞!