一种停车场智能语音播报系统的制作方法
本发明涉及语音播报领域,特别是涉及一种停车场语音播报系统。
背景技术:
随着经济的发展,科技的进步,物联网正逐渐进入人们的生活,走向社会。目前,语音播报系统广泛应用于智能化设备中,通过语音播报可以友好地与使用者进行人机交互。市面上一般语音系统模块一般为两种,一种是播报固定的人声和语音,这种成本虽然低,但是不能灵活修改播报内容,且播报内容相当有限。另一种是可以输入任意语句进行语音播报的片上系统,这种片上系统在本身处理器外需要多加该处理芯片,这样不仅增加系统结构的尺寸,而且片上系统造价较高从而导致整个设计成本增加。
技术实现要素:
为了解决上述现有技术的缺陷和不足,本发明提供了一种无需外加芯片就可以播报任意语句的智能播报的语音系统。
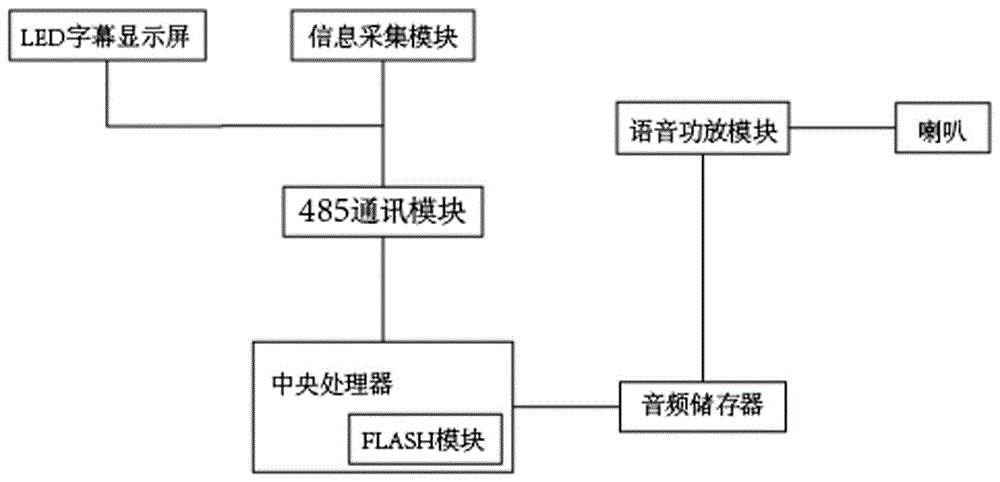
本发明所采用的技术方案是:一种停车场智能语音播报系统,包括led字幕显示屏、信息采集模块、中央处理器、485通讯模块、音频存储器、语音功放模块、喇叭,所述中央处理器包括flash模块。所述led字幕显示屏分别与信息采集模块、中央处理器通过485通讯模块连接进行控制和数据传输,信息采集通过485通讯模块与中央处理器连接进行数据传输,所述音频存储器与所述中央处理器连接,语音功放模块与中央处理器的dac输出接口连接进行数据的传输,所述中央处理器用于汉字发音处理。
所述音频存储器用于存储已编译好的固定播报内容。
所述中央处理器的型号为st意法半导体生产的stm32f105系列芯片。
所述flash模块,flash模块包含有汉字语音库,汉字语音库包含有一千四百四十个发音,所述一千四百四十个发音是由gb2312编码内六千多个字整合而成,汉字语音库通过查表的方式进行汉字发音搜索,使flash模块中的汉字语音库的存储空间节省了6倍。
所述汉字发音处理包括读取语音库、多音字处理、播报语境处理、读取音频、字与字之间的衔接处理。
所述多音字处理的处理方法包括以下步骤:
第一步:通过中央处理器遍历信息采集模块中需要播报的汉字的gb2312编码,并通过汉字发音库中查表判断每个汉字是否为多音字。
第二步:需要播报的汉字中包含有多音字,则通过遍历多音字的每个发音与其前后汉字的组合。
第三步:将组合融于剩下所需要播报的汉字中,识别该组合与剩下所需要播报的汉字是否吻合,当该组合与剩下所需要播报的汉字吻合,则该组合的发音为多音字的正确发音。
第四步:将确定好正确发音的多音字和剩下所需要播报的汉字根据汉字的gb2312码从flash中查表获取发音数据的位置。
所述播报语境处理主要是针对数字是否连读和数字后面是否带计量单位;所述播报语境处理的处理方法包括以下步骤:
第一步:识别需要播报的内容是否包含有数字。
第二步:提取需要播报的内容中出现数字前后的内容,判断数字前后是否带计量单位。
第三步:一是数字前后出现了计量单位,则对数字采用取整取余的方法进行拆分处理,拆分后根据数字位数不同,分别在每个数字后面分别加入计量单位,播报出带有计量单位的语音。二是数字前后没有出现计量单位,则按数字顺序直接播报。如需要播报的内容为“拨打电话123”和“123个人”,则两例子将分别播报为“拨打电话一二三”和“一百二十三个人”。
所述读取音频的方法包括以下步骤:
第一步:通过flash模块中查表将需要播报的内容的gb2312通过公式((msb-176)*94+(lsb-161)+62)<<2转换为从1开始的十进制数。
第二步:通过将第一步得到的十进制数在flash模块中进行查表获取该十进制数的音频存储地址。
第三步:中央处理器读取flash模块上的十进制数的音频数据,并进入字与字之间的衔接处理阶段。
所述字与字之间的衔接处理的处理方法:以傅里叶变换思想为前提,根据每个音频在开始和结尾阶段均有增益和衰减过程,中央处理器根据音频的采样率和采样精度,将每一汉字正确发音的音频末尾衰减至衰减系数值0.717以下数据与下一个汉字正确发音的音频起始增益系数值0.283以下的数据根据其采样率和采样精度,将同一时域内两个需要合成的数据进行运算合成,使得每个汉字前后的音频衔接成一句流利的话。
所述汉字发音处理完成的音频数据通过中央处理器的dac输出接口输出至语音功放模块进行功率放大,再输出至喇叭进行播报。
本发明采用的中央处理器的型号为st意法半导体生产的stm32f105系列芯片。该芯片具有dac音频输出,可直接与语音功放模块连接,无需再外加音频芯片,且芯片并具有128k可编程rom和20k数据缓存ram,保证具有需要播报的内容的音频在自身运行处理、保证音质和智能播放的同时极大节省系统结构空间和将低了成本。
附图说明
图1为本发明的系统图。图2为本发明的语音处理前的波形图。
图3为本发明的语音处理后的波形图。
图4为本发明的中央处理器的电路图。
图5为本发明的功放语音模块的电路图。
图6为本发明的485通讯的电路图。
具体实施方式
下面结合附图和具体实施例对本发明作进一步的说明。
请参照附图1-6,一种停车场智能语音播报系统,包括led字幕显示屏、信息采集模块、中央处理器、485通讯模块、音频存储器、语音功放模块、喇叭,所述中央处理器包括flash模块;所述led字幕显示屏分别与信息采集模块、中央处理器通过485通讯模块连接进行控制和数据传输,信息采集通过485通讯模块与中央处理器连接进行数据传输,所述音频存储器与所述中央处理器连接,语音功放模块与中央处理器的dac输出接口连接进行数据的传输,所述中央处理器用于汉字发音处理。
所述flash模块,flash模块包含有汉字语音库,汉字语音库包含有一千四百四十个发音,所述一千四百四十个发音是由gb2312编码内六千多个字整合而成,汉字语音库通过查表的方式进行汉字发音搜索,使flash模块中的汉字语音库的存储空间节省了6倍。
所述汉字发音处理包括读取语音库、多音字处理、播报语境处理、读取音频、字与字之间的衔接处理。
所述多音字处理的处理方法包括以下步骤:
第一步:通过中央处理器遍历信息采集模块中需要播报的汉字的gb2312编码,并通过汉字发音库中查表判断每个汉字是否为多音字;
第二步:需要播报的汉字中包含有多音字,则通过遍历多音字的每个发音与其前后汉字的组合;
第三步:将组合融于剩下所需要播报的汉字中,识别该组合与剩下所需要播报的汉字是否吻合,当该组合与剩下所需要播报的汉字吻合,则该组合的发音为多音字的正确发音;
第四步:将确定好正确发音的多音字和剩下所需要播报的汉字根据汉字的gb2312码从flash中查表获取发音数据的位置。
所述播报语境处理主要针对的是数字是否连读和数字后面是否带计量单位;所述播报语境处理的处理方法包括以下步骤:
第一步:识别需要播报的内容是否包含有数字;
第二步:提取需要播报的内容中出现数字前后的内容,判断数字前后是否带计量单位;
第三步:一是数字前后出现了计量单位,则对数字采用取整取余的方法进行拆分处理,拆分后根据数字位数不同,分别在每个数字后面分别加入适用的词,播报出带有计量单位的语音;二是数字前后没有出现计量单位,则按数字顺序直接播报。如需要播报的内容为“拨打电话123”和“123个人”,则两例子将分别播报为“拨打电话一二三”和“一百二十三个人”
所述读取音频的方法包括以下步骤:
第一步:通过flash模块中查表将需要播报的内容的gb2312通过公式((msb-176)*94+(lsb-161)+62)<<2转换为从1开始的十进制数;
第二步:通过将第一步得到的十进制数在flash模块中进行查表获取该十进制数的音频存储地址;
第三步:中央处理器读取flash模块上的十进制数的音频数据,并进入字与字之间的衔接处理阶段。
所述字与字之间的衔接处理的处理方法:以傅里叶变换思想为前提,根据每个音频在开始和结尾阶段均有增益和衰减过程,中央处理器根据音频的采样率和采样精度,将每一汉字正确发音的音频末尾衰减至衰减系数值0.717以下数据与下一个汉字正确发音的音频起始增益系数值0.283以下的数据根据其采样率和采样精度,将同一时域内两个需要合成的数据进行运算合成,使得每个汉字前后的音频衔接成一句流利的话。
所述音频存储器用于存储已编译好的固定播报内容。
所述中央处理器的型号为st意法半导体生产的stm32f105系列芯片。
所述汉字发音处理完成的音频数据通过中央处理器的dac输出接口输出至语音功放模块进行功率放大,再输出至喇叭进行播报。
本发明采用的中央处理器的型号为st意法半导体生产的stm32f105系列芯片。该芯片具有dac音频输出,可直接与语音功放模块连接,无需再外加音频芯片,且芯片并具有128k可编程rom和20k数据缓存ram,保证具有需要播报的内容的音频在自身运行处理、保证音质和智能播放的同时极大节省系统结构空间和将低了成本。
本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。而对于属于本发明的实质精神所引伸出的显而易见的变化或变动仍属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!