通过使用音频频谱图上的结构张量来重构相位信息的编码的制作方法
本发明涉及音频信号处理,具体地,涉及使用频谱图上的结构张量进行谐波-冲击-残差(harmonic-percussive-residual)声音分离的装置和方法。
背景技术:
能够将声音分离成其谐波分量和冲击分量是许多应用的有效预处理步骤。
尽管“谐波-冲击(-残差)分离”是一个常用术语,但它具有误导性,因为它意味着谐波结构的正弦曲线的频率为基频的整数倍。尽管正确的术语应该是“音调-打击-(残差)分离”,但为了便于理解,下面使用术语“谐波”而不是“音调”。
例如,使用音乐录音的分离的冲击分量可以导致节拍跟踪(参见[1])、节奏分析和节奏乐器的转录的质量改善。分离的谐波分量适用于音高乐器和和弦检测的转录(参见[3])。此外,谐波-冲击分离可以用于重新混合目的,例如改变两个信号分量之间的水平比(参见[4]),这会使得实现“更平滑”或“更强”的整体声音感知。
用于谐波-冲击声音分离的一些方法依赖于这样的假设:在输入信号的幅度频谱图中,谐波声音具有水平结构(在时间方向上),而冲击声音表现为垂直结构(在频率方向上)。ono等人提出了一种方法,该方法首先通过在时间/频率方向上的扩散来产生谐波/冲击增强的频谱图(参见[5])。之后通过比较这些增强的表示,可以得到声音是谐波还是冲击的决定。
fitzgerald发表了一种类似的方法,在该方法中,通过在垂直方向上使用中值滤波而不是扩散来计算增强的频谱图是(参见[6]),这产生了类似的结果,同时降低了计算复杂度。
受到正弦+瞬态+噪声(s+t+n)信号模型(参见[7]、[8]、[9])的启发,得到一种旨在借助于小的参数集来描述各个信号分量的框架。然后,fitzgerald的方法扩展到[10]中的谐波-冲击-残差(hpr)分离。由于音频信号通常由既不明显地是谐波也不明显地是冲击的声音组成,因此该过程在第三残差分量中捕获这些声音。尽管这些残差信号中的一些明显具有各向同性的(既不是水平的也不是垂直的)结构(例如,如噪声一样),但是存在不具有明显的水平结构但仍然携带音调信息并且可以被感知为声音的谐波部分的声音。一个示例是频率调制的音调,就像它们可以出现在小提琴演奏或声乐作品的录音中,据说它们具有“颤音”。由于识别水平结构或垂直结构的策略,上述方法并不总是能够在其谐波分量中捕获这样的声音。
在[11]中提出了一种基于非负矩阵因子分解的谐波-冲击分离过程,该分离过程能够在谐波分量中捕获具有非水平频谱结构的谐波声音。然而,它不包括第三残差分量。
综上所述,最近的方法依赖于以下观察:在频谱图表示中,谐波声音导致水平结构,而冲击声音导致垂直结构。此外,这些方法将既不水平也不垂直的结构(即,非谐波、非冲击声音)与残差类别相关联。然而,这种假设对于诸如频率调制音调等的信号不成立,这些信号显示波动的频谱结构,但仍然携带音调信息。
结构张量(一种用于图像处理的工具(参见[12]、[13]))应用于灰度图像以用于边缘和角落检测(参见[14]),或估计对象的取向。结构张量已经用于音频处理中的预处理和特征提取(参见[15]、[16])。
技术实现要素:
本发明的目的是提供用于音频信号处理的改进的构思。通过根据权利要求1所述的装置、根据权利要求18所述的系统、根据权利要求19所述的编码器、根据权利要求20所述的方法、以及根据权利要求21所述的计算机程序来实现本发明的目的。
提供了一种用于根据音频信号的幅度频谱图进行相位重构的装置。该装置包括:频率改变确定器,被配置为根据音频信号的幅度频谱图,来确定针对音频信号的幅度频谱图的多个时频段中的每个时频段的频率的改变;以及相位重构器,被配置为根据针对多个时频段而确定的频率的改变来产生针对多个时频段的相位值。
此外,提供了一种编码器,其被配置为产生音频信号的幅度频谱图以供上述装置进行相位重构。
此外,提供了一种用于根据音频信号的幅度频谱图进行相位重构的方法。所述方法包括:
-根据音频信号的幅度频谱图,来确定针对音频信号的幅度频谱图的多个时频段中的每个时频段的频率的改变,以及
-根据针对多个时频段而确定的频率的改变来产生针对多个时频段的相位值。
此外,提供了一种计算机程序,其中所述计算机程序被配置为当在计算机或信号处理器上执行时实现上述方法。
附图说明
以下参考附图更详细地描述本发明的实施例,在附图中:
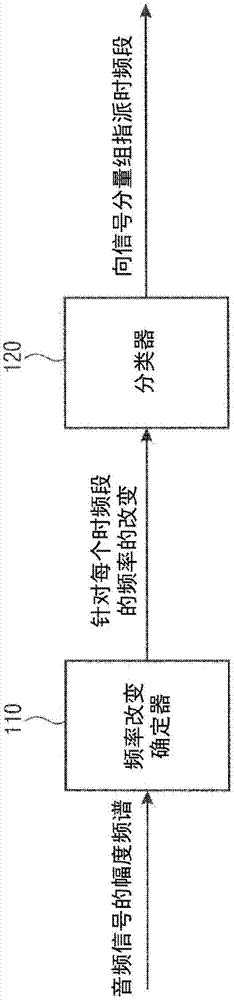
图1示出了根据实施例的用于分析音频信号的幅度频谱图的装置,
图2示出了根据实施例的歌声、响板和掌声的混合的频谱图,其中在某一区域中对该频谱图进行了放大,在该放大区域中,箭头的取向指示方向,并且箭头的长度指示各向异性度量,
图3示出了根据实施例的通过使用结构张量计算的取向/各向异性值的范围,
图4示出了用于合成输入信号的摘录的hpr-m和hpr-st方法之间的比较,
图5示出了根据实施例的装置,其中该装置包括信号产生器,
图6示出了根据实施例的装置,其中该装置包括用于记录音频信号的一个或多个麦克风,
图7示出了根据另一实施例的用于相位重构的装置,
图8示出了根据实施例的用于相位重构的装置,该装置包括信号产生器,
图9示出了根据实施例的包括编码器和解码器在内的系统,其中解码器是根据实施例的用于相位重构的装置,以及
图10示出了根据实施例的音频编码器和音频解码器,其使用幅度频谱进行传输。
具体实施方式
图1示出了根据实施例的用于分析音频信号的幅度频谱图的装置。
该装置包括频率改变确定器110。频率改变确定器110被配置为根据音频信号的幅度频谱图,来确定针对音频信号的幅度频谱图的多个时频段(bin)中的每个时频段的频率的改变。
此外,该装置包括分类器120。分类器120被配置为根据针对所述时频段而确定的频率的改变,向两个或更多个信号分量组中的信号分量组指派多个时频段中的每个时频段。
根据实施例,频率改变确定器110可以例如被配置为根据针对多个时频段中的每个时频段的角度α(b,k),来确定针对该时频段的频率的改变。针对所述时频段的角度α(b,k)取决于音频信号的幅度频谱图。
在实施例中,频率改变确定器110可以例如被配置为:进一步根据音频信号的采样频率fs、根据分析窗口的长度n、以及根据分析窗口的跳大小h,来确定针对多个时频段中的每个时频段的频率的改变。
根据实施例,装置的频率改变确定器110被配置为根据下式来确定针对多个时频段中的每个时频段的频率的改变:
(b,k)指示多个时频段中的时频段,其中r(b,k)指示针对所述时频段(b,k)的频率的改变,其中b指示时间,其中k指示频率,其中fs指示音频信号的采样频率,其中n指示分析窗口的长度,其中h指示分析窗口的跳大小,并且其中α(b,k)指示针对所述时频段(b,k)的角度,其中该角度α(b,k)取决于幅度频谱图。
在实施例中,频率改变确定器110可以例如被配置为确定音频信号的幅度频谱图s关于时间索引的偏导数sb。在这样的实施例中,频率改变确定器110可以例如被配置为确定音频信号的幅度频谱图s关于时间索引的偏导数sk。
此外,在这样的实施例中,频率改变确定器110被配置为:根据音频信号的幅度频谱图s关于时间索引的偏导数sb、以及根据音频信号的幅度频谱图s关于频率索引的偏导数sk,确定针对多个时频段中的每个时频段(b,k)的结构张量t(b,k)。
此外,在这样的实施例中,频率改变确定器110可以例如被配置为:根据针对多个时频段中的每个时频段(b,k)的结构张量t(b,k),确定针对该时频段(b,k)的角度α(b,k)。
根据实施例,频率改变确定器110可以例如被配置为:通过确定多个时频段中的每个时频段(b,k)的结构张量t(b,k)的特征向量v(b,k)的两个分量v1(b,k)和v2(b,k)、以及通过根据下式确定针对所述时频段(b,k)的角度α(b,k),来确定针对该时频段(b,k)的角度α(b,k):
α(b,k)指示针对所述时频段(b,k)的角度,其中b指示时间,其中k指示频率,并且其中atan()指示反正切函数。
在实施例中,分类器120可以例如被配置为:根据下式中的至少一个,来确定针对多个时频段中的每个时频段(b,k)的各向异性的度量:
以及
μ(b,k)+λ(b,k)≥e,
μ(b,k)是所述时频段(b,k)的结构张量(t(b,k))的第一特征值,λ(b,k)是所述时频段(b,k)的结构张量(t(b,k))的第二特征值,并且
在这样的实施例中,分类器120可以例如被配置为:进一步根据各向异性的度量的改变,向两个或更多个信号分量组中的信号分量组指派多个时频段中的每个时频段。
根据实施例,分类器120可以例如被配置为:根据下式,来确定针对所述时频段(b,k)的各向异性的度量:
c(b,k)是取决于所述时频段(b,k)的各向异性的度量,并且其中分类器120被配置为如果各向异性的度量c(b,k)小于第一阈值c,则向两个或多个信号分量组中的残差分量组指派所述时频段(b,k),或者其中分类器120被配置为如果各向异性的度量c(b,k)小于或等于第一阈值c,则向两个或更多个信号分量组中的残差分量组指派所述时频段(b,k),其中
在实施例中,分类器120可以例如被配置为:根据针对多个时频段中的每个时频段而确定的频率的改变r(b,k),向两个或更多个信号分量组中的信号分量组指派所述时频段(b,k),使得分类器120根据针对所述多个时频段中的时频段而确定的频率的改变r(b,k)的绝对值|r(b,k)|是否小于第二阈值rh,或者根据针对所述时频段(b,k)而确定的频率的改变r(b,k)的绝对值|r(b,k)|是否小于或等于第二阈值rh(其中rh
根据实施例,分类器120可以例如被配置为:根据针对多个时频段中的时频段而确定的频率的改变r(b,k),向两个或更多个信号分量组中的信号分量组指派所述时频段(b,k),使得分类器120根据针对多个时频段中的时频段而确定的频率的改变r(b,k)的绝对值|r(b,k)|是否大于第三阈值rp,或者根据针对所述时频段(b,k)而确定的频率的改变(r(b,k))的绝对值|r(b,k)|是否大于或等于第三阈值rp(其中
在下文中,提供了实施例的详细描述。
实施例提供基于结构张量的谐波-冲击-残差(hpr)声音分离的改进构思。一些实施例通过利用与由结构张量提供的频谱结构的取向有关的信息来捕获在谐波分量中保持音调信息的频率调制声音。
一些实施例基于以下发现:向水平和垂直的严格分类不适合于这些信号,并且可能导致音调信息泄漏到残差分量中。实施例涉及一种新颖的方法,其取而代之地使用结构张量这一数学工具来计算幅度频谱图中的主导取向角。即使在频率调制信号的情况下,实施例也采用该取向信息来区分谐波信号分量、冲击信号分量和残差信号分量。最后,借助于客观评价措施以及音频示例来验证实施例的构思的有效性。
此外,一些实施例基于以下发现:结构张量可以被认为是黑盒,其中输入是灰度图像,并且输出是针对每个像素的与最低改变的方向相对应的角度n以及针对每个像素的针对该方向的确定性或各向异性度量。附加地,结构张量提供了平滑的可能性,这减少了噪声的影响以增强鲁棒性。此外,确定性度量可以用于确定估计的角度的质量。该确定性度量的低值指示像素位于恒定亮度的区域中而没有任何明确的方向。
例如,可以从通过结构张量获得的角度中提取局部频率改变。通过这些角度,可以确定频谱图中的时频段是属于谐波(=低局部频率改变)分量还是冲击(=高或无限局部频率改变)分量。
提供了针对谐波-冲击-残差分类和分离的改进实施例。
谐波-冲击-残差声音分离是一种有用的预处理工具,其用于诸如音高乐器转录或节奏提取之类的应用。一些实施例不是仅搜索严格水平和垂直的结构,而是通过使用从图像处理中已知的结构张量来确定频谱图中的主导取向角以及局部各向异性。
在实施例中,然后可以使用所提供的与频谱结构的取向有关的信息以通过设置适当的阈值来区分谐波信号分量、冲击信号分量和残差信号分量,参见图2。
图2示出了歌声、响板和掌声的混合的频谱图,其中在某一区域中对该频谱图进行了放大,该放大区域附加地示出了通过结构张量获得的方向(箭头的取向)和各向异性度量(箭头的长度)。箭头的颜色指示基于取向和各向异性信息将相应的时频段指派给谐波分量(区域210)、冲击分量(区域230)还是残差分量(区域220)。
既没有高局部频率改变率也没有低局部频率改变率或指示恒定区域的确定性度量的所有段被指派为属于残差分量。在图2中可以看到频谱图中的该分离的示例。针对包括频率调制声音在内的音频信号,实施例比针对幅度频谱图的类似方法表现得更好。
首先,描述结构张量的构思,并且该一般构思扩展为适用于音频处理的上下文。
在下文中,为了便于标记,矩阵和向量被写为粗体字。此外,(.)运算符用于对特定元素编索引。在这种情况下,矩阵或向量被写为非粗体字以显示其标量用法。
首先,描述根据实施例的频谱图的计算。音频信号可以例如是(离散的)输入音频信号。
结构张量可以应用于采样频率为fs的离散输入音频信号
其中
通过使用上面的公式(1),可以获得频谱图。频谱图包括多个频谱,其中多个频谱在时间上彼此相继。如果存在至少一些第二时域样本,则多个频谱中的第二频谱在时间上相继于第一频谱,其中所述至少一些第二时域样本用于产生第二频谱而不用于产生第一频谱,并且是指作为比用于产生第一频谱的第一时域样本更晚的时间点的时域样本。用于及时产生相邻频谱的时域样本的窗口可以例如重叠。
在实施例中,分析窗口长度n可以例如被定义为:
256个样本≤n≤2048个样本。
在一些实施例中,分析窗口长度可以例如是2048。在其它实施例中,分析窗口长度可以例如是1024个样本。在另外的实施方案中,分析窗口长度可以是例如768个样本。在另外的实施例中,分析窗口长度可以是例如256个样本。
在实施例中,分析跳大小h可以例如在分析窗口的25%与75%之间的范围内。在这样的实施例中:
0.25n≤h≤0.75n。
因此,在这样的实施例中,如果分析窗口具有例如2048个样本(n=2048),则分析跳大小可以例如在以下范围内:
512个样本≤h≤1536个样本。
如果分析窗口具有例如256个样本(n=256),则分析跳大小可以例如在以下范围内:
64个样本≤h≤192个样本。
在优选实施例中,分析跳大小可以例如是分析窗口的50%。这与两个后续分析窗口的50%的窗口重叠相对应。
在一些实施例中,分析跳大小可以例如是分析窗口的25%。这与两个后续分析窗口的75%的窗口重叠相对应。
在其它实施例中,分析跳大小可以例如是分析窗口的75%。这与两个后续分析窗口的25%的窗口重叠相对应。
应当注意,本发明的构思适用于任何类型的时域到频谱域变换,例如适用于改进离散余弦变换(mdct)、改进离散正弦变换(mdst)、离散短时傅里叶变换(dstft)等。
实值对数频谱图可以例如计算为:
s(b,k)=20log10|x(b,k)|(2)
音频信号的幅度频谱图可以被称为s,并且针对时频段(b,k)的幅度频谱图的值可以被称为s(b,k)。
在下文中,描述了根据实施例的结构张量的计算。
对于结构张量的计算,需要s的偏导数。通过下式给出关于时间索引b的偏导数:
sb=s*d(3)
而关于频率索引k的偏导数被定义为:
sk=s*dt(4)
其中d是离散微分算子(例如,对于中心差异,可以选择d=[-1,0,1]/2),并且*表示二维卷积。
此外,可以定义:
t11=(sb⊙sb)*g(5)
t21=t12=(sk⊙sb)*g(6)
t22=(sk⊙sk)*g(7)
其中,⊙是逐点矩阵乘法,也称为hadamard乘积,并且g是2维高斯平滑滤波器,其在时间索引方向上具有标准差σb并且在频率索引方向上具有标准差σk。然后,通过2×2对称的正半定矩阵给出结构张量t(b,k):
结构张量包括与频谱图的位置(b,k)处的主导取向有关的信息。应当注意,在g是标量的特殊情况下,t(b,k)不包括除了频谱图中的该位置处的梯度之外的信息。然而,与梯度相比,可以通过g对结构张量进行平滑而没有抵消效果,这使得它对噪声更加鲁棒。
应注意,结构张量t(b,k)是针对多个时频段中的每个时频段(b,k)而定义的。因此,当考虑多个时频段(例如,时频段(0,0);(0,1);(0,2);...(1,0);(1,1);(1,2);...)时,存在多个结构张量t(0,0);t(0,1);t(0,2);...t(1,0);t(1,1);t(1,2);...。例如,针对多个时频段中的每个时频段(b,k),确定一个结构张量t(b,k)。
在下文中,描述了根据实施例的角度和各向异性度量的计算。
通过计算结构张量t(b,k)的特征值λ(b,k)、μ(b,k)(其中λ(b,k)≤μ(b,k))和对应的特征向量v(b,k)=[v1(b,k),v2(b,k)]t和w(b,k)=[w1(b,k),w2(b,k)]t,来获得与针对频谱图中的每个段的取向有关的信息。应当注意,与较小特征值λ(b,k)相对应的特征向量v(b,k)指向频谱图中的索引(b,k)处的最低改变的方向,而w(b,k)指向最高改变的方向。因此,可以通过下式获得特定段处的取向角:
v1(b,k)和v2(b,k)是特征向量v(b,k)的分量。
atan()指示反正切函数。
此外,可以针对每个段确定各向异性的度量
其中
通过考虑在时间间隔δt期间具有瞬时频率改变δf的连续信号,可以理解角度α(b,k)的物理意义。因此,瞬时频率改变率r表示为:
例如,根据实施例,通过结构张量获得的角度(由图2中的箭头的方向指示)可以例如被转换为针对频谱图中的每个时频段的局部频率改变率
针对每个时频段的频率的改变可以例如被称为瞬时频率改变率。
考虑到所应用的stft分析的采样率、长度和跳大小,可以通过下式导出频谱图中的角度与针对每个段的瞬时频率改变率r(b,k)之间的关系:
也可以通过下式将离散域中的平滑滤波器g的标准差σb和σk转换为连续的物理参数σt和σf:
在下文中,描述了使用结构张量的谐波-冲击-残差分离。
经由结构张量获得的信息可以应用于hpr分离的问题,例如,以将频谱图中的每个段分类为输入信号的谐波分量、冲击分量或残差分量的一部分。
实施例基于以下发现:指派给谐波分量的段应该属于相当水平的结构,而属于相当垂直的结构的段应该指派给冲击分量。此外,应向残差分量指派不属于任何类型的定向结构的段。
根据实施例,如果段(b,k)满足以下两个约束中的第一约束,则可以例如向谐波分量指派该段。
根据优选的实施例,如果段(b,k)满足以下两个约束,则可以例如向谐波分量指派该段:
-第一约束可以例如是角度α(b,k)的绝对值小于(或等于)阈值αh。阈值αh可以例如在范围αh∈[0;π/2]内。这意味着,段应该是斜率不大于或小于αh的某一频谱结构的一部分。这样,根据参数αh,还可以将频率调制声音认为是谐波分量的一部分。
-第二约束可以是例如各向异性的度量c(b,k)支持段(b,k)是某一定向的各向异性结构的一部分,并因此超过另一阈值c。应当注意,对于给定的段(b,k),角度α(b,k)和各向异性的度量c(b,k)一起定义了极坐标下给出的
类似地,在实施例中,指派另一角度阈值αp以定义何时应将段指派给冲击分量(图3中具有垂直线的区域330)。
因此,根据实施例,如果段(b,k)满足以下两个约束中的第一约束,则可以例如向冲击分量指派该段。
根据优选实施例,如果段(b,k)满足以下两个约束,则可以例如向冲击分量指派该段:
-第一约束可以例如是角度α(b,k)的绝对值大于(或等于)阈值αp。阈值αp可以例如在范围αp∈[0;π/2]内。这意味着,段应该是斜率不大于或小于αp的某一频谱结构的一部分。这样,根据参数αp,还可以将频率调制声音认为是谐波分量的一部分。
-第二约束可以是例如各向异性的度量c(b,k)支持段(b,k)是某一定向的各向异性结构的一部分,并因此超过另一阈值c。应当注意,对于给定的段(b,k),角度α(b,k)和各向异性的度量c(b,k)一起定义了极坐标下给出的
最后,在实施例中,可以向残差分量指派既不向谐波分量指派也不向冲击分量指派的所有段。
可以通过定义针对谐波分量的掩模mb、针对冲击分量的掩模mp、以及针对残差分量的掩模mr来表示上述指派过程。
应当注意,在实施例中,替代使用阈值αh和阈值αp,可以例如定义关于最大绝对频率改变率的阈值
mr(b,k)=1-mh(b,k)-mp(b,k)(16)
最后,通过下式获得谐波分量xh、冲击分量xp和残差分量xr的stft:
xh=mh⊙x(17)
xp=mp⊙x(18)
xr=mr⊙x(19)
然后可以经由逆stft计算对应的时间信号。
图3示出了通过结构张量计算的取向/各向异性值的范围。
具体地,图3描绘了导致向谐波分量进行指派的所有点的子集。具体地,具有波浪线的区域310中的值导致向谐波分量进行指派。
具有垂直线的区域330中的值导致向冲击分量进行指派。
点状区域320中的值导致向残差分量进行指派。
阈值αh定义图3中的线301,并且阈值αp定义图3中的线302。
图5示出了根据实施例的装置,其中该装置包括信号产生器130,其被配置为根据向两个或更多个信号分量组指派多个时频段来产生音频输出信号。
例如,信号产生器可以通过对不同信号分量组的时频段的幅度值应用不同的加权因子来对音频信号的不同分量进行滤波。例如,谐波信号分量组可以具有第一加权因子wh,冲击信号分量组可以具有第二加权因子wp,并且残差信号分量组可以具有第一加权因子wr,并且多个时频段中的每个时频段的幅度值可以例如用向其指派该时频段的信号分量组的加权因子来加权。
例如,为了强调谐波信号分量,在实施例中,将加权因子与线性幅度值相乘,例如,
wh=1.3,wp=0.7,和wr=0.2。
例如,为了强调谐波信号分量,在实施例中,将加权因子与对数幅度值相加,例如,
wh=+0.26,wp=-0.35,和wr=-1.61。
例如,为了强调冲击信号分量,在实施例中,将加权因子与线性幅度值相乘,例如,
wh=0.7,wp=1.3,和wr=0.2。
例如,为了强调冲击信号分量,在实施例中,将加权因子与对数幅度值相加,例如,
wh=-0.35,wp=+0.26,和wr=-1.61。
因此,信号产生器130被配置为:对多个时频段中的每个时频段的幅度值应用加权因子以获得音频输出信号,其中,对所述时频段应用的加权因子取决于向其指派所述时频段的信号分量组。
在图5的特定实施例中,信号处理器130可以例如是上混频器(upmixer),其被配置为对音频信号进行上混频以获得包括两个或更多个音频输出通道在内的音频输出信号。上混频器可以例如被配置为根据向两个或更多个信号分量组指派多个时频段来产生两个或更多个音频输出通道。
例如,如上所述,可以根据音频信号产生两个或更多个音频输出通道,以通过对不同信号分量组的时频段的幅度值应用不同的加权因子,来对音频信号的不同分量进行滤波。
然而,为了产生不同的音频通道,可以使用针对信号分量组的不同权重,所述权重可以例如特定于不同音频输出通道中的每一个。
例如,对于第一音频输出通道,要与对数幅度值相加的权重可以是例如
w1h=+0.26,w1p=-0.35,和w1r=-1.61。
例如,对于第二音频输出通道,要与对数幅度值相加的权重可以是例如
w2h=+0.35,w2p=-0.26,和w2r=-1.61。
例如,当对音频信号进行上混频以获得左前环绕、中环绕、右环绕、左环绕和右环绕这五个音频输出通道时:
-与用于产生左环绕和右环绕音频输出通道的谐波加权因子w2h相比,用于产生左、中和右音频输出通道的谐波加权因子w1h可以更大。
-与用于产生左环绕和右环绕音频输出通道的冲击加权因子w2p相比,用于产生左、中和右音频输出通道的冲击加权因子w1p可以更小。
针对要产生的每个音频输出通道可以使用单独的加权因子。
图6示出了根据实施例的装置,其中该装置包括用于记录音频信号的一个或多个麦克风171、172。
在图6中,第一麦克风171记录音频信号的第一音频通道。可选的第二麦克风172记录音频信号的可选的第二音频通道。
此外,图6的装置还包括幅度频谱图产生器180,其用于根据包括第一音频通道、并且可选地包括可选的第二音频通道在内的音频信号来产生音频信号的幅度频谱图。根据音频信号产生幅度频谱图是本领域技术人员公知的构思。
在下文中,考虑对实施例的评价。
为了说明实施例在从谐波分量中捕获频率调制声音中的有效性,将根据实施例的基于结构张量的hpr方法(hpr-st)与[10]中提出的基于中值滤波的非迭代方法(hpr-m)进行比较。此外,还使用用作针对最大可实现分离质量的参考的理想二元掩模(ibm)针对分离结果计算度量。
考虑到系统测试参数,对于hpr-st和hpr-m两者,使用针对w的正弦窗口,将stft参数选择为fs=22050h、n=1024和h=256。如在[10]中执行的实验中那样选择针对hpr-m的分离参数。根据实施例,使用微分算子(例如,scharr-算子[17]作为离散微分算子d)计算结构张量。使用9×9各向同性高斯滤波器执行平滑,该高斯滤波器具有标准差σb=σk=1.4,这使得σt≈16ms和σf≈30hz。最后,用于分离的阈值被设置为e=20,c=0.2和rh=rp=10000hz/s。
应当注意,通过根据实施例选择rh和rp,甚至向谐波分量指派频谱图中的非常陡的结构。实施例采用与现实世界颤音有关的观察(例如如图2所示)。这里,可以看到,在某些情况下,歌声中的颤音具有非常高的瞬时频率改变率。此外,应该注意,通过选择rh=rp,向残差分量指派频谱图中的段完全取决于其各向异性度量。
通过借助于客观评价度量以及音频示例两者将根据实施例的hpr-st与[10]中提出的现有的基于中值滤波的方法hpr-m进行比较,来评价根据实施例的hpr-st的有效性。
为了将根据实施例的hpr-st的性能与现有技术的hpr-m的性能进行比较,当应用于包括频率调制声音在内的信号以获得客观结果时,产生两个测试项。
测试项1由纯合成声音的叠加组成。将谐波源选择为颤音音调,其基频为1000hz、颤音频率为3hz、颤音范围为50hz、且有4个泛音。对于冲击源,使用了若干个脉冲,而白噪声既不表示谐波源也不表示冲击残差源。
测试项2是通过将歌声的现实世界信号与颤音(谐波)、响板(冲击)和掌声(既不是谐波也不是冲击)进行叠加而产生的。
通过将这些项的hpr分离解释为源分离问题,已经计算了标准源分离评价度量(如[18]中所介绍的源失真比sdr、源干扰比sir、以及源伪像比sar),以产生两种过程的分离结果。表1中示出了结果。
表1描述了客观评价度量,其中所有值均以db为单位给出:
(表1)
对于项1,hpr-st针对颤音音调产生21.25db的sdr,因此与hpr-m的分离结果(11.51dr)相比,更接近ibm的最佳分离结果(29.43db)。这指示与hprm相比,hpr-st在从谐波分量中捕获该频率调制声音方面得到改善。图4中也示出了这一点。
图4示出了用于合成输入信号(项1)的摘录的hpr-m和hpr-st方法之间的比较。为了增强可见性,使用与用于分离算法的参数不同的stft参数来计算频谱图。
图4中的(a)示出了输入信号的频率相对于时间的图。在图4中,绘制了针对两个过程计算的谐波分量的频谱图以及冲击分量和残差分量之和的频谱图。可以看出,对于hpr-m,颤音音调的陡峭斜率泄漏到残差分量中(图4中的(b)和图4中的(c)),而hpr-st(图4中的(d)和图4中的(e))产生良好的分离。这也解释了与hpr-st相比,hprm针对残差分量的sir值非常低(-11.99db对14.12db)。
应该注意,hpr-m针对谐波分量的高sir值仅反映了来自其它分量的干扰声音很少,而没有反映整体上很好地捕获了颤音的声音。一般而言,针对项1的大多数观察不太明显,但对于项2中的现实世界声音的混合也有效。对于这个项,hpr-m针对人声的sir值甚至超过了hpr-st的sir值(20.83db对15.61db)。同样,针对掌声的低sir值支持人声中的颤音部分泄漏到针对hpr-m的残差分量中(1.11db),而hpr-st的残差分量包括较少的干扰声音(6.34db)。这指示与hpr-m相比,实施例能够远远更好地捕获人声的频率调制结构。
综上所述,对于包括频率调制音调在内的信号,与hpr-m相比,实施例的hpr-st构思提供了远远更好的分离结果。
一些实施例采用结构张量来进行歌声检测。(在[2]中描述了根据现有技术的歌唱检测)。
在下文中,描述了实施例的另一方面。该另一方面涉及根据幅度频谱图的相位重构。
图7示出了根据实施例的用于根据音频信号的幅度频谱图进行相位重构的装置。
该装置包括频率改变确定器110,其被配置为根据音频信号的幅度频谱图,来确定针对音频信号的幅度频谱图的多个时频段中的每个时频段的频率的改变。
此外,该装置包括相位重构器140,其被配置为根据针对多个时频段而确定的频率的改变来产生针对多个时频段的相位值。
根据实施例,相位重构器140可以例如被配置为:通过对频率的改变进行两次积分(通过在时间上进行两次积分),来产生针对多个时频段中的每个时频段的相位值。换句话说,在实施例中,相位重构器140被配置为:通过在时间上进行两次积分来产生针对多个时频段中的每个时频段的相位值。因此,换句话说,执行两次积分的间隔沿着频谱图的时间轴延伸。
根据其它实施例,相位重构器140被配置为:通过在频率上进行两次积分(通过在频谱上进行两次积分)来产生针对多个时频段中的每个时频段的相位值。因此,换句话说,执行两次积分的间隔沿着频谱图的频率轴延伸。例如,可以基于公式(30)和(31)执行在频率上进行了两次的积分。
在实施例中,相位重构器140可以例如被配置为根据下式产生针对多个时频段的相位值:
b0可以例如是指示多个块中的分析块的索引。b可以例如是指示多个块中的另外的分析块的另外的索引。h可以例如指示跳大小。φ(bh)、φb(b0)以及φbb(m)可以例如指示相位值。
在实施例中,频率改变确定器110可以例如被配置为:根据针对多个时频段中的每个时频段的角度α(b,k),确定针对所述时频段的频率的改变,其中针对所述时频段的角度α(b,k)取决于音频信号的幅度频谱图。
根据实施例,频率改变确定器110可以例如被配置为:进一步根据音频信号的采样频率fs、根据分析窗口的长度n、以及根据分析窗口的跳大小h,来确定针对多个时频段中的每个时频段的频率的改变。
在实施例中,装置的频率改变确定器110可以例如被配置为:根据下式来确定针对多个时频段中的每个时频段的频率的改变:
(b,k)指示多个时频段中的时频段,r(b,k)指示针对所述时频段(b,k)的频率的改变,b指示时间,k指示频率,fs指示音频信号的采样频率,n指示分析窗口的长度,h指示分析窗口的跳大小,并且α(b,k)指示针对所述时频段(b,k)的角度,其中该角度α(b,k)取决于幅度频谱图。
根据实施例,频率改变确定器110可以例如被配置为确定音频信号的幅度频谱图s关于时间索引的偏导数sb。此外,频率改变确定器110可以例如被配置为确定音频信号的幅度频谱图s关于时间索引的偏导数sk。此外,频率改变确定器110可以例如被配置为:根据音频信号的幅度频谱图s关于时间索引的偏导数sb、以及根据音频信号的幅度频谱图s关于频率索引的偏导数sk,确定针对多个时频段中的每个时频段(b,k)的结构张量t(b,k)。此外,频率改变确定器110可以例如被配置为:根据针对多个时频段中的每个时频段(b,k)的结构张量t(b,k),确定针对所述时频段(b,k)的角度α(b,k)。
在实施例中,频率改变确定器110可以例如被配置为:通过确定多个时频段中的每个时频段(b,k)的结构张量t(b,k)的特征向量v(b,k)的两个分量v1(b,k)和v2(b,k)、以及通过根据下式确定针对所述时频段(b,k)的角度α(b,k),来确定针对所述时频段(b,k)的角度α(b,k):
α(b,k)指示针对所述时频段(b,k)的角度;b指示时间,k指示频率,并且atan()指示反正切函数。
根据实施例,相位重构器140被配置为根据针对多个时频段而确定的频率的改变来产生针对多个时频段中的每个时频段的相位值。
在实施例中,相位重构器140可以例如被配置为:根据针对多个时频段中的每个时频段而确定的频率的改变,确定针对多个时频段中的每个时频段(b,k)的各向异性的度量。
根据实施例,相位重构器140可以例如被配置为:根据下式中的至少一个,来确定针对多个时频段中的每个时频段(b,k)的各向异性的度量:
以及
μ(b,k)+λ(b,k)≥e,
μ(b,k)是所述时频段(b,k)的结构张量(t(b,k))的第一特征值,λ(b,k)是所述时频段(b,k)的结构张量(t(b,k))的第二特征值,并且
根据实施例,相位重构器140被配置为:根据下式,来确定针对所述时频段(b,k)的各向异性的度量:
c(b,k)是取决于所述时频段(b,k)的各向异性的度量。相位重构器140可以例如被配置为:如果各向异性的度量c(b,k)小于上阈值c,则向两个或更多个信号分量组中的残差分量组指派所述时频段(b,k),或者其中相位重构器140可以例如被配置为:如果各向异性的度量c(b,k)小于或等于上阈值c,则向两个或更多个信号分量组中的残差分量组指派所述时频段(b,k),其中
根据实施例,相位重构器140可以例如被配置为:根据各向异性的度量、是否应该执行相位重构,来确定针对多个时频段中的每个时频段的相位重构模式。
相位重构器140可以例如被配置为:如果相位重构器140针对多个时频段中的每个时频段所确定的相位重构模式指示第一模式,则通过对频率的改变进行两次积分,来产生针对所述时频段的相位值。此外,相位重构器140可以例如被配置为:如果相位重构器140针对多个时频段中的每个时频段所确定的相位重构模式指示与第一模式不同的第二模式,则通过对频率的改变进行两次积分,来确定针对所述时频段的相位。
在实施例中,相位重构器140可以例如被配置为:确定针对多个时频段中的每个时频段(b,k)的相位重构模式,使得如果各向异性的度量大于下阈值c,则相位重构模式指示第一模式;并且使得如果针对所述时频段(b,k)的各向异性的度量小于或等于下阈值c,则相位重构模式指示第二模式。
在实施例中,上阈值和下阈值c可以例如相等。
或者,相位重构器(140)被配置为:确定针对多个时频段中的每个时频段(b,k)的相位重构模式,使得如果针对所述时频段(b,k)的各向异性的度量大于或等于阈值c,则相位重构模式指示第一模式;并且使得如果各向异性的度量小于阈值c,则相位重构模式指示第二模式。
例如,第一模式可以指示时频段属于谐波或冲击信号分量组。
例如,第一模式可以指示时频段属于残差信号分量组。
在下文中,更详细地描述了根据特定实施例的相位估计。
在[19]和[20]中已经提出了用于根据给定的幅度频谱图来估计相位信息的任务的算法。然而,这些算法要么具有高计算复杂度,要么使得一般音频信号的可感知质量不令人满意。
根据幅度频谱图来估计相位信息是可以用于例如音频编码的任务,其中编码器可以仅传输幅度而在解码器处恢复相位。与现有技术的基于mdct的编码器相比(其中频谱展示即使对于恒定的音调信号也随时间波动),(例如,dft或cmdct(也称为mclt)的)幅度频谱更加稳定,这允许随时间的比特率有效的差分编码(参见[21])和有效的多通道冗余减少。
在实施例中,基于通过结构张量而进行的局部频率改变估计,根据实施例的新算法基于考虑任意输入信号由若干线性调频脉冲(chirp)组成的信号模型。线性调频脉冲信号由下式给出
x(t)=sin(φ(t)),φ(t)=2πf0t+πrt2(20)
其中t是时间变量,f0[hz]是恒定的起始频率,r[hz/s]是恒定的频率改变率。通过关于t对相位自变量φ(t)进行两次求导,可以示出:
因此,可以通过对频率改变率进行两次积分来获得当前相位。对于工作在离散域中的该算法,这种积分变成求和。假设每个频谱图段与局部线性调频脉冲信号相对应,则通过结构张量估计的局部频率改变与针对每个局部线性调频脉冲的r相对应。此外,使用通过结构张量获得的各向异性度量,可以在没有任何显式信号模型或先前语义分类的情况下执行局部频率改变率的所需积分。
由于高各向异性度量与频谱图中的定向结构(如音调或冲击分量)相对应,因此与可以假设随机相位的各向同性噪声区域形成对比,高各向异性度量与可以重构相位的区域相对应。
现在对此进行更详细的描述:
如上所述,通过结构张量获得的角度(例如,由图2中的箭头方向所示)可以转换为针对频谱图中的每个时频段的局部频率改变率
其中α(b,k)是通过结构张量提取的针对每个段的角度。
在下文中,解释了使用例如结构张量的信息来根据幅度频谱图进行相位重构及其用于音频编码的构思。假设:
不仅是stft而且是x(t)的任意时频表示。然后,可以将相位重构的问题描述为从幅度频谱图|x(b,k)|中提取估计
然后可以再次产生对应的时域信号y(t)。
在实施例中,基于通过结构张量而进行的局部频率改变估计,提供了一种用于根据幅度频谱图进行相位重构的新算法。通过考虑由下式给出的离散线性调频脉冲信号,可以理解主要思想:
其中,
因此,φb(b)是相对于分析块索引b的有限差分,并且可以被解释为对x(t)的瞬时角频率的估计。通过使用φb(b),当φb(b0)已知时,可以在任何分析块b>b0处表示φ(bh):
现在,考虑从先前分析块b-1到当前块b的φb(b)的改变:
φbb(b)对于线性调频脉冲而言是恒定的,并且包括固定常数以及频率改变率r0。可以将其解释为从一个分析块到下一个块的角频率增加。如果φb(b0)已知,则甚至可以进一步使用φbb(b)来表示公式(27):
这意味着,如果知道先前分析块处的相位和瞬时频率、并且进一步知道恒定频率改变r0,则可以计算分析块b处的相位φ(bh)。
注意,可以针对瞬态信号(例如,脉冲)计算这些表达式和公式的双重表达式(dual)。然而,必须相对于某个分析块b的频谱相位ψ(k)=arg(x(b,k))中的频率索引k进行有限差分。
然后通过下式获得针对瞬态信号的时间重心:
ψk(k)=ψ(k)-ψ(k-1)(30)
并且通过下式获得瞬态信号的时间重心随频率索引k的改变:
ψkk(k)=ψk(k)-ψk(k-1)(31)
对于这种情况,可以导出公式(27)和公式(29)的双重表达式(dualexpression)。
根据实施例,如上所述,使用通过结构张量获得的局部频率改变率的估计来提供用于根据幅度频谱进行相位重构的算法。
假设每个频谱图段与分别具有线性频率改变的局部线性调频脉冲信号相对应,则如在先前子部分中所说明的,通过结构张量估计的局部频率改变r(b,k)与调频脉冲率或者局部线性频率改变r0相对应。这意味着:通过结构张量获得的主导方向可以被视为φbb(b)关于时间索引b的二阶导数的平滑鲁棒估计,并且高达一些乘法常数。
使用该估计,然后可以使用公式(29)来计算信号的当前相位。由于仅在一个段的范围内假设线性频率改变,因此即使对于具有更复杂频率调制的信号,也可以获得相位估计。必须注意,瞬时频率以及初始相位必需是事先已知(例如作为边信息传输)的,或者是用不同方法估计的。特别地,可以使用诸如qfft之类的内插或幅度频谱的导数来估计瞬时频率。
必须注意,即使公式(29)显示严格求和为分析块方向b的和,在更先进的算法中,总和必须遵循频谱图中信号主瓣的轨迹。因此,可能有必要在求和方向上隐式地或显式地分别将通过结构张量获得的方向信息和局部频率改变率进行合并。这可以使得估计的相位是频率索引k方向和分析块索引b方向上的和的结果的叠加。
此外,必须注意,经由公式(29)计算的表达式与公式(25)中所示的正弦的自变量相对应。尽管这与在频谱表示中观察到的相位具有很强的对应关系,但可能有必要使用进一步的知识(例如,依赖于相位的频谱的解析表达)来正确合成针对每个段(例如,针对频谱的旁瓣)的相位。
此外,使用通过结构张量获得的各向异性度量,可以在没有任何显式信号模型或先前语义分类的情况下执行局部频率改变率的所需积分。由于高各向异性度量与频谱图中的定向结构(如音调或冲击分量)相对应,因此与可以假设随机相位的各向同性噪声区域形成对比,高各向异性度量与可以重构相位的区域相对应。
此外,没有必要将算法局限于单音信号。
实施例实现了优于现有技术的优点。例如,一些实施例表现出适度的计算复杂度(例如,小于[19]中的计算复杂度)。此外,针对频率调制信号,与[20]中的相位估计相比,一些实施例实现了更好的相位估计。
一些实施例实现了信号分量的固有分类:
例如,根据一些实施例,可以针对谐波信号分量进行相位估计;可以针对冲击信号分量进行相位估计;但不能针对残差信号分量和/或噪声信号分量进行相位估计。
在下文中,考虑音频编码应用。
滤波器组的选择是设计音频编解码器的关键步骤。现有的编解码器通常使用mdct(改进离散余弦变换),因为它在严格采样时提供50%的重叠,并且在没有量化的情况下能够进行完美重构。在编码应用中,这些属性减少了块伪像,同时使必须传输的频谱系数的数据量保持较低。mdct的缺点在于:即使对于平稳信号,其也随时间存在频谱波动。这使得例如频谱系数的差分编码的编码增益损失,因为先前传输的mdct频谱的信息在当前mdct频谱的重构中仅有有限的用途。
因为频谱的幅度(例如,50%重叠mclt(调制复合重叠变换)滤波器组的幅度)随时间更加稳定[21],特别是对于平稳信号更是如此,因此实施例提供了基于上述针对相位重构的构思的编解码器的设计。
根据实施例,编码器使用分析滤波器组执行pcm输入信号x(t)的时频分解,以获得针对特定时间间隔(例如,一帧)的复合频谱x(f)。x(f)用于提取边信息。
在实施例中,边信息可以例如包括瞬态信号和/或初始化相位(例如,按规则间隔的)的基频和/或时间位置和/或关于当前信号类别的信息等。
然后,将x(f)的幅度量化为|y(f)|,并且将其与边信息一起传输到解码器。然后,解码器使用边信息以及量化后的幅度频谱|y(f)|来估计如上所述的原始复合频谱x(f)的相位。通过使用该估计相位,可以获得复合频谱y(f),其应该非常接近x(f)。然后,将y(f)馈入合成滤波器组以获得时域输出信号y(t)。利用所提出的mclt滤波器组,这样的编解码器仍将展示出诸如重叠和临界采样之类的期望特征,同时为平稳信号的差分编码提供更有效的可能性。
图8示出了根据上述实施例之一的用于相位重构的装置,其包括信号产生器150。信号产生器150被配置为根据音频信号的幅度频谱图并且根据针对多个时频段的相位值来产生音频输出信号。
例如,幅度频谱图提供针对特定时频段的幅度值,并且相位重构器140已经重构了针对该特定时频段的相位值。
图9示出了根据实施例的包括编码器210和解码器220在内的系统,其中解码器220是根据上述实施例之一的用于相位重构的装置。
编码器210被配置为对音频信号的幅度频谱图进行编码。
解码器220被配置为根据音频信号的幅度频谱图,来确定针对音频信号的幅度频谱图的多个时频段中的每个时频段的频率的改变。
此外,解码器220被配置为根据针对多个时频段而确定的频率的改变来产生针对多个时频段的相位值。
此外,解码器220被配置为使用音频信号的幅度频谱图并且使用针对多个时频段的相位值来对音频信号进行解码。
图10示出了根据实施例的音频编码器210和音频解码器220,其使用幅度频谱进行传输。
音频编码器210被配置为产生音频信号的幅度频谱图以供所述装置如上所述地进行相位重构。在图10中,解码器220可以是例如如上所述的用于相位重构的装置。
尽管已经在装置的上下文中描述了一些方面,但是将清楚的是,这些方面还表示对对应方法的描述,其中,块或设备对应于方法步骤或方法步骤的特征。类似地,在方法步骤的上下文中描述的方面也表示对对应块或者对应装置的项或特征的描述。可以由(或使用)硬件装置(比如,微处理器、可编程计算机或电子电路)来执行一些或全部方法步骤。在一些实施例中,可以由这种装置来执行最重要方法步骤中的一个或多个方法步骤。
根据某些实现要求,本发明的实施例可以以硬件或软件实现,或者至少部分地以硬件、或至少部分地以软件实现。可以使用其上存储有电子可读控制信号的数字存储介质(例如,软盘、dvd、蓝光、cd、rom、prom、eprom、eeprom或闪存)来执行实现,该电子可读控制信号与可编程计算机系统协作(或者能够与之协作)从而执行相应方法。因此,数字存储介质可以是计算机可读的。
根据本发明的一些实施例包括具有电子可读控制信号的数据载体,该电子可读控制信号能够与可编程计算机系统协作,从而执行本文所述的方法之一。
通常,本发明的实施例可以被实现为具有程序代码的计算机程序产品,程序代码可操作用于在计算机程序产品在计算机上运行时执行方法之一。程序代码可以例如存储在机器可读载体上。
其他实施例包括存储在机器可读载体上的计算机程序,该计算机程序用于执行本文所述的方法之一。
换言之,本发明方法的实施例因此是具有程序代码的计算机程序,该程序代码用于在计算机程序在计算机上运行时执行本文所述的方法之一。
因此,本发明方法的另一实施例是其上记录有计算机程序的数据载体(或者数字存储介质或计算机可读介质),该计算机程序用于执行本文所述的方法之一。数据载体、数字存储介质或记录的介质通常是有形的和/或非暂时性的。
因此,本发明方法的另一实施例是表示计算机程序的数据流或信号序列,所述计算机程序用于执行本文所述的方法之一。数据流或信号序列可以例如被配置为经由数据通信连接(例如,经由互联网)传送。
另一实施例包括被配置为或适用于执行本文所述的方法之一的处理装置(例如,计算机或可编程逻辑器件)。
另一实施例包括其上安装有计算机程序的计算机,该计算机程序用于执行本文所述的方法之一。
根据本发明的另一实施例包括被配置为向接收机(例如,以电子方式或以光学方式)传送计算机程序的装置或系统,该计算机程序用于执行本文所述的方法之一。接收机可以是例如计算机、移动设备、存储设备等。装置或系统可以例如包括用于向接收机传送计算机程序的文件服务器。
在一些实施例中,可编程逻辑器件(例如,现场可编程门阵列)可以用于执行本文所述的方法的功能中的一些或全部。在一些实施例中,现场可编程门阵列可以与微处理器协作以执行本文所述的方法之一。通常,方法优选地由任意硬件装置来执行。
可以使用硬件装置、或者使用计算机、或者使用硬件装置和计算机的组合来实现本文描述的装置。
可以使用硬件装置、或者使用计算机、或者使用硬件装置和计算机的组合来执行本文描述的方法。
上述实施例对于本发明的原理仅是说明性的。应当理解的是:本文所述的布置和细节的修改和变形对于本领域其他技术人员将是显而易见的。因此,本发明旨在仅由所附专利权利要求的范围来限制而不是由借助对本文实施例的描述和解释所给出的具体细节来限制。
参考文献:
[1]aggelosgkiokas,vassilioskatsouros,georgecarayannis,andthemosstafylakis,“musictempoestimationandbeattrackingbyapplyingsourceseparationandmetricalrelations”,inproceedingsoftheieeeinternationalconferenceonacoustics,speech,andsignalprocessing(icassp),2012,pp.421-424.
[2]bernhardlehner,gerhardwidmer,andreinhardsonnleitner,“onthereductionoffalsepositivesinsingingvoicedetection”,inproceedingsoftheieeeinternationalconferenceonacoustics,speech,andsignalprocessing(icassp),florence,italy,2014,pp.7480-7484.
[3]yushiueda,yuukiuchiyama,takuyanishimoto,nobutakaono,andshigekisagayama,“hmm-basedapproachforautomaticchorddetectionusingrefinedacousticfeatures”,inproceedingsoftheieeeinternationalconferenceonacoustics,speech,andsignalprocessing(icassp),dallas,texas,usa,2010,pp.5518-5521.
[4]nobutakaono,kenichimiyamoto,hirokazukameoka,andshigekisagayama,“areal-timeequalizerofharmonicandpercussivecomponentsinmusicsignals”,inproceedingsoftheinternationalsocietyformusicinformationretrievalconference(ismir),philadelphia,pennsylvania,usa,2008,pp.139-144.
[5]nobutakaono,kenichimiyamoto,jonathanleroux,hirokazukameoka,andshigekisagayama,“separationofamonauralaudiosignalintoharmonic/percussivecomponentsbycomplementarydiffusiononspectrogram”,ineuropeansignalprocessingconference,lausanne,switzerland,2008,pp.240-244.
[6]derryfitzgerald,“harmonic/percussiveseparationusingmedianfiltering”,inproceedingsoftheinternationalconferenceondigitalaudioeffects(dafx),graz,austria,2010,pp.246-253.
[7]scottn.levineandjuliuso.smithiii,“asines+transients+noiseaudiorepresentationfordatacompressionandtime/pitchscalemodications”,inproceedingsoftheaesconvention,1998.
[8]tonys.vermaandteresah.y.meng,“ananalysis/synthesistoolfortransientsignalsthatallowsaflexiblesines+transients+noisemodelforaudio”,inproceedingsoftheieeeinternationalconferenceonacoustics,speech,andsignalprocessing(icassp),seattle,washington,usa,may1998,pp.3573-3576.
[9]laurentdaudet,“sparseandstructureddecompositionsofsignalswiththemolecularmarchingpursuit”,ieeetransactionsonaudio,speech,andlanguageprecessing,vol.14,no.5,pp.1808-1816,september2006.
[10]jonathandriedger,meinardmüller,andsaschadisch,“extendingharmonic-percussiveseparationofaudiosignals”,inproceedingsoftheinternationalconferenceonmusicinformationretrieval(ismir),taipei,taiwan,2014,pp.611-616.
[11]jeongsooparkandkyogulee,“harmonic-percussivesourceseparationusingharmonicityandsparsityconstraints”,inproceedingsoftheinternationalconferenceonmusicinformationretrieval(ismir),málaga,spain,2015,pp.148-154.
[12]josefbigunand
[13]hansknutsson,“representinglocalstructureusingtensors”,in6thscandinavianconferenceonimageanalysis,oulu,finland,1989,pp.244-251.
[14]chrisharrisandmikestephens,“acombinedcornerandedgedetector”,inproceedingsofthe4thalveyvisionconference,manchester,uk,1988,pp.147-151.
[15]rolfbardeli,“similaritysearchinanimalsounddatabases”,ieeetransactionsonmultimedia,vol.11,no.1,pp.68-76,january2009.
[16]matthiaszeppelzauer,angelas.
[17]hannoscharr,“optimaleoperatoreninderdigitalenbildverarbeitung“,dissertation,iwr,
[18]emmanuelvincent,rémigribonval,andcédricfévotte,“performancemeasurementinblindaudiosourceseparation”,ieeetransactionsonaudio,speech,andlanguageprocessing,vol.14,no.4,pp.1462-1469,2006.
[19]danielw.griffinandjaes.lim,“signalestimationfrommodifiedshort-timefouriertranfform”,ieeetransactionsonacoustics,speech,andsignalprocessing,vol.32,no.2,pp.236-243,1984.
[20]paulmagron,rolandbadeau,andbertranddavid,“phasereconstructionofspectrogramswithlinearunwrapping:applicationtoaudiosignalrestoration”,insignalprocessingconference(eusipco),201523rdeuropean.ieee,2015,pp.1-5.
[21]byung-junyoonandhenriquesmalvar,“codingovercompleterepresentationsofaudiousingthemclt”,indatacompressionconference,2008.dcc2008.ieee,2008,pp.152-161。
- 还没有人留言评论。精彩留言会获得点赞!