耳机的有源噪声消除系统的制作方法
本发明涉及有源噪声消除系统,特别是适用于头戴式耳机和耳机,以及具有有源噪声消除系统的头戴式耳机和耳机。
背景技术:
在具有有源噪声消除功能的传统耳机中,耳机内的麦克风检测外部环境噪声,然后对外部环境噪声进行处理,以生成一个反相信号,为耳机佩戴者消除音频信号中的环境噪声。测量的噪声信号用于产生反馈信号,该反馈信号通过放大器进行处理以调整电平,然后将其反相并应用于耳机的扬声器以消除噪声信号。滤波用于保留预期的音频信号。目前使用的大多数有源噪声消除技术都是类似的,在实现方案、滤波器以及麦克风和扬声器的放置上都有所不同。
最近,数字噪声消除技术得到了发展。传统的数字噪声消除技术主要是基于子带滤波和主频率音频及其谐波产生的来消除大部分的环境噪声。这些技术为用户在实践中受到的大部分典型噪声提供了合理有效的噪声消除。然而,现有的噪声消除技术在它们可以处理的音频信号带宽、为用户播放的预期音频信号的质量以及噪声的降低水平上有很大的限制,因此一流的产品通常不能降低超过10db的噪声水平。
在不影响为用户提供的预期声音的音频质量的前提下,可以改善有源噪声消除的性能。
技术实现要素:
鉴于上述,本发明的目的是提供一种在保持高质量音频信号的同时有效地消除环境噪声的有源噪声消除系统。
本发明的另一个目的是提供一种具有有源噪声消除系统的耳机,所述有源噪声消除系统能够有效地消除环境噪声,并且对提供给佩戴者的音频信号的质量具有最小或无影响。
有源噪声消除系统易于实施且具有成本效益。
本发明的目的是通过提供根据权利要求1所述的有源噪声消除系统、根据权利要求6所述的耳机以及根据权利要求8所述的产生耳机音频信号的方法来实现。
本说明书和权利要求书中所用的“耳机”一词旨在包括任何由人戴在耳朵或耳朵上、靠近耳朵或耳朵内的电动移动发声装置。例如,一个耳机或一对耳机在这里被理解为属于术语“耳机”的含义。
本发明公开了一种有源噪声消除系统,包括有源噪声消除电路,所述有源噪声消除电路连接到设置为感测环境噪声的麦克风,所述有源噪声消除电路包括:
模数转换器(adc)(14),其被设置成将所感测的环境噪声转换成数字环境噪声信号,
预测滤波器(16),其被配置用于预测多个(d个)反相的数字环境噪声样本并生成数字环境噪声反相信号,
数模转换器(dac)(24),用于将数字环境噪声反相信号转换为模拟环境噪声反相信号以消除环境噪声。
在一个实施例中,有源噪声消除电路包括设置在预测滤波器之前或之后的数字信号路径中的外壳频率响应滤波器,以补偿麦克风位置对感测环境噪声的影响。
在一个实施例中,有源噪声消除电路包括一个求和电路,所述求和电路被设置为将用于向用户播放的音频信号添加到所述数字或模拟环境噪声反相信号中。
在一个实施例中,有源噪声消除电路包括一个放大器,用于调整求和的音频信号和环境噪声反相信号的增益。
在一个实施例中,adc和dac以总延迟小于1微秒的时钟频率fs工作。
本发明还公开了一种耳机,其包括如上述任何实施例中所述的有源噪声消除系统、外壳、设置为感测连接到有源噪声消除电路的环境噪声的麦克风、以及连接到有源噪声消除电路的扬声器系统,所述扬声器系统安装在外壳中。
在一个实施例中,麦克风和有源噪声消除电路安装在外壳中。
本文还公开了一种生成耳机音频信号的方法,包括以下步骤:
通过麦克风感测环境音频噪声信号;
使用模数转换器(adc)将感测到的环境音频噪声信号转换为数字环境音频噪声信号;
对所述数字环境音频噪声信号运行预测滤波训练算法,提取预测滤波器系数;
将所述预测滤波器系数更新至工作在n倍的时钟频率(fs)下预测滤波器,所述预测滤波器配置为预测未来环境噪声信号的多个(d个)样本;
对数字环境音频噪声信号及其预测的多个未来样本进行处理,生成反相的预测环境噪声样本;
通过数模转换器(dac)将反相的预测环境噪声样本转换为模拟有源噪声消除信号。
在一个实施例中,adc和dac以总延迟小于1微秒的时钟频率(fs)工作。
在一个实施例中,该方法还包括:
将用户预期的音频信号样本添加到反相的预测环境噪声样本中,并通过数模转换器(dac)将所述样本转换为包括有源噪声消除信号的模拟音频信号。
在一个实施例中,包括有源噪声消除信号的模拟音频信号被馈送到扬声器系统,向用户播放预期的音频信号,同时消除环境噪声。
在一个实施例中,该方法还包括:
在外壳频率响应滤波器中处理数字环境音频噪声信号及其预测的多个未来样本,以适应麦克风位置。
在一个实施例中,所述预测的多个未来样本具有与包括所述adc和所述dac的有源噪声抵消电路的总延迟相对应的预测深度时间tpd。
在一个实施例中,所述预测滤波器配置为预测所述多个(d个)环境噪声信号的未来样本,使得所述多个d除以所述时钟频率d/fs实质上等于所述预测深度时间tpd。
在一个实施例中,预测滤波器以比adc的时钟频率fs高n倍的时钟频率nxfs运行,其中,n在10到1000的范围内。
在一个实施例中,预期未来噪声信号中预测噪声样本的数量等于tpd*fs,其中tpd是有源噪声消除系统的总延迟,fs是adc的时钟频率。
在一个实施例中,有源噪声消除系统的总延迟tpd在100微秒到200微秒的范围内。
在一个实施例中,adc的时钟频率fs高于200khz,例如在200khz到1mhz的范围内。
附图说明
从权利要求书和以下与附图有关的本发明实施例的详细说明中可以看出本发明的其他目的和有利特征,其中:
图1是根据本发明实施例的耳机简图示意图;
图2是根据本发明第一实施例的有源噪声消除系统的原理框图;
图3是根据本发明第二实施例的有源噪声消除系统的原理框图。
具体实施方式
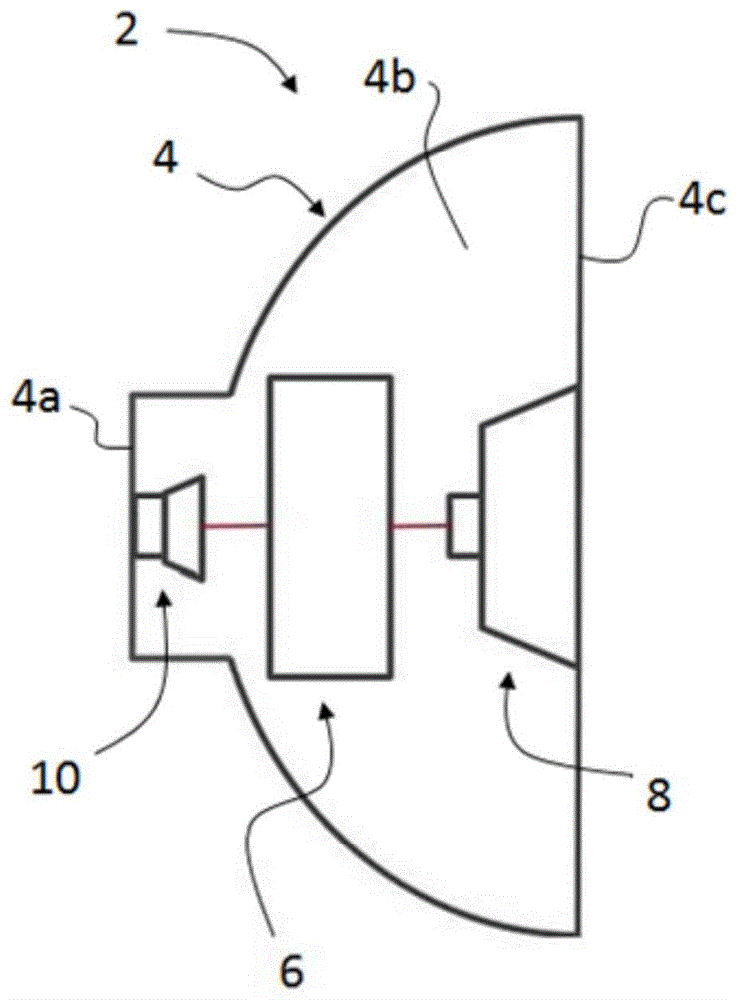
参考上述附图,根据本发明实施例的耳机2被配置成佩戴在人的耳朵上、耳朵内或耳朵附近,包括外壳4、安装在外壳4中的有源噪声消除系统6和安装在外壳4中的扬声器系统8。扬声器系统8可包括各种声音换能器,以从提供给所述换能器的音频信号中再现声音,本身为所属领域内众所周知的。
外壳4包括对应于外部环境噪声接收侧的外侧4a、配置成将扬声器系统8产生的声音指向人的耳朵的耳侧4c以及容纳扬声器系统8的部件的内部4b。有源噪声消除系统的部件最好也安装在外壳4内,但是在其他变化实施例中,有源噪声消除系统的部件也可以部分或全部安装在容纳扬声器系统的外壳4外,例如安装在单独的外壳内,例如在连接两个耳机设备的头带或连接到耳机设备的有线控制装置中。
有源噪声消除系统6包括麦克风10和有源噪声消除电路12。在较佳实施例中,麦克风可放置于外壳外侧4a附近,其配置成捕获要消除的外部(环境)噪音。然而,在其他变化实施例中,也可以将话筒放置在外壳的不同位置或外壳外部的单独支架(如耳机头带)中。
在一个实施例中,有源噪声消除电路包括模拟-数字转换器(adc)14、预测滤波器16、数字-模拟转换器(dac)24、时钟28和连接到扬声器系统8的放大器电路26。有源噪声消除系统还可以包括外壳频率响应滤波器(casingfrequencyresponsefilter)22。
预测滤波器16包括数字预测滤波器电路20和预测滤波器系数训练算法18。
参考图2和图3,图示地说明了本发明耳机的有源噪声消除系统的示例性实施例。有源噪声消除系统包括麦克风10、模拟-数字转换器14、用于提取预测滤波器最佳系数的预测滤波器系数训练算法18、用于预测预期环境噪声e.n.的多个(d个)反相噪声样本的预测滤波器20、数字求和电路36、数模转换器24、调节噪声级的放大器26,以及扬声器系统8以播放音频和反相噪声信号。在一个较佳的实施例中,根据采样频率,多个(d个)反相噪声样本可以较佳的在10到40个样本的范围内。例如,该范围的样本有助于预测未来一段时间的环境噪声,该时间最长可达200微秒。
麦克风10接收到的环境噪声e.n.由麦克风的传感器转换为电信号,该电信号被送入模拟-数字转换器(adc)14,该模数转换器将环境噪声的模拟信号转换为数字信号。可以注意到,麦克风的位置可以在耳机中或耳机上的不同位置,也可以与耳机分开,这样,麦克风产生的信号可以采用耳机的滤波器系统的传输功能,根据其特定位置进行调整。换言之,可由滤波器系统根据麦克风传感器输出信号的位置变化进行补偿,作为麦克风输出信号的传输功能。麦克风滤波器可用于adc14之前的模拟信号或adc14之后的数字信号。
模数转换器(adc)14本身是已知的,但优选在总延迟小于1微秒的adc和优选14位或更高分辨率的adc中配置或选择。
e.n.的数字信号被送入预测滤波器16,该预测滤波器16存储并执行训练算法,以提取预测滤波器电路20的系数。在各种通用预测滤波器(如递归最小二乘(rls)滤波器或卡尔曼滤波器)中使用的各种通用训练算法可用于此目的。由于用户所处的大多数环境中环境噪声的典型自然变化,预测滤波器的系数可配置为以最长2秒或更短的离散时间间隔tu更新,其中时间间隔tu最好小于1秒。
在非限制性示例中,预测滤波器系数训练程序可以包括接收麦克风数字输入信号的通用nlms(归一化最小均方)算法和预测滤波器20的预期输出信号,预期输出信号包括预测数字信号的样本。预测滤波器可以是有限脉冲响应(fir)滤波器。然后利用系数训练算法生成有限脉冲响应(fir)滤波器的预测系数。通常,512个系数足以进行适当的预测。这些滤波器系数将用于预测滤波器电路20。预测滤波器电路16和预测滤波器系数训练算法20例如可以在现场可编程门阵列(fpga)(例如xilinx的artix7系列)中实施和执行,以满足系统的速度和延迟要求。
来自adc的数字噪声样本以及预测滤波器系数被送入预测滤波器电路20。例如,预测滤波器电路可以基于预测滤波器的有限脉冲响应(fir)或无限脉冲响应(iir)通用方案。在本发明实施例中,预测滤波器的工作频率比adc14和dac24的时钟频率(fs)高n倍,因为它需要在未来一个时钟时间(1/fs)内生成多个(d个)样本。倍数n优选大于10,例如在10到1000的范围内。预期未来噪声信号中预测噪声样本的数量可能等于tpd*fs,其中tpd是有源噪声消除系统的总延迟(如图2和图3所示)。根据数字路径中所有模块14、16、22、36、24的总延迟,总延迟tpd优选在100微秒到200微秒的范围内。为了实现最佳的高性能系统,时钟频率fs优选高于200千赫,例如在200千赫到1兆赫的值范围内。
数字噪声样本和预测噪声样本还可以通过外壳频率响应滤波器22进行处理。外壳频率响应滤波器22根据麦克风10的位置补偿耳机外壳4对环境噪声信号的影响。外壳频率响应滤波器允许麦克风安装在耳机中的任何位置,甚至是噪音环境中,并且可以通过校准来补偿麦克风接收到的噪音信号与使用该外壳频率响应滤波器的听者耳朵接收到的噪音信号之间的差异。在麦克风安装在耳机内的实施例中,麦克风接收到的声音信号基本上与为听者耳朵提供的声音信号相同,外壳频率响应滤波器可将传输功能设置为1,对应于无滤波效果或-1,对应于无滤波效果,但具有反相信号。
在图2的实施例中,外壳频率响应滤波器输出反相噪声的最终预测样本,用于消除指向听者耳朵的声音中的环境噪声。为了消除环境噪声,数字信号的反相可由外壳频率响应滤波器进行。
在如图3所示的变化实施例中,外壳频率响应滤波器22可置于预测滤波器16之前,由此预测滤波器电路20输出最终预测的反相噪声样本,以消除指向听者耳朵的声音产生的环境噪声。
最终预测的噪声样本通过求和电路36添加到从音频信号源34接收的用户音频信号样本(例如音乐、语音)中。求和电路36的输出由以fs时钟频率工作的数模转换器(dac)24处理成模拟信号。数模转换器的输出是一个模拟反相噪声加上用户音频信号。dac24本身已知,优选在总转换延迟小于1微秒的dac中配置或选择。
模拟反相噪声加上用户音频信号可以馈入具有固定增益的放大器,用于调节模拟信号的增益匹配至扬声器系统,放大后的信号可以通过扬声器系统8播放。音频信号的音量控制由音频信号源的音量控制,在加上反相的环境噪声信号之前,因为要消除的环境噪声的振幅独立于向用户播放的音频信号的振幅。
扬声器系统的声音音频信号抵消瞬时环境噪声,用户只能听到来自音频信号源34的用户音频信号。
在其他变化的实施例(未显示)中,求和电路可以是在设置为将模拟音频信号添加到dac输出的模拟反相环境信号之后提供的模拟求和电路。
根据本发明实施例产生耳机音频信号的方法可以包括以下步骤:
通过麦克风感测声环境噪声信号;
使用以fs的时钟频率工作的低延迟和快速模数转换器(adc),将感测环境噪声信号转换为数字环境噪声信号,总延迟小于1微秒;
在数字环境噪声信号上运行预测滤波器系数训练算法,以离散的时间间隔tpt秒提取预测滤波器系数,tpt例如在50ms到1s的范围内,例如在100ms左右;
将预测滤波器系数更新至工作于n倍时钟频率fs(nxfs)的预测滤波器,以能够预测未来多个(d个)环境噪声信号样本;
在预测滤波器中处理所述数字音频噪声信号,以预测所述噪声信号的多个(d个)具有反相的未来数字样本;
对数字音频噪声信号及其预测的多个(d个)未来样本进行处理,生成反相预测的环境噪声样本;
将用户期望的音频信号样本添加到反相预测的环境噪声样本中,生成最终的数字音频样本;
通过以fs的时钟频率工作的数模转换器(dac),将最终的数字音频样本转换为模拟音频信号,总延迟小于1微秒。
然后,模拟音频信号可由放大器放大,以产生被放大的音频信号,该音频信号被送入扬声器系统,向用户播放预期的音频信号,同时消除环境噪声。可以注意到,音频信号的音量控制由音频信号源的音量控制控制,然后再添加到反相的环境噪声信号中,因为要消除的环境噪声的振幅与播放给用户的音频信号的振幅无关。
包括adc和dac在内的数字电路的总延迟对应于预测深度时间tpd。预测滤波器被配置为预测未来的多个(d个)样本,使得d/fs等于tpd,从而最大限度地降低环境噪声。
该方法还可以包括通过外壳频率响应滤波器电路处理数字环境噪声信号,以适应麦克风的位置。
所述耳机可以是无线或有线耳机,并且还可以包括用于与安装在诸如智能手机、平板电脑或计算机等用户设备上的应用程序通信的通信模块。通信模块可以配置为允许用户通过用户设备上的应用程序手动更改和自定义有源噪声消除系统的某些参数。通信的建立方式可以使用用户设备的处理能力至少完成一些处理。
参考列表
耳机2;
外壳4;
外侧(环境噪声接收侧)4a;
内部4b;
耳(发声)侧4c;
有源噪声消除系统6;
麦克风10;
有源噪声消除电路12;
模数转换器(adc)14;
预测滤波器16;
预测滤波系数训练算法18;
数字预测滤波器电路20;
外壳频率响应滤波器22;
数模转换器(dac)24
放大器26;
求和电路36;
时钟28;
时钟30;
扬声器系统8;
音频信号源34;
d:环境噪声信号预测未来样本数;
tpd:预测深度时间;
fs:时钟频率;
n:预测滤波器和外壳频率响应滤波器工作的时钟频率fs的倍数;
tpt:在数字环境噪声信号上运行预测滤波器系数训练算法以提取预测滤波器系数的时间间隔;
tu:预测滤波器更新系数之间的时间间隔。
- 还没有人留言评论。精彩留言会获得点赞!