用于确定一或多个音频源的一或多个音频表示的方法、系统和设备与流程
本申请主张2017年5月25日提交的美国临时专利申请第62/510,898号和2016年9月29日提交的美国临时专利申请第62/401,636号的优先权权益,所述两个申请以全文引用的方式并入本文中。
本公开涉及立体音频捕获、建模和表示以及提供一或多个音频对象的立体音频表示(其包含位置和/或音频特征)的方法、设备和过程。
背景技术:
虚拟现实(vr)、扩增现实(ar)和混合现实(mr)应用快速发展为包含声音源的逐渐细化声学模型和可从不同视点/视角欣赏到的场景。两个不同类别的柔性音频表示可用于vr应用:声场表示和基于对象的表示。声场表示是基于物理的方法,其编码收听者位置处的入射波前。举例来说,如b格式或高阶立体混响(higher-orderambisonics;hoa)的方法表示使用球面谐波分解的空间波前。基于对象的方法将复杂听觉场景表示为单个要素的集合,其包括可能随时间变化的音频波形和相关参数或元数据。
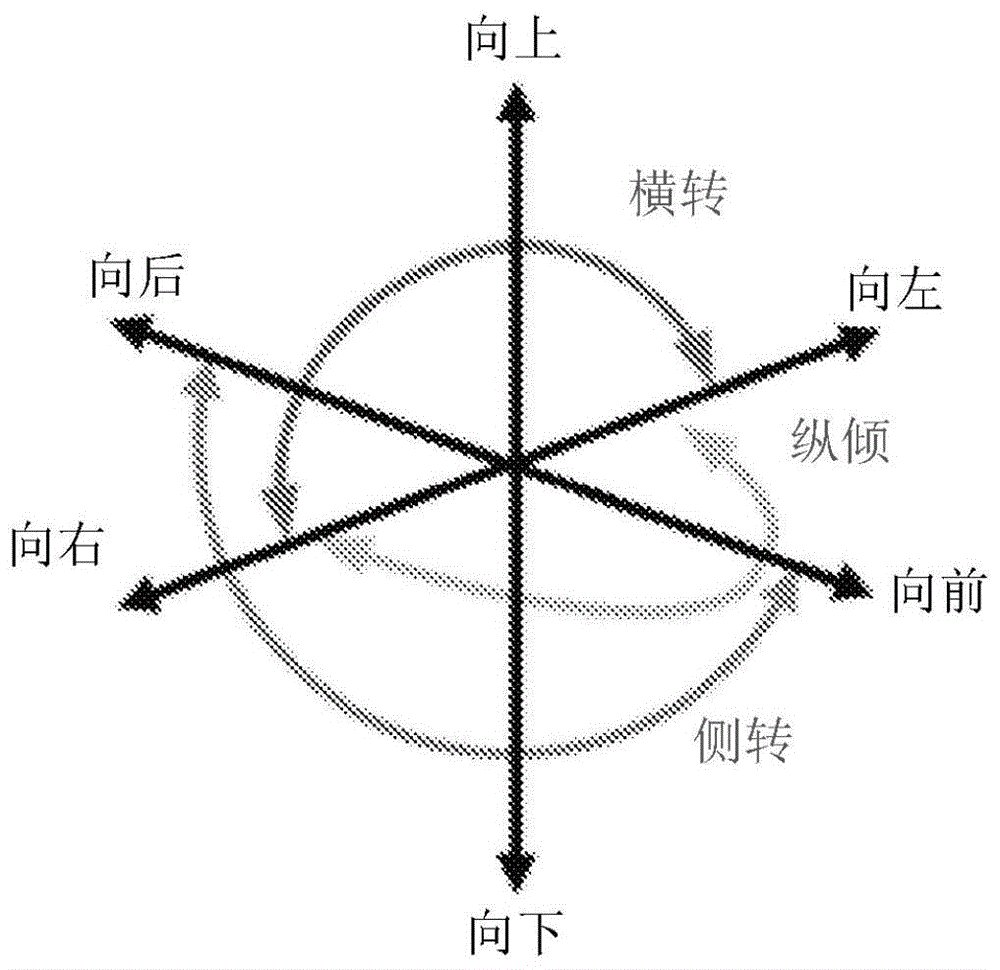
享受vr、ar和mr应用可包含用户经历不同听觉视点或视角。举例来说,可基于使用6个自由度(degreesoffreedom;dof)的机制来提供基于空间的vr。图1说明展示平移移动(向前/向后、向上/向下和向左/向右)和旋转移动(纵倾、侧转和横转)的6dof交互的实例。不同于限于头部旋转的3dof球面视频体验,为6dof交互创建的内容除了头部旋转之外还允许虚拟环境的导航(例如,在室内行走)。这可基于位置追踪器(例如,基于相机)和定向追踪器(例如,陀螺仪和/或加速计)而实现。6dof追踪技术可在较高端桌面vr系统(例如,
尽管存在允许重构来自多个相机(例如,基于摄影测量)的3d场景的视觉技术,所述相机允许与立体3d模型的交互,但缺乏可与这些立体视频方法匹配的音频方案。举例来说,声场捕获、建模和重构(例如,波场合成(wfs)或较高阶立体混响(hoa))当前在于相对大区域内提供引人注目的6dof交互和提供方向特性方面受到限制。为在相对大面积或相对宽频率范围内实现良好重构,需要相对大量的单声道麦克风。因此,此类方法受个别麦克风炭精盒的质量或snr困扰。此外,在单声道麦克风可捕获音频场景信息时,每个点处的空间信息的缺乏使其难以将不同录音融合到相干的音频场景中。
技术实现要素:
本文献以高效和精确方式解决确定包括一或多个音频源的音频场景的立体音频表示的技术问题。
根据一方面,描述一种用于确定至少一个音频源的位置的方法。方法包含在两个或更多个麦克风阵列处接收第一麦克风信号和第二麦克风信号,其中两个或更多个麦克风阵列置放在不同位置处(例如,在至少一个音频源周围的不同位置处两个或更多个麦克风阵列各自至少包括用于捕获第一麦克风信号的第一麦克风炭精盒和用于捕获第二麦克风信号的第二麦克风炭精盒,其中第一麦克风炭精盒与第二麦克风炭精盒具有以不同方式定向的空间方向性。此外,方法包含针对每一麦克风阵列且基于各别第一和第二麦克风信号来确定各别麦克风阵列处的至少一个音频源的入射方向。另外,方法包含基于两个或更多个麦克风阵列处的入射方向来确定音频源的位置。
根据另一方面,描述一种用于确定至少一个音频源的位置的方法。方法经调适以捕获两个或更多个麦克风阵列处的第一麦克风信号和第二麦克风信号,其中两个或更多个麦克风阵列置放在不同位置处。两个或更多个麦克风阵列各自至少包括用于捕获第一麦克风信号的第一麦克风炭精盒和用于捕获第二麦克风信号的第二麦克风炭精盒,其中第一麦克风炭精盒与第二麦克风炭精盒具有以不同方式定向的空间方向性。方法经进一步调适以针对每一麦克风阵列且基于各别第一和第二麦克风信号来确定各别麦克风阵列处的至少一个音频源的入射方向。另外,方法经调适以基于两个或更多个麦克风阵列处的入射方向来确定音频源的位置。
方法经进一步调适以基于音频源的位置来确定核心单声道音频信号且构建音频方向性的球面谐波表示。方法可进一步基于音频源的位置、核心单声道信号和音频方向性的球面谐波表示来确定音频表示。
根据另一方面,描述一种可执行上述方法的系统。
根据另一方面,描述一种软件程序。所述软件程序可适合于在处理器上执行且当在处理器上执行时适合于执行本文献中概述的方法步骤。
根据另一方面,描述一种存储媒体。存储媒体可包括适用于在处理器上执行且当在处理器上执行时适用于执行本文献中概述的方法步骤的软件程序。
根据另一方面,描述一种计算机程序产品。计算机程序可包括当在计算机上执行时执行本文献中概述的方法步骤的可执行指令。
应注意,如本专利申请中所概述的包含其优选实施例的方法和系统可单独或与本文献中所公开的其它方法和系统组合使用。此外,本专利申请中概述的方法和系统的所有方面可任意组合。确切地说,权利要求书的特征可以任意方式彼此组合。
附图说明
参考附图在下文以示范性方式解释本发明,其中
图1说明包含平移移动(向前/向后、向上/向下和向左/向右)和旋转移动(纵倾、侧转和横转)的基于示范性6自由度(dof)空间的vr;
图2说明用于捕获由一或多个音频源发射的音频信号的多个麦克风阵列的图式;
图3说明音频源的实例方向性图案;
图4展示在麦克风阵列处捕获的音频信号的声道间特征与音频源的方向参数之间的实例函数关系;
图5展示用于从在麦克风阵列处捕获的麦克风信号的声道间特征推导音频源的方向参数的实例神经网络;
图6说明用于确定一或多个立体音频表示的示范性方法的流程图;
图7展示用于确定音频源的位置的示范性方法的流程图;
图8展示用于确定音频源的方向性图案的示范性方法的流程图;以及
图9展示用于确定虚拟收听者位置处的收听信号的示范性方法的流程图。
具体实施方式
如所属领域的技术人员将了解,完全沉浸在虚拟世界中“欺骗”人的大脑去相信所感测的东西。当视线受到视野限制时,声音为不可见的东西增加维度。举例来说,声音可指示什么时候公牛从后面向前冲、响尾蛇正向右移动,或甚至什么时候耳语从人的左耳移动到其头部后面然后传到右耳。通过利用声音来导引用户的视线,内容创建者可更有效地说谎。
现在电影院和家庭式影院中正经由基于对象的声音形成、封装和内容回放来提供沉浸式音频体验。这已为vr声音铺平了道路,所述vr声音需要声音精确度才能完全沉浸在虚拟世界中。vr内容的创建者需要能够在三维空间中创建基于对象的声音。此外,此类内容需要通过(头戴式耳机上的)双耳和扬声器精确和高效地进行编码、传送和再现从而使用户享受内容。通常假设良好vr音频内容可通过与相机视角匹配的直接捕获来实现。然而,制作引人注目的混合通常需要超越现实从而基于操作提供增强视角。从内容创建到消费必须保留必要的艺术意图和创作完整性,从而确保完整沉浸到虚拟世界中。
本文中所描述的实例实施例描述经调适以利用相对少量的(高质量、低阶)方向性麦克风阵列(例如,立体声xy麦克风、xy+全向麦克风或a格式麦克风)记录音频场景且重构立体音频表示的方法、设备和过程,所述立体音频表示估计一或多个音频对象(即,从一或多个位置发射音频信号的一或多个音频源)的位置和音频特征。音频特征包含例如音频源的音频信号、音频信号的方向特性和/或用于音频信号的直接/漫射元数据标识符。
本文中所描述的额外实例实施例提出一种有效方案,所述方案通过将参数对象音频编码和空间集群方法扩展为包含方向信息来对方向音频源进行编码和空间写码。本文中所公开的实例实施例可采用各种捕获技术。举例来说,在一个实例实施例中,可通过将多个单点方向录音(例如,立体声、b格式、hoa)合并到单个3d音频场景中来创建vr、ar和/或mr环境。
图6说明用于确定立体音频表示的示范性方法600。在601处,声音可由一或多个麦克风或麦克风阵列捕获。替代地,在601处,预捕获声音可由方法600接收。声音可由音频信号表示,且此外,可由一或多个麦克风位姿(即,麦克风位置和定向数据)表示。
可基于计算机视觉技术或传感器(例如,陀螺仪、结构光传感器等)或基于音频源(例如,小扩音器)的平面布置经由声学测量来捕获麦克风位姿,其中音频源的几何形状已事先知道。举例来说,麦克风位姿可借由较高端vr系统(例如,
替代地,可进一步基于到达时间差(atimedifferenceofarrival;tdoa)分析来以声学方式获得麦克风位姿。举例来说,位置可通过求解将麦克风位置链接到全部麦克风对之间的tdoa(即,麦克风间距离)的非线性等式的集合来恢复。方向追踪可恢复麦克风的定向。替代地或另外,可基于具有已知几何形状的空间音频源来确定麦克风位姿。可逐个地或一次完全确定多个麦克风或麦克风阵列中的每一个的位姿。在一个实例中,可在601处根据结合图7的方法700(例如,图7的块701)所描述的原理来捕获声音。
在602处,可处理所捕获的麦克风信息(即,麦克风信号)。举例来说,在602处,可基于所捕获的麦克风信息来执行降噪和时间对准,所述所捕获的麦克风信息如(即,一或多个麦克风信号集合上的)全部所捕获的麦克风输入。输入可取决于对应麦克风阵列的麦克风位姿。可对一或多个麦克风信号集合(还称为麦克风声道)采用空间分析。可例如使用提交为pct/us2016/040836的从立体声记录确定方位角和仰角(determiningazimuthandelevationanglesfromstereorecordings)中所描述的xy上转换方法来针对不同频率子带(例如,时间/频率图像块)确定入射的直接/漫射分量和一或多个主方向。还可使用额外源分离方法或信号分类从而不限于子带分析。
举例来说,在xy上转换技术期间,一对重合、竖直堆叠的方向性麦克风炭精盒可输出第一麦克风音频信号和第二麦克风音频信号。所述麦克风炭精盒对(其形成麦克风阵列)可经组配使得所述重合、竖直堆叠的方向性麦克风炭精盒对是xy立体声麦克风系统。一些方法可涉及接收包含由一对重合、竖直堆叠的方向性麦克风炭精盒输出的第一麦克风音频信号和第二麦克风音频信号的输入音频数据。可至少部分地基于第一麦克风音频信号与第二麦克风音频信号之间的强度差来确定对应于声音源位置的方位角。可根据两个麦克风音频信号之间的时间差来估计仰角。可基于方位角和仰角信息来确定对由麦克风阵列捕获的声音的入射(在本文中又称为入射方向)的3d方向的估计。可针对不同频率子带和/或分离音频源或音频分量执行这一过程。
可相对于全部输入来在所有频率上实施宽带时间对准。可在上混/方向估计后对直接声音的每一子带执行空间平均。在一个实例中,可根据结合图7的方法700(例如,图7的块702)所描述的原理来处理声音。
在603处,使用麦克风阵列的已知位姿,可基于由每一麦克风阵列估计的入射方向来确定每一子带音频源再投影到每一麦克风“视点”中的位置(针对每一子带和/或针对每一分离音频分量)。图2中说明一实例。举例来说,可例如使用梯度下降通过使表示每一麦克风阵列210、220、230的位置估计的再投影误差的成本函数最小化来获得位置估计从而确定每一音频源200(例如,每一子带)的所估计位置。图2说明根据本文中所公开的实例实施例的具有所估计方向211、221、231和音频源200的所估计方位的多个麦克风阵列210、220、230的图式。在一个实例中,可根据结合图7的方法700(例如,图7的块703)或图6的方法600(例如图6的块603)所描述的原理来确定位置。
在604处,可重构每一音频源200(例如,每一子带)的单声道核心信号(即,音频信号)。基于对由音频源200发射到环境中的原始信号的估算来确定这种核心信号或音频信号。举例来说,可基于麦克风音频信号的线性组合(例如,由所估计源位置与每一麦克风位置之间的距离加权的和)来确定单声道核心信号。更一般来说,可将音频源200的单声道核心信号(即,音频信号)确定为由多个麦克风阵列210、220、230捕获的全部麦克风信号的加权平均。可基于麦克风阵列210、220、230的相对位置与音频源200的估计位置的函数来确定用于确定加权平均的权重。
在605处,可进一步最佳地构建音频源200的音频信号的球面谐波表示。可确定每一音频源200(例如,每一子带)的方向“残余”信号。可基于在604处重构的单声道音频信号的能量与由多个麦克风阵列210、220、230捕获的麦克风信号的能量之间的差来确定这一信息。知晓可通过将球面谐波系数的集合与由每一麦克风记录的能量级拟合来(例如针对每一音频源200)确定麦克风位姿以及每一音频源200(例如,每一子带或分离音频分量)的所估计位置、如图3中所展示的方向性图案302。图3说明根据本文中所公开的实例实施例的对与多个拟合球面谐波分量301重叠的多个麦克风阵列210、220、230的拟合方向性图案302的模拟。可相对于在604处确定的全向/平均音频信号将这一方向性图案302编码为分贝(decibel;db)增量。在一个实例中,可根据结合图8中展示的方法800所描述的原理来执行605处的处理。
在606处,基于来自603、604和605的信息来确定音频表示。更具体地,可基于(i)来自603的位置输出、(ii)来自604的核心音频信号和(iii)来自605的方向性函数输出来确定音频表示。可如先前所提及针对不同子带来估计那些要素。可随后输出且传输音频表示以用于进一步处理,(例如,通过图9中展示的方法900),如用于重新再现到新的收听有利点。
本文中所公开的实例实施例还可采用各种工具和gui,所述各种工具和gui可另外组合上混、自动融合和通过将输入链接/解链接进行的手动混合,生成对象音频输出(同时保持直接/漫射分量分离),调整随收听者距离而变的直接/漫射分量增益(在编码之前或在编码后)。gui要素可包含移动收听者,移动音频源200,以及在输入与世界视图之间改变。
实例实施例指向借助于对方向声音对象的参数编码和解码或借助于将方向源动态地分组到具有代表性位置的代表性方向集群(如新全向信号和新方向的方向性增量)中进行的编码和传送。
本文献的列举实例是:
列举实例1.一种立体音频捕获、表示和编码方法,其包括:从一或多个麦克风捕获或确定一或多个麦克风位姿以模拟相对于一或多个麦克风位姿的方向性的音频信息;根据从每一麦克风“视点”获得的方向估计来使子带音频对象的再投影位置最小化;估算所记录场景中的实体声音源的3d位置;以及重构每一子带对象的单声道核心和方向残余信号从而估算由所记录场景中的实体声音源发射的信号。
列举实例2.根据列举实例1所述的方法,其中捕获一或多个麦克风位姿包括使用位置追踪器或基于已知源几何形状的音频分析。
列举实例3.根据列举实例1所述的方法,其中通过恢复针对不同频率子带的入射的直接/漫射分量和一或多个主方向来对一或多个麦克风输入声道集合采用空间分析。
列举实例4.根据列举实例1所述的方法,其中与借助于空间分析的一或多个麦克风输入的捕获组合来采用源分离方法,所述空间分析不限于子带分析。
列举实例5.根据列举实例1所述的方法,其中估计源3d位置采用梯度下降以获得位置估计。
列举实例6.根据列举实例1所述的方法,其中重构针对每一子带对象的单声道核心加上方向残余信号采用基于相对于每一或多个麦克风的所估计源距离/方向的麦克风信号的线性组合。
列举实例7.根据列举实例5所述的方法,其中重构针对每一子带对象的单声道核心加上方向残余信号包含优化用于每一子带对象的球面谐波表示。
列举实例8.根据列举实例6所述的方法,其中相对于全向/平均源将方向性编码为分贝(db)增量。
列举实例9.根据列举实例6所述的方法,其进一步包括以下步骤:将高阶空间谐波转换为稀疏余弦瓣的和;以及将核心全向和方向残余解码为对象重要性函数。
列举实例10.根据列举实例1所述的方法,其中在多个子带对象中在舍弃了漫射分量的一些估计后基于每一子带对象到每一直接麦克风信号的所估计距离由全部麦克风的加权/时间对准的总和来重构对象信号的估算。
列举实例11.根据列举实例1所述的方法,其中非暂时性计算机可读媒体具有储存于其上的指令,在所述指令由一或多个处理器执行时,执行本文献中所描述的方法。
列举实例12.一种设备,其经配置用于立体音频捕获、表示和编码,所述设备包括:至少一个处理器和至少一个存储器,所述处理器和存储器经配置以:从一或多个麦克风捕获一或多个麦克风位姿以模拟相对于一或多个麦克风位姿的方向性的信息;使对应于每一麦克风“视点”的子带对象的再投影位置最小化;且重构针对每一子带对象的单声道核心加上方向残余信号。
图7展示用于确定至少一个音频源(例如,音频源200)的位置的实例方法700的流程图。在一个实例中,方法700可包含结合图6中所示的方法600的块602和603执行的处理。方法700可指向确定由至少一个音频源200发射的音频信号。另外,方法700可指向生成独立于收听者位置(即可对位于任意收听位置处的收听者重新再现)的音频表示。确切地说,可生成由至少一个音频源200发射的音频信号的音频表示。
这一音频表示可由方法900使用以再现不同收听位置处的收听信号,其中收听信号指示收听者如何感知由不同收听位置处的至少一个音频源200发射的音频信号。为了能够生成此类收听信号,可基于本文献中所描述的方法600、700或800来确定音频表示(即,一或多个音频源200的位置、所发射音频信号和/或方向性图案302)。
方法(700)可包含在701处捕获两个或更多个麦克风阵列210、220、230处的第一麦克风信号和第二麦克风信号,其中两个或更多个麦克风阵列210、220、230置放在不同位置处。换句话说,两个或更多个麦克风阵列210、220、230(例如,三个或更多个麦克风阵列210、220、230)可置放在三维环境内的不同位置处。尽管本方法说明三个麦克风阵列,但可实施三个以上麦克风阵列。麦克风阵列210、220、230可置放在一或多个音频源200周围。麦克风阵列210、220、230中的每一个可捕获第一麦克风信号和第二麦克风信号,其中麦克风阵列210、220、230的麦克风信号指示如何在麦克风阵列210、220、230的位置处感知由音频源200发射的音频信号。
两个或更多个麦克风阵列210、220、230通常至少各自包括用于捕获第一麦克风信号的第一麦克风炭精盒和用于捕获第二麦克风信号的第二麦克风炭精盒。第一麦克风炭精盒与第二麦克风炭精盒通常具有不同定向。换句话说,第一麦克风炭精盒和第二麦克风炭精盒可经配置以捕获不同空间方向上或具有不同方向性的声音。借助于实例,麦克风阵列(例如,210、220、230)可包括或可以是包括第一麦克风炭精盒和第二麦克风炭精盒的xy麦克风阵列,其中麦克风炭精盒经配置以捕获不同角度处(例如,相对于彼此的90°角度处)的声音。替代地或另外,麦克风阵列210、220、230可包括声场麦克风(例如,b格式麦克风)。
如此,麦克风阵列210、220、230的第一麦克风信号和第二麦克风信号指示由至少一个音频源200发射的音频信号的不同角度。所述不同角度可处于相对于彼此的90°角度。不同角度可用于确定由麦克风阵列210、220、230处的至少一个音频源200发射的音频信号的入射方向211、221、231。
麦克风阵列210、220、230可如此以使得麦克风阵列210、220、230的两个或更多个麦克风炭精盒的位置对于麦克风阵列210、220、230的两个或更多个麦克风炭精盒而言大体上相同。在另一方面,麦克风阵列210、220、230的麦克风炭精盒的空间方向性的定向可大体上不同。因此,可简化用于确定由音频源200发射的音频信号的入射方向211、221、231的处理。
可(例如,经由包括多个麦克风阵列210、220、230的系统设计)事先知道麦克风阵列210、220、230的空间方向性的位置和定向。替代地,方法700可包含例如使用图像处理,例如使用固定在麦克风阵列210、220、230处的位置传感器和/或例如使用红外(infrared;ir)追踪来确定麦克风阵列210、220、230的位置。此外,方法700可包括(例如,使用定向传感器)确定麦克风阵列210、220、230的定向(即,不同麦克风炭精盒的空间方向性的定向)。可随后基于麦克风阵列210、220、230的位置和/或定向来确定由麦克风阵列210、220、230处的音频源200发射的音频信号的入射方向211、221、231。
如此,方法700可包含在702处针对每一麦克风阵列210、220、230且基于各别第一和第二麦克风信号来确定各别麦克风阵列210、220、230处的至少一个音频源200的入射方向211、221、231。确切地说,可基于由麦克风阵列210、220、230捕获的第一麦克风信号和第二麦克风信号来确定由麦克风阵列210、220、230处的音频源200发射的音频信号的入射方向211、221、231。入射方向211、221、231可通过处理第一麦克风信号和第二麦克风信号而确定。确切地说,第一麦克风信号和第二麦克风信号的声级差和/或相位差(即,声道间声级差和/或相位/时间差)可用于确定入射方向211、221、231。
麦克风阵列210、220、230处的音频源200(或由音频源200发射的音频信号)的入射方向211、221、231可指示方向,音频信号从所述方向到达麦克风阵列210、220、230的位置。使用两个或更多个(例如,三个或更多个)麦克风阵列210、220、230,可确定音频源200的两个或更多个(例如,三个或更多个)入射方向211、221、231。换句话说,可使用k个麦克风阵列210、220、230,其中k是k>1的整数(例如,k>2)。k个麦克风阵列210、220、230可各自经调适以捕获指示由音频源200发射的音频信号的第一麦克风信号和第二麦克风信号,借此提供第一麦克风信号与第二麦克风信号的k个集合。使用第一麦克风信号与第二麦克风信号的集合,可确定入射方向211、221、231。因此,可确定单个音频源200的用于k个麦克风阵列210、220、230的k个入射方向211、221、231。
方法700可进一步包括在703处基于两个或更多个麦克风阵列210、220、230处的入射方向211、221、231来确定音频源200的位置。换句话说,用于k个麦克风阵列210、220、230的k个入射方向211、221、231可用于确定音频源200的位置。出于此目的,由音频源200发射的音频信号通常从单个位置(即,从音频源200的位置)发射可加以利用。因此,k个麦克风阵列210、220、230的k个位置处的k个入射方向211、221、231应彼此相关。k个入射方向211、221、231应指向音频源200的独特位置。借助于实例,三角测量技术可用于从k个入射方向211、221、231确定音频源200的这一独特位置。
使用图7的方法700,可以高效和精确方式确定音频源200的位置。确切地说,仅相对低数目的(方向)麦克风阵列210、220、230(例如,k=3)需要用以捕获由音频源200发射的声音。由(相对低数目的)麦克风阵列210、220、230捕获的麦克风信号可随后用于以精确方式确定音频源200的位置。
如上文所指出,音频源200的k个入射方向211、221、231应指向音频源200的位置。这说明于图2中。麦克风阵列210、220、230处的入射方向211、221、231指示起源于麦克风阵列210、220、230的位置处且(大致)指向音频源200的位置方向的直线或射线。在703处,为了确定音频源200的位置,可减小成本函数或使成本函数最小化。成本函数可指示音频源200的(待确定)位置与起源于k个麦克风阵列210、220、230的k个位置的k条直线的平均距离(例如,平均平方距离),其中k条直线分别根据k个入射方向211、221、231而定向。换句话说,成本函数可指示音频源200的(待确定)位置到先前确定的k个入射方向211、221、231上的(平均)重投影误差。如此,可确定与k条直线最近(平均上,相对于某一距离测量值,例如平均平方距离或平均绝对距离)的音频源200的位置,所述直线分别由k个入射方向211、221、231限定且由k个麦克风阵列210、220、230的k个位置(或位姿)限定。借此,可以精确方式确定音频源200的位置。
方法700可包含基于麦克风阵列210、220、230的第一麦克风信号和第二麦克风信号来确定声道间声级差(inter-channelleveldifference;icld)和声道间时间差(inter-channeltimedifference;ictd)。在一个实例中,可在图7中展示的方法700的702处确定或接收icld和/或ictd。icld可指示第一麦克风信号和第二麦克风信号的声级和/或能量的差。ictd可指示第一麦克风信号的相位与第二麦克风信号的相位之间的相位差。换句话说,ictd可指示第一麦克风信号的到达时间与第二麦克风信号的到达时间之间的到达时间差。可随后基于声道间声级差且基于声道间时间差来确定麦克风阵列210、220、230处的入射方向211、221、231。借此,可以精确方式确定入射方向211、221、231,从而改进音频源200的所确定位置的精确度。
麦克风阵列210、220、230处的入射方向211、221、231可指示三维环境内的方位角和仰角。可相对于麦克风阵列210、220、230的位置和/或相对于麦克风阵列210、220、230的定向(即,相对于麦克风阵列210、220、230的位姿)来限定角度。换句话说,麦克风阵列210、220、230处的入射方向211、221、231可指示起源于麦克风阵列210、220、230的位置处且指向音频源200的估计位置的直线的方位角411和仰角412。
图4展示可用于基于声道间声级差401和/或基于声道间时间差来确定入射方向211、221、231的方位角411和仰角412的实例函数关系420。借助于实例,可基于声道间声级差(icld)401来确定方位角411。出于此目的,可假设在平面内捕获第一麦克风信号和第二麦克风信号且方位角411指示这一平面内的入射方向211、221、231的角度。在另一方面,可基于声道间时间差来确定仰角412。如可从图4看出,方位角411与icld401之间的函数关系420通常还取决于仰角412。如此,可有益地从一对icld401和ictd确定用于入射方向211、221、231的一对仰角412与方位角411,借此能够精确地确定多个麦克风阵列210、220、230处的入射方向211、221、231。
可基于麦克风阵列210、220、230的第一麦克风信号和第二麦克风信号来使用分类器500确定麦克风阵列210、220、230处的入射方向211、221、231,其中分类器500可包含或可以是机器学习分类器(例如,神经网络)。通过利用分类器(例如,机器学习分类器),可以精确方式确定入射方向211、221、231。
分类器500可经配置以将由麦克风阵列210、220、230的第一麦克风信号和第二麦克风信号衍生的声道间声级差401和声道间时间差501映射到麦克风阵列210、220、230处的入射方向211、221、231,尤其映射到方位角411和仰角412。图5展示实例分类器500,尤其具有多个隐藏层510的神经网络。图5中展示的神经网络的输入层用于输入icld401与ictd501的集合,且神经网络的输出层用于提供方位角411与仰角412的对应集合。神经网络可以是前馈神经网络。隐藏层510的数目可以是1、2、3或多个(例如,4)。神经网络的不同神经元可利用相同类型或不同类型的激活函数。确切地说,tan-sigmoid函数可用作激活函数。可使用训练数据(例如,使用levenberg-marquardt演算法)来训练激活函数的权重和偏置值。
方法700可包含从麦克风阵列210、220、230的第一麦克风信号和第二麦克风信号确定直接分量和间接分量。在一个实例中,在图7中展示的方法700的702处,直接和间接分量可用于确定用于每一麦克风阵列的入射方向。确切地说,可确定第一麦克风信号的第一直接分量和第二麦克风信号的第二直接分量。可基于第一麦克风信号与第二麦克风信号之间的相关性来确定直接分量。第一和第二麦克风信号的直接分量可指示从音频源发射的直接接收的音频信号(而不考虑发射的音频信号的反射且不考虑周围的杂讯)。可随后基于麦克风阵列210、220、230处捕获的麦克风信号的直接分量,尤其基于第一直接分量和第二直接分量来确定麦克风阵列210、220、230处的入射方向211、221、231。通过从麦克风阵列210、220、230的第一麦克风信号和第二麦克风信号提取直接分量,可确定具有增大精确度的在麦克风阵列210、220、230处的入射方向211、221、231。
方法700可包含从麦克风阵列210、220、230的第一麦克风信号确定n个第一子带信号,其中n是n>1的整数(尤其n>5、10,例如n=13)。可在图7中展示的方法700的702处确定n个子带信号。此外,可从麦克风阵列210、220、230的第二麦克风信号确定n个第二子带信号。n个第一子带信号和n个第二子带信号对应于第一麦克风信号和第二麦克风信号的总体频率范围的n个不同子范围。如此,麦克风210、220、230的麦克风信号可分别细分为n个子带信号,其中n个子带信号覆盖麦克风信号的不同频率范围。在一个实例中,总体频率范围可介于0hz到24khz范围内。可使用时域到频域变换,如快速傅里叶变换(fastfouriertransform;fft)或滤波器组来确定子带信号。
n个不同子带可视为对应于n个不同音频源200。如此,在麦克风阵列210、220、230处,可分别基于n个第一子带信号和n个第二子带信号来确定n个不同音频源200的n个入射方向211、221、231。换句话说,可假设由n个不同音频源200发射的n个不同音频信号到达麦克风阵列210、220、230处。可随后分别基于n个第一子带信号和n个第二子带信号来确定由n个音频源200发射的n个音频信号的n个入射方向211、221、231。使用用于k个不同麦克风阵列210、220、230处的各别子带的各别入射方向211、221、231,可以精确方式确定n个不同音频源200的n个位置。
如此,通过使用子带处理,可以精确方式识别不同音频源200。出于此目的,可基于分离子带的第一子带信号和第二子带信号来执行本文献中所描述的处理。换句话说,本文献中所描述的用于第一麦克风信号与第二麦克风信号的集合的处理可由在第一子带信号和第二子带信号的分离集合上执行的处理替换。
可基于两个或更多个(即,k个)麦克风阵列210、220、230的第一麦克风信号和第二麦克风信号(或基于由第一麦克风信号和第二麦克风信号衍生的第一子带信号和第二子带信号)来确定音频源200的方向性图案302。音频源200的方向性图案302可指示由音频源200发射的音频信号的空间方向性。方向性图案302可通过图8中展示的方法800而确定。
通常,音频源200的声压级随着与音频源200的距离d成比例地减小。基于音频源200的位置和k个麦克风阵列210、220、230的位置,可确定k个麦克风阵列210、220、230与音频源200之间的k个距离dk,k=1…k。使用由k个麦克风阵列210、220、230捕获的麦克风信号,可确定音频源200的k个声压级ek。在第k个麦克风阵列210、220、230的方向dk211、221、231上,用于第k个麦克风阵列210、220、230的声压级ek可以认为与由音频源200发射的声音的声压级sk成比例,其中比例因子对应于第k个麦克风阵列210、220、230与音频源200的距离dk。因此,可将在第k个麦克风阵列210、220、230的方向dk211、221、231上的音频源200的声压级sk确定为sk=ek*dk。
可使用于k个麦克风阵列210、220、230的k个方向dk211、221、231的声压级sk,k=1…k标准化。借助于实例,可使用声压级sk的平均值使声压级sk,k=1…k标准化。如下文将概述,可有益地将k个麦克风阵列210、220、230中的单个一个的麦克风信号指派为音频源200的单声道音频信号。借助于实例,可将第一麦克风阵列210、220、230的麦克风信号指派为音频源200的单声道音频信号。如此,可优选地通过s1(通过第一麦克风阵列210、220、230的声压级)使声压级sk,k=1…k标准化,例如,对于k=1…k,gk=sk/s1。(标准化)声压级sk或增益gk指示音频源200的方向性。确切地说,声压级sk或增益gk可以认为是针对不同入射方向dk211、221、231的音频源200的方向性图案的样本点。
可使用多个方向性点310、320、330(如图3中所说明)来描述或说明空间方向性,其中(出于说明的目的)方向性点310、320、330置放在与音频信号200的(先前确定的)位置的不同距离处。方向性点310、320、330可定位在音频源200的位置周围。方向性点310、320、330与音频源200的位置之间的距离可指示从音频源200朝向方向性点310、320、330发射的音频信号的能量有多少。换句话说,方向性点310、320、330与音频源200的位置之间的距离可指示在方向性点310、320、330的方向dk211、221、231上由音频源200发射的声音的声压级sk。如此,更大距离可指示增大的声压级sk(且反之亦然)。因此,音频源200的方向性可由多个样本点310、320、330所描述或说明,所述多个样本点根据由每一麦克风阵列210、220、230从音频源200的估计位置的方向dk211、221、231接收的能量和/或声压级而定位。
方向性点310、320、330(如图3中所说明)的距离可对应于应用于全向、均一音频源的方向相依增益gk。增大的距离可对应于增大的增益,而减小的距离可对应于减小的增益。因此,方向性图案302可限定待应用于全向、均一音频源的方向相依增益gk。应注意,方向性点310、320、330与音频源200的位置的的距离(其用于说明方向性图案302)不同于不同麦克风阵列210、220、230与音频源200的位置的实体距离dk。
音频源200的方向性图案302可用于以增大精确度在收听环境内确定不同收听位置处感知到的声音。
可分别基于两个或更多个麦克风阵列210、220、230的第一麦克风信号和第二麦克风信号来确定用于音频源200的两个或更多个能量或声压级值。换句话说,可分别针对k个麦克风阵列210、220、230处的k个麦克风信号集合来确定k个能量值或声压级值(例如,ek)。可例如基于麦克风信号的(平均)能量或声级来确定麦克风信号集合的能量值或声压级值。可例如使用k个麦克风信号集合的能量或声级(尤其能量或声级的平均值总和)或使用麦克风信号集合中的所选一个的能量或声级来使能量值或声压级值标准化。标准化能量或声压级值可用作方向相依增益以应用于全向、均一音频源。
可随后基于k个入射方向dk211、221、231且基于k个能量值或声压级值(例如声压级ek)来确定音频源200的方向性图案302。此外,可考虑不同麦克风阵列210、220、230与音频源200的估计位置之间的距离dk。确切地说,可确定方向性图案302以使得方向性点310、320、330与音频源200的位置之间的距离(如图3中所说明)指示在方向性点310、320、330的入射方向211、221、231上由音频源200发射的声音的强度或声压级。因此,可以精确和高效方式确定音频源200的方向性图案302。
确定音频源200的方向性图案302可包括分别基于两个或更多个麦克风阵列210、220、230的第一麦克风信号和第二麦克风信号来确定用于两个或更多个麦克风阵列210、220、230的两个或更多个(所捕获)能量值或声压级值ek。确切地说,可分别基于不同麦克风阵列210、220、230的麦克风信号来确定不同麦克风阵列210、220、230处捕获的声音的能量和/或声压级ek。
此外,可分别基于(所捕获)两个或更多个能量值或声压级值ek且基于两个或更多个麦克风阵列210、220、230与音频源200的位置之间的各别距离dk来确定在两个或更多个麦克风阵列210、220、230的入射方向211、221、231上由音频源200发射的声音的两个或更多个能量值或声压级值sk。确切地说,可通过将各别(所捕获)声压级ek乘以各别距离dk来确定由音频源200发射的声音的(所发射)声压级sk。可随后分别基于两个或更多个(所发射)能量值或声压级值sk来确定用于两个或更多个入射方向211、221、231的方向性图案302的样本点310、320、330(其可说明为如图3中所展示的方向性点)。
此外,确定音频源200的方向性图案302可包括使用所指派麦克风阵列210、220、230的能量值或声压级值s1使能量值或声压级值sk标准化。可随后基于两个或更多个标准化能量值或声压级值(例如,sk/s1)来确定用于两个或更多个入射方向211、221、231的方向性图案302的样本点310、320、330。
此外,可使用用于内插在用于两个或更多个入射方向211、221、231的样本点310、320、330之间的内插技术来确定并不位于音频源200的位置与麦克风阵列210、220、230的位置之间的直线上一或多个样本点310、320、330(即,用于除麦克风阵列210、220、230的入射方向211、221、231以外的方向的样本点)。内插技术可利用球面谐波函数301的线性组合。借此,可以高效和精确方式确定完整(三维)方向性图案302。三维方向性图案302可用作方向相依增益(例如以db为单位经缩放)以应用于全向、均一音频源。
如上文所指出,可使用球面谐波函数301的线性组合来估算方向性图案302。可使用优化方法(例如,梯度下降法)来确定球面谐波函数301的最佳组合。确切地说,可确定球面谐波函数301的组合从而最佳拟合已知的方向性样本点310、320、330。借助于实例,可确定且最小化来自样本点310、320、330的球面谐波函数301的组合的平均(平方)偏差以确定球面谐波函数301的最优组合。
因此,确定方向性图案302可包括确定,尤其减小或最小化用于由球面谐波函数301的线性组合估算的两个或更多个入射方向211、221、231的方向性图案302的估算样本点与用于两个或更多个入射方向211、221、231的方向性图案(302)的(实际)样本点310、320、330之间的(有可能平方)距离。
图8展示用于确定音频源的方向性图案(例如,音频源200的方向性图案302)的示范性方法800的流程图。在一个实例中,可根据结合图6所示的块605描述的原理执行方法800。方法800包括在801处确定由k个不同麦克风阵列210、220、230处的音频源200发射的音频信号的能量信息(例如,能量值和/或声压级)。换句话说,可确定关于由k个不同麦克风阵列210、220、230捕获的麦克风信号的能量信息。此外,方法800包括在802处基于能量信息来确定方向性图案302的样本点310、320、330。出于此目的,可如上文所概述使能量信息(例如,能量值和/或声压级)标准化。另外,方法800包括在803处基于样本点310、320、330来确定音频源200的(所估算)方向性图案302。确切地说,可将球面谐波301的总和拟合到样本点310、320、330以确定方向性图案302。
对于k=1…k,增益gk=sk/s1和/或由音频源200的所估算方向性图案302指示的增益可在回放时间期间使用以生成针对由音频源200发射的信号的收听(即再现)信号。这一收听信号可指示位于特定收听位置处的收听者如何感知由音频源200发射的信号。因此,方向性图案302的增益可用于在音频源200周围的不同收听位置处重构由音频源200发射的信号。
如此,方法700可用于确定n个不同音频源200的位置和方向性图案302。此外,方法700可包含确定用于音频源200的音频信号步骤,尤其确定用于n个不同音频源200的n个音频信号的步骤。出于此目的,方法700可包含基于两个或更多个能量值310、320、330将两个或更多个麦克风阵列210、220、230中的一个的第一麦克风信号和/或第二麦克风信号指派到音频源200。确切地说,可将具有最高能量值的麦克风信号集合指派至音频源200。可随后使用麦克风信号的单个集合(尤其具有最高能量值的麦克风信号的集合)来确定由音频信号200发射的音频信号。借此,可将高质量音频信号指派到音频源200。
如上文所概述,可基于子带来执行处理以确定用于n个不同音频源200的位置和/或方向性图案302。以对应方式,可比较子带信号的k个不同集合的能量值以选择用于特定音频源200的子带信号的集合。
可将两个或更多个麦克风阵列210、220、230的第一麦克风信号和第二麦克风信号划分为具有帧持续时间(例如,20ms或更小)的帧序列。可针对来自帧序列的每一帧确定音频源200的位置、方向性图案302和/或音频信号。借此,可以精确方式追踪移动的音频源200。
如上文所概述,可基于两个或更多个麦克风阵列210、220、230的第一麦克风信号和第二麦克风信号来确定由音频源200发射的音频信号。确切地说,方法700可允许仅使用由k个以不同方式定位的麦克风阵列210、220、230捕获的麦克风信号来确定音频源200的位置、方向性图案302和/或音频信号。这一信息可用于生成独立于收听位置的音频表示。可再现这一音频表示以用于三维(3d)环境内的任意收听位置处的收听者。确切地说,音频源200的所确定的音频信号、所确定的位置和/或所确定的方向性图案302可用于确定收听者如何感知由3d环境内的任意收听位置处的音频源200发射的音频信号。因此,提供一种高效和精确的音频表示方案(例如,用于vr应用)。
可从麦克风阵列210、220、230的第一麦克风信号和第二麦克风信号来确定间接分量。音频表示也可包含一或多个麦克风阵列210、220、230的间接分量。为了生成音频表示的这些间接分量,可假设麦克风阵列210、220、230的间接分量起源于与麦克风阵列210、220、230的位置相关联的位置。借助于实例,麦克风阵列210、220、230的间接分量的虚拟源可对应于或可等于麦克风阵列210、220、230的位置。通过考虑间接分量,当生成音频表示时,可改善音频表示的感知质量。
本文献中描述的特征中的任一个可以是用于确定至少一个音频源200的位置的对应系统的部分。所述系统可包括用于执行本文献中概述的方法步骤的处理器。确切地说,系统可经调适以捕获两个或更多个麦克风阵列210、220、230处的第一麦克风信号和第二麦克风信号,其中两个或更多个麦克风阵列210、220、230置放在不同位置处。两个或更多个麦克风阵列210、220、230可至少各自包括用于捕获第一麦克风信号的第一麦克风炭精盒和用于捕获第二麦克风信号的第二麦克风炭精盒。此外,第一麦克风炭精盒和第二麦克风炭精盒可呈现以不同方式定向的空间方向性。
系统可经进一步调适以针对每一麦克风阵列210、220、230且基于各别第一和第二麦克风信号来确定各别麦克风阵列210、220、230处的至少一个音频源200(由所述至少一个音频源发射的声音)的入射方向211、221、231。此外,系统可经调适以基于两个或更多个麦克风阵列210、220、230处的入射方向211、221、231来确定音频源200的位置。
图9展示用于确定音频源200的收听信号的实例方法900的流程图。在一个实例中,可在图6所示的块606之后执行方法900。可针对再现环境内的每一音频源200(例如,针对每一子带)来确定收听信号。音频源信号可由图6所示的方法600的块606提供。可随后通过重叠用于不同音频源200(例如,用于不同子带)的收听信号来确定总体上收听信号。
方法900包括在901处设置或确定用于收听者的虚拟收听者位置。虚拟收听者位置可置于距音频源200的位置某一距离d处。此外,虚拟收听者位置可呈现相对于音频源200的位置的某一虚拟入射方向。方法900进一步包括在902处(例如,使用上述方案)确定用于音频源200的音频信号。举例来说,在902处,来自图6的方法600的核心音频信息可用于确定音频信号。另外,方法900包括在903处基于音频源200的方向性图案302来确定虚拟收听者位置处的收听信号的能量信息。举例来说,在903处,来自图6的方法600的方向性可用于确定能量信息。确切地说,可基于方向性图案302且基于虚拟收听者位置与音频源200的位置的距离d来确定在虚拟收听者位置处由音频源200发射的音频信号的能量值和/或声压级。确切地说,1/d增益可应用于由音频源200发射的音频信号。
此外,方法900包括在904处执行对由音频源发射的单声道音频信号的空间音频处理(例如,立体声处理)。举例来说,在904处,来自图6的方法600的位置可用于执行空间音频处理。出于此目的,可考虑虚拟收听者位置处的音频信号的虚拟入射方向。使用空间音频处理,虚拟收听者位置处的收听者可能能够感知来自虚拟入射方向的收听信号。可随后将由音频源200发射的音频信号的空间化收听信号再现到收听者(例如,与其它音频源200的其它收听信号组合)。方法900可随后输出空间化信号(例如,以立体声或多声道格式)。可将空间化信号格式化以在扬声器或头戴式耳机上的双耳上回放。
本公开中所描述的实施方案的各种修改可以是对所属领域的技术人员显而易见的。在不脱离本发明的精神或范围的情况下,本文中所定义的一般原理可应用于其它实施方案。因此,权力要求书并不希望限于本文中所展示的实施方案,而应符合与本公开、本文中所公开的原理和新颖特征相一致的最广泛范围。
本文献中描述的方法和系统可实施为软件、固件和/或硬件。某些组件可例如实施为在数字信号处理器或微处理器上运行的软件。其它组件可例如实施为硬件和/或实施为专用集成电路。所描述方法和系统中遇到的信号可存储于如随机存取存储器或光学存储媒体的媒体上。所述信号可经由网络传送,如收音机网络、卫星网络、无线网络或有线网络,例如因特网。利用本文献中描述的方法和系统的典型装置是用于存储和/或再现音频信号的便携式电子装置或其它消费者设备。
- 还没有人留言评论。精彩留言会获得点赞!