音频通信系统和方法与流程
本发明属于利用音频通信的人机接口的领域,并且与用于提供免提音频通信的系统和方法有关。
背景
音频通信占据人类交互的一大部分。我们进行电话交谈,听与电视节目相关的音乐或声音,以及接收警报,例如闹钟或微波炉或洗碗机循环的结束。
声学信号的自然波行为和相对长的波长导致声波的大范围扩散,并允许位于共同区域中的人听到声音并感知其上携带的数据。
已知用于允许用户通过声音进行通信同时保持通信的私密性的各种技术。在这些技术之间,最出名的示例包括电话接收机和头戴式耳机或耳机,它们都提供指向用户的一只耳朵或两只耳朵的相对低振幅的声学信号。
由本申请的发明人开发的另外的技术提供从远程位置传输给选定用户的私人声音。在授予给本申请的受让人的wo2014/076707和wo2014/147625中描述了该技术的细节。
更具体地,wo2014/076707公开了一种用于在指定空间位置上生成局部可听声场的系统和方法。根据这种技术,携带预定声音数据的在空间上受限的可听声音在它应该被听到的指定空间位置处局部地产生。甚至更具体地,根据所公开的技术,为了生成携带期望声音数据的局部受限的可听声音,基于声音数据来确定至少两个超声波束的频率内容,并且至少两个超声波束的频率内容是由声换能器系统(例如,包括多个超声波换能器元件的布置的换能器系统)传输的。然后,空间上受限的可听声音由至少两个超声波束在指定位置处产生。例如,所述至少两个超声波束包括至少一个主音频调制超声波束,其频率内容包括至少两个超声波频率分量和一个或更多个附加超声波束,所述至少两个超声波频率分量被选择为在非线性介质中经历非线性相互作用后产生可听声音,每个附加超声波束包括一个或更多个超声波频率分量。指示指定位置的位置数据用于确定分别关于至少两个超声波束的至少两个焦点,使得将至少两个超声波束聚焦在至少两个焦点上实现生成在指定空间位置附近具有可听声音的局部声场。
也授予给本申请的受让人的wo2014/147625描述了一种换能器系统,其包括具有一个或更多个压电使能箔/片/层的面板和耦合到面板的电触头的布置。电触头被配置成限定在面板中的多个换能器。每个换能器与面板的相应区域以及与耦合到在面板的相应区域处的至少两个区域处的至少两个电触头相关联。电触头适于在这至少两个区域中提供电场,以引起在这至少两个区域中的不同程度的压电材料变形,并从而使面板的相应区域在实质上垂直于面板的表面的方向上变形,并从而实现电信号到机械振动(声波)的有效转换,和/或反之亦然。本发明的换能器可以被配置成和可操作来产生可用于产生上面讨论的wo2014/076707中公开的空间上受限的可听声音的至少两个超声波束。
总体描述
在本领域中存在对能够管理指向位于特定空间内的选定的一个或更多个用户的私人声音(即,向选定用户提供声音,从而由用户私密地消费/听到)的新颖的系统和方法的需要。本发明的技术利用与一个或更多个换能器单元相关联的一个或更多个三维传感器模块(tdsm),其用于确定用户的位置并确定适当的声音轨迹以用于向选定用户传输私人声音信号,同时消除或至少显著减少声音信号对可能位于相同空间中的其他用户的干扰。
关于这一点,应当注意,三维传感器模块可以或者可以不被配置用于当以单个模块操作时提供三维感测数据。更具体地,本发明的技术利用布置在感兴趣区域中的一个或更多个传感器模块,并分析和处理因此接收到的感测数据以确定三维数据。为此目的,tdsm单元可以包括可选地关联/包括扩散ir发射器的相机单元(例如,若干相机单元的阵列/布置),并且附加地或可选地可以包括可操作来感测指示感测体积的三维布置/内容的三维数据的其他类型的感测模块。
本发明的技术利用适合于布置在空间(例如公寓、房屋、办公楼、公共空间、车辆内部等,并安装在墙壁、天花板上或立在架子或其它表面上)中并被配置成且可操作来向一个或更多个选定用户提供私人(例如局部受限)可听声音(例如语音通信)的一个或更多个换能器单元(换能器阵列)。
例如,在本发明的一些实现方式中,一个或更多个换能器单元(例如在授予给本申请的受让人的wo2014/147625中公开的换能器单元)被包括在本发明的系统中/与本发明的系统相关联,并且被配置成生成定向的且通常聚焦的声学信号,从而在距换能器单元的选定距离内的空间中的选定点(受限区域)处产生可听声音。
为此目的,在本发明的一些实施例中,一个或更多个换能器单元被配置成选择性地传输在两个或更多个超声波频率范围处的声学信号,使得超声波信号解调以在选定位置处形成可听信号频率。所传输的超声波信号被聚焦到期望位置,在该期望位置中在声波之间的相互作用导致自解调生成在可听频率处的声波。如在关于用于生成私人声音区域的技术的授予给本申请的受让人的并通过引用被并入本文的专利公开wo2014/076707中所述的,根据输出超声波信号的选定振幅、波束形状和频率来确定接收位置/目标位置和所生成的可听信号。
本技术利用与一个或更多个三维传感器模块(tdsm)和一个或更多个麦克风单元组合的这样的一个或更多个换能器单元,其都可连接到一个或更多个处理单元以提供形成免提音频通信系统的附加管理功能。更具体地,本发明的技术基于生成选定空间的三维模型,并且使位于所述空间中的一个或更多个用户能够私密地且在不需要主动与控制面板或手持设备联系的情况下发起音频通信会话和对音频通信会话做出响应。
关于这一点,本发明可以提供各种类型的通信会话,包括但不限于:与一个或更多个其他用户的本地和/或远程通信、从外部系统/设备接收通知、向一个或更多个外部设备提供语音指令/命令、向系统提供内部操作命令(例如权限管理、音量改变、添加用户身份等)、从本地或远程系统提供信息和广告活动(例如,针对特定用户的用于做广告的公共空间信息、关于博物馆藏品的信息、入耳翻译等)。本发明的技术还可以提供关于用户对所传输的数据的接收的指示,如下面在本文描述的。这样的数据可以被进一步处理以确定广告活动、父母控制等的有效性。
为此目的,可以使用可连接到一个或更多个换能器单元和一个或更多个tdsm以及一个或更多个麦克风单元的集中式或分散式(例如分布式)处理单元(在本文也被称为控制单元或音频服务器系统)或者以提供均包括换能器单元、tdsm单元、麦克风单元和特定处理能力的一个或更多个音频通信系统的分布式管理的形式来实现本技术,其中不同的音频通信系统被配置成在它们之间通信,从而向大于单个换能器单元的覆盖区域的区域或者在断开连接的区域(例如,由墙壁间隔开的不同房间)中提供音频通信。
被配置成用于集中式或分布式管理的处理器被配置成接收关于一个或更多个tdsm所位于的空间的三维配置的数据(例如,感测数据)。基于至少最初的所接收的感测数据,处理器可以被配置成和可操作来生成空间的三维(3d)模型。3d模型通常包括关于在空间内的静止物体的布置的数据,从而确定与一个或更多个换能器单元相关联的一个或更多个覆盖区域。因此,当一个或更多个tdsm提供指示用户位于空间中的特定位置上的数据时,通信会话(远程地发起的或由用户发起的)使用被选择为向用户的位置提供最佳覆盖的换能器单元来私密地进行。
可选地或附加地,该技术可以利用用于基于来自一个或更多个tdsm单元的输入数据和关于换能器阵列单元的覆盖区域的相对布置和tdsm单元的感测体积的数据来定位和识别用户在感兴趣区域内的存在和位置的图像处理技术。应当理解,通常可以对系统执行初始校准。这种初始校准通常包括在被使用时提供关于不同换能器阵列单元、tdsm单元和麦克风单元、以及任何其他所连接的元件(例如扬声器)的数量、安装位置和相应覆盖区域的数据。可以如上所述以生成3d模型的形式自动地或者通过提供关于感兴趣区域的布置以及换能器阵列单元、tdsm单元和麦克风单元的安装位置的数据来手动地完成这种校准。
应当注意,一个或更多个tdsm可以包括一个或更多个相机单元、三维相机单元或任何其他合适的成像系统。另外,一个或更多个换能器单元还可以被配置成用超声波束周期性扫描覆盖区域,并且基于检测到的反射来确定覆盖区域的映射。因此,一个或更多个换能器单元可以作为声纳来操作以提供额外的映射数据。这种基于声纳的映射数据可以包括关于表面的反射特性及其空间布置的数据。
另外,一个或更多个麦克风单元可以被配置为麦克风阵列单元,并且可操作来提供从相应的收集区域(例如,感测体积)收集的输入声音可听数据。一个或更多个麦克风单元可以包括实现可听数据的收集并提供指示所收集的声学信号源自的方向的数据的麦克风元件的阵列。可以基于在由阵列的不同麦克风元件收集的信号部分之间的相位或时间变化来确定所收集的声音方向数据。可选地,麦克风单元可以包括被配置为从在感测区域内的不同方向收集声学信号的一个或更多个定向麦克风元件。在这种配置中,可以基于所收集的振幅的变化以及时间延迟和/或相位变化来确定到所检测的信号的原点方向。
通常,音频通信会话可以是单边的或双边的。更具体地,单边通信会话可以包括被发送给用户的可听通知,例如关于新电子邮件的通知、洗衣机完成循环的通知等。用户的双边音频通信会话通常包括音频对话,在该音频对话期间,可听数据被传输给用户并从用户接收。这种通信会话可以包括与第三方的电话对话、用户发起的请求系统执行一个或更多个任务的命令等。
此外,该系统可用在多个断开连接的远程感兴趣区域中,提供在两个或更多个远程空间之间的私人通信。为此目的,如下面在本文所述的,感兴趣区域可以包括一个或更多个所连接的空间和附加的一个或更多个断开连接的/远程位置,实现在用户之间的私人和免提通信而不管在他们之间的物理距离如何,而不是与和在远程位置之间的数据的传输相关联的可能的时间延迟有关。
本发明的技术还可以提供与单边通信会话以及关于其成功相关联的指示。更具体地,本技术利用从一个或更多个tdsm接收的指示用户在接收输入通知的时间段的运动和/或反应的感测数据,并确定用户是否实际上注意到该通知的特定概率。这种响应可以与身体运动的面部、语音或可以使用与系统相关联的输入设备检测到的任何其他响应相关联。
如上面所指示的,系统被使用于的空间的3d模型可以包括与一个或更多个换能器单元相关联的一个或更多个不重叠或部分重叠的覆盖区域。此外,本技术允许用户在区域之间四处移动时保持通信会话。为此目的,该系统被配置为从一个或更多个tdsm接收感测数据,并用于处理感测数据以提供关于一个或更多个选定用户(例如当前参与通信会话的用户)的位置的周期性指示。
此外,为了提供私人声音,一个或更多个换能器单元优选地被配置和操作成在相对小的焦点内生成可听声音。这形成相对小的区域,其中所生成的声波是可听见的,即可听见的频率和足够的声压级(spl)。亮区域或可听区域可以例如具有大约30cm的半径,而在该区域之外,声学信号通常足够低以防止由其他人广泛听到。因此,音频通信系统还可以被配置为处理输入感测数据以定位选定用户并识别用户的头部和耳朵的位置和方位以确定用于生成可听(私人)声音区域的位置。基于该系统被使用到的空间的3d模型,该处理可以包括确定在选定换能器单元和用户的耳朵中的至少一只耳朵之间的视线。在没有直接视线被确定的情况下,可以使用不同的换能器单元。可选地,空间的3d模型可用于利用来自一个或更多个反射表面(例如墙壁)的声音反射来确定视线。当一个或更多个换能器单元用作声纳式映射设备时,关于表面的声反射的数据可用于确定最佳间接视线。另外,为了提供有效的声学性能,当沿着间接视线向用户传输声学信号时,本技术可以利用振幅调节。
在这一点上,还应该注意到,在系统被配置成分别与用户的两只耳朵接合的情况/实施例中,振幅调节和平衡也被执行用于平衡在两只耳朵之间的音量(特别是在耳朵在到为它们服务的换能器单元的不同距离处的情况下)。
关于这一点,上面所述的技术和系统能够通过采用多个换能器阵列单元和相对应的tdsm单元和麦克风单元来提供在感兴趣区域(roi)内的音频通信。该技术实现到一个或更多个用户的音频私人通信,以用于在他们之间或与外部链路进行通信,使得只有某个信号的接收方用户接收可听和可理解的声学信号,而例如位于离接收方低至50厘米的距离处的其他用户将不能够完全接收该信号。
此外,本发明的技术提供了确定接收方的位置,以用于向其直接和准确地传输聚焦的声学信号。该技术还提供了周期性地定位选定用户,例如被标记为在正在进行通信会话的用户,从而允许系统即使用户在空间中移动时也跟踪用户并保持通信会话。为此目的,该技术提供了根据用户位置和方位连续地选择优选的换能器阵列单元以用于向用户进行信号传输。该系统和技术因而使用户能够在roi内的不同的部分地连接的空间(例如房间)之间移动同时保持正在进行的通信会话。
因此,根据本发明的一个广泛方面,提供了一种用于在音频通信中使用的系统。该系统包括:
-一个或更多个(例如多个)换能器单元,其位于多个位点中,用于覆盖所述位点中的相应覆盖区域。位点可以是不同的空间和/或音频服务应由系统提供到的感兴趣区域(roi)。换能器单元(例如它们中的至少一些)能够发射在一个或更多个通用频率中的超声波信号,以用于在它们的相应覆盖区域内的选定空间位置处形成局部可听声场;换能器单元可以包括换能器元件的阵列。
-一个或更多个(例如多个)三维传感器模块(tdsm;在本文也被称为三维输入设备,例如3d相机、雷达、声纳、lidar),其被配置为提供关于在输入设备的视场内的周围事物的三维布置的数据。tdsm适于位于将由系统覆盖的位点(空间)中,并且每个三维传感器模块被配置成和可操作来提供关于在位点内的相应感测体积中的元件的三维布置的感测数据。
-映射模块,其提供分别指示在所述tdsm的感测体积和换能器单元的覆盖区域之间的关系的映射数据。
-用户检测模块,其可连接到所述一个或更多个三维传感器模块以用于从其接收所述感测数据,并被配置成和可操作来处理所述感测数据以确定至少一个用户在tdsm的感测体积内的空间位置。以及
-输出声音发生器(在本文也被称为声音处理设施),其可连接到所述一个或更多个换能器单元,并适于接收指示要被传输到所述至少一个用户的声音的声音数据,并且被配置成和可操作来用于操作至少一个选定换能器单元,以用于生成携带所述声音数据的靠近所述至少一个用户的局部声场,其中,所述输出声音发生器利用映射数据来根据关于所述至少一个用户的空间位置的所述数据而确定所述至少一个选定换能器单元,使得所述选定换能器单元的相应覆盖区域包括所述至少一个用户的所述位置。
在一些实施例中,该系统包括音频会话管理器(例如,包括输入和输出通信设施),其被配置成经由一个或更多个通信网络实现与远程方的通信;以及至少一个声音处理设施。所述至少一个处理器设施包括:感兴趣区域(roi)映射模块,其被配置成和可操作来从3d输入设备接收视场的三维输入并生成roi的3d模型;用户检测模块,其被配置成和可操作来从3d输入设备接收视场的三维输入,并确定在感兴趣区域内的一个或更多个人的存在和位置。处理器单元被配置成用于生成语音数据并且用于操作至少一个换能器单元以传输合适的信号,以用于在靠近选定用户的耳朵处生成局部声场,从而实现与用户的私人通信。
该系统还可以包括可连接到一个或更多个麦克风单元的接收声音分析器,该接收声音分析器被配置用于从roi接收音频输入并且适于确定指示所述音频信号在roi内的起源的位置的数据。
附加地或可选地,该系统可以包括或可连接到一个或更多个扬声器,以用于提供可以被多个用户公开听到的音频输出。此外,该系统还可以包括被配置成和可操作来向用户提供一个或更多个图像或视频的显示的一个或更多个显示单元。
应当注意,系统可以利用关于用户位置的数据,用于对一个或更多个换能器单元的选择以向用户提供局部私人音频数据。类似地,当扬声器和/或显示单元被使用时,系统可以利用关于一个或更多个选定用户的位置的数据以确定一个或更多个选定扬声器和/或显示单元,以用于向用户提供相对应的数据。
根据一些实施例,处理单元还可以包括手势检测模块,该手势检测模块被配置成和可操作来从音频输入位置模块接收输入音频信号及其位置,并且确定所述输入音频信号是否包括请求过程或通信会话的发起的一个或更多个关键词。
处理单元还可以包括方位检测模块。方位检测模块可以被配置成和可操作来接收关于感兴趣区域的所述3d模型的数据和关于至少一个用户的位置的数据,并且确定至少一个用户的耳朵相对于系统的方位,从而生成至少一个用户的耳朵中的至少一个是否在与至少一个换能器单元的视线内的指示。
根据一些实施例,处理器单元还可以包括换能器选择器模块,该换能器选择器模块被配置成和可操作来接收指示至少一个用户的头部或耳朵中的至少一个是否在至少一个换能器单元的视线内的数据并且用于确定到用户的耳朵的声音传输的优化轨迹。优化轨迹可以利用下列操作中的至少一个:将局部声音区域指向在至少一个换能器单元的视线内同时在距隐藏的用户的耳朵的预定范围内的点;以及接收和处理关于感兴趣区域的3d模型的数据以确定包括从在感兴趣区域内的一个或更多个壁朝着隐藏的用户的耳朵的一个或更多个反射的声音轨迹。
根据一些实施例,处理单元可以被配置成和可操作来与一个或更多个通信系统通信,所述一个或更多个通信系统被布置成形成连续的视场以从而提供与用户的连续音频通信,同时允许用户在大于系统的视场的预定空间内移动。此外,通信系统可以在一个或更多个断开连接的区域内被使用,提供与一个或更多个远程位置的无缝音频通信。
根据一些实施例,处理单元可以被配置成和可操作来提供下列通信方案中的一个或更多个通信方案:
-管理和进行远程音频对话,处理单元被配置成和可操作来通过通信网络与远程音频源通信,以从而实现双边通信(例如电话对话);
-响应于通过所述通信网络从一个或更多个相关系统接收的一个或更多个输入警报而提供语音指示;
-响应于来自用户的一个或更多个语音命令而生成相对应的命令,并通过通信网络将所述相对应的命令传输到选定的一个或更多个相关系统,从而实现用于由一个或更多个相关系统执行一个或更多个任务的语音控制。
根据又一些实施例,处理单元还可以包括手势检测模块,该手势检测模块被配置成和可操作来从用户检测模块接收关于用户位置的数据,并且识别一个或更多个预定手势是否被用户执行,在检测到所述一个或更多个预定手势时,手势检测模块生成相对应的命令并向处理单元传输相对应的命令以用于执行一个或更多个相对应的动作。
该系统还可以包括面部识别模块,该面部识别模块被配置成和可操作来从三维输入设备接收输入数据并用于定位和识别在roi内的一个或更多个用户,该系统还包括许可选择器模块,该许可选择器模块包括所识别的用户和所述用户具有使用许可的动作的列表的数据库,该许可选择器模块接收关于用户的身份的数据和关于由所述用户进行的所请求的动作的数据,并提供指示所述用户是否具有对执行所述请求的动作的许可的处理单元数据。
根据本发明的另一个广泛方面,提供了一种用于在音频通信中使用的系统。该系统包括:一个或更多个换能器单元,其位于多个物理位置上,以用于覆盖相应的覆盖区域,其中所述换能器单元能够发射处于一个或更多个频率的超声波信号,以用于在其相应覆盖区域内的选定空间位置处形成局部可听声场;一个或更多个三维传感器模块(tdsm)(例如,3d相机、雷达、声纳、lidar),其位于所述位点上,其中每个三维传感器模块被配置成和可操作来提供关于元件在所述位点内的相应感测体积中的三维布置的感测数据;映射模块,其提供指示在感测体积和覆盖区域之间的关系的映射数据;用户检测模块,其可连接到所述一个或更多个三维传感器模块以用于从其接收所述感测数据,并被配置成和可操作来处理所述感测数据以确定至少一个用户的耳朵在三维传感器模块的感测体积内的空间位置;以及声音处理器设施,其可连接到所述一个或更多个换能器单元,并适于接收指示要被传输到所述至少一个用户的耳朵的声音的声音数据,并被配置成和可操作来操作至少一个选定换能器单元,以用于在靠近所述至少一个用户的耳朵处生成携带所述声音数据的局部声场,其中所述输出声音发生器利用映射数据以根据从相对应的用户检测模块接收的关于至少一个用户的耳朵的空间位置的所述数据来确定所述至少一个选定换能器单元,使得所述选定换能器单元的相应覆盖区域包括所述至少一个用户的耳朵的所述位置。
一个或更多个换能器单元优选地能够发射处于一个或更多个频率的超声波信号,以用于在它的相应覆盖区域内的选定空间位置处形成局部聚焦解调可听声场。
该系统通常可以包括被配置为处理从所述位点接收的输入音频信号的接收声音分析器。此外,该系统可以包括适用于处理所述输入音频信号以确定指示所述音频信号在所述位点内的起源的位置的数据的音频输入位置模块。接收声音分析器可以连接到可操作来从位点接收音频输入的一个或更多个麦克风单元。
根据一些实施例,该系统可以包括或可连接到一个或更多个扬声器和/或一个或更多个显示单元,以用于向用户提供公共音频数据和/或显示数据。通常,系统可以利用关于一个或更多个用户的位置的数据以用于根据用户位置来选择适用于提供期望输出数据的扬声器和/或显示单元。
根据一些实施例,用户检测模块还可以包括手势检测模块,该手势检测模块被配置成和可操作来处理包括来自所述一个或更多个tdsm的输入数据和所述输入音频信号中的至少一个,确定所述输入数据是否包括与系统的一个或更多个操作相关联的一个或更多个触发器,所述声音处理器设施被配置为将输入数据的起源的位置确定为与系统的所述操作相关联的用户的初始位置。所述一个或更多个命令可以包括用于发起音频通信会话的请求。输入数据可以包括由接收声音分析器接收的音频输入数据和由tdsm接收的运动模式输入数据中的至少一个。更具体地,手势检测模块可以被配置为检测语音和/或运动手势。
根据一些实施例,用户检测模块可以包括适于处理所述感测数据以确定所述用户的头部位置和方位并从而估计至少一个用户的耳朵的所述位置的方位检测模块。
根据一些实施例,用户检测模块包括适于处理感测数据以确定用户的至少一只耳朵的位置的面部识别模块。输出声音发生器被配置成和可操作来确定来自至少一个选定换能器单元的声场传播路径,以用于为用户生成局部声场,使得局部声场包括靠近用户的至少一只耳朵的受限声音气泡(aconfinedsoundbubble)。
例如,面部识别模块可以被配置成和可操作来基于用户的头部的人体测量模型来确定用户的至少一只耳朵的所述位置。在一些情况下,面部识别模块被配置成并可操作来基于从tdsm接收的所述感测数据来进行下列中的至少一个:构建用户的头部的所述人体测量模型和更新用户的头部的所述人体测量模型。
在一些实施例中,面部识别模块适于处理感测数据以确定用户的两只耳朵的位置,并且其中所述输出声音发生器被配置成和可操作来分别确定从所述至少一个选定换能器单元朝着用户的所述两只耳朵的两个声场传播路径,并且生成所述局部声场,使得它包括分别定位成靠近用户的所述两只耳朵的两个受限声音气泡,从而向所述用户提供私人双耳(例如立体声)可听声音。
在一些实施例中,输出声音发生器被配置成和可操作来确定沿着两个传播路径到用户的两只耳朵的声场传播的相应相对衰减,并基于所述相对衰减来使指向用户的两只耳朵的相应声场的音量均衡,从而向所述用户提供平衡的双耳可听声音。
根据一些实施例,用户检测模块还被配置成和可操作来处理接收到的感测数据,并根据接收到的感测数据来区分开一个或更多个用户的身份,用户检测模块由此提供指示在三维传感器模块的一个或更多个感测体积内的一个或更多个用户的空间位置和身份的数据。
该系统还可以包括面部识别模块。面部识别模块通常适用于从用户检测模块接收关于用户位置的数据,并且用于从tdsm接收与所述用户位置相关联的感测数据的至少一部分,并且被配置成和可操作来用于应用面部识别以确定指示所述用户的身份的数据。在一些配置中,系统还可以包括特权模块。特权模块可以包括或利用所识别的用户和所述用户具有使用许可的动作的列表的数据库。通常,特权模块从所述面部识别模块接收指示用户的身份的所述数据和关于由所述用户进行的所请求的动作的数据,并且提供指示所述用户是否具有对执行所述请求的动作的许可的处理单元数据。
根据一些实施例,声音处理器设施可以适于将视线处理应用于所述映射数据以确定在各自的所述换能器单元和用户的耳朵的所述位置之间的声音轨迹,以及处理声音轨迹以确定具有用于到用户的耳朵的声音传输的最佳轨迹的至少一个换能器单元,并且将所述至少一个换能器单元设置为选定换能器单元。这样的优化轨迹可以被确定成使得其满足下列情况中的至少一个:其沿着在所述选定换能器单元和用户的耳朵之间的无障碍视线通过,同时不超过距用户的耳朵的特定第一预定距离;其沿着第一视线从所述换能器单元和所述位点中的声反射元件以及从所述声反射元件到所述用户的耳朵通过,同时不超过第二预定距离。
根据一些实施例,声音处理器设施利用两个或更多个换能器单元来实现优化轨迹,使得至少一个换能器单元具有到用户的耳朵之一的无障碍视线,并且至少一个其它换能器单元具有到用户的第二耳朵的无障碍视线。
根据一些实施例,声音处理器设施可以适于进行以下操作:将所述视线处理应用于所述映射数据以确定至少一个换能器单元,对于所述至少一个换能器单元在所述至少一个换能器单元的覆盖区域内存在到用户的耳朵的所述位置的无障碍炮目线;以及将所述至少一个换能器单元设置为选定换能器单元并且沿着所述炮目线设置所述轨迹。
在所述换能器单元和用户的耳朵的所述位置之间的炮目线有障碍的情况下,所述炮目线处理可以包括处理感测数据以识别在所述用户的附近的声反射元件;确定所述选定换能器单元使得来自所述选定换能器单元的所述轨迹沿着来自所述选定换能器单元和所述声反射元件的炮目线通过,并且从此处沿着炮目线到达用户的耳朵。
输出声音发生器被配置成并可操作来监测用户的耳朵的位置以跟踪所述位置的变化,并且其中在检测到所述位置的变化时执行所述炮目线处理以更新所述选定换能器单元,从而提供与用户的连续音频通信同时允许用户在所述位点内移动。声音处理器设施可以适于处理所述感测数据以确定沿着在选定换能器单元和所述用户的耳朵之间的所述传播路径的距离,以及根据所述距离来调节由选定换能器单元生成的所述局部声场的强度。在声反射元件存在于选定换能器单元和用户的耳朵之间的轨迹中的情况下,所述处理设施可以适于调节所述强度以补偿所述声反射元件的所估计的声吸收特性。此外,在声反射元件存在于所述传播路径中的情况下,所述处理设施可以适于根据指示所述声反射元件的声谱吸收分布的所述所估计的声吸收特性来使所述超声波信号的谱内容强度均衡。
通常,声音处理器设施可以适于处理所输入的感测数据以确定所述声反射元件的类型(例如桌子、窗户、墙壁等)并基于所述类型来估计所述声吸收特性。
声音处理器设施还可以被配置为根据存储在相对应的存储设施中并对所述声音处理器设施可访问的关于表面类型的数据来确定一个或更多个声音反射表面的类型。
根据一些实施例,该系统可以包括可连接到所述输出声音发生器并且被配置成和可操作来操作所述输出声音发生器以向所述用户提供通信服务的通信系统。该系统可以被配置成和可操作来提供下列通信方案中的一个或更多个通信方案:
-管理和进行远程音频对话,通信系统被配置成和可操作来通过通信网络与远程音频源通信,从而实现双边通信(例如电话对话);
-管理和进行在感兴趣区域内的两个或更多个用户之间的无缝局部私人音频通信;
-处理输入音频数据并向一个或更多个选定用户生成相对应的输出音频数据;
-响应于通过所述通信网络从一个或更多个相关系统接收到的一个或更多个输入警报而提供语音指示;以及
-响应于来自用户的一个或更多个语音命令,而生成相对应的命令,并通过通信网络将所述相对应的命令传输到选定的一个或更多个相关系统,从而实现用于由一个或更多个相关系统执行一个或更多个任务的语音控制。
系统1000可以包括手势检测模块,该手势检测模块被配置成和可操作来从用户检测模块接收关于用户位置的数据,并且可连接到所述三维传感器模块以用于从其接收与所述用户位置相关联的感测数据的至少一部分;所述手势检测适于将手势识别处理应用于感测数据的所述至少一部分,以识别一个或更多个预定手势是否由用户执行,在检测到所述一个或更多个预定手势时,手势检测模块生成并传输用于操作所述通信系统的相对应的命令以用于执行一个或更多个相对应的动作。
根据一些实施例,该系统还可以包括适用于从所述通信系统接收指示感兴趣可听内容向所述用户的耳朵的传输的触发信号的用户响应检测模块;并且其中,所述用户响应检测模块适用于从用户检测模块接收关于用户位置的数据,并且适用于从三维传感器模块接收与所述用户位置相关联的感测数据的至少一部分,并且被配置成和可操作来响应于所述触发信号来处理感测数据的所述至少一部分,以确定指示所述用户对所述感兴趣可听内容的响应的响应数据。响应数据可以被记录在所述通信系统的存储设施中或者被上传到服务器系统。
所主张的系统可以与分析服务器相关联,分析服务器被配置成和可操作来从所述系统接收与所述感兴趣内容相关联的所述响应数据,并且处理从多个用户响应于所述感兴趣内容而提供的所述统计响应数据,以确定用户对所述感兴趣内容的反应的参数。
通常,所述感兴趣内容可以包括商业广告,并且其中所述通信系统与提供所述感兴趣内容的广告服务器相关联。
根据本发明的另一个广泛方面,提供了一种语音网络系统,其包括服务器单元和如上所述的被布置在用于以部分重叠的方式覆盖一个或更多个roi的空间中的一个或更多个局部音频通信系统;服务器系统通过通信网络连接到一个或更多个局部音频通信系统,并且被配置成和可操作来对来自任何局部音频通信系统的用户生成的输入消息做出响应,并且响应于一个或更多个预定条件而选择性地定位在所述一个或更多个roi内的期望用户以及选择性地向所述期望用户传输语音通信信号。
根据本发明的又一个广泛方面,提供了一种在管理个人语音通信网络时使用的服务器系统;该服务器系统包括:音频会话管理器,其被配置为连接到通信网络和一个或更多个局部音频系统;映射模块,其被配置成和可操作来从一个或更多个局部音频系统接收关于3d模型的数据,并生成由所述一个或更多个局部音频系统覆盖的组合感兴趣区域(roi)的组合3d地图;用户位置模块,其被配置成和可操作来从一个或更多个局部音频系统接收关于一个或更多个用户的位置的数据并用于确定期望用户在组合roi内的位置和具有与用户的合适视线的相对应的局部音频系统。服务器系统被配置成和可操作来对指示要传输给选定用户的一个或更多个消息的数据做出响应。响应于这样的数据,服务器系统从用户位置模块接收关于用户的位置和关于合适的局部音频系统的数据,以用于与所述用户通信并将关于所述一个或更多个消息的数据传输到相对应的局部音频系统以向用户提供语音指示。
用户位置模块可以被配置成周期性地定位选定用户和相对应的局部音频系统,并且对用户的位置或方位的变化做出响应,从而改变与局部音频系统的关联以提供与用户的无缝和连续的语音通信。
根据本发明的又一个广泛方面,提供了一种用于在音频通信中使用的方法,该方法包括:提供关于要传输给选定用户的一个或更多个信号的数据,提供与感兴趣区域相关联的感测数据,处理所述感测数据以用于确定选定用户在感兴趣区域内的存在和位置,选择位于感兴趣区域内的一个或更多个合适的换能器单元,并且操作选定的一个或更多个换能器元件以将声学信号传输到用户的所确定的位置,从而向所述选定用户提供携带所述一个或更多个信号的局部可听区域。
根据本发明的又一广泛方面,提供了一种方法,其包括:向用户传输预定声音信号,并收集指示用户对所述预定声音信号的响应的感测数据,从而生成指示所述用户对所述预定声音信号的反应的数据,其中,所述传输包括生成在两个或更多个预定频率范围内的超声波场,所述超声波场被配置为在根据所述用户的物理位置确定的距离处相互作用,从而形成提供所述预定声音信号的局部声场。
根据本发明的另一广泛方面,提供了一种用于在音频通信中使用的系统。该系统包括:
-至少一个换能器单元,其适用于在至少一个位点的至少一个相应覆盖区域内的选定空间位置处形成局部可听声场;
-至少一个三维传感器模块(tdsm),其被配置成并可操作来提供关于在至少一个位点内的相应感测体积中的元件的三维布置的感测数据;
-用户检测模块,其可连接到一个或更多个三维传感器模块以用于从其接收感测数据,并被配置成和可操作来处理感测数据以确定至少一个用户在至少一个位点内的空间位置;
-面部识别模块,其适于处理感测数据以确定用户的至少一只耳朵的位置;以及
-输出声音发生器,其可连接到一个或更多个换能器单元,并适于接收指示要被传输到至少一个用户的声音的声音数据,并且被配置成和可操作用于确定来自所述至少一个换能器单元的声场传播路径以用于生成包括靠近用户的至少一只耳朵的受限声音气泡的局部声场,并且用于操作至少一个换能器单元用于产生局部声场。
根据本发明的又一个广泛方面,提供了一种用于在音频通信中使用的方法,该方法包括:提供关于要被传输给选定用户的一个或更多个信号的数据;提供与感兴趣区域相关联的感测数据;处理感测数据以确定用户在感兴趣区域内的选定的存在,并确定在感兴趣区域内的用户的至少一只耳朵的位置;以及选择和操作位于感兴趣区域内的一个或更多个合适的换能器单元以将声学信号传输到用户的至少一只耳朵的所确定的位置。
在一些实现方式中,基于用户的头部的人体测量模型来确定用户的至少一只耳朵的位置。在一些情况下,人体测量模型基于感测数据进行构造和更新中的至少一项。
在一些实施例中,该方法/系统被配置成和可操作包括以下项:处理感测数据以确定用户的两只耳朵的位置;确定从选定的一个或更多个换能器单元分别朝着用户的两只耳朵的两个声场传播路径;以及操作选定换能器单元以沿着两个相应的声场传播路径将声学信号传输到两只耳朵的所确定的位置。在一些情况下,该方法还包括确定沿着两个传播路径到用户的两只耳朵的声场传播的相应相对衰减,并基于相对衰减来使指向用户的两只耳朵的相应声场的音量均衡,从而向用户提供平衡的双耳可听声音。
附图简述
为了更好地理解本文公开的主题并且为了例示其可以如何在实践中被执行,现在将仅仅作为非限制性示例参考附图描述实施例,在附图中:
图1a至图1c示意性示出了根据本发明的一些实施例的音频通信系统,其中图1a是音频通信系统的框图,图1b示意性示出了音频通信系统的部署,以及图1c示出了音频通信系统的终端单元的框图;
图2示出了根据本发明的一些实施例的利用中央控制单元的音频通信系统的附加示例;
图3例示了适合于用在根据本发明的一些实施例的音频通信系统中的私人通信的终端单元;
图4a是示出根据本发明的实施例被执行用于朝着用户传输局部(受限)声场的方法的流程图。
图4b和图4c是分别在用户的头部和耳朵附近生成的局部(受限)声场的示意图;
图4d是根据本发明的实施例的用于确定用户的耳朵的位置的方法的流程图;
图5例示了根据本发明的一些实施例的音频通信系统在感兴趣区域中的部署;
图6示意性示出了根据本发明的一些实施例的音频通信服务器/控制单元;
图7例示了根据本发明的一些实施例的用于向用户传输声学信号的操作的方法;
图8例示了根据本发明的一些实施例的用于保持移动用户的正在进行的通信的操作的方法;
图9例示了根据本发明的一些实施例的用于对用户发起的请求做出响应的操作的方法;以及
图10例示了根据本发明的一些实施例的用于确定用户对所传输的声学信号的响应的操作的方法。
具体实施方式
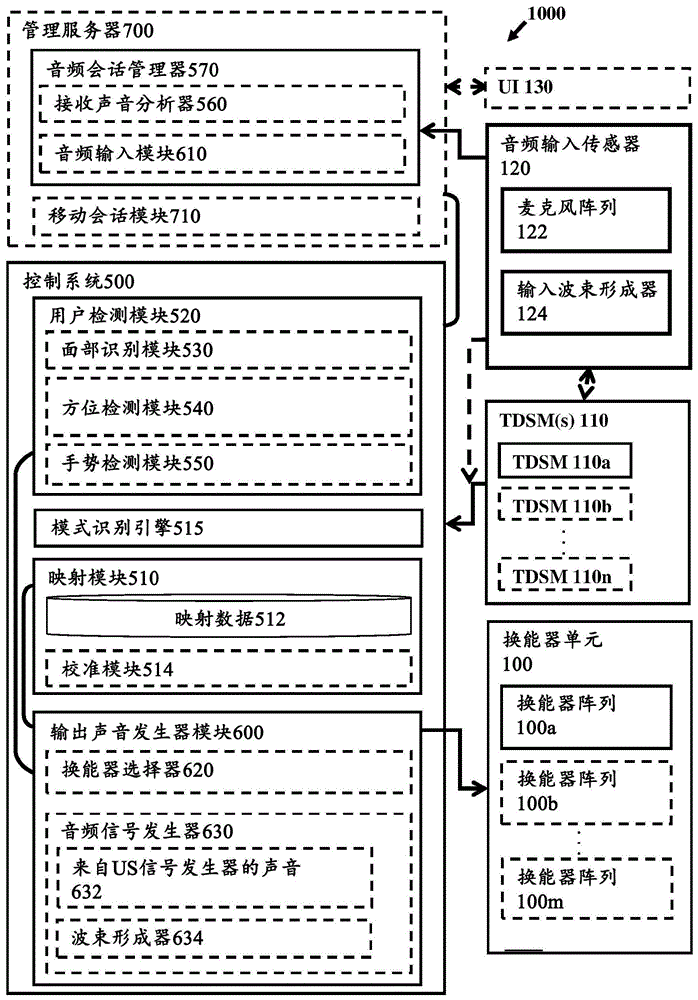
如上面所指示的,本发明提供了一种用于在空间内提供私人和免提可听通信的系统和方法。一起对图1a至图1c进行参考,其中图1a至图1c,其中图1a是根据本发明的实施例的音频通信系统1000的框图,图1b示意性示出了音频通信系统1000的示例性部署,以及图1c是例示根据本发明的一些实施例的音频通信系统1000的终端单元200的配置的框图。
系统1000包括一个或更多个声学/声音换能器单元100,每个声学/声音换能器单元通常可以包括声音传输元件的阵列,声音传输元件的阵列可以被操作来生成定向声束并朝着选定方向引导定向声束。例如,在图中例示了换能器阵列单元100a和可选的100b至100n)。换能器阵列单元100a-100n均可以负责在相应换能器单元的视线内的特定区/区域。此外,音频通信系统1000还包括一个或更多个三维感测设备/模块(tdsm)110,每个三维感测设备/模块包括能够获取指示它们被放置到的环境的/在它们被放置于的环境中的三维结构的感测数据的一个或更多个传感器。tdsm模块110可以例如包括无源和/或有源传感器,例如一个或更多个相机(例如,在视觉和/或ir波段中操作)和/或深度传感器(例如,lidar和/或结构光扫描仪)、和/或回波位置传感器(例如,声纳)、和/或如在本领域中可能已知的能够感测环境的3d结构并提供指示其的感测数据的传感器的任何组合。应当注意,在一些情况下,tdsm模块110被配置成利用/操作换能器单元100,也作为用于感测环境的3d结构的声纳模块。在这种情况下,换能器单元100可以适于在超声波信号的传输和接收模式中操作,和/或音频输入传感器120和/或与tdsm模块110相关联的其他传感器可以被配置成和在超声波波长下可操作来感测/接收反射/返回的声纳信号。
在本示例中,tdsm110包括tdsm单元110a和可选地包括附加tdsm单元110b至110m,由此,每个tdsm单元能够监测给定大小和形状的区域的3d结构。因此,在由音频通信系统1000服务的每个空间/位点(例如,房间/办公室/车辆空间)处,至少一个tdsm100和可能多于一个tdsm100被安装成以便覆盖该空间的主要区域并向系统1000提供指示该空间的结构的3d感测数据。此外,该系统包括控制系统500(在本文也被称为局部音频系统),该控制系统500可连接到tdsm110和连接到换能器单元100,并且被配置成和可操作来从tdsm110接收指示tdsm110所位于/被装备于的一个或更多个空间的3d结构的3d感测数据,并且操作位于这些空间处的换能器单元100,以便向在这些空间中的用户提供指定的音频数据/信号。
根据本发明的一些实施例,控制系统500包括用户检测模块520,用户检测模块520(例如,通过有线或无线连接)可连接到一个或更多个tdsm110,并且被配置成和可操作来处理从其获得的3d感测数据以检测、跟踪并且可能还识别位于tdsm110被安装到的空间中的用户。为此目的,用户检测模块520被配置成并可操作来处理感测数据以确定在由tdsm覆盖的空间/感觉体积内的空间位置元素,并且特别是检测用户的头部或用户的耳朵中的至少一者在三维传感器模块的感测体积内的位置。
通常,tdsm110可以与换能器100分开地被定位和/或可以与相应的感测坐标系(相对于该坐标系,因而感测的感测体积的3d感测数据被提供)相关联。
事实上,如对图1b中的示例所示的,感测坐标系可以不同于声换能器100的坐标系。例如在图1b中,在房间r2中的tdsm110b的坐标系c被示为不同于覆盖该房间的换能器单元100b的坐标系c'。因此,tdsm110b可以检测/感测位于感测体积svb内的用户p(例如,其头部/耳朵)的位置,并且提供指示用户的头部/耳朵相对于tdsm110b的坐标系c的位置的数据。换能器100b可以布置在房间中不同的位置处和/或不同的方向处,并且通常可以被配置为相对于不同的坐标系c'进行操作,以用于将声音引导到位于换能器100b的覆盖区域czb处的用户p。
因此,根据本发明的一些实施例,为了在可能被安装在可能不同的位置和/或方位处的tdsm110和换能器100的不同坐标系之间桥接,控制系统500包括映射模块510,该映射模块510被配置成和可操作来在tdsm110的坐标系(获得针对该坐标系的感测数据)和换能器100的坐标系(由系统1000生成针对该坐标系的声音)之间映射。例如,映射模块510可以包括/存储映射数据512(例如,一个或更多个坐标变换的列表,例如从c到c'的变换),映射数据512在一个或更多个tdsm110的坐标到属于/覆盖由对应的tdsm110感测的相同/公共空间的一个或更多个相对应的换能器100的坐标之间进行映射。
可选地,映射模块510还包括被配置成和可操作来获得在tdsm110和换能器100之间的映射数据的校准模块514。这在下文中更详细地被讨论。
附加地,控制系统500包括输出声音发生器模块600(在下文中也可互换地被称为声音处理设施/模块)。输出声音发生器模块600(声音处理设施)可连接到一个或更多个换能器单元100,并且适于操作一个或更多个换能器单元100以生成由用户检测模块520所检测的一个或更多个用户接收/听到的声学信号。
为此目的,输出声音发生器模块600可以与系统1000的音频会话管理器570的音频输入模块610(例如外部音频源)相关联。音频输入模块610被配置成和可操作来接收声音数据并向输出声音发生器模块600提供要被传输到在由系统覆盖的空间(例如公寓apt)中的至少一个预定的感兴趣用户(例如用户p)的声音数据。
根据一些实施例,输出声音发生器模块600包括被配置成和可操作来从换能器100中选择(最适合于)生成和引导由预定用户(例如由用户p)听到的声场的至少一个选定换能器(例如100a)的换能器选择器模块620。
为此目的,根据一些实施例,输出声音发生器模块600连接到用户检测模块520,以用于从其接收指示因而被服务的感兴趣用户的位置的数据(例如,位置可以根据至少一个tdsm110的坐标系c进行指定)。输出声音发生器模块600连接到映射模块510,并且适用于从其接收指示在感测感兴趣用户p的tdsm110的坐标系(例如tdsm110b的坐标c)和一个或更多个换能器100的坐标系(例如换能器100b的坐标c')之间的坐标映射(例如变换)的映射数据512。
换能器选择器从用户检测模块520接收预定用户的位置(该位置可以例如是关于在检测用户p的tdsm(例如110b)的相应感测坐标系而言的)。换能器选择器模块620被配置成和可操作来利用从映射模块510获得的映射数据(例如,坐标变换c-c'和/或c-c”)以用于将检测到的用户p的头部/耳朵的位置转换到一个或更多个换能器100的坐标空间/系统中。可选地,换能器选择器模块620可以适于也接收指示位于感兴趣用户p附近(例如,与图1b所示的用户p在相同的空间/房间中)的结构/物体obj(例如元件,例如墙壁和/或家具和/或其表面)的数据。然后,换能器选择器模块620利用从映射模块510获得的映射数据(例如,坐标变换c-c'和/或c-c”)以用于将检测到的用户p的头部/耳朵的位置以及可能还有方位转换到一个或更多个相关换能器100的坐标空间/系统中。相关换能器其实是在用户p所位于的覆盖区域内的换能器(为此目的排除了不在相同空间内和/或覆盖区域不与预定用户的位置重叠的换能器)。可能地,在这个阶段,换能器选择器模块620利用从映射模块510获得的映射数据来将物体obj在空间中的位置转换成相关换能器的坐标。然后,基于用户的头部/耳朵在相关换能器100的坐标空间中的位置和方位,换能器选择器模块620确定并选择位置和方位最适合于向用户提供最高质量声场的换能器(例如100b)。为此目的,换能器选择器620可以选择具有到预定用户p(到他的头部/耳朵)的较短的无阻碍视线的换能器(例如100b)。在没有具有无阻碍视线的换能器被发现的情况下,换能器选择器620可以利用模式识别来处理3d感测数据(例如,来自tdsm的2d和/或3d图像)以识别如此靠近用户的声反射器,并且选择可以最佳地生成经由来自空间中的物体obj的反射到达用户的声场的一个或更多个换能器。为此目的,换能器选择器620确定用于服务预定用户以向他提供音频场的选定换能器(例如100a),并确定用于将音频场引导至用户的头部/耳朵的音频传输路径(例如,优选地直接的,但可能也间接的/经由反射)。
输出声音发生器模块600还包括音频信号发生器630,音频信号发生器630被配置成并可操作来生成音频信号,以用于操作选定换能器来生成期望音频场并将期望音频场传输给预定用户。在这一点上,音频信号发生器630对来自音频输入模块610的声音数据编码和/或可能地放大声音数据以生成携带声音数据的音频信号(例如模拟信号)。在这一点上,可以根据任何已知的技术来执行对要被传递到选定声换能器(例如100a)的扬声器的信号上的声音数据的编码。
特别地,在本发明的一些实施例中,音频信号发生器630被配置成和可操作来生成仅在用户附近携带声音数据的音频场,使得用户私密地听到传输给他的音频场,而在他附近的用户/人们不能听到声音。这可以例如通过利用来自在被授予给本发明的受让人并通过引用并入本文的wo2014/076707中公开的超声波技术的声音来实现。为此目的,音频信号发生器630可以包括来自超声波信号发生器632的声音,超声波信号发生器632被配置成和可操作来接收和处理声音数据同时实现在wo2014/076707中公开的私人声场生成技术,以便产生只能被其所指向的预定用户听到的私人声场。为此目的,用户相对于(如从换能器选择器630获得的)选定换能器的相对位置用于生成从换能器指向用户的位置并且被配置为在该区域中具有形成在用户的区域处的局部声场的非线性相互作用的超声波束。
此外,该系统可以包括波束形成模块634,该波束形成模块634被配置成和可操作来处理所生成的携带信号的音频场以生成多个波束形成信号,波束形成信号在被提供给选定声换能器(例如100b)的多个换能器元件时生成聚焦于用户(在他的头部上,以及更优选地在他的耳朵上)的输出声波束。如本领域中的技术人员将容易认识到的,本发明的波束形成模块634可以被配置成和可操作来实现各种在本领域中已知的波束形成技术(例如相控阵波束形成和/或延迟和相减波束形成)中的任何一种或多种。
因此,控制系统500被配置成并可操作来处理从tdsm110获得的感测数据,以便确定音频信号/数据应该被传递到的在所监测的空间中的用户,并且操作一个或更多个换能器单元100a和100b,以便向用户提供免提私人音频会话,其中用户私密地听到随之被指定的声音数据,而在空间中的其他用户没有听到它。
根据一些实施例,该系统包括被配置成和可操作来管理位于由系统1000覆盖的空间中的一个用户或多个用户的音频会话的音频会话管理器570。音频会话管理器570可以适于管理各种类型的会话,包括例如音频/声音数据被提供给用户的单边会话(例如音乐播放会话、电视观看会话、打游戏等)和/或音频/声音数据被提供给用户并且还从用户被接收的双边会话(例如电话/视频呼叫/会议会话和/或语音控制/命令会话等)。为此目的,会话管理器可以管理和保持跟踪与在由系统覆盖的空间中的多个用户相关联的多个音频会话,该会话管理器区分开要传递给不同的相应用户的声音并且还区分从不同的相应用户接收的声音。
为此目的,可选地在系统被配置为使用户能够进行双向(双边)音频通信会话(例如电话呼叫)的实现方式中。系统1000包括分布在由系统覆盖的空间/位点中的一个或更多个音频输入传感器模块120。每个音频输入传感器模块120被配置成和可操作来在由此覆盖的空间处接收来自用户的音频信息。音频会话管理器570包括输入声音分析器560,其适于处理来自音频输入传感器模块120的音频信息,以便区分开不同用户的声音/话音。
例如,音频输入传感器120可以作为可以用于区分开从不同方向到达的声音的定向音频输入传感器进行配置和操作。因此,输入声音分析器560被配置成和可操作来基于在用户和在同一空间中的一个或更多个定向音频输入传感器120之间的不同相对方向来区分开来自在该空间中的不同用户的输入声音。
例如,在一些情况下,定向音频输入传感器120被实现为麦克风阵列。麦克风阵列可以包括面向不同方向的多个定向麦克风、或者多个麦克风(例如相似的麦克风)和输入声波束形成器。因此,不同地被定向的定向麦克风的阵列和/或连接到麦克风的阵列的输入声波束形成器(未特别示出)提供指示从与它们被接收自的方向相关联的不同方向接收的声音的数据。输入声波束形成器可以被配置成和可操作来根据任何合适的在本领域中已知的波束形成技术来处理由麦克风阵列接收的信号,以便确定由该阵列接收的不同声音的方向。输入声音分析器560可以被配置成和可操作来基于如例如由用户检测模块520确定的用户在这些空间中的位置来使从不同方向到达的声音与在被监测的空间中的不同相应用户相关联。更特别地,输入声音分析器560可以适于利用用户检测模块520,以便确定不同用户在由系统1000监测的空间中的位置。然后,利用映射模块510(其在这种情况下也保存使麦克风阵列120的坐标(位置、方位、和感测特性)与tdsm110的坐标相关联的映射数据),输入声音分析器560确定从每个特定方向到达的声音属于哪个用户。因此,声音分析器560将来自每个用户的方向的声音与用户的会话相关联。因此,输出声音发生器模块600凭此私密地向系统的相应用户提供声音,并且声音分析器560单独/独特地从每个用户获得声音,可以与每个用户建立双边音频通信。
如上面所指示的,系统1000可以被配置为分布式系统,其包括一个或更多个换能器单元(通常以100指代)和可分配地布置在期望空间(例如房屋、公寓、办公室、车辆和/或其他空间)中的一个或更多个tdsm(通常以110指代)以及连接到分布式单元的管理服务器系统700。例如,图1b示出了分布式系统1000。系统1000包括布置在公寓apt的房间r1至r3中并连接到管理在公寓内的音频通信会话的控制系统500的tdsm110a至110c。系统1000还包括布置在车辆vcl中并连接到管理在车辆vcl内的音频通信会话的控制系统500'的tdsm110e和换能器100e。在系统的各种实现方式中,控制系统500和500'(其在本文也被称为局部音频系统)可以通过有线或无线连接来连接到它们相应的tdsm110和换能器100。管理服务器系统700管理用户的音频通信会话同时跟踪当用户在由系统覆盖的空间/位点(在这种情况下是公寓apt的房间r1-r3和车辆vcl)之间穿行时用户的位置。
服务器系统700可以例如距控制系统(局部音频系统)500和/或500'远程地(即距公寓apt和/或距车辆vcl远程地)驻留,并且可以作为基于云的服务器系统被配置和可操作来在用户在公寓apt的房间之间移动时、从公寓到车辆vcl和/或当他驾驶车辆vcl时向用户提供语音通信。为此目的,控制系统500或其一个或更多个模块可以作为从远程例如通过网络通信(例如因特网)可连接到多个tdsm和换能器的基于云的服务进行配置和操作。为此目的,除了tdsm110和换能器阵列单元100之外,控制系统500和/或500'以及可能还有系统1000的其他模块可以被实现为基于云的模块(硬件和/或软件),并且距由系统覆盖的空间(例如公寓apt、车辆vcl和/或办公室)远程地被定位,并且适于与tdsm110和换能器阵列单元100通信。因此,在由系统覆盖的空间处可能没有与控制系统500和/或500'相关的物理硬件。
为此目的,服务器系统700与控制系统500和500'通信以从其接收指示感兴趣用户(p)的位置的数据。为此目的,服务器系统700接收通过处理由各种tdsm110收集的感测数据而从控制系统500和500'的用户检测模块520获得的用户检测数据,tdsm110在感兴趣的用户(例如,用户p)在不同空间(公寓的房间和/或车辆)中移动时感测他。因此,服务器系统700在用户在不同空间之间移动时跟踪他,同时在用户移动时管理他的音频会话。在用户在活动音频会话中时从一个/第一控制系统(例如500)的tdsm和换能器的覆盖空间移动到另一个/第二控制系统(例如500')的覆盖区域的情况下,服务器系统700操作第二控制系统500'以继续用户的活动音频会话。
事实上,在一些情况下,用户可以移动到没有tdsm110和没有换能器100被安装的地方/位置。例如,当用户在公寓apt和车辆vcl之间的路径上行走时。因此,在一些实施例中,服务器系统700还包括移动会话模块710(例如调制解调器),在该移动会话模块710中能够将音频通信会话传送到用户的移动设备mob(例如预先注册的移动设备,例如在如与用户相关联的服务器700中预先记录的移动电话),以便允许用户在不同空间之间穿行时保持连续的音频会话。因此,一旦用户离开系统的覆盖区域,他就可以通过他的电话继续他的音频会话。
可选地或此外,在一些实现方式中,系统1000包括一个或更多个完整的封装单元,其包括一起封装在同一模块中的至少一个换能器单元100、至少一个tdsm110、以及可选的输入音频传感器(麦克风阵列)120。这例如在图1c中示出,并且在图1b中看到模块100a+110a和100c+110c。可选地,完整的封装单元还包括控制单元500和音频会话管理器570。
在这种情况下,换能器单元100和tdsm110预先安装在封装内,并且在它们的感测体积和覆盖区域的坐标之间的关系先验地被预先确定,并且在控制单元的映射模块510(例如存储器)中被编码。因此,在这种情况下,在tdsm和换能器之间的映射的校准是不需要的。为此目的,这个示例的完整封装单元被配置为部署在某个空间中而没有校准,并且可以用于在其被部署到的空间处向用户提供私人音频通信会话。
然而,通常可能需要校准,以便确定使换能器的坐标空间/系统(例如,c')、tdsm的坐标空间/系统(例如,c)、和可能还有的音频输入传感器120的坐标系统相关联的映射数据。更特别地,在换能器和tdsm如图1b所示分开地被定位的情况下,校准可能是需要的。为此目的,可选地,映射模块510包括校准模块514,该校准模块514被配置成和可操作来获得和/或确定指示不同tdsm和换能器以及可能还有的连接到控制系统500的音频输入传感器120的相对位置和方位的校准数据。
在一些实施例中,校准模块514适于从安装系统1000的用户接收手动输入校准数据。例如,这种输入数据可以指示tdsm和换能器的相对位置和方位,并且校准模块514可以适于利用该数据来确定指示在tdsm110的坐标和换能器100以及可能的音频输入传感器120的坐标之间的坐标变换的映射数据。
可选地或此外,校准模块514可以适于实现自动校准方案,其中使用tdsm110的感测能力以及可能还有的音频输入传感器120的音频感测能力,以便确定tdsm110相对于各种换能器100和/或输入传感器120的位置和方位。为此目的,在一些实施例中,校准模块514利用模式识别引擎515,以便处理由每个tdsm110感测的数据以识别位于每个tdsm的感测区域中的换能器100和可能的音频输入传感器120,并确定它们相对于tdsm110的相对位置和方位。
实际上,在一些实施例中,为了识别换能器100和可选地识别音频输入传感器120,校准模块514利用指示换能器和/或音频输入传感器的外观和/或形状的某些预先存储的参考数据。该参考数据可以由模式识别引擎515使用来识别在由tdsm监测的空间(感测体积sva-svn)中的这些元素。
此外,可选地,根据一些实施例,换能器100和可能的音频输入传感器120配置有携带识别标记(例如,一般是视觉被动标记,但可能也是主动标记,例如主动辐射发射标记)和/或声学标记和/或帮助通过tdsm来识别换能器100和/或音频输入传感器120的类型及位置和方位的其他标记的封装。为此目的,标记应具有由在tdsm中包括的传感器可识别的类型。在这样的实施例中,由校准模块514使用的预先存储的参考数据可以包括指示由不同类型的换能器100和/或音频输入传感器120携带的标记连同它们各自的类型和音频属性的数据。参考数据可以由模式识别引擎515使用来识别在由tdsm监测的空间(感测体积sva-svn)中的标记,并从而确定换能器100和可选的音频输入传感器120的相对位置和方位。
然而,可选地或附加地,校准模块可以适于执行主动校准阶段,其中通过感测和处理在校准阶段期间由换能器生成的声场并且经由检测和处理由此生成的校准声场而定位(例如回声定位)换能器(例如,通过使用tdsm110和/或音频输入传感器120来感测这些声场并处理所感测的声场;例如利用波束形成)来确定换能器的位置,以便确定换能器相对于tdsm和/或110和/或音频输入传感器120的相对位置和方位。
此后,一旦换能器100的相对位置和方位被确定,校准模块514就确定在换能器100的坐标空间/系统(换能器100a-100m的覆盖区域的cza-czm坐标,系统可以通过所述坐标来调节/控制所生成的声场的方向和/或位置)和tdsm的感测区域sva-svn的坐标空间之间的坐标变换。这允许生成映射模块的映射数据,其能够准确地选择和操作选定换能器,以便生成声场并朝着由tdsm之一检测到的用户p的位置引导声场。可选地,以相同的方式,校准模块514确定在音频输入传感器120的覆盖区域(在图中未特别示出)的坐标空间/系统和tdsm的感测区域sva-svn的坐标空间之间的坐标变换,系统通过所述音频输入传感器120来接收来自用户的声音。这允许生成能够准确地确定用户(其话音由音频输入传感器120接收)的映射数据。
因此,应当注意,尽管在图中没有特别示出,但是控制系统500和通常系统1000包括一个或更多个通信输入和输出端口,该一个或更多个通信输入和输出端口用于在网络通信中使用和/或根据情况可以用于附加的一个或更多个元件的连接。
在一些实施例中,系统1000还可以包括可连接到控制单元500,并被配置成和可操作来向一个或更多个用户提供显示数据的一个或更多个显示单元130。控制单元500可以从用户检测模块接收关于用户的位置的数据,并且基于该位置数据来确定用于向用户显示一个或更多个选定数据段的合适显示单元130,并且当用户移动时进一步选择附加显示单元130。控制单元可操作来显示各种数据类型,包括但不限于下列操作中的一个或更多个:显示与参与正在进行通信会话的另一用户相关联的数据,显示由用户选择的数据(例如电视节目、视频剪辑等),显示基于由系统确定的用户属性(例如年龄、性别)而选择的商业数据。如下面进一步描述的,控制单元500可以允许用户使用一个或更多个命令手势来控制所显示的数据。附加地,在一些实施例中,显示器也是系统的用户界面的一部分(可能还包括用户输入设备,例如键盘和/或触摸屏和/或手势检测),其作为系统设置界面进行配置和操作,系统设置界面向用户呈现系统的设置和配置参数并从用户接收用于配置系统1000的设置和配置参数的指令。
一个或更多个tdsm110被配置为提供关于在一个或更多个相对应的感测区域内的区域的三维布置的数据。为此目的,一个或更多个tdsm110可以包括一个或更多个相机单元、三维相机单元、以及附加的感测元件,例如雷达单元、lidar(例如基于光的雷达)单元和/或声纳单元。附加地,控制单元500可以被配置成通过用超声波束扫描相对应的覆盖体积并根据超声波束的检测到的反射确定的覆盖体积的布置来操作一个或更多个换能器单元100以充当一个或更多个声纳单元。
如上面所指示的,换能器单元100均可以包括换能器元件的阵列。图3示出了这种换能器单元100的示例,该换能器单元100可以被包括在系统1000中,并且特别适合于实现来自超声波技术(例如在wo2014/076707中公开的)的声音,用于在它的覆盖区域内(例如在感兴趣的指定用户的头部/耳朵附近)生成局部声场(例如受限的声音气泡)。换能器单元100包括:被配置为发射在超声(us)频率范围处的超声波的声学信号的换能器元件的阵列105;以及声音生成控制器108,其被配置为接收指示要被传输的声学信号和信号将被传输到的空间位置的输入数据。声音生成控制器108还被配置成和可操作来操作不同的换能器元件105以振动和发射具有选定频率和在它们之间的相位关系的声学信号,使得所发射的us信号朝着所指示的空间位置传播,并且在期望位置处在它们之间相互作用以生成对应于将被传输的信号的可听声音,如下面进一步描述的。关于这一点,如本文下面使用的术语换能器阵列、换能器单元和换能器阵列单元应该被理解为指包括能够传输在预定的超声频率范围(例如40-60khz)内的声学信号的任何类型的换能器元件的阵列的单元。换能器阵列单元可以通常能够提供波束形成和波束转向选项,以引导和聚焦所发射的声学信号,从而实现对可听声音的亮区域的创建。
一个或更多个麦克风阵列120被配置成从空间收集在可听频率范围内的声学信号以允许使用语音手势和双边通信会话。麦克风阵列120被配置为接收输入可听信号,同时至少实现声音信号的起源的可靠区分。为此目的,麦克风阵列120可以包括与空间内的一个或更多个不同方向对准的一个或更多个方向麦克风单元、或者在空间内布置在它们之间的预定距离处的一个或更多个麦克风单元。关于这一点,应该注意到,因为可听声音具有在几毫米和几米之间的典型波长,对相控阵音频输入设备的形式的多个麦克风单元的使用可能需要在麦克风单元之间的大间隔,并且可能是相对困难的。然而,利用在其之间具有几厘米的距离的若干麦克风单元并根据检测的时间来分析音频输入可以提供关于信号起源的方向和位置的可靠指示。一般应当注意,音频输入数据可以与由一个或更多个tdsm110接收的感测数据并行地被处理,以提供关于音频输入信号的起源的指示并降低背景噪声。
控制/处理系统500被配置成和可操作来向位于该系统被使用的空间内的一个或更多个用户提供免提私人声音通信。通常,系统1000被配置成并可操作来发起一个或更多个用户的音频通信会话或对来自用户的发起做出响应,同时提供私人声音区域,在该私人声音区域只有选定用户能够听到声音信号。为此目的,控制单元500利用关于空间的三维布置的感测数据来确定选定用户的位置,传输具有合适振幅、相位、频率和空间波束形成的两个或更多个选定超声波频率的声学信号,以使超声波信号在选定用户附近在它们之间相互作用,以解调可听声音的频率。这提供了用户可以听到的声音的区域,而声音不能在相对小的区域之外被听到。为此目的,控制单元500通常被配置为提供某些数据处理能力以及指示在换能器阵列单元100的覆盖区域和tdsm单元110的感测体积之间的对应关系的校准数据。如上面所指示的,这种校准数据可以被预先存储或由系统自动生成。控制系统500和/或音频会话管理器570可以包括音频输入模块610,该音频输入模块610被配置成和可操作来与一个或更多个音频源(例如,本地或远程通信模块和/或其他音频数据提供者)通信以从其获得要提供给用户的可听数据。而且,控制系统500和/或音频会话管理器570可以包括被配置成和可操作来从一个或更多个麦克风单元120接收输入音频信号的音频分析器560。控制系统500还可以包括手势检测模块550,手势检测模块550被配置成并可操作来处理来自麦克风单元120的音频信号以确定指示一个或更多个手势的音频信号是否是从系统的用户接收到的,并且可能将这样的手势与从用户接收的某些指令(例如,关于用户正在进行的通信会话和/或通信会话的发起等的用户指令)相关联。
映射模块510可连接到一个或更多个tdsm110单元,并且被配置成和可操作来接收指示相应感测体积的三维感测数据的输入。映射模块510还被配置为处理输入感测数据,并生成tdsm的一个或更多个相应感测体积的三维(3d)模型。在系统被配置为分布式系统的情况下,例如,如在图1b的当前示例中,一个控制单元500的映射模块可以被配置为沿着合适的通信网络与连接到其的一个或更多个其他音频通信系统的映射模块通信。附加地或可选地,映射模块可以被预先提供有关于不同换能器单元100、tdsm单元110和麦克风单元120的布置的数据,从而实现在由tdsm单元110和相对应的换能器单元100确定的感测数据和接收方位置之间的关联。
用户检测模块520被配置成和可操作来从一个或更多个tdsm110接收输入感测数据,并处理输入感测数据以确定一个或更多个人在相对应的感测体积内的存在和位置。关于这一点,用户检测模块可以包括被配置成和可操作来识别从tdsm110获得的图像中的各种物体的模式识别引擎/设施515或者与模式识别引擎/设施515相关联。就此而言,应当理解,tdsm110的图像可以包括:视觉图像和/或ir图像和/或回声定位图像和/或深度图像和/或包括上述项的任何组合/由上述项的任何组合构成的合成图像。从tdsm110获得的图像信息的确切类型通常取决于所使用的tdsm和在其中包括的传感器的具体配置。为此目的,术语“图像”在这里应该被理解为在它的与指示被监测空间的各种属性(例如各种谱色、深度和/或其他属性)的空间分布的数据像素的集合有关的广泛含义上。模式识别引擎/设施515可以利用如通常在本领域已知的各种类型的图像处理技术和/或各种模式识别方案,以用于识别在由tdsm监测的空间/感测体积中的人和/或他们的头部/耳朵(例如,图1b中的p)以及可能还有其他可识别物体(例如,图1b中的obj),并确定他们在被监测空间中的位置。这允许使与人或通常前景物体相关联的图像数据部分与背景图像数据分离。
为此目的,在一些实现方式中,模式识别引擎/设施515被配置成和可操作来将模式识别处理应用于从tdsm110获得的图像,并从而生成由tdsm监测的空间的3d模型。用户检测模块520又可以适于基于由模式识别引擎/设施515生成的空间的3d模型来确定(监测)并(及时)跟踪一个或更多个用户(例如,感兴趣的用户p的)的位置(例如,3d位置)。因此,用户检测模块520确定为感兴趣的用户p生成私人声音区域(声音气泡)所在的期望位置,使得所述位置在选定用户的头部上居中,并且更优选地在用户的单独耳朵上/附近居中。
在系统的一些配置中,用户检测模块520可以包括或连接到面部识别模块530、方位/头部检测模块540、和手势检测模块550中的一者或更多者。一般而言,应当注意,用户检测模块520被配置成和可操作来利用一个或更多个通常已知的处理算法来处理输入感测数据以确定在相对应的感测体积内的一个或更多个人(潜在用户)的存在。面部识别模块530通常可以被配置为接收指示一个或更多个选定用户的存在和位置的感测数据(例如,tdsm的图像),并且通过一种或多种面部识别技术来处理该数据以确定一个或更多个被检测的用户的身份。面部识别模块530因此被配置成和可操作用于生成指示一个或更多个被检测的用户的位置和身份的身份数据,并用于将身份数据提供到输出声音发生器模块600以使换能器选择器620能够选择合适的换能器单元,并操作它,以用于生成选定用户可听见的局部私人声音区域。面部识别模块530可以适于将身份数据也提供到接收声音分析器560,使得后者可以处理从音频输入声音接收的声音以确定/识别/分离从在被监测空间中的每个特定用户到达的声音。在一些实施例中,面部识别模块530还可以适于执行随意配对,并为了诸如递送商业广告的目的而确定用户年龄/性别。
输出声音发生器模块600和音频输入模块610通常可以根据用户的位置、由用户提供的一个或更多个手势(例如,语音手势)和双边正在进行的通信会话来向用户检测模块520提供关于输入音频信号的数据。
为此目的,方位/头部检测模块540被配置为接收来自tdsm的感测数据的至少一部分和/或从模式识别模块515获得的与感兴趣的用户p的位置相关联的3d模型的至少一部分,并且处理感测数据以确定选定用户的头部的位置,并且可能还确定用户的头部的方位。因此,方位/头部检测模块540可以向输出声音发生器模块600提供指示用户的头部的位置和方位的数据,使得输出声音发生器模块600可以在用户的头部附近(例如,至少部分地围绕用户的头部)生成局部/受限声场。
如下面更详细讨论的,在本发明的一些实施例中,头部方位模块540还被配置为处理来自tdsm的感测数据和/或从模式识别模块515获得的3d模型,以便确定指示用户的耳朵的位置和方位的数据,并将这些数据提供到输出声音发生器模块600,使得后者可以生成至少部分地围绕用户的耳朵的局部/受限可听声场。
如上面所指示的,头部方位模块540和/或换能器选择器模块620还可以生成指示在一个或更多个换能器单元和用户的耳朵/头部之间的视线的数据。关于这一点,应当注意,在一些实施例中,一个或更多个换能器单元100和一个或更多个tdsm110可以被配置在单个物理封装内以简化系统的部署。
如例如在图1c中所示的,在提供分布式处理的一些实施例中,这种物理封装还可以包括控制系统500和附加元件(未特别示出),例如在这里未特别示出的存储器和通信设施以及电源单元。在一些其他配置中,物理单元(即具有相同的封装)可以包括换能器单元100、tdsm110、麦克风单元120、电源单元(未特别示出)、和提供与遥控系统500的通信的通信设施(未特别示出),遥控系统500被配置为接收和处理感测数据,选择性地传输关于音频通信会话的物理分布式单元数据。
因此,由方位检测模块540基于感测数据确定的视线通常可以指示相对应的换能器单元100的视线。在本发明的一些配置中,方位检测模块可以被配置成根据接收方的头部/耳朵的所确定的位置来选择最适合于向接收方传输选定声学信号的换能器单元100。
另外,手势检测模块550通常被配置成和可操作来接收与一个或更多个选定用户相关联的输入感测数据,并且处理和分析输入数据以检测与被定义为发起一个或更多个命令的一个或更多个预定手势相关联的用户行为/运动。在一些实施例中,手势检测模块550还可以被配置为接收和处理从用户接收并由麦克风阵列120收集的音频信号,以检测与一个或更多个预定命令相关联的一个或更多个语音手势。
通常,为了提供免提音频通信以及提供对系统的免提管理和控制,控制系统500的手势检测模块550被配置成和可操作来对一个或更多个预定手势(运动和/或语音)做出响应并发起一个或更多个预定操作命令。此外,在一些实施例中,一些操作命令可以包括与被配置为从本发明的音频通信系统接收适当指示的外部元件相关联的一个或更多个命令。这种操作命令可以例如包括用于在音频通信会话(例如,与选定联系人的电话对话)中发起的命令、对基于一个或更多个条件的通知的请求、以及由系统和/或用户定义的任何其他预定命令。附加地,在一些配置中,手势检测模块可以用于检测与用户身份相关联的一个或更多个手势。更特别地,一个或更多个用户均可以被分配有唯一的手势,该唯一手势允许音频通信系统识别用户,同时简化对输入数据的处理。
通常,手势检测模块550可以被配置成和可操作来从用户检测模块520接收关于用户位置的数据,并且从一个或更多个tdsm110和/或从麦克风阵列120接收与同一位置相关联的感测数据。手势检测模块550还被配置为处理输入数据以识别一个或更多个预定义的手势是否由用户执行。在检测到一个或更多个手势时,手势检测模块550操作来生成一个或更多个相对应的命令并将一个或更多个相对应的命令传输到声音处理器设施600,以用于执行一个或更多个相对应的动作。在一些实施例中,接收声音分析器560被配置成接收来自用户的输入语音命令并结合手势模块550来分析输入语音命令。为了实现此,接收声音分析器560可以包括实现如在本领域中通常已知的一种或更多种语言解释技术的一个或更多个自然语言处理(nlp)模块,以用于对自然语言用户命令的破译。更特别地,用户可以在使用选择的自然语言时向音频通信系统提供语音命令。因此,接收声音分析器560可以被配置成和可操作来从周围声音中分离/过滤用户的语音(例如,可选地基于如上面所指示的感兴趣用户p的位置和/或基于用户的语音的频谱内容/颜色),并分析用户的输入语音/话音数据的部分(例如,分析如由手势检测模块550指示为语音命令的部分)以确定用户p给系统的实际命令。因此,这可以基于用户的自由/自然语言语音和可能还有基于用户的运动或其他身体手势。在一些附加实施例中,接收声音分析器560可以利用远程处理单元(例如云)的一种或更多种语言处理技术。为此目的,控制系统500可以将指示由音频输入传感器120接收的声音的数据传输到远程位置以进行处理,并接收指示输入信号的内容的所分析的数据。
在一些配置中,手势检测模块550也可以被配置为作为唤醒模块来操作。在这种情况下,手势检测模块550被配置成并可操作来对发起以由用户执行的运动手势的可听形式的命令的通信会话做出响应。例如,这种可听手势可以被配置为响应于诸如“呼叫乔治”或任何其他联系人名字的关键字而发起针对远程用户(例如,电话对话)的双边通信会话,以在相对应的存储器设施中定位乔治的联系人信息,并访问输入/输出设施以发起对乔治或任何其他所指示的联系人的外部呼叫。还应当注意,联系人可能同时出现在同一空间处,在该空间的不同或相同的所连接的区域中(即,在视线内或视线外)。在这种情况下,诸如“呼叫爸爸”的命令可以操作用户检测模块520以定位在空间内的用户,并且操作面部识别模块530以识别例如相对于呼叫请求用户被指示为“爸爸”的用户,并且发起在用户之间的私人双边通信会话。在两个用户之间的这种私人双边通信会话中,例如在不同的房间内,第一用户的音频输出由第一音频通信系统1000的选定麦克风阵列120收集,其中第一用户位于第一系统1000的覆盖区域内。所收集的音频电子地被传输到第二音频通信系统1000,第二音频通信系统1000操作来识别第二选定用户(例如乔治、爸爸)的位置,并操作相对应的选定换能器单元100以在第二用户的耳朵周围产生私人音频信号。同时,由第二用户生成的音频被相对应的第二音频通信系统1000收集,并且类似地被传输以被第一用户听到。
如上面所指示的并且如图1b所示的,系统1000可以被部署在一个或更多个所连接的空间中(例如在公寓apt的多个房间中),并且可能也部署在另外的一个或更多个断开连接的/远程的位置/空间(例如车辆vcl)中。因此,系统1000可以被配置成和可操作来提供在用户之间的无缝通信,而不管在他们之间的物理距离如何。为此目的,远程位置(例如公寓apt、车辆vcl)可以连接到类似的控制系统(例如500和500'),并且可以使用形成在控制系统(例如500和500')之间的外部数据/音频连接/通信的公共管理服务器700或连接到公共管理服务器700。为此目的,管理服务器700可以远离连接到其的一个或更多个控制系统,并且可以包括音频会话管理器570,该音频会话管理器570管理用户的音频会话,同时还在用户在由不同控制系统控制的区域/空间之间移动时跟踪用户的位置,以便当用户进入由其控制的区域/空间时将音频会话的管理和操作无缝地转移到相应的控制系统500或500'。
为此目的,管理服务器700实际上连接到一个或更多个终端单元,例如200、200',由此,每个终端单元控制某一个或更多个所连接的空间(例如房间),并管理在这些空间内的用户的音频会话。每个这样的终端单元可以如上面参考图1b和图1c所述的进行配置和操作,并且通常可以包括换能器阵列单元100、tdsm单元110和麦克风单元120中的至少一个。在终端单元例如200、200'和管理服务器700之间的远程连接可以利用任何已知的连接技术,包括但不限于网络连接、光纤光学器件等。
一个或更多个远程位置可以包括提供次中央处理方案的一个或更多个相对应的附加音频服务器单元、提供分布式管理的多个附加音频服务器单元,或者远程地连接到单个音频服务器单元以提供中央管理配置。例如,处理单元500可以连接到外部服务器(云),其中用户的所有位置被收集。当处理单元500的用户检测模块520在某个地方识别出选定用户时,它向外部服务器700报告它的位置,因而将所有通信(内部或外部的)转移到该特定处理单元500以被引导到选定的用户/接收方。
而且,如上面所指示的,控制/处理单元500通常可以包括方位检测模块540,该方位检测模块540被配置为根据来自一个或更多个tdsm110的输入感测数据和感测体积的3d模型来确定用户的头部的方位。方位检测模块540因此被配置成用于确定用户的头部或耳朵中的至少一者相对于tdsm110的方位并且优选地相对于换能器单元100的方位。方位检测模块540因此可以生成至少一个用户的耳朵中的至少一个耳朵是否在至少一个换能器单元的视线内的指示。基于用户的耳朵的所确定的位置和方位,处理单元500可以利用未特别示出的方向模块,该方向模块被配置为接收指示用户的头部/耳朵的位置和方位的数据,并且根据空间的3d模型来处理数据以确定从一个或更多个选定换能器单元到用户的头部/耳朵的声音传输的一个或更多个优化轨迹。
通常,优化轨迹可以是从选定换能器到用户的头部/耳朵的直接视线。然而,当这种直接视线不存在或者存在但基于相对于其他轨迹位于相对大的距离处的换能器单元时,可以使用声学信号的反射或其他技术。更特别地,当在换能器单元和用户的头部/耳朵之间的直接视线不能被确定时,处理单元500可以操作声音处理器设施600以将局部声音区域指向在选定换能器单元100的视线内的尽可能靠近用户的耳朵的点。
应当注意,通常私人声音区域可以被定义为其中在它的外部声音强度降低了例如30db的区域,因此,声音在非常接近选定区域时仍然可以是可忽略的,并且使用户能够识别声音并且可能四处移动到更好的收听位置。
可选地或附加地,在换能器单元100和用户的头部p之间的直接视线的形式的优化轨迹没有被找到的情况下,声音处理设施600且更特别地其换能器选择器模块620可以操作来确定在换能器100之一到用户的头部p之间的间接路径。这种间接路径可以包括从一个或更多个换能器100到位于用户p的附近区域中的一个或更多个声反射物体obj的直接路径。为此目的,换能器选择器620可以接收由模式识别引擎/设施515生成的由tdsm监测的空间的3d模型并利用该模型来确定位于用户附近(例如,在离其的预定距离内)并且可以具有可以被用于声音到用户p的间接传输的足够的声反射率的一个或更多个物体obj。为此目的,在一些实施例中,模式识别模块515还包括物体分类器(未特别示出),该物体分类器被配置成和可操作来将所识别的物体分类为它们相应的类型,并将每个物体类型与通常取决于物体的结构和材料的某个标称声反射/吸收参数(例如反射/吸收/散射的声谱)相关联。因此,在确定从选定换能器单元到用户的头部/耳朵的间接路径(在本文也被称为反射型轨迹)时,换能器选择器620可以模拟/计算针对在换能器100——反射物体obj——用户p之间的每个候选路径的声场的衰减(可能计算每频率衰减曲线)。为此目的,换能器选择器620可以被配置成和可操作来使用任何数量的声模拟/估计技术以基于从候选换能器100到物体obj和从物体obj到用户的距离(例如,其可以由3d模型指示)并且基于物体obj的声反射参数来估计每给定候选换能器100和候选反射物体obj的声场衰减。本领域中的普通技术人员将容易认识到可以由换能器选择器620实现的各种可能的技术以估计与到用户的每个间接/反射路径相关联的声场衰减。在可能若干候选间接路径(可能涉及不同的换能器和/或不同的物体)当中,换能器选择器620选择具有最小声衰减和/或最小畸变声衰减的路径,并从而选择一个和可能多于一个的换能器以用于经由来自在空间中的物体的反射将声学信号直接传输到用户p。为此目的,在任何换能器100到用户p之间没有足够短的直接路径的情况下,换能器选择器620利用空间(感兴趣区域)的3d模型并确定间接(基于反射的)声音轨迹,其包括从物体(例如墙壁)的表面朝着潜在用户的耳朵的反射。
因为反射可能导致声强的降低和信号的更大扩展,包括单次反射的轨迹通常是优选的,优于更大数量的反射。
在一个或更多个换能器单元100用于生成用于形成3d模型的声纳式感测数据的情况下,模型还可以包括关于来自表面的声反射的某些指示。因此,物体分类器可以利用这种声纳式感测数据来确定在空间中的物体的声反射特性。
如上面所指示的,根据本发明的音频通信系统可以利用集中式或分布式管理。这在示出包括可连接到本文例示的多个换能器单元中的换能器100a、100b和100c和可连接到本文例示的多个tdsm单元110a和110b的中央控制单元500a(充当音频通信服务器)的音频通信系统2000的图2中被例示。如下面参考图5所述的,换能器单元(100a、100b或100c)中的每一个可以安装在空间中的选定位置处以实现声学信号的传输,在相应覆盖区域(如在图中例示的cza、czb或czc)内的选定位置处形成局部声音区域。此外,tdsm单元110a或11b被配置成安装在空间内的选定位置处以提供指示相应感测体积(如在图中例示的sva和svb)的感测数据。附加地,该系统可以包括一个或更多个麦克风阵列120,该一个或更多个麦克风阵列120在选定位置处被使用并且被配置为提供关于从该系统被使用的空间收集的声学信号的数据。
应当注意,不同tdsm单元110的感测体积和换能器单元100的覆盖区域可以是单独的物理单元或者一起封装在单个公共物理单元中。附加地,换能器阵列单元100和tdsm单元110优选地被安装成使得系统被安装到的总空间由换能器阵列单元的覆盖区域cz和tdsm单元的感测体积sv覆盖。优选地,每个换能器阵列单元100与相对应的tdsm单元110配对以覆盖在换能器单元100的覆盖区域和tdsm单元110的感测体积内的公共区域。
换能器单元100和tdsm单元110通常可连接到被配置为管理系统的输入和输出数据以及通信的一个或更多个集中控制单元500a,如上面参考图1a中的控制单元500所述。控制单元500a通常被配置为充当音频通信服务器,该音频通信服务器被配置为管理在该系统被使用的空间内的不同用户之间的私人音频通信以及使用通信网络(例如电话通信、互联网通信等)的输入和输出通信。
控制单元500a通常至少包括映射模块510、用户检测模块520和声音处理器设施600。通常,控制单元还可以包括或可连接到一个或更多个存储器设施以及输入和输出通信端口。
映射模块510如上所述被配置成从tdsm单元110并且在一些配置中从换能器单元100接收输入感测数据,并且提供指示在感测体积和覆盖区域之间的关系的映射数据。这种映射数据还可以包括该系统被使用的空间的3d模型。为此目的,映射模块通常可以获得关于在不同换能器单元100和tdsm单元110被部署的空间中的位置的(例如,自动生成的和/或手动输入的)校准数据以及优选地包括空间本身的示意性地图。
如在图中所示的,用户检测模块520可连接到三维传感器模块(tdsm单元)110,以用于接收指示物体在相对应感测体积sva和svb中的布置和移动的感测数据。用户检测模块520还被配置成和可操作来处理输入的感测数据以确定一个或更多个用户在相对应的空间中的存在和空间位置。如上面参考图1a所述,用户检测模块520还可以包括面部识别模块530、方位检测模块540和手势检测模块550。通常,在本发明的一些实施例中,用户检测模块可操作来接收指示特定用户的输入命令,并处理来自多个tdsm单元110的感测数据以确定特定用户是否位于由系统覆盖的任何感测体积内,通过面部或其他可识别特征来识别用户,并确定适合于传输将由用户听到的局部的私有声音区域的用户的空间位置。优选地,用户检测模块能够提供指示用户的头部/耳朵中的至少一个的位置的空间坐标以实现声音到用户的耳朵的准确和直接传输。
声音处理器设施600可连接到换能器单元100,并且适于接收指示要传输给选定用户的声音的声音数据,并且操作选定换能器单元以生成并传输声学信号,从而私密地向用户播放期望的声音信号。
关于这一点,声音处理器设施600可以对指示被指定为消息的目标的选定用户的输入数据和指示要向用户播放的消息的声学内容的数据做出响应。响应于这样的输入指令,声音处理器设施可以为了所指定的用户的空间位置而与用户检测模块520通信;从映射模块510接收关于覆盖所确定的空间位置的相对应的换能器的数据;以及操作选定换能器100以传输合适的声学信号,从而形成将消息传送到指定空间位置的私人声音区域。如也在上面指示的,用户检测模块520及其方位检测模块可以优选地提供指示至少一个或用户的耳朵的位置的数据以提供准确和私人的音频通信。
附加地,且如上面所指示的,根据一些实施例,控制系统500还可以包括接收声音分析器570,其被配置成和可操作来连接到在所覆盖的区域/空间中采用的一个或更多个麦克风阵列120,并且用于从麦克风阵列120接收输入音频数据以实现双边通信会话。通常,接收声音分析器570处理从在所连接的位点中的一个或更多个选定麦克风阵列120接收的输入音频信号,并确定由选定用户例如发起或参与通信会话的用户生成的声学数据。为此目的,一个或更多个麦克风阵列120可以被配置为使用时间或相位延迟的定向麦克风阵列以基于其源的位置来区分输入声学数据。附加地或可选地,声音处理器设施可以利用由向用户传输声学信号的换能器单元100接收的超声波反射,并使超声波反射与由麦克风阵列120收集的可听信号相关联以确定与特定用户相关联的声音部分。
通常应当注意,一个或更多个麦克风单元120通常可连接到控制/处理单元500a(或如在图1a中例示的500)以提供音频输入数据。这种音频输入数据可以与一个或更多个语音手势相关联和/或是双边正在进行的通信会话的一部分。为此目的,用户检测模块520以及声音处理设施600通常被配置成和可操作来接收输入音频数据,并确定一个或更多个语音手势和/或操作来为操作指令处理数据的内容和/或作为正在进行的通信会话的一部分与输入音频数据相关,并将数据传输给本地或远程接收方。
如上面所指示的,本文所述的音频通信系统利用与一个或更多个换能器单元100、tdsm单元110和可能的一个或更多个麦克风阵列/单元120可连接的一个或更多个控制单元(500或500a),以在某个空间(感兴趣区域)内提供私人免提通信管理。关于这一点,参考图3,其示出了被配置成用于在上述音频通信系统中使用的终端单元200。终端单元通常包括换能器阵列单元100、三维感测模块110,并且可以包括麦克风阵列单元120。附加地,终端单元200通常还包括被配置为在终端单元和连接到其的控制单元500之间提供输入和输出通信的输入/输出模块130。
如上面所指示的,换能器阵列单元100通常可以包括换能器元件105的阵列,每个换能器元件被配置成发射超声波信号。换能器阵列单元100通常还可以包括被配置为确定适当信号结构和在从不同换能器元件105发射的信号之间的相位关系的声音生成控制器108。换能器阵列单元100被配置成和可操作来在期望位置处声场局部声音区域。为此目的,声音生成控制器108被配置成驱动阵列100的不同换能器元件105以将具有在换能器元件105之间的选定相位差以形成聚焦超声波束的选定超声波信号传输到根据在所发射的信号之间的相位差确定的选定位置(空间中的点)。超声波信号可以被形成有两个或更多个选定主频率、选定振幅和相位结构。选择两个或更多个频率及其振幅和相位结构以提供在期望位置处形成期望可听声波的信号的声波的空中传播的非线性解调(airbornenonlineardemodulation)。
在技术上,在超声波束中的不同基频由于压力波在非线性介质(例如空气、填充气体的体积、水)中的相互作用而被解调。更特别地,当信号包含具有两个(或更多)差频率f1和f2的声波时,空气的非线性解调信号并产生是f1和f2的整数倍、f1+f2的和、以及在f1和f2之间的差的频率。使用适当的超声波频率,假定在频率之间的差在可听声频谱内,并且包括期望的可听声学信号。
因此,所传输的声学信号被配置成在选定位置处、优选地在靠近用户的头部处生成局部可听区域(声音被私密地听到的区域)。为此目的,基于来自用户检测模块520的数据,声音处理器设施600确定选定用户的头部的位置。然后,如上所述,利用来自映射模块510的映射数据,换能器选择器620选择选定换能器(可能多于一个换能器;例如图2中的100a、100b、100c、或其组合),以被操作来将声音直接或间接地传输到用户的头部/耳朵。
然后,选定换能器以上述方式操作,用于生成携带期望声音数据的局部声场并朝着用户的头部/耳朵附近传输局部声场。
现在参考图4a和图4b,其中图4a是示出根据本发明的实施例执行的用于朝着用户p的头部传输局部(受限)声场的方法4000的流程图,而图4b是局部(在用户的头部附近生成的受限声场)的示意图。在操作4010中,系统——通常是用户检测模块520——定位在感兴趣区域中的用户。在操作4020中,面部识别模块530识别并定位在感兴趣区域内的感兴趣用户(例如,用户p)的头部。在操作4050中,系统——通常是换能器选择器620——确定/选择可用于朝着用户的头部直接或间接地传输声音信号/场以便在用户的头部附近(例如,至少部分地围绕用户的头部)生成局部受限声场的合适的换能器单元100。在操作4060中,音频信号发生器630被操作以生成可用于操作选定换能器100以转换在用户附近的局部/受限声场的有效的声音编码信号。为此目的,在操作4060中,来自超声(us)信号发生器632的声音被操作以确定信号的超声内容,其在与在用户附近的介质(例如空气)的非线性相互作用之后将生成/形成可以由用户听到的可听声场。而且,在操作4060中,波束形成器634被操作以生成选定换能器100的每个换能器元件105的特定信号,使得根据被提供给每个换能器元件105的相位延迟和不同频谱内容,预定形状和方向的一个或更多个超声波束(通常是两个或更多个)将由选定换能器100朝着用户传输,由此,这种波束的超声频谱内容使得在与在用户附近的介质(例如空气)相互作用之后,它们将产生将期望声音数据传送到用户的耳朵的可听声场。相应地,换能器阵列单元100被操作来使用相控阵波束形成技术生成超声频率的声波束。
如图4b所示,该技术有效地创建了声学亮区bz,在该声学亮区bz中所传输的信号形成可以由用户听到的可听声场。声学亮区bz通常被选择为在用户的头部附近(例如,围绕用户的头部的全部或部分)。亮区bz从其侧面和背面被暗区dz包围,在暗区dz中所传输的信号仍然可以形成一些可听声波,但具有足够低的声压级(spl)以至于不被人耳听到或几乎听不到。因此,声学亮区bz实际上限定声音气泡区域,其中携带期望声音数据的可听声场可以被听到,而在该区域外声场是不可听见的(例如,因为它在超声频带中),并且实际上不能被听到。实际上,在一些实现方式中,还可以生成私有区域pz声学区域,其包括在亮区和换能器阵列单元100之间的某个区域,在该区域处超声波形成某种程度的可听声音。通常,该私有区域从用户p朝着换能器100延伸某个距离(例如,在几厘米和几分米之间的范围内)。为此目的,应当理解,在用户后面的区域(例如,从用户到远离换能器100的方向)是可听声音不能被听到的暗区。
附加地或可选地,在选择将被操作用于向用户p传输音频场的换能器单元100(例如换能器100a至100m中的任何一个)时,换能器选择器模块620验证在音频场的朝着指定用户p的传播路径中没有其他用户(即在选定换能器和用户p之间的区域中没有其他用户)。在这种情况下,在选定换能器和用户之间的“暗区”dz中的音频电平不太重要,只要其spl低于在亮区bz中的spl。通常,在该区域处的spl实际上明显低于在亮区bz中的spl。应当注意,在选定换能器和用户p之间的区域中存在其他用户的情况下,则换能器选择器模块620可以选择换能器100中的用于将音频场投射到用户的不同换能器100,和/或确定音频场到用户的反射(间接)传播路径(例如经由通过obj的反射)。
通常,应该理解,当使用本发明的私人音频技术时,在亮区bz之外的spl(即在任何方向上围绕亮区的私人区pz和暗区dz)比在亮区bz处的zpl低至少20db。
图4b示出了围绕用户的头部(例如,用户的整个头部)的受限声场的生成的示例。然而,在本发明的系统的一些实现方式/实施例中,生成仅被限制在围绕用户的一个或两只耳朵但不是围绕用户p的整个头部的区域处的更小的声音气泡(更小的局部可听声场)是更优选的。这可能有几个优点。仅举一例,从超声波中生成可听声音可能通常不是在能量上高度有效的。也就是说,由此,大部分的能量被花在超声波声场的生成上,只有超声波声场的小部分的能量经历将它们转换成可听声音的非线性相互作用。因此,为了减少用于生成到用户的期望可听声场的所需功率/能量并且因此还可能降低所使用的换能器的复杂性和成本,生成仅被限制在用户的耳朵附近/周围的较小的局部可听声场气泡是优选的。另外的优点涉及向用户提供双耳(例如立体声)声音数据的能力,这在向不同的耳朵传输不同的声音内容时通常是可能的。然而,此外,在没有/减小的畸变的情况下的在空间上延伸的受限声音气泡(例如,延伸超过几十厘米,以便包围用户的整个头部)的生成在一些情况下可能比仅被限制在用户的耳朵周围的较小声音气泡(例如,仅几厘米至一或两分米)的生成更复杂(例如,在计算上更密集和/或需要更大数量的换能器元件105)。因此,由于上面所述的一个或更多个原因,产生仅聚焦在用户的耳朵附近的较小的局部声场在许多情况下是优选的。
然而,传统的面部识别和/或面部特征分析技术通常在它们准确、连续和可靠地识别和确定用户的耳朵的位置的能力方面是没有能力的和/或缺乏的。这可能是由于几个原因:(i)用户的耳朵可能隐藏/部分地隐藏在他的头发后面/下面;(ii)用户可能是从他的侧影被观察的,从而隐藏他的耳朵之一;和/或(iii)一些可用的技术也可能由于耳朵的复杂3d形状而完全避免对用户耳朵的检测。
为此目的,根据一些实施例,方法4000还包括操作4030,其被执行以确定用户p的耳朵(一个或两只耳朵)的位置,使得小于整个头部所需的可听声场的受限局部可听声场可以在用户p的一个或两只耳朵附近被生成。图4c是以一目了然的方式示出由换能器100生成的在用户的耳朵附近的受限可听声音(气泡)的较小亮区bz1和bz2的示意图。如所示,在这些亮区bz1和bz2之外有暗区,可听声音实际上不能在该暗区处被听到。在一些实施例中,可选地在从亮区bz1和bz2延伸到换能器100的某个距离(例如几分米)处,存在所谓的私人区pz1和pz2,可听声音可以在私人区pz1和pz2处被听到,但是不清楚和/或是低强度。
图4d是更详细地示出用于实现用于确定用户p的耳朵的位置的方法4000的操作4030的方法的流程图。在本发明的一些实施例中,面部识别模块530被配置成和可操作来携带/实现方法4030以在空间上定位和跟踪用户的耳朵的位置,同时可选地通过利用模式识别引擎515的模式识别能力。
在操作4032中,面部识别模块530操作来将面部/模式识别应用于从tdsm获得的感测数据(例如,应用于从tdsm获得的图像数据或3d模型和/或合成图像和/或3d图像)。为此目的,面部识别可以根据在本领域中已知的任何技术来实现。
在操作4034中,面部识别模块530基于面部识别来确定用户p的耳朵是否可以在图像中被识别出。在用户p的耳朵在图像中可识别的情况下,面部识别模块530继续进行到操作4036,在操作4036中面部识别模块530基于耳朵在图像中的位置来确定耳朵在由tdsm覆盖的空间中的位置。更特别地,在这种情况下,基于来自tdsm的图像/模型的3d数据,面部识别模块530确定耳朵在由tdsm覆盖的感测体积中的3d位置。
可选地,在用户p的耳朵在图像中可识别的情况下,面部识别模块530继续执行操作4038,以用于生成/更新用户p的个人头部模型。例如,在操作4038中,面部识别模块530可以通过如下执行步骤a、b和c基于图像来确定/估计用户p的面部模型:
(a)操作面部识别方案/过程以确定在用户面部中的附加面部特征点(例如,除耳朵之外)的位置。例如,确定鼻梁和眼睛的位置以及在它们之间的距离。
(b)处理耳朵的位置和在用户p中的附加面部特征点的位置以获得用户面部的某些个人人体测量关系的估计。因此,确定包括例如用户面部的使用户的耳朵的位置与其他面部特征点相关联的某些预定人体测量关系的个人头部模型。
(c)基于如为用户面部的当前图像获得的用户面部的人体测量关系来生成/更新个人头部模型。在这一点上,应当注意,面部识别模块可以包括被配置成和可操作来存储用户的个人头部模型的面部数据参考数据存储装置(未特别示出)或者与面部数据参考数据存储装置相关联。用户(其面部模型被存储)可以包括注册用户(例如,在系统中已知/注册的普通用户),并且用户的面部模型数据可以永久地被存储。可选地,面部参考数据存储装置还存储临时用户(未在系统中注册)的面部模型,至少只要这样的用户参与通信会话和/或只要这样的用户在由系统的tdsm覆盖的空间内(例如,当用户离开由系统覆盖的空间时和/或当他们的通信会话终止后,临时用户的面部模型可以被删除)。因此,在存储个人头部模型之前,在(b)中确定面部识别模块530首先检查以查看匹配模型是否已经存在于面部参考数据存储装置中。如果否,则该模型将被存储为新模型。然而,如果匹配模型已经存在,则现有模型基于从当前图像获得的数据、即基于最新估计的模型而被更新。为了在该时间期间提高用户p的所存储的个人头部模型的准确度,可以在利用某些滤波方案(例如卡尔曼滤波器和/或pid滤波器)时执行该更新,这些滤波方案允许从多个测量(例如从用户的多个图像)获得的数据被收敛以形成更高准确度的模型。
应当注意,操作4038是可选的,并且可以被执行,以便基于在图像中的耳朵和其他面部特征点的位置来完成/更新头部模型。
在操作4034发现用户p的耳朵不能在图像中被识别的情况下,继续进行到操作4040,其中确定面部识别模块530的面部数据参考数据存储装置是否已经存储了用户p的面部的个人头部模型。
在参考数据存储装置具有用户p的个人头部模型的情况下,面部识别模块530继续执行操作4042以基于用户p的个人头部模型和在从tdsm获得的用户的图像中识别的其他面部特征点在空间中的位置来确定用户p的耳朵在空间中的位置。
否则,在参考数据存储装置不包括用户p的个人头部模型的情况下,面部识别模块530继续执行操作4044,在操作4044中它基于统计人体测量建模方法来确定用户p的耳朵在空间中的位置。更特别地,在这种情况下,面部识别模块530确定用户的一个或更多个面部特征点在由tdsm监测的空间中的位置(例如,通过处理tdsm的图像),并且利用在用户的耳朵的位置相对于其他面部特征点的位置之间的一个或更多个在统计上稳定的人体测量关系,以便获得用户的p耳朵的位置的估计。为此目的,在4044中,在图像中的检测到的面部特征点和相对应的人体测量数据本质上在4044中用于推断耳朵的位置。
附加地,在4044中,可以基于例如用户的眼睛、鼻子等的面部特征点来构建或进一步更新个人头部模型。因此,当用户p的附加图像被获得和处理时,头部模型进一步被更新(见操作4046)。在这一点上,即使耳朵在图像中是不可见的,也可以通过根据在当前图像中的相对应面部特征点的所检测的位置来调整模型的面部特征点的位置来更新模型。
在这一点上,由本发明的面部识别模块530实现的在统计上的人体测量建模方法可以包括下列方法中的一个或更多个:
(a)平均面部比例方法。这是基于下面的事实的简化方法:典型/普通人脸通常遵循某些比例关系,例如在http://dhs.dearbornschools.org/wp-content/uploads/sites/625/2014/03/facial-proportions-worksheet.pdf中描述的那些关系。为此目的,在一些实施例中,面部识别模块530利用瞳孔间距离(ipd)平均为头部宽度的约3/5的事实。因此,通过应用面部识别以确定对应于用户的瞳孔的面部特征点在tdsm图像中的位置,可以估计头部尺寸以及相应地估计耳朵位置。
(b)人体测量建模方法——该方法基于从多个用户的测量中获得的可用人体测量统计数据。为此目的,在一些实施例中,面部识别模块530利用例如在https://www.facebase.org/facial_norms/处可获得的统计人体测量数据库来导出在用户的耳朵位置和各种面部特征点之间的经验多变量函数关系。这种方法对人类子组中的微妙关系是敏感的,且例如可以考虑各种参数(例如宽鼻子与圆脸等)的综合效应。因此,使用在用户p的图像中的可见面部特征点,面部识别模块530可以确定它们的形状(例如宽鼻子),并且相应地将用户分类到子组(例如亚洲人、高加索人或其他人)。然后,基于所分类的子组,面部识别模块530获得用户p的相关准确人体测量关系。
因此,如在操作4046中所示的,面部识别模块530对从tdsm获得的包括用户p的每个图像重复方法4000。因此,一般在一个或更多个图像被捕获之后,用户的耳朵一般被显露,并且用户p的个人头部模型被构建(例如,从零开始,即使这样的模型没有先验地被包括在面部参考数据库中)。更特别地,在许多情况下,耳朵被暴露且对相机是可见的,尤其是当随着时间的推移头部运动之后,当用户自然地转动头部时。耳朵位置的直接检测因此是可得到的,并且在特定用户p的面部特征点和耳朵位置之间的个人人体测量关系可以被准确地确定。
因此,在对用户面部的图像的重复分析期间,方法4000提供了进一步更新用户的这种个人头部模型以提高它的准确性。换句话说,当随着时间的推移更多的信息和统计数据被累积时,用户p的个人头部模型的更准确和稳定的估计被获得。因此,在本发明的一些实施例中,方法4000被实现并用于定位和跟踪感兴趣的用户p的耳朵。输出声音发生器模块600又在用户耳朵附近生成受限/私人可听声场,并从而有效地将可听声音传输给用户p。
为此目的,声学信号形成限定私人区域的局部可听声场,该私人区域被限制到在指定位置z0和声换能器系统10之间的区域附近。该区域包括一个或更多个亮区区域,其中清晰可听和可理解的可听声音被产生。在亮区bz之外定义暗区区域,其中声音对人耳是听不见的,或者它的内容不能被清楚地理解。
因此,回到图1a,应当注意,根据本发明的一些实施例,输出声音发生器模块600适于操作一个或更多个换能器单元100以转换将被用户p和可能附加用户的一只或两只耳朵接收/听到的声学信号。更特别地,用户检测模块520以上述方式检测用户p的耳朵,并且换能器选择器620确定/选择换能器100,通过该换能器100声音应被传输到每个耳朵。如上面所指示的,换能器选择器620确定声学信号从选定换能器到用户p的相应耳朵的传播路径(直接或间接路径),声学信号应由选定换能器朝着相应耳朵传输。因此,来自超声信号发生器632和波束形成器634的声音被配置成并可操作来生成用于操作选定换能器阵列以转换超声波声学信号的信号,超声波声学信号在它们朝着用户的传播路径中经历与介质(例如空气)的非线性相互作用时在用户p的一只或两只耳朵附近(例如围绕用户p的一只或两只耳朵)形成非常小的声音气泡。为此目的,每个耳朵的可听声音气泡的尺寸可以在直径上小到几毫米,并且通常可以在几毫米到几厘米的范围内,以便不包围用户p的整个头部。
上述技术允许系统1000单独地向用户p的每一只耳朵提供单独的可听声音。这又允许向用户私密地传输双耳声音。为此目的,应当理解,相同或不同换能器100可以被选择(由换能器选择器620进行),并且被操作以将声音传输到用户p的不同耳朵。例如,在用户的右耳在一个换能器(例如100a)的视线内并且左耳在另一个换能器(例如100b)的视线内的情况下,可以选择不同的换能器100。因此,在换能器100与用户的左耳和右耳之间的距离也可能是不同的(例如,这可能是由于在换能器和耳朵之间的距离的差异和/或由于用户的到一只或两只耳朵的反射传播路径的差异)。因此,在这样的实施例中,可能需要调整被提供给用户的可听双耳声音的平衡(即适当调整在用户听到的可听声音气泡的左音量和右音量之间的平衡)。实际上,由于在相应换能器与用户的左耳和右耳之间的传播路径的差异,以相同强度将声音传输到左耳和右耳可能对用户产生不平衡的左右可听声音。因此,根据一些实施例,在换能器选择器620选择将用于将声音传输到用户p的耳朵的相应的一个或更多个换能器100之后,并且在它确定它们到相应耳朵的相应直接和/或间接传播路径之后,换能器选择器620进一步确定沿着到用户p的每个耳朵的传播路径的所传输的声学信号/场的衰减水平。因此,换能器选择器620向来自超声信号发生器632的声音提供指示可听场在它们传播到用户的耳朵期间的衰减水平的数据。超声信号发生器632又利用接收到的衰减水平,以便调整超声信号的传输振幅,以便获得下列项中的至少一个:
(1)在由用户p的右耳和左耳听到的可听声音的音量之间保持预定的左右平衡(例如均衡的平衡和/或用户调整的平衡);以及
(2)当用户可以穿过由系统1000覆盖的空间移动时,为用户提供及时的连续/平滑的音量,并且当在这个移动期间时不同的换能器可以被切换到为用户服务,同时可能在离用户的耳朵的不同的距离处。
现在参考图5,其示出了根据本发明的一些实施例的用于音频通信的系统3000,该系统在具有空间(感兴趣区域roi)的部分地连接的位点中被采用。在该示例中,roi可以是公寓、办公空间或任何其他期望位置。为了提供roi的覆盖,在roi内的选定位置处采用多个终端单元(在本示例中的eu1、eu2、eu3和eu4)。终端单元通常包括换能器阵列单元100、tdsm单元110和可能的麦克风阵列120,并且通常类似于图3所示的终端单元200或在图1中例示的分布式管理通信系统1000。不同的终端单元(例如eu1)可以安装在墙壁、天花板、或任何其他表面上,或者是直立单元,并且被配置成覆盖相对应的覆盖区域,其在被使用时优选地与终端单元的tdsm单元的感测体积对齐或大部分对齐。
在该示例中,音频通信系统3000被配置为中央控制系统,并且包括控制单元/音频服务器5000。音频服务器5000可以包括一个或更多个上述模块,包括映射模块、用户检测模块和声音处理器设施。如上面所指示的,控制单元5000被配置为对发起通信会话(单边或双边)的请求做出响应,并管理正在进行的通信会话,向正在通信的一个或更多个用户提供私人声音区域。如上面所指示的,通信会话可以是单边的(系统向用户传输选定声音)或双边的(系统也从用户收集声音,用于处理相对应的数据或向另一用户/系统传输相对应的数据)。
关于这一点,参考图6,其示意性地示出了音频通信服务器6000,该音频通信服务器6000被配置成和可操作来操作与感测模块相结合的多个一个或更多个换能器阵列单元以提供在感兴趣区域内的私人和免提音频通信。服务器6000可用作中央控制单元(例如,图2和图5中的控制单元500a或5000),其可连接到多个分布式终端单元,包括换能器阵列单元、tdsm单元和麦克风单元;或者它可以被配置为如在图1中例示的音频通信系统的组成部分,其中终端单元200和处理设施被包装在单个单元(单个盒子)中。通常,音频通信服务器6000可以是被配置为连接到多个终端单元200的独立服务器,如上面参考图3所述的。可选地或附加地,在一些实施例中,音频通信服务器6000可以配置有一个或更多个整体的终端单元200,同时可以根据情况连接到一个或更多个附加的终端单元200。
音频服务器系统6000通常包括一个或更多个处理设施6010、存储器设施720和输入/输出控制器730。然而,应当注意,服务器系统6000通常可以被配置为计算机化系统和/或可以包括没有在这里特别示出的附加模块/单元。还应当注意,服务器系统的单元/模块/设施的内部布置可以不同于本文描述的具体示例。
输入/输出控制器730被配置为连接到多个终端单元,每个终端单元包括换能器阵列单元、tdsm单元和麦克风阵列中的至少一个。一般,一些终端单元可以如上面在图3中所述地进行配置,提供包括换能器阵列单元、tdsm和麦克风阵列的单个物理单元。通常,输入/输出控制器730使用通常已知的网络通信技术来实现与一个或更多个选定终端单元的通信。
一个或更多个处理设施6010通常包括如上所述的映射模块510、用户检测模块520、声音处理模块600,此外,一个或更多个处理设施6010还可以包括外部管理服务器700、响应检测模块570和特权模块580。
通常,如上面所指示的,映射模块510被配置为提供关于在roi内的换能器单元和tdsm单元的布置的校准数据。校准数据可以被预先存储或自动生成。在一些实施例中,映射模块510被配置成并可操作来从多个tdsm单元接收感测数据并且在一些实施例中从换能器阵列单元接收感测数据,并接收关于在感兴趣区域中的系统使用的输入数据,并且处理该数据以用于生成感兴趣区域的3d映射模型。3d模型通常包括roi的结构、不同换能器单元和tdsm单元的覆盖区域、以及指示在roi中的相对静止物体的数据。在一些配置中,3d模型还可以包括关于如由不同换能器阵列单元检测到的在roi中的不同表面的声反射和吸收特性的数据。3d模型通常存储在存储器设施720中,并且可以周期性地或响应于一个或更多个预定触发器而被更新。
用户检测模块520被配置成和可操作来接收关于待检测的用户的输入数据,并且从tdsm单元接收关于在roi内的用户的输入数据,从而定位期望用户并确定其空间坐标。在一些实施例中,用户检测模块520被配置成确定与用户的耳朵的位置相关联的空间坐标。附加地或可选地,用户检测模块520被配置成和可操作来对由在roi中的一个或更多个用户提供的命令做出响应,并生成对声音处理设施600的相对应的指示。通常,如上面所指示的,用户检测模块可以包括一个或更多个子模块或与一个或更多个子模块相关联,一个或更多个子模块包括面部识别模块530、方位检测模块540和手势检测模块550。
如上面所指示的,面部识别模块530被配置成和可操作来接收指示一个或更多个用户和优选地指示用户的面部的输入感测数据以及可以预先存储在存储器设施中的关于用户身份的数据,并且处理感测数据以从而确定一个或更多个用户的身份。为此目的,面部识别模块530可以利用一种或多种面部识别技术以及关于注册用户的一个或更多个身份的预先存储的数据。
方位检测模块540被配置成确定检测到的用户的头部的方位和用户的耳朵的位置。为此目的,方位检测模块被配置成和可操作来接收输入感测数据,并使用如在本领域中通常已知的一种或多种图像处理技术来处理如上面所指示的输入数据
手势检测模块550被配置成并可操作来对来自在roi中的一个或更多个用户的一个或更多个运动和/或声音手势做出响应,并且生成包括关于请求用户及其位置的数据的适当通知以及所请求的命令。通常,如上面所指示的,手势检测模块550被配置为对多个预定的语音或运动相关手势做出响应,手势被分配有与由系统执行的一个或更多个动作相关联的相对应的命令。例如,用户可以请求“呼叫家”,请求系统操作来确定用户的身份,搜索用户的家庭电话号码,并利用外部管理服务器700来与电话连接通信以发起呼叫。附加命令可以与不同外部系统的操作的控制相关联,例如与识别在用户所位于的区域内的tv单元并将它打开相关联的“打开tv”命令,或者与其他用户的通信相关联。在一些实施例中,预定命令可以包括与系统管理相关联的操作命令,例如增加音量、访问数据等的请求。
声音处理设施600被配置成和可操作来可连接到一个或更多个换能器单元,并操作一个或更多个选定换能器单元以生成选定声学信号,并向一个或更多个选定用户提供期望的私人声音。通常,声音处理设施被配置为接收或生成关于要被传输给一个或更多个选定用户的音频信号的数据,并且从用户检测模块520接收关于用户的位置的数据。声音处理设施还可以从映射模块510(或从存储器设施720)接收关于roi的3d模型的数据,并确定适合于将期望声学信号传输给选定用户的一个或更多个选定换能器单元。
声音处理设施600还可以被配置成和可操作来分析输入和/或输出音频数据。例如,声音处理设施600可以被配置成从手势检测模块接收指示音频/语音用户指令的数据,从而利用一种或多种语音(自由语音)识别技术来分析输入数据并生成相对应的指令。
在一些配置中,声音处理设施600也可以被配置为使用一种或更多种云处理技术。声音处理设施600因此可以被配置成通过外部管理服务器700向远程处理设施传输指示待处理的音频信号的数据。数据由远程服务器处理和分析,并且相对应的所分析的数据被传输回到音频通信服务器6000及其声音处理设施600。
通常,声音处理设施600可以被配置成和可操作来处理输入数据并生成相对应的输出数据,并执行下列处理类型中的一种或更多种:将输入数据从一种语言翻译成一种或更多种其他语言,分析输入数据以确定其中的一个或更多个技术指令,分析输入数据以提供经过滤的音频数据(例如滤除噪声),处理输入数据以根据情况改变其一个或更多个属性(例如增加/减少音量、速度等)和其他处理技术。如上所述,该处理可以由声音处理设施600执行和/或部分地在远程处理服务器上被执行。
如上面所指示的,声音处理设施600可以确定在选定换能器阵列单元和用户的耳朵之间的一条或更多条可能的视线。一般,声音处理单元可以被配置成偏爱声学信号沿着无障碍视线的传输;然而,在一些实施例中,声音处理设施可以利用反射型视线,其中声学信号在到达用户的位置之前经历来自一个或更多个表面的一次或更多次反射。如也在上面所指示的,声音处理设施600通常被配置为操作一个或更多个选定换能器阵列单元,以用于在选定位置处生成私人声音区域,如在上面和在被授予给本申请的受让人的专利公布wo2014076707和wo2014147625中所述。
附加地,根据一些实施例,声音处理设施600可以包括音频输入模块610,或者与音频输入模块610相关联。音频输入模块可以连接到在roi中采用的一个或更多个麦克风阵列单元,并接收与用户生成的声音相关联的声学输入数据。作为双边通信会话的一部分,这种声学输入数据可以与语音命令相关手势以及用户响应相关联。音频输入模块610可以被配置成接收与由一个或更多个麦克风阵列单元收集的声学可听信号相关联的输入数据。通常,麦克风阵列单元可以被配置成还提供与所收集的声学可听信号的源的位置相关联的数据。这可以通过适当选择麦克风阵列单元(例如被配置为麦克风元件或定向麦克风元件的相控阵的单元)来提供。此外,在一些配置中,可以根据由一个或更多个选定换能器阵列收集的超声波信号来处理所收集的声学可听信号,以确定在来自用户的超声波反射和来自用户的可听输入之间的相关性,并滤除来自用户的外围的噪声。更特别地,换能器阵列操作来根据来自相对应的tdsm单元的感测数据基于由用户检测模块520提供的用户位置来将单个超声波聚焦在用户面部上。换能器单元还可以收集关于从接收方(用户)面部反射的超声波信号的反射的数据。由于多普勒效应,用户面部的运动(例如嘴运动)产生对反射波的微小的变化。这些变化通常与由用户生成的音频信号相关联,并且可以与输入音频信号结合来被处理以滤除周围的噪声并提高信噪比。
如上面所指示的,音频通信服务器6000及其处理设施6010还可以包括响应检测模块570和/或特权模块580。响应检测模块570通常被配置成和可操作来确定指示用户对传输到其的输入信号的反应的数据。更特别地,响应检测模块570可以被配置成和可操作来接收关于从声音处理设施600传输给用户的一个或更多个信号的数据以及来自用户检测模块520和/或终端单元的一个或更多个相对应的tdsm的用户的感测数据,并且使输入数据相关联以确定用户对信号的响应。通常,用户的响应可以与运动模式、面部表情的变化、生成声音等相关联。
这种响应数据可以被收集用于进一步处理和分析,或者被传输到外部系统,例如最初生成传输给用户的信号的系统,作为接收的指示。这种响应数据可以用于例如使父母识别他们的孩子是否对发送给他们的消息做出了响应,用于广告分析和其他用途。
用户特权模块580被配置成接收关于一个或更多个用户向系统生成一个或更多个命令的数据以及关于所请求的命令的数据,并且确定请求用户具有对发起该命令的特权。如上面所指示的,音频通信系统可以向一个或更多个不同的用户提供私人声音。此外,语音和运动手势可以在用户以及访问和管理特权之间改变。为此目的,特权模块580可以基于预先存储的特权映射来将关于用户身份和所请求的动作的数据相关联,以及确定用户是否具有发起所请求的动作或者根据请求用户的身份来特别识别所请求的动作的权利。应当注意,可以根据与用户相关联的输入感测数据或者根据由用户提供的语音或手势类型密码来确定用户身份。为此目的,特权模块580可以被配置成和可操作来接收指示由用户提供的一个或更多个关键词的输入数据,并确定用户身份是否被充分确定。此外,特权模块580可以被配置成和可操作来根据情况允许或阻止对由外部管理服务器700执行的外部动作的访问。
处理设施还可以包括被配置为根据情况减轻在音频通信服务器6000和外部系统之间的通信的外部管理服务器700。例如,外部管理服务器700可以连接到通信网络、电话线、不同的电子系统,例如家用电器、远程(云)服务器等。外部管理服务器700被配置为发起诸如向特定用户提供通知的动作,例如洗衣机完成循环,管理来自外部源的输入呼叫、以及将来自系统或在roi中的用户的数据传输到任何期望的所连接的外部系统。
关于这一点,参考为若干示例性动作例示根据本发明的音频通信系统的操作的方法的图7、8、9和10。在图7中,系统操作来向选定用户传输某个信号;在图8中,系统向移动用户提供无缝通信会话;在图9中,系统对用户发起的动作做出响应;并且在图10中,系统确定用户对输入信号的响应。
如图7所示,系统从不同的用户、处理设施(例如,管理数据信号)或者通过外部管理服务器从外部系统接收向用户传输消息的请求7010。该请求通常包括关于待发送的一个或更多个消息的数据以及关于消息的用户/接收方的数据。所接收的请求通常可以被预处理以确定一个或更多个请求属性,例如紧急性、请求类型等。此外,预处理可以包括验证是否存在关于相对应的请求的未完成的用户指令(例如,用户希望仅在某些时间接收请求、用户希望成批地接收请求、或者在某个时间段内接收多个请求,等等)。一旦请求被允许传输给用户,通信系统就操作用户检测模块以定位在roi内的用户7020,并在用户之间识别选定接收方7030。如果未找到所请求的用户,可以向请求信号传输的源发送响应通知,系统可以选择默认用户或利用到一个或更多个扬声器的连接,并向所有用户播放一般可听消息。如果用户被定位,则用户检测模块识别用户的空间坐标7040,并且声音处理设施可以确定用于传输信号的优选换能器阵列单元7050。声音处理设施然后可以将指示信号和用户的空间位置的数据传输到选定换能器阵列单元,以用于将信号传输到用户7060。应当注意,这种信号可以发起诸如电话对话的双边通信会话。可选地,这种信号可以仅仅是提供有用信息的,并且仅仅指示用户反应以确定用户是否实际上接收到该信号。
图8例示了根据本发明的用于向用户提供无缝和免提通信的技术。如所示,当用户正在进行通信会话8010(例如,与第三方的电话对话或听音乐)时,系统标记用户是活动的并跟随用户的位置8020。此外,该系统收集由用户生成的音频信号以传输给第三方,并因此保持通信。用户检测模块跟随用户的位置数据8020,并且如果用户在所使用的换能器单元的覆盖区域的边缘附近则生成对声音处理设施的指示8030。当用户接近覆盖区域的边缘时,声音处理设施确定并识别具有适于向用户的位置提供通信的覆盖区域的附加换能器阵列单元8040,并确定指示换能器阵列单元对用户的特定位置和方位的适合性的测量数据。当附加换能器阵列是优选的、胜过当前使用的换能器阵列时,声音处理设施将通信会话转移到新选择的换能器阵列8050,以继续正在进行的通信会话8060。
附加地,图9例示了响应于用户发起的动作的系统操作。关于这一点,用户检测模块通常从roi主动接收感测数据,以用于处理感测数据和确定用户的位置。手势检测模块接收关于用户的运动的数据或由此生成的可听信号,并确定可识别的手势是否被用户执行9010。当手势被识别出时,面部检测模块可操作来确定用户的身份9020,并且手势模块确定与手势相关联的相对应的命令9030。通常,用户的身份与关于所请求的动作的用户特权进行比较9040。如果用户没有特权,系统可以向他提供适当的通知。可以通过外部管理服务器向远程位置传输所请求的数据或者发起通信会话或任何其他指定的动作来提供所请求的动作9050。如上面所指示的,动作可以是对与在roi内(内部私人通信会话)或远程(例如,电话呼叫类型通信会话或与连接到相同或类似音频通信系统的远程roi的通信)的特定其他用户的通信的请求。附加地或者可选地,这种动作可以与第三方系统的操作(例如打开热水器、打开前门、调高或调低音频系统的音量等)相关联。
图10例示了用于确定关于用户对传输到其的输入消息的响应的数据的操作技术。当声音消息被传输给用户10010时,用户检测模块和响应检测模块可以操作来接收指示用户的输入感测数据10020。接收到的感测数据与关于所传输的信号的数据相关联地被处理10030,以识别在用户感测数据和发送到其的信号之间的相关性。这种相关性可以与所传输的信号的内容相关联,然而相关性也可以是时间相关性。如果响应检测模块确定相关性高于相对应的预定阈值,则用户响应被确定10040,并且适当的指示被生成10050。该指示可以作为阅读回执被传输到信号源,和/或被存储用于在本地或远程地进一步处理。
因此,本发明的技术提供了直接传输到选定用户的耳朵的单边和双边音频通信,同时仅允许选定用户清楚地听到信号。然而,应当注意,如本文描述的本发明的系统和技术也可以被配置成选择性地利用用于提供在roi内的公共声音的一个或更多个可听扬声器。这可以在roi中没有找到特定的期望用户时或者为了向多个用户提供清晰的信号被执行。此外,该技术及其特权模块还可用于向用户请求他们的身份的证明,例如请求密码或安全问题以确定用户的身份。
此外,如上所述的本发明的技术和系统可操作来基于上述构建块来提供各种类型的通信会话。这种通信会话可以在用户和系统控制器(例如声音处理设施)之间、在通过在roi内的系统进行的两个或多个用户(位于不同的覆盖区域(例如房间)中)的通信之间或者在一个或更多个用户和外部第三方之间。这种外部第三方可以是利用类似或不同的音频通信系统(例如电话对话)的远程用户或者是能够接收和/或传输适当命令的一个或更多个其他系统。
本领域中的技术人员将容易认识到,各种修改和改变可应用于如上文所述的本发明的实施例而不偏离在所附权利要求中且由所附权利要求限定的其范围。
- 还没有人留言评论。精彩留言会获得点赞!