基于模拟退火神经网络和消除干扰的数据检测方法与流程
本发明属于通信技术领域,更进一步涉及无线通信技术领域中的一种基于模拟退火神经网络和消除干扰的数据检测方法。本发明可用于从高斯信道中同一频段上的混合数据中以最低误码率检测出用户发送的数据。
背景技术:
用户发送的数据经过多载波直接序列码分多址(multicarrierdirectsequencecodedivisionmultipleaccess)技术处理后在无线通信中高斯信道的同一频段上传输,用户发送的数据使用扩频码进行编码调制,接收端根据扩频码的正交性完成用户的数据检测。多载波直接序列码分多址mc-ds-cdma技术将码分多址cdma(codedivisionmultipleaccess)和正交频分复用ofdm(orthogonalfrequencydivisionmultiplexing)技术相结合,具有较高的频谱利用率、低截获率、较强的抗干扰能力的优点。然而,由于扩频码的不完全正交,加上正交频分复用ofdm技术对扩频码的正交性产生了进一步的破坏,不同用户发送的数据之间的干扰严重,使得用户的数据检测相当困难。
南京邮电大学在其申请的专利文献“量子神经网络用于多用户检测的方法”(申请专利号:200610038722.1,公开号:cn100547944c)中提出了一种量子神经网络用于多用户检测的方法。该方法通过经典计算机仿真,将量子神经网络构成多用户检测器,网络核心采用反馈型量子神经网络简化多用户检测器的结构,量子神经网络使用梯度下降算法经过多次迭代得到稳定的网络权值和阈值,形成稳定的网络,网络演化利用量子并行计算特性进行快速寻优,降低多用户检测器的复杂度和误码率。但是,该方法仍然存在的不足之处是,由于量子神经网络的迭代过程采用梯度下降算法,得到的权值和阈值并不是最优的权值和阈值,影响神经网络的分类检测性能,导致神经网络输出的数据与用户发送数据相差过大,检测出用户数据的误码率较高。
赵星在其发表论文“同步ds-cdma系统中基于信号重构的并行干扰消除算法的设计与实现”(南京邮电大学学报(自然科学版),2016,36(1):64-70)中提出了一种基于信号重构的并行干扰消除算法的设计与实现方法。该方法为了保证每个目标的解调性能,采用干扰消除算法,在相关解调后重构信号,根据扩频码的互相关性并行消除各目标中的其他干扰信号,然后再次相干解调,以达到减小解调误码率的效果。该方法存在的不足之处是,仅考虑了扩频码的不完全正交带来的影响,没有考虑到由于正交频分复用ofdm调制,进一步破坏了扩频码的正交性,不完全正交带来的影响没有被完全消除,检测出的的数据与用户发送的数据相差较大。
技术实现要素:
本发明的目的在于针对上述已有技术的不足,提出一种基于模拟退火神经网络和消除干扰的数据检测方法。
实现本发明目的的思路是,通过模拟退火神经网络的分类检测性能,从混合数据中提取出模拟退火神经网络优化数据,通过干扰消除方法消除模拟退火神经网络优化数据中的干扰数据,得到用户发送的数据,以用户发送的数据的误码率作为检测性能好坏的依据。
本发明具体步骤包括如下:
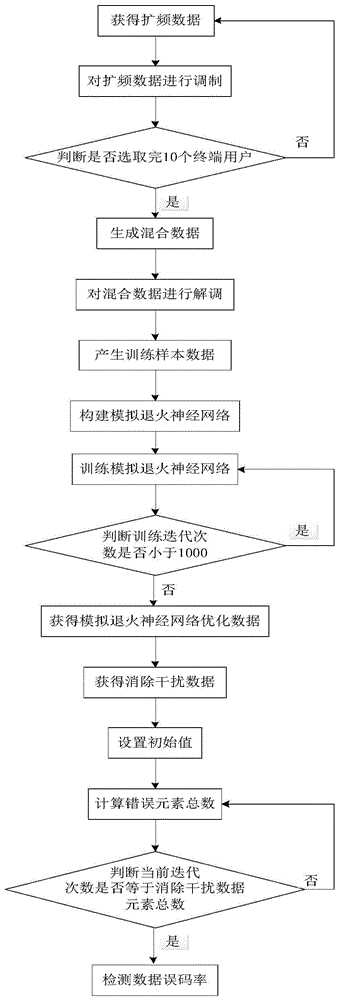
(1)获得扩频数据:
(1a)从10个终端用户中任选一个,作为向基站注册拟发送数据的目标用户;
(1b)基站随机产生一段数据,叠加到目标用户拟发送的数据之前,组成叠加数据;
(1c)基站从gold码矩阵中选取第一行作为扩频码,将叠加数据中的每一个元素与扩频码分别进行逻辑与操作,得到扩频数据;
(2)对扩频数据进行调制:
对扩频数据进行正交频分复用ofdm调制,得到所选一个终端用户的调制数据;
(3)判断是否选取完10个终端用户,若是,则执行步骤(4),否则,执行步骤(1);
(4)生成混合数据:
选择所有终端用户的调制数据中第一个元素分别进行相加,作为混合数据的第一个元素,以此类推,将混合数据的所有元素组成混合数据;
(5)对混合数据进行解调:
对混合数据进行离散傅里叶逆变换,得到解调数据;
(6)产生训练样本数据:
(6a)基站从gold码矩阵中选取第一行作为扩频码;
(6b)截取解调数据前端与基站随机产生的数据相同长度的一段数据,将其每一个元素与扩频码分别进行逻辑与操作,作为训练样本的输入数据,以基站随机产生的一段数据作为训练样本的输出数据,组成训练样本;
(7)构建模拟退火神经网络;
(7a)构造一个三层神经网络,其结构依次为输入层、隐藏层和输出层,隐藏层设置为具有不同权值和阈值的两层;
(7b)将模拟退火温度的初始值设置为80;
(7c)将隐藏层第一层和第二层的权值和阈值的初始值设置为0;
(7d)将训练迭代次数的初始值设置为0;
(8)训练模拟退火神经网络:
(8a)以训练样本的每一列作为一组元素,计算每组元素的输入和输出之间差值的绝对值,得到预测误差;
(8b)在[0,1]的实数范围内随机生成一个数,将模拟退火温度设置为当前模拟退火温度的0.9倍,计算模拟退火神经网络退火的临界值;
(8c)判断模拟退火神经网络退火的临界值是否大于0,若是,则执行步骤(8d),否则,执行步骤(8f);
(8d)采用神经网络权值的调整方法,计算模拟退火神经网络中隐藏层第一层和第二层的权值;
(8e)采用神经网络阈值的调整方法,计算模拟退火神经网络中隐藏层第一层和第二层的阈值;
(8f)将训练迭代次数加1;
(9)判断训练迭代次数是否小于1000,若是,则执行步骤(8),否则,得到训练好的模拟退火神经网络,执行步骤(10);
(10)获得模拟退火神经网络优化数据:
(10a)将步骤(5)解调数据中的每一个元素分别与步骤(6)的扩频码进行逻辑与操作,得到解扩数据;
(10b)将解扩数据与模拟退火神经网络隐藏层中第一层的权值相乘后加上第一层的阈值,得到模拟退火神经网络第一次优化数据;
(10c)将模拟退火神经网络第一次优化数据与模拟退火神经网络隐藏层中第二层的权值相乘后加上第二层的阈值,得到模拟退火神经网络优化数据;
(11)获得消除干扰数据:
(11c)通过gold码求得扩频码的互相关值,分别与模拟退火神经网络优化数据的每个元素相乘,得到干扰数据;
(11d)用模拟退火神经网络优化数据减去干扰数据,消除扩频码的不完全正交带来的影响,得到消除干扰数据;
(12)设置初始值:
(12a)将错误元素的个数初始值设置为0;
(12b)将迭代次数的初始值设置为1;
(13)计算错误元素总数:
(13a)从消除干扰数据中依次选取一个元素;
(13b)从第一个拟发送数据中依次选取一个元素;
(13c)将消除干扰数据中所选取元素值与第一个拟发送数据中所选取元素值相减后取模,得到中间值;
(13d)中间值向上取整后与错误元素个数相加,得到错误元素总数;
(14)判断当前迭代次数是否等于消除干扰数据元素总数,若是,则执行步骤(15),否则,将迭代次数加1后执行步骤(13);
(15)检测数据误码率:
将错误元素总数除以消除干扰数据元素总数,得到用户拟发送数据的误码率,完成数据误码率的检测。
本发明与现有技术相比具有以下优点:
第一,由于本发明采用模拟退火神经网络,在每次迭代时以一定的概率调整权值和阈值,随着迭代次数增加提高调整权值和阈值的概率,利用模拟退火神经网络的分类检测性能从混合数据中提取出用户发送的数据,克服了现有技术神经网络由于采用梯度下降法,得到的权值和阈值并不是最优的权值和阈值,影响神经网络的分类检测性能,导致神经网络输出的数据与用户发送数据相差过大的不足,使得本发明从混合数据中提取的用户发送数据的误码率更低,提高了数据检测性能。
第二,由于本发明采用消除干扰方法,通过扩频码的互相关性和重构正交频分复用ofdm的调制数据求出优化数据中的干扰数据,并从优化数据中剔除,克服了由于正交频分复用ofdm调制,进一步破坏了扩频码的正交性,导致检测出的数据误码率较高的问题,使得利用本发明的方法可以消除用户在发送数据的过程中产生的干扰数据,由此基站接收的数据更接近用户发送的数据,提高了数据检测的效果。
附图说明
图1是本发明的流程图;
图2是本发明仿真图。
具体实施方式
下面结合附图对本发明做进一步的详细描述。
参照附图1,对本发明的步骤做进一步的详细描述。
步骤1:获得扩频数据。
从10个终端用户中任选一个,作为向基站注册拟发送数据的目标用户。
基站随机产生一段数据,叠加到目标用户拟发送的数据之前,组成叠加数据。
基站从gold码矩阵中选取第一行作为扩频码,将叠加数据中的每一个元素与扩频码分别进行逻辑与操作,得到扩频数据。
步骤2:对扩频数据进行调制。
对扩频数据进行正交频分复用ofdm调制,得到所选一个终端用户的调制数据。
正交频分复用ofdm调制的具体步骤如下:
将扩频数据分割成n个子扩频数据。
按照下式,对扩频数据进行正交频分复用ofdm调制:
其中,z表示完成正交频分复用ofdm调制的数据,∑表示求和操作,n表示子扩频数据总数,z(k)表示第k个子扩频数据,exp(·)表示以自然常数为底的指数操作。
步骤3:判断是否选取完10个终端用户,若是,则执行步骤4,否则,执行步骤1。
步骤4:生成混合数据。
选择所有终端用户的调制数据中第一个元素分别进行相加,作为混合数据的第一个元素,以此类推,将混合数据的所有元素组成混合数据。
步骤5:对混合数据进行解调。
对混合数据进行离散傅里叶逆变换,得到解调数据。
步骤6:产生训练样本数据。
基站从gold码矩阵中选取第一行作为扩频码。
截取解调数据前端与基站随机产生的数据相同长度的一段数据,将其每一个元素与扩频码分别进行逻辑与操作,作为训练样本的输入数据,以基站随机产生的一段数据作为训练样本的输出数据,组成训练样本。
步骤7:构建模拟退火神经网络。
构造一个三层神经网络,其结构依次为输入层、隐藏层和输出层,隐藏层设置为具有不同权值和阈值的两层。
将模拟退火温度的初始值设置为80。
将隐藏层第一层和第二层的权值和阈值的初始值设置为0。
将训练迭代次数的初始值设置为0。
步骤8:训练模拟退火神经网络。
以训练样本的每一列作为一组元素,计算每组元素的输入和输出之间差值的绝对值,得到预测误差。
在[0,1]的实数范围内随机生成一个数,将模拟退火温度设置为当前模拟退火温度的0.9倍,计算模拟退火神经网络退火的临界值。
计算模拟退火神经网络退火的临界值的具体步骤如下:
按照下式,计算模拟退火神经网络退火的临界值:
r=rand-exp(-e/t)
其中,r表示模拟退火神经网络退火的临界值,rand表示在[0,1]的实数范围内随机生成一个数,exp(·)表示以自然常数为底的指数操作,e表示预测误差,t表示模拟退火温度。
采用神经网络权值的调整方法,计算模拟退火神经网络中隐藏层第一层和第二层的权值。
神经网络权值的调整方法的具体步骤如下:
第一步,按照下式,计算模拟退火神经网络中隐藏层的第一层权值:
其中,d1表示模拟退火神经网络中隐藏层的第一层权值,η表示值为0.1的模拟退火神经网络的学习速率,exp(·)表示以自然常数为底的指数操作,x表示当前训练样本元素的输入值,d2表示模拟退火神经网络中隐藏层的第二层权值,k表示预测误差;
第二步,按照下式,计算模拟退火神经网络中隐藏层的第二层权值:
其中,d2表示模拟退火神经网络中隐藏层的第二层权值,k表示预测误差。
采用神经网络阈值的调整方法。计算模拟退火神经网络中隐藏层第一层和第二层的阈值。
神经网络阈值的调整方法的具体步骤如下:
第一步,按照下式,计算模拟退火神经网络中隐藏层的第一层阈值:
其中,a1表示模拟退火神经网络中隐藏层的第一层阈值;
第二步,用模拟退火神经网络中隐藏层的第二层阈值加上预测误差,得到模拟退火神经网络中隐藏层的第二层阈值。
将训练迭代次数加1。
步骤9:判断训练迭代次数是否小于1000,若是,则执行步骤8,否则,得到训练好的模拟退火神经网络,执行步骤10。
步骤10:获得模拟退火神经网络优化数据。
将步骤5解调数据中的每一个元素分别与步骤6的扩频码进行逻辑与操作,得到解扩数据。
将解扩数据与模拟退火神经网络隐藏层中第一层的权值相乘后加上第一层的阈值,得到模拟退火神经网络第一次优化数据。
将模拟退火神经网络第一次优化数据与模拟退火神经网络隐藏层中第二层的权值相乘后加上第二层的阈值,得到模拟退火神经网络优化数据。
步骤11:获得消除干扰数据。
通过gold码求得扩频码的互相关值,分别与模拟退火神经网络优化数据的每个元素相乘,得到干扰数据。
用模拟退火神经网络优化数据减去干扰数据,消除扩频码的不完全正交带来的影响,得到消除干扰数据。
步骤12:设置初始值。
将错误元素的个数初始值设置为0。
将迭代次数的初始值设置为1。
步骤13:计算错误元素总数。
从消除干扰数据中依次选取一个元素。
从第一个拟发送数据中依次选取一个元素。
将消除干扰数据中所选取元素值与第一个拟发送数据中所选取元素值相减后取模,得到中间值。
中间值向上取整后与错误元素个数相加,得到错误元素总数。
步骤14:判断当前迭代次数是否等于消除干扰数据元素总数,若是,则执行步骤15,否则,将迭代次数加1后执行步骤13。
步骤15:检测数据误码率。
将错误元素总数除以消除干扰数据元素总数,得到用户拟发送数据的误码率,完成数据误码率的检测。
下面结合仿真实验对本发明的效果进一步说明。
1.仿真条件:
本发明的仿真实验是在matlab16.0软件下进行的。在本发明的仿真实验中,为了真实地模拟加性高斯白噪声信道,采用伪随机序列模拟高斯白噪声。设置每一个数据帧的大小为1000,用户发送数据的平均功率为1毫瓦。
2.仿真内容与结果分析:
本发明的仿真实验是采用本发明方法与两项现有技术三种方法(并行干扰消除方法、神经网络方法),通过从混合数据中提取出用户发送的数据,将用户发送数据中的错误元素总数除以用户发送的数据元素总数,得到从混合数据中提取的用户发送数据的误码率结果进行对比,其结果如附图2所示。
图2中横轴表示信道的信噪比,纵轴表示从混合数据中提取的用户发送数据的误码率。图2中以星号标示的曲线表示,使用现有技术的并行干扰消除方法得到的误码率曲线。图2中以正方形标示的曲线表示,使用现有技术的神经网络方法得到的误码率曲线。图2中以空心圆标示的曲线表示使用本发明方法得到的误码率曲线。
从图2中可以看出,在信道的信噪比相同的情况下,使用本发明方法得到的误码率曲线上所对应的点的位置低于使用两项现有技术(并行干扰消除方法、神经网络方法)得到的误码率曲线上所对应的点的位置,反映了使用本发明方法从混合数据中提取出的用户发送的数据具有更低的误码率,具有更高的数据检测性能。
- 还没有人留言评论。精彩留言会获得点赞!